| Transformation function |
解释 |
|---|
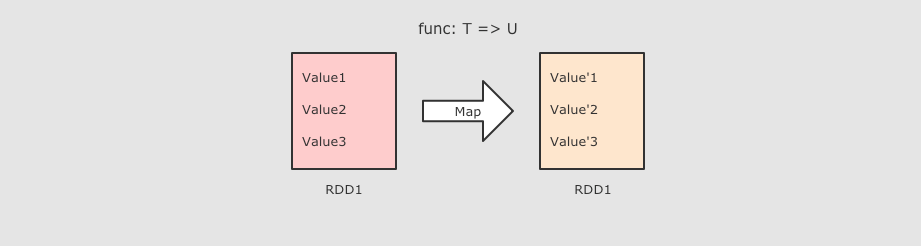
| map(T ⇒ U)
|
sc.parallelize(Seq(1, 2, 3))
.map( num => num * 10 )
.collect()


作用
签名 def map[U: ClassTag](f: T ⇒ U): RDD[U]
参数
注意点
|
|---|
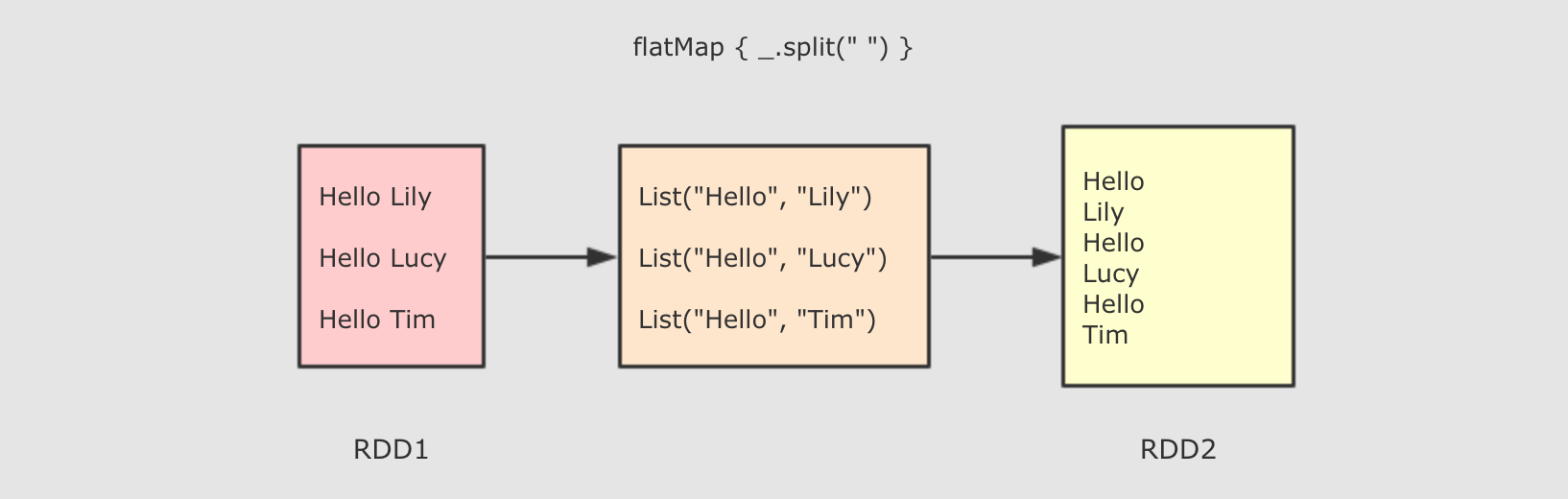
| flatMap(T ⇒ List[U])
|
sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim"))
.flatMap( line => line.split(" ") )
.collect()


作用
调用 def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
参数
注意点
-
flatMap 其实是两个操作, 是 map + flatten, 也就是先转换, 后把转换而来的 List 展开
-
Spark 中并没有直接展平 RDD 中数组的算子, 可以使用 flatMap 做这件事
|
|---|
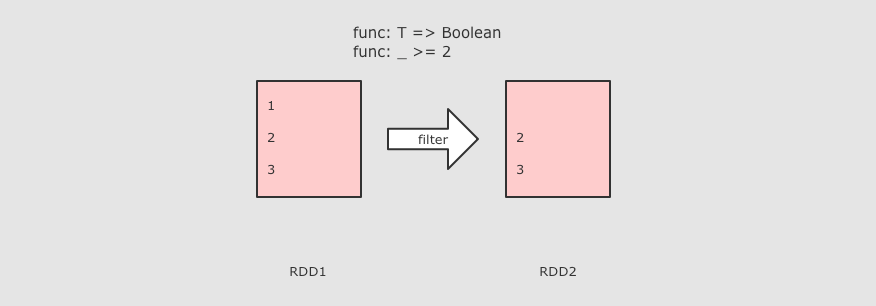
| filter(T ⇒ Boolean)
|
sc.parallelize(Seq(1, 2, 3))
.filter( value => value >= 3 )
.collect()


