

1. 数据收集和构建:制作原材料
数据是任何机器学习项目的命脉,构成了模型训练的基础。在这种情况下,我必须收集我的书面文本的强大数据集。这包括电子邮件、短信、社交媒体帖子等,这些帖子是匿名的,并被结构化为对话格式。
Python编程语言提供了一种直接的方法:
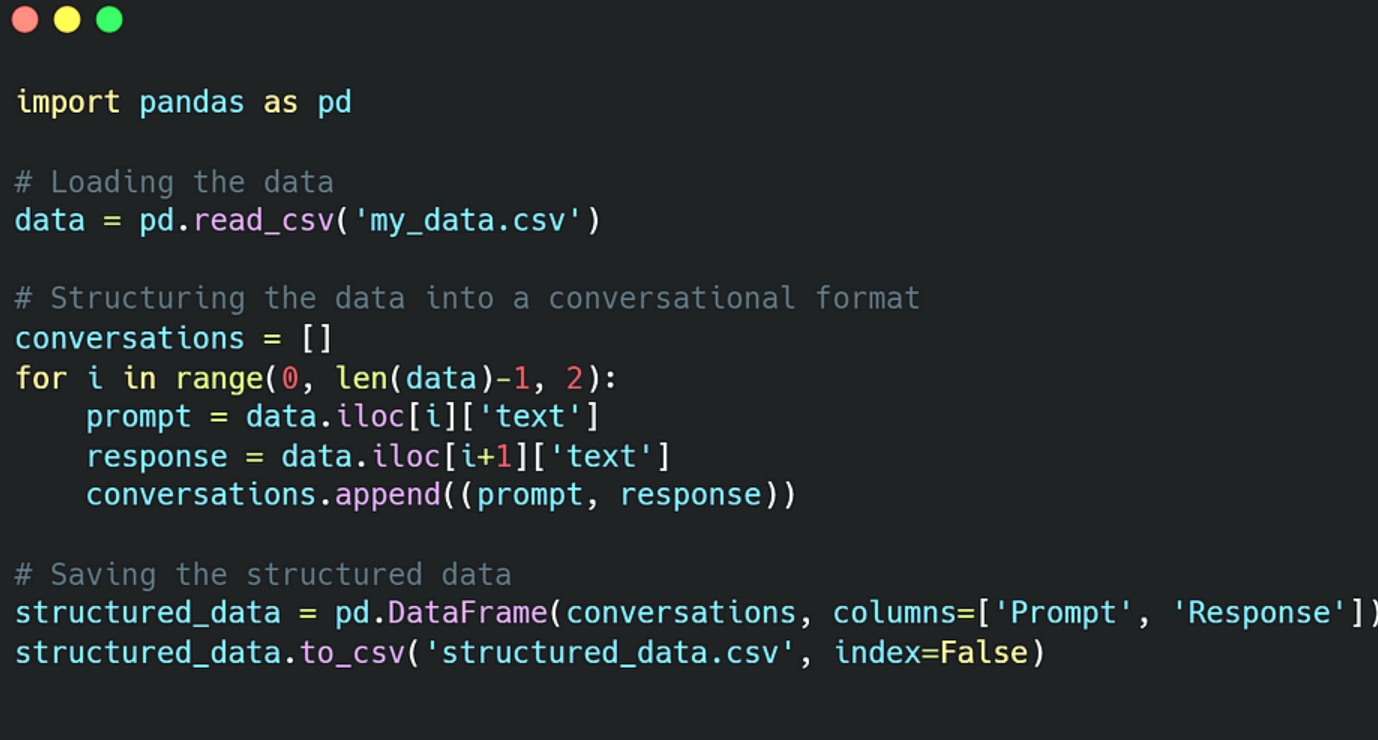
在此 Python 脚本中,读取原始数据,并将每对连续消息结构化为提示-响应对。然后将这些对保存在结构化的 CSV 文件中。例如,如果原始数据包含句子“A”、“B”、“C”、“D”,则它们的结构为 [(“A”、“B”)、(“C”、“D”)],其中“A”和“C”是提示,“B”和“D”是响应。
2. 监督学习:奠定基础
训练过程从监督学习开始,其中 GPT-4 的任务是根据给定的提示预测响应。让我们看看它是如何实现的:
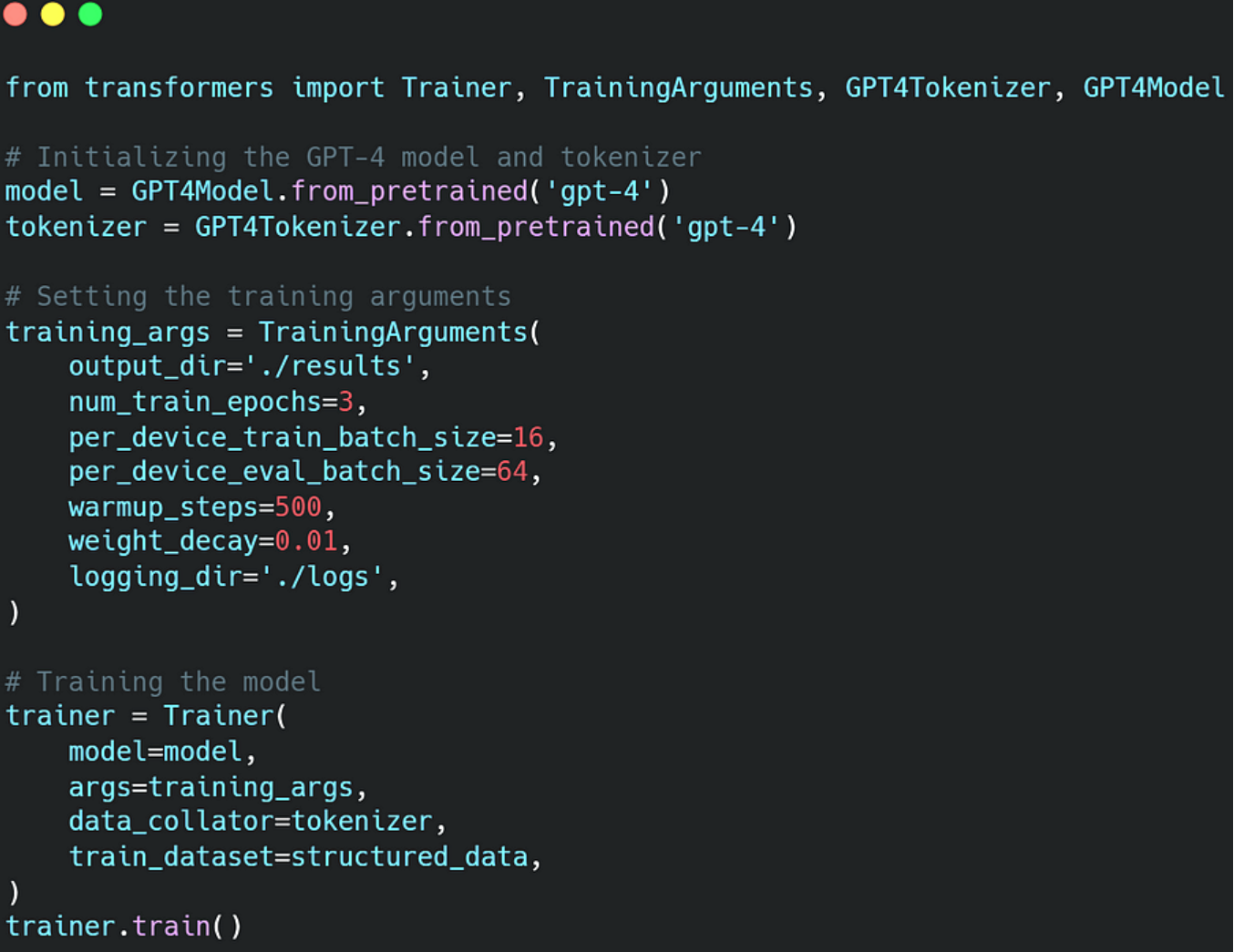
这段代码使用我的数据作为输入来设置 GPT-4 模型进行训练。Hugging Face的变形金刚库中的课程负责处理训练过程。Trainer
3. 迭代细化:通过迭代实现精确
在初始训练之后,使用了一个称为“迭代细化”的过程。以下是它的工作原理:
