
数据库类型本篇文章主要介绍了相关 MySQL 技术系列体系中,最重要的部分-索引,带你从索引的本质(底层原理)、索引的类型、索引的原理、索引的数据结构,最后到索引的使用角度以及索引的优化,全方位 360 度去探索索引的奥秘!
- OLAP:联机分析处理----对海量历史数据进行分析,产生决策性的策略----数据仓库—Hive
- OLTP:联机事务处理----要求很短时效内返回对应的结果----数据库—关系型数据库(mysql、oracle)
- 磁盘角度去看索引机制(运作机制提升性能原理)
- 索引机制的分析和基本介绍
- 索引机制的分类和概念
- 索引本身的优缺点以及不同分类的优缺点
索引和磁盘的关系
数据读取时主要时间开销
从概念模型上来讲,从磁盘读出一条数据需要两步:
- 将磁头移动到数据所在的扇区,找到数据所在的页,将这一页数据加载到内存
- 在内存中,找到数据所在的偏移量,并返回该记录
总结分析瓶颈点
这两步中,第 1 步消耗的时间远远大于第 2 步,其原因是需要移动磁头到给定扇区,时间开销由寻道和延迟两部分构成,通常在毫秒级。而从内存直接读取数据,时间为纳秒级。
优化的方式
主要的时间开销来源于寻找数据所在的页。因此优化寻找数据所在页的需求是非常紧急且重要的。
数据量计算
对于给定大小的数据量(比如 2^ 20 条)、平均每条记录所占用的内存空间(比如 2^ 7byte)和每一页的大小(如 4kb),那么平均每页的记录数和所需的数据页数就可以确定,分别是(32(2^12/2^7)条和 2^15(2^20/2^5)页)。
传统暴力(顺序型读写)X
如果使用遍历的方式,将每一页加载到内存然后搜索,那么最坏情况下需要 1 万次的读取数据页的操作才能搜索到给定记录。这就好像我有一本书,我要从第一页一指翻到最后一页,才能找到我要读到的某一行文字,这显然不太高效。
索引机制(半随机性读写)√
优化的办法是建立索引,将数据按索引排序,对于每一条数据,我可以建立一个索引+指针来指向该数据的起始地址。(空间来换时间)
那么我就可以将这个索引存起来,并使用指针指向该记录。
- 现在需要 2^ 20 个索引,假设每条索引和指针共占 8byte 空间,那么所需的索引页为 2^ 11(2^ 20 * 8 / 4kb)页。