作用
-
Filter 算子的主要作用是过滤掉不需要的内容
-
scala> sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")).flatMap(_.split(" ")).filter(x=>x.length >4).collect
res8: Array[String] = Array(Hello, Hello, Hello)
|
|---|
| mapPartitions(List[T] ⇒ List[U])
|
RDD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换 |
|---|
| mapPartitionsWithIndex
|
和 mapPartitions 类似, 只是在函数中增加了分区的 Index |
|---|
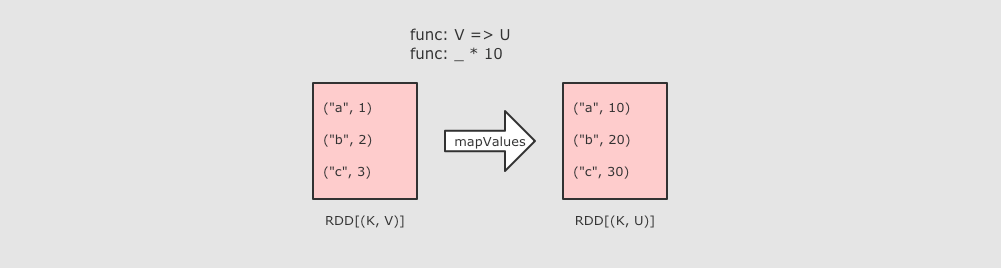
| mapValues
|
sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
.mapValues( value => value * 10 )
.collect()


作用
|
|---|
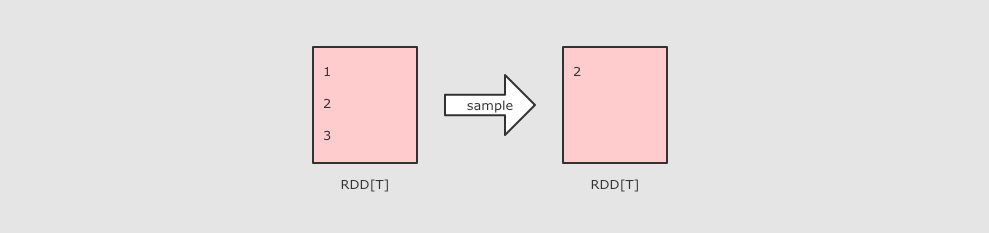
| sample(withReplacement, fraction, seed)
|
sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
.sample(withReplacement = true, 0.6, 2)
.collect()


作用
参数
-
Sample 接受第一个参数为 withReplacement, 意为是否取样以后是否还放回原数据集供下次使用, 简单的说, 如果这个参数的值为 true, 则抽样出来的数据集中可能会有重复
-
Sample 接受第二个参数为 fraction, 意为抽样的比例
-
Sample 接受第三个参数为 seed, 随机数种子, 用于 Sample 内部随机生成下标, 一般不指定, 使用默认值
|
|---|
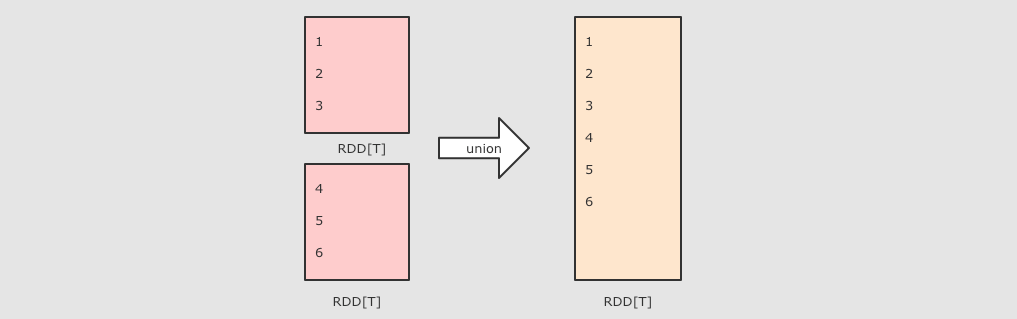
| union(other)
|
val rdd1 = sc.parallelize(Seq(1, 2, 3))
val rdd2 = sc.parallelize(Seq(4, 5, 6))
rdd1.union(rdd2)
.collect()