- 该模型为每个提示生成多个备选响应。
- 我根据这些回复与我的风格最接近的程度手动对这些回复进行排名。
- 该模型从这些反馈中学习,并利用这些知识进行进一步完善。
这种强化过程使模型能够逐步改进其响应生成。
4. 近端策略优化 (PPO):高级微调
微调模型的响应以增强与我的对话风格的一致性,需要使用称为近端策略优化 (PPO) 的强化学习技术。
在强化学习中,模型学习执行最大化“奖励”的动作。在这种情况下,“奖励”是我分配给模型响应的排名。与我的风格非常相似的回答获得了更高的奖励。
**PPO是一种算法,旨在通过优化参数来改进策略(模型的行为),从而使预期奖励最大化。**与其他一些强化学习技术不同,PPO确保策略的更新不会与以前的策略发生重大偏差,从而保持学习的稳定性和稳健性。
以下是如何实现的概述:

该函数是一个生成器,可从输入数据生成随机小批量。该函数使用 PPO 算法更新模型的参数。在更新规则中,“批评者”是估计预期回报的模型的一部分,而“参与者”决定要采取的行动。是控制每次更新时允许策略更改量的超参数。ppo_iter``ppo_update``clip_param
此代码提供了 PPO 算法的基本实现,可以根据项目的具体要求对其进行增强和调整。