- 此时如果遍历索引页,然后再去找到对应的记录,最坏需要 2^11 + 1 次读取,显然效率高了些。
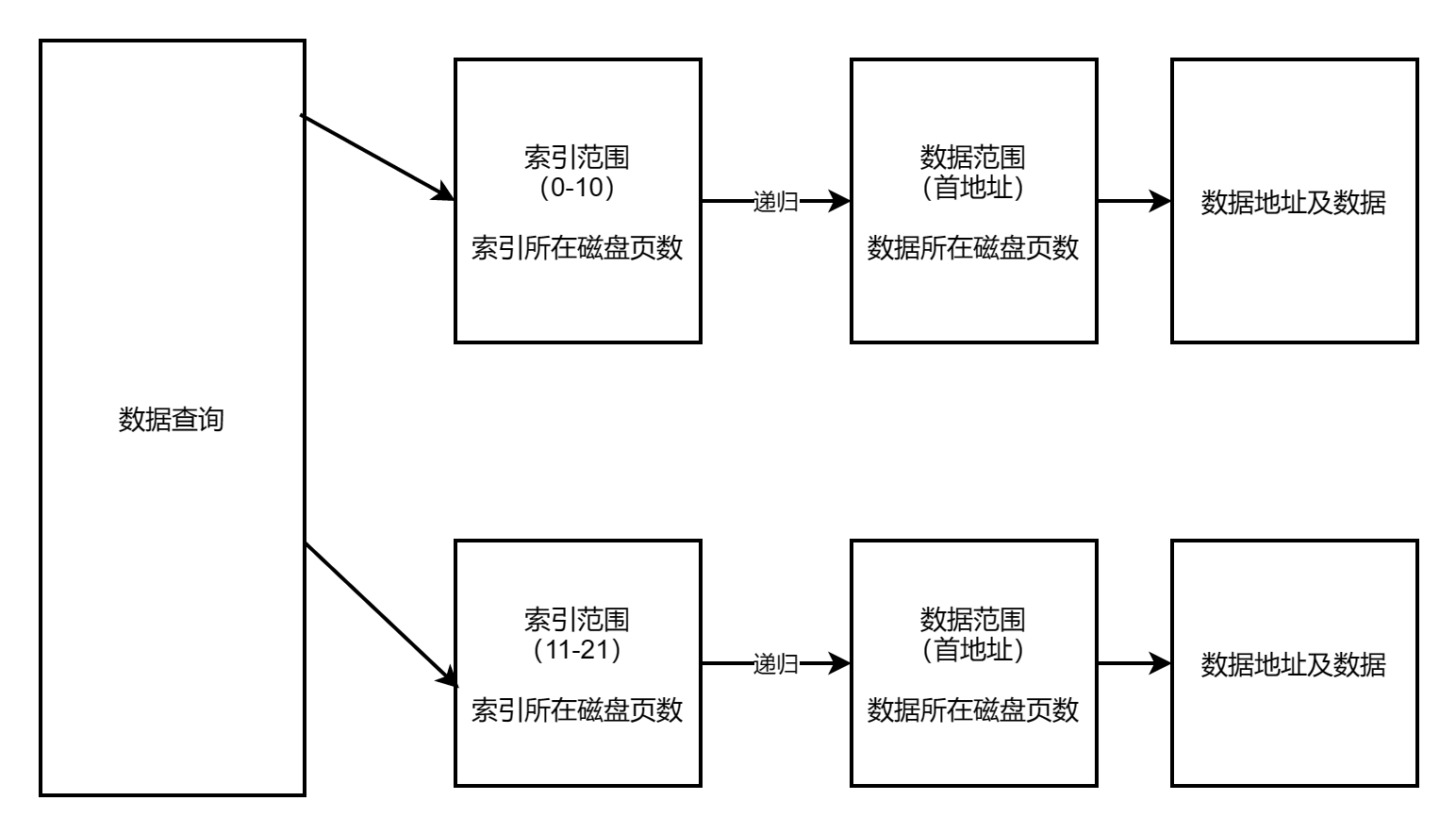
索引升级之多级索引化(全随机性读写)
如果利用递归的思想,对索引页再建索引(是不是在内存管理中有类似的想法,对页表建立页表)。
比如,对这 2^20 条数据的索引建立索引。对于给定的一页,它的第一条索引是确定的。
- 那么将第一条索引再存到另一个索引中(索引的索引),假设索引都连续,那么对于给定的一个索引,就可以根据索引的索引找到这个索引所在的页。
- 然后找到这个索引,根据这个索引指向的数据去读取数据。比如:检索索引 15,它在 0 到 31 之间,便可以知道它在第一个数据页上,通过之前保存起来的指针即可访问到该页。
- 由于更上层的索引更稀疏了,因此可以保存更多的索引,使每一页能表示更多的数据。
- 递归到最终只需 1 页就能保存某一级索引的时候,就可以停止递归了。此时根据索引来访问数据,只需要查每一级索引中的某一页,就可以确定下一级索引所在的页。直到最底一层的索引,它指向了数据。
- 那么需要读取的总页数为索引级数+1。这个次数远远小于总数据页数。
使用索引的好处在于
- 第一,将数据进行了分桶,对于落在桶内区间段的索引,都可以通过一个指针访问到对应的数据页。
- 第二,索引所占的内存要远远小于 1 条记录所占的空间,因此个索引页能保存非常多的索引。
索引机制总结
一句话:减少加载磁盘的次数(寻道的时间和次数),且索引占用数据较少,所以可以存放更多的数据内存(提高检索效率)。
磁盘预读
- 去磁盘读取数据,是用多少读取多少吗?
- 内存和磁盘发生数据交互的时候,一般情况下有一个最小的逻辑单元:页(Page)。
- 页一般由操作系统觉得大小,4k 或 8k,而我们在进行数据交互的时候,可以取页的整数倍来读取。
- innodb 存储引擎每次读取数据,读取 16k
局部性原理:数据和程序都有聚集成群的倾向,同时之前被访问过的数据很可能再次被查询,空间局部性,时间局部性
索引存储
磁盘,查询数据的时候会优先将索引加载到内存中
- 索引在存储的时候,需要什么信息?需要存储存储什么字段值?