|
|---|
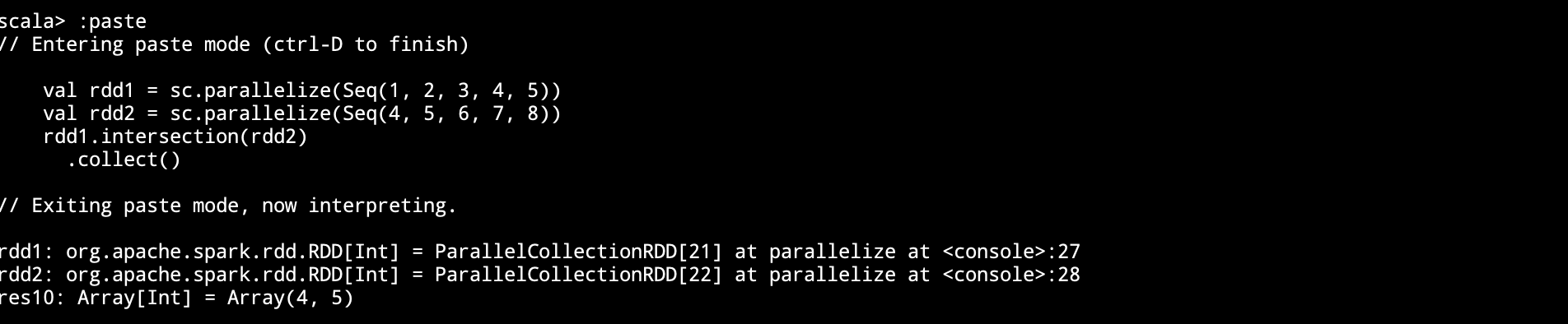
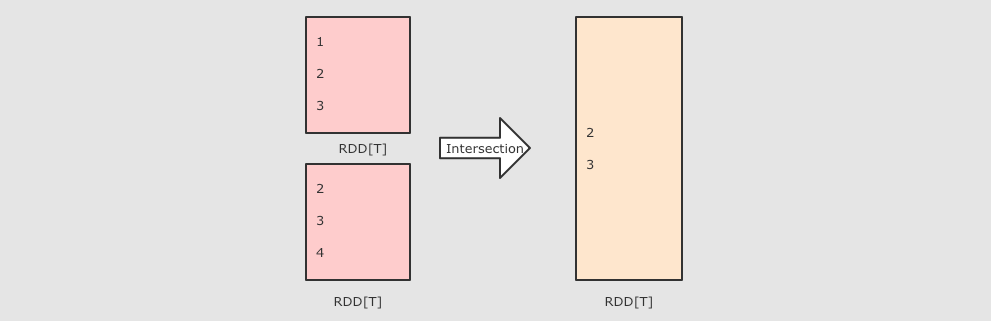
| intersection(other)
|
val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5))
val rdd2 = sc.parallelize(Seq(4, 5, 6, 7, 8))
rdd1.intersection(rdd2)
.collect()


作用
-
Intersection 算子是一个集合操作, 用于求得 左侧集合 和 右侧集合 的交集, 换句话说, 就是左侧集合和右侧集合都有的元素, 并生成一个新的 RDD
|
|---|
| subtract(other, numPartitions)
|
(RDD[T], RDD[T]) ⇒ RDD[T] 差集, 可以设置分区数 |
|---|
| distinct(numPartitions)
|
sc.parallelize(Seq(1, 1, 2, 2, 3))
.distinct()
.collect()