总之,PPO 实现了对 GPT-4 模型的先进、有效且稳定的微调,使其逐渐接近于复制我独特的对话风格。这种强化学习技术在微调语言模型中的应用具有巨大的潜力,为人工智能驱动的通信开辟了新的途径。
5. 验证和评估:检查镜像
与训练一样重要,验证和评估训练模型的性能同样重要。只有通过这样的评估,我们才能衡量培训是否有效地塑造了模型,以便像我一样做出反应。
对于该项目,在多个级别进行了验证。
5.1. 提示测试
最简单的验证形式是使用各种提示测试模型并评估其响应。下面是如何完成此操作的示例:
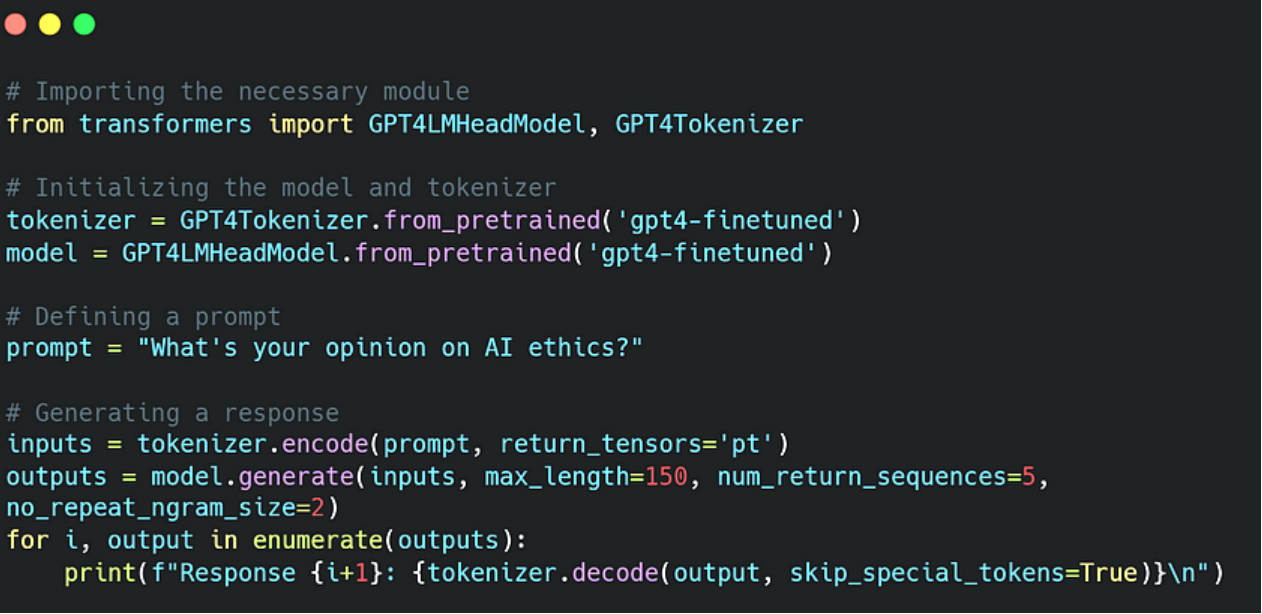
此代码片段相当简单。
我们加载微调的模型及其相应的分词器。然后,我们定义一个提示并使用模型生成响应。参数设置为 5 可生成五个不同的响应,参数设置为 2 可防止模型生成重复短语。num_return_sequences``no_repeat_ngram_size
5.2. 与真实对话比较
验证过程的另一个重要方面是将模型的响应与我在过去对话中给出的实际响应进行比较。这需要维护我的对话数据集,其中每个对话都由我和他人之间的一系列交流组成。
这种比较可以对模型的反应与我自己的反应的一致性进行定性分析。