- key:实际数据行中存储的索引键。
- 文件地址,所在磁盘文件地址
- offset:偏移量
索引系统性介绍
索引的定义
索引(index)是帮助 MySQL 高效获取数据的数据结构(有序)。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
索引的介绍
- 索引是一种用于快速查询和检索数据的数据结构。
- 索引的作用就相当于目录的作用,可以类比字典、 火车站的车次表、图书的目录等。
- 索引是在存储【引擎层】实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
可以简单的理解为“排好序的快速查找数据结构”,数据本身之外,数据库还维护者一个满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构,就是索引。
索引本身也很大,不可能全部存储在内存中,一般以索引文件的形式存储在磁盘上,(InnoDB 数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
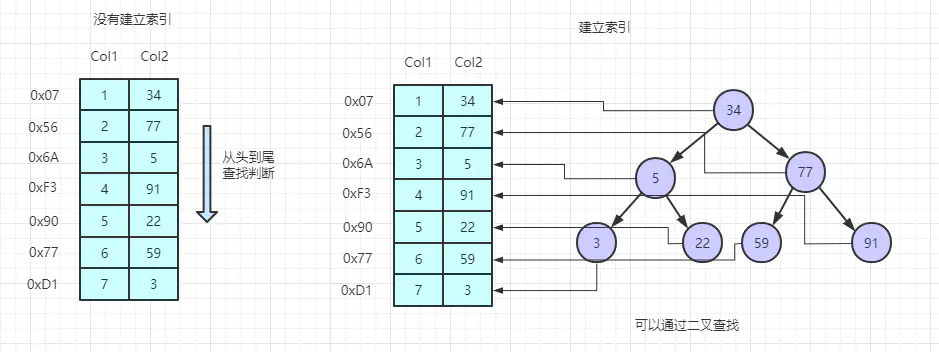
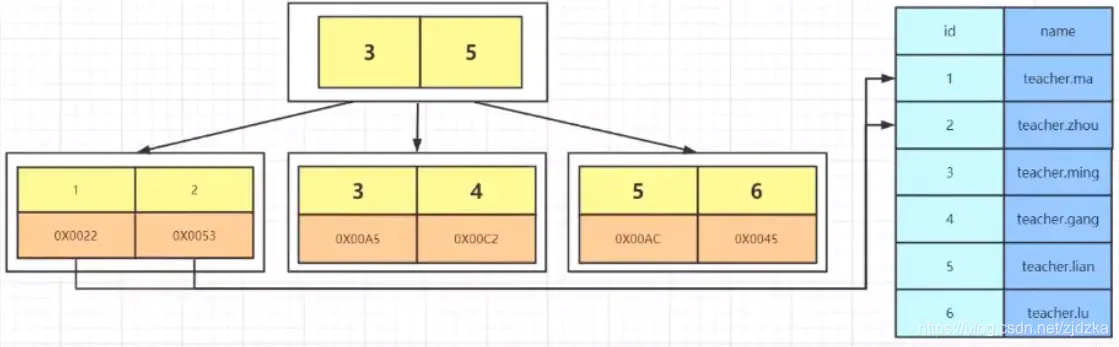
- 左边是数据表,一共有两列七行记录,最左边的 0x07 格式的数据是物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。
- 为了加快 Col 2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据的物理地址的指针,这样就可以运用二叉查找快速获取到对应的数据了。
- 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。建立索引是数据库中用来提高性能的最常用的方式。
索引优缺点
优势
- 效率:大大提高数据检索效率(减少了检索的数据量以及次数),降低数据库 IO 成本,这也是创建索引的最主要原因;
- 性能:降低数据排序的成本,降低 CPU 的消耗,提高系统性能;
- 索引大大减小了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机 IO 变成顺序 IO
在 MySQL5.1 和更新的版本中,InnoDB 可以在服务器端过滤掉行后就释放锁,但在早期的 MySQL 版本中,InnoDB 直到事务提交时才会解锁。
对不需要的元组的加锁,会增加锁的开销,降低并发性。
InnoDB 仅对需要访问的元组加锁,而索引能够减少 InnoDB 访问的元组数。但是只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。
一旦索引不允许 InnoDB 那样做(即索引达不到过滤的目的),MySQL 服务器只能对 InnoDB 返回的数据进行 WHERE 操作,已经无法避免对那些元组加锁了。
如果查询不能使用索引,MySQL 会进行全表扫描,并锁住每一个元组,不管是否真正需要。
劣势
- 空间方面:索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以索引也需要占用内存(物理空间)。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存索引文件。
注意要点
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效;
- 因此应该只为最经常查询和最经常排序的数据列建立索引
- MySQL 里同一个数据表里的索引总数限制为 16 个。
关于 InnoDB、索引和锁:InnoDB 在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
索引的分类
存储数据结构划分
B-Tree 索引(B-Tree 或 B+Tree 索引),Hash 索引,full-index 全文索引,R-Tree 索引,这里所描述的是索引存储时保存的形式。