作用
注意点
|
|---|
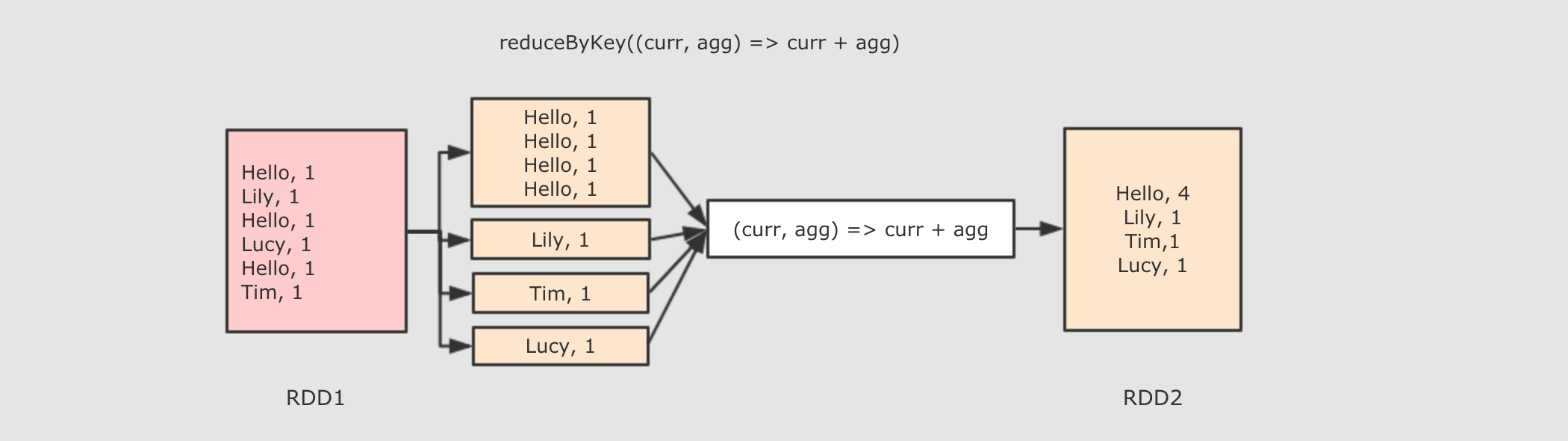
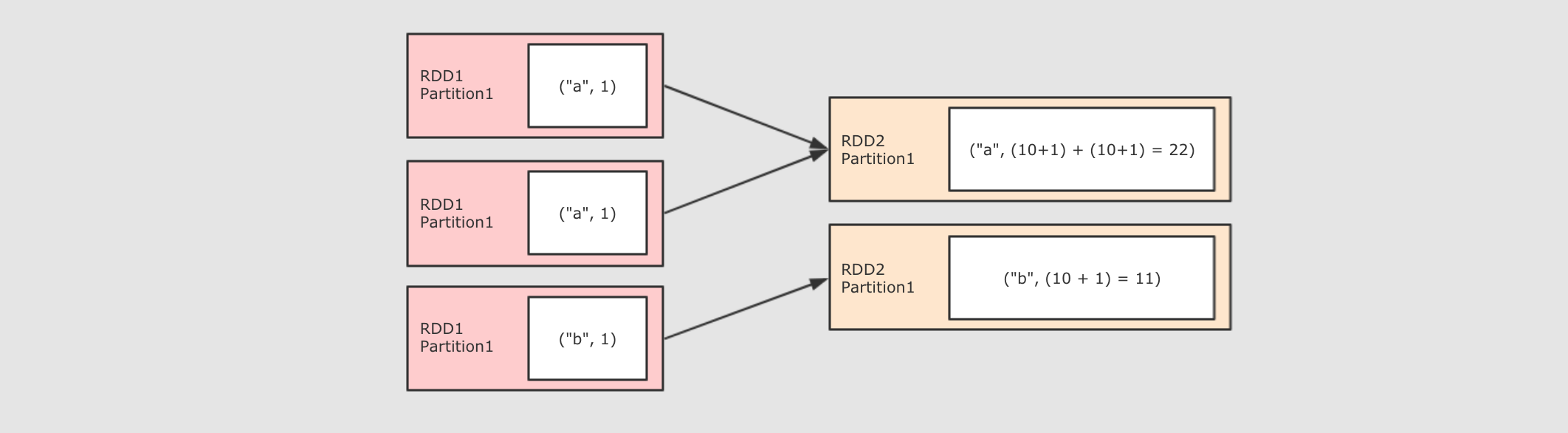
| reduceByKey((V, V) ⇒ V, numPartition)
|
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.reduceByKey( (curr, agg) => curr + agg )
.collect()