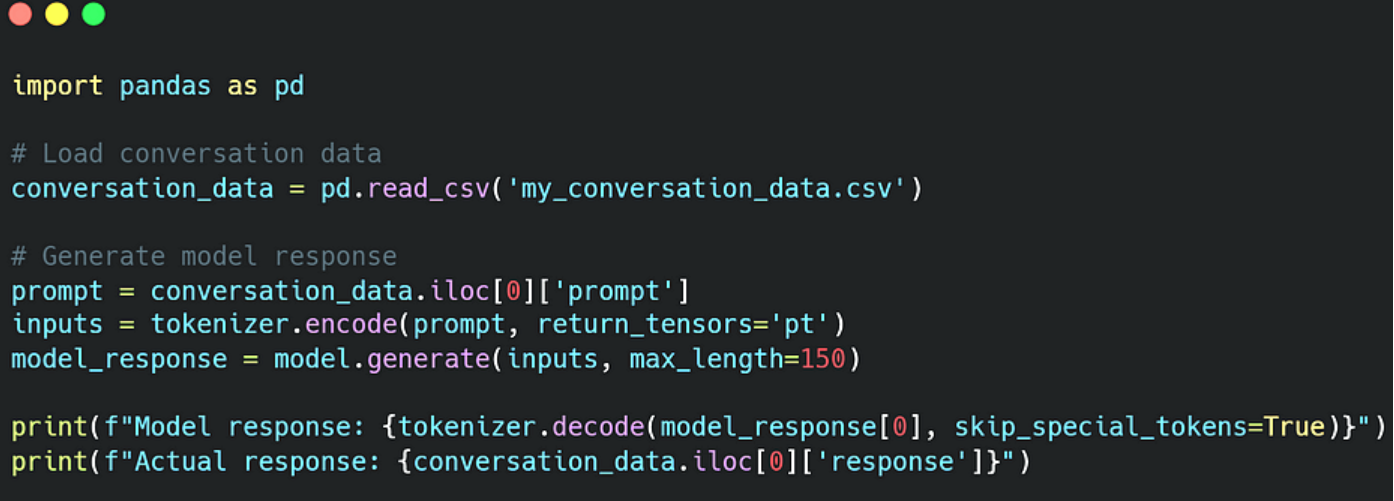
在此代码中,我们加载一个包含我过去的对话的 CSV 文件。然后,我们根据数据集中第一个对话的提示从模型生成响应,并将其与我的实际响应进行比较。
5.3. 图灵测试
最终的测试是让另一个人与模特聊天,猜测他们是在和我聊天还是在和模特聊天。这是著名的图灵测试的变体,是模型令人信服地模仿我的能力的直接衡量标准。
总之,验证和评估阶段有助于验证模型模仿我的对话风格的熟练程度,有助于微调我的“数字孪生”。它照亮了需要进一步训练的区域,从而指导了后续训练迭代的方向。
6. 未来的潜力和挑战:个性化 AI 的未来
这种训练 GPT-4 以模仿个人对话风格的探索揭示了个性化 AI 的未来。借助正确的数据和训练技术,人工智能模型可以潜在地捕捉到个人的细微差别,并以前所未有的方式个性化数字通信。
然而,负责任地走这条路至关重要,优先考虑道德考虑和数据隐私。随着我们越来越接近实现个性化人工智能的潜力,这些考虑必须指导我们的进步。
总之,个性化 GPT-4 的旅程突出了人工智能的扩展功能。通过详细的数据准备、微调技术和严格的验证,可以实现高度的个性化。这证明了人工智能的变革力量,也是对未来可能性的令人兴奋的一瞥。


