【从物理角度划分】
- 聚集索引:即数据文件本身就是主键索引文件(InnoDB)。
- 聚集索引(聚簇索引、Innodb):聚集索引即索引结构和数据一起存放的索引,主键索引属于聚集索引。表中记录的物理顺序与键值的索引顺序相同。 因为真实数据的物理顺序只有一种,所以一个表只能有一个聚集索引。
- InnoDB 引擎的表的 .ibd 文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
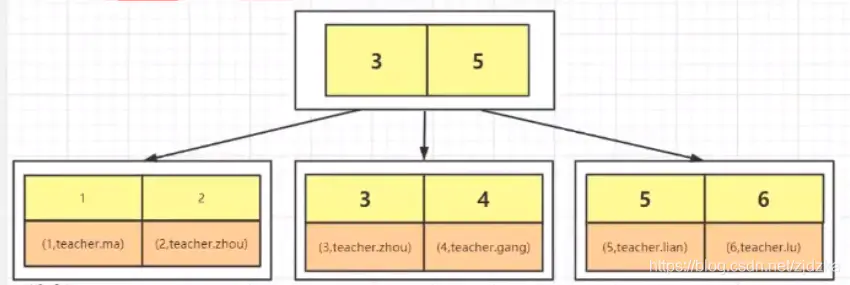
- 非聚集索引(辅助索引):即索引文件与数据文件是分离的(MyISAM),聚集索引和非聚集索引都是 B+树结构。
- 非聚集索引即索引结构和数据分开存放的索引。二级索引属于非聚集索引。
- 记录的物理顺序与键值的索引顺序不同。这也是非聚集索引与聚集索引的根本区别。
- 表中记录的物理顺序与键值的索引顺序不同。这也是非聚集索引与聚集索引的根本区别。
非聚集索引的叶子节点并不一定存放数据的指针, 因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
MYISAM 引擎的表的.MYI 文件包含了表的索引, 该表的索引(B+树)的每个叶子非叶子节点存储索引, 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
聚集索引的优点
聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
聚集索引的缺点
- 依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- 更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改, 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的, 所以对于主键索引来说,主键一般都是不可被修改的。
非聚集索引的优点
更新代价比聚集索引要小 。因为非聚集索引的叶子节点是不存放数据的
非聚集索引的缺点:
- 跟聚集索引一样,非聚集索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
【从功能角度划分】
- 普通索引(单列索引):每个索引只包含单个列,一个表可以有多个单列索引,仅加速查询;
- 唯一索引:加速查询 + 列值唯一(可以有 null)
- 主键索引:加速查询 + 列值唯一(不可以有 null)+ 表中只有一个,在 mysql 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
- 组合/复合索引(多列索引):多列值组成一个索引,专门用于组合搜索,其效率大于索引合并(即使用多个单列索引组合搜索)
主键与唯一索引的区别
- 主键是一种约束,目的是对这个表的某一列进行限制;唯一索引是一种索引,目的是为了加速查询;
- 主键列不允许为空值,而唯一索引列可以为空值(null)
- 一个表中最多只能有一个主键,但是可以包含多个唯一索引
- 主键一定是唯一性索引,唯一性索引并不一定就是主键
【从特性角度划分】
MySQL 目前主要有以下几种索引类型:B+Tree 索引、哈希索引、全文索引(full-index)与空间数据索引(R-Tree)
- B+Tree 索引:是大多数 MySQL 存储引擎的默认索引类型,不需进行全表扫描,只需对树进行搜索,所以查找速度快很多; B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
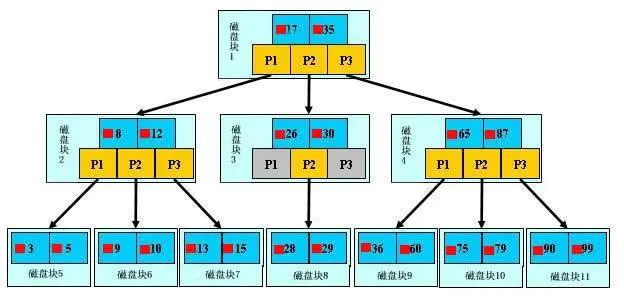
B+树把数据全放在了叶子节点中,叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。 例如: 查询范围 select * from table where id between 11 and 35?
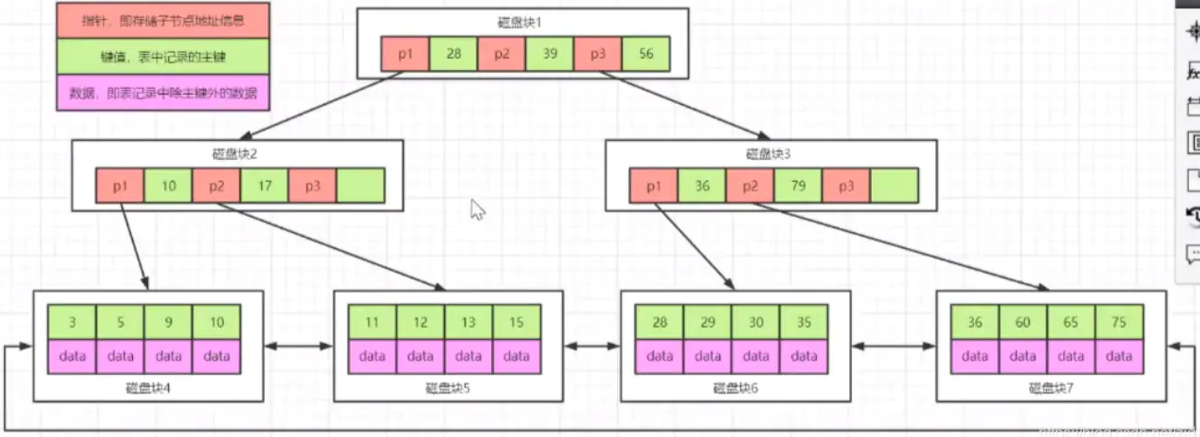
- 第一步,将磁盘一加载到内存中,发现 11<28,寻找地址磁盘 2
- 第二步,将磁盘二加载到内存中,发现 10>11>17,寻找地址磁盘 5
- 第三步,将磁盘五加载到内存中,发现 11=11,读取 data
- 第四步,继续向右查询,读取磁盘 5,发现 35=35,读取 11-35 之间数据,结束 由此可见,这样的范围查询比 B 树速度提高了不少。
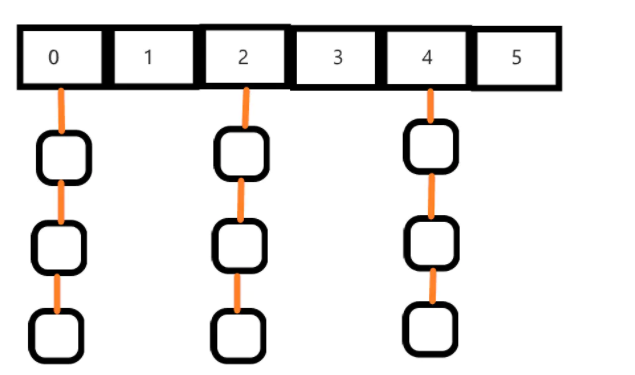
- 哈希索引:哈希索引能以 O(1) 时间进行查找,一次定位,不需要像树形索引逐层查找,具有极高的效率。哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。但是失去了有序性
- 对排序与组合索引效率不高;
- 只支持精确查找(等值查询,如=、in()、<=>),无法用于部分查找和范围查找。
- InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
- 全文索引:MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
- 查找条件使用 MATCH AGAINST,而不是普通的 WHERE。全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
- 空间数据索引:MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。必须使用 GIS 相关的函数来维护数据
树(二叉树、红黑树、AVL 树、B 树、B+树),这里为什么索引默认用 B+树,而不用 B 树、二叉树、hash 和红黑树呢?
为什么不用 B-tree:
- B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针(B 树每个节点都存储数据,B+树只有叶子节点才存储节点),所以查找相同数据量的情况下,B 树的高度更高,IO 更频繁。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。
- 由于 B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可(叶子节点使用双向链表连接)。但是 B 树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来找,所以 B+树更加适合在区间查询的情况,通常 B+树用于数据库索引。
为什么不用 Hash 方式:
因为 Hash 索引底层是哈希表,哈希表是一种以 key-value 存储数据的结构,只适合等值查询(等值查询效率高),如=、in()、<=>多个数据在存储关系上是完全没有任何顺序关系的,所以对于区间查询是无法直接通过索引查询的,就需要全表扫描,即不支持范围查询 。
哈希索引不支持多列联合索引的最左匹配规则,如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题。
为什么不用二叉树方式:
树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且 IO 代价高。
什么不用红黑树
期待下篇树的高度随着数据量增加而增加,IO 代价高。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。
哎 支持太多了,期待下篇的介绍说明,未完待续 ......




