作用
调用 def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)]
参数
-
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
注意点
-
ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
-
ReduceByKey 是一个需要 Shuffled 的操作
-
和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
|
|---|
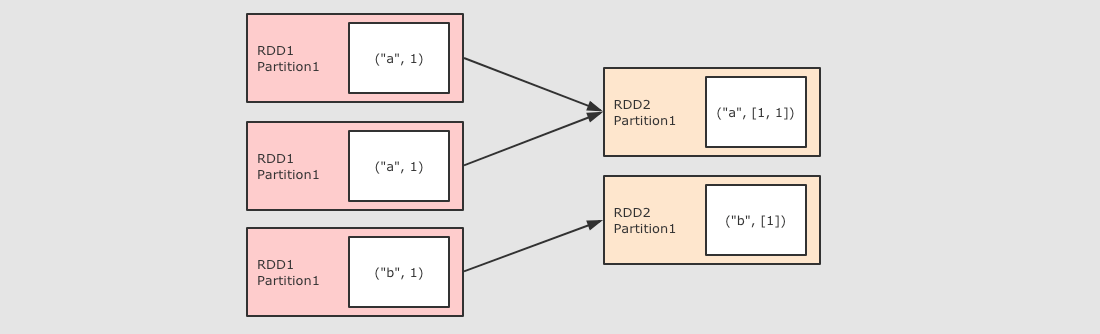
| groupByKey()
|
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.groupByKey()
.collect()


scala> sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))).groupByKey().collect
res33: Array[(String, Iterable[Int])] = Array((a,CompactBuffer(1, 1)), (b,CompactBuffer(1))) scala> sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))).groupByKey().mapValues(_.reduce(_+_)).collect
res34: Array[(String, Int)] = Array((a,2), (b,1)) 作用
注意点
-
GroupByKey 是一个 Shuffled
-
GroupByKey 和 ReduceByKey 不同, 因为需要列举 Key 对应的所有数据, 所以无法在 Map 端做 Combine, 所以 GroupByKey 的性能并没有 ReduceByKey 好
|
|---|
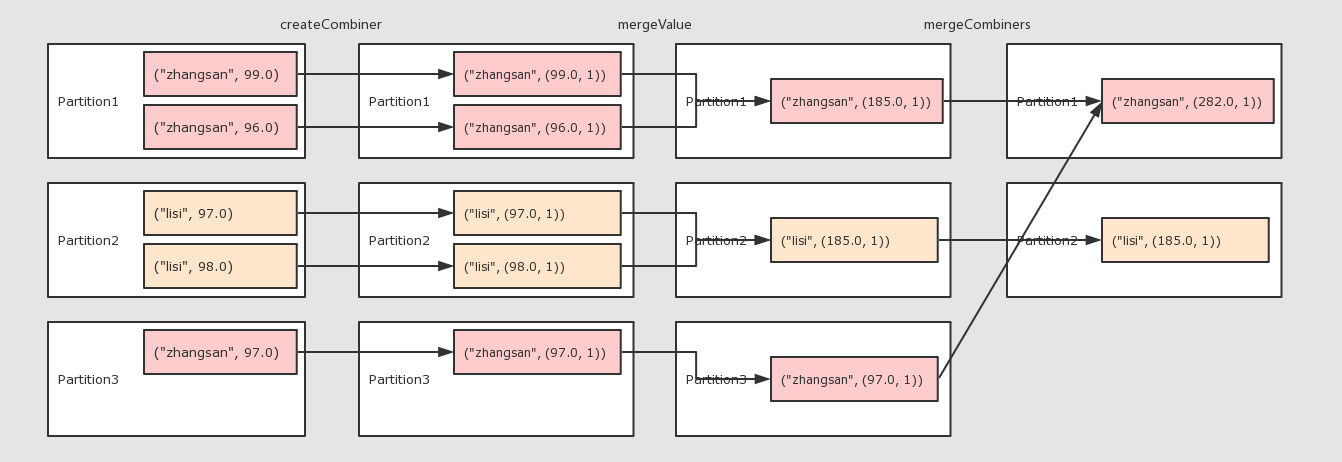
| combineByKey()
|
val rdd = sc.parallelize(Seq(
("zhangsan", 99.0),
("zhangsan", 96.0),
("lisi", 97.0),
("lisi", 98.0),
("zhangsan", 97.0))
)
val combineRdd = rdd.combineByKey(
score => (score, 1),
(scoreCount: (Double, Int),newScore) => (scoreCount._1 + newScore, scoreCount._2 + 1),
(scoreCount1: (Double, Int), scoreCount2: (Double, Int)) =>
(scoreCount1._1 + scoreCount2._1, scoreCount1._2 + scoreCount2._2)
)
val meanRdd = combineRdd.map(score => (score._1, score._2._1 / score._2._2))
meanRdd.collect()

作用
调用
-
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数
-
createCombiner 将 Value 进行初步转换
-
mergeValue 在每个分区把上一步转换的结果聚合
-
mergeCombiners 在所有分区上把每个分区的聚合结果聚合
-
partitioner 可选, 分区函数
-
mapSideCombiner 可选, 是否在 Map 端 Combine
-
serializer 序列化器
注意点
|
|---|
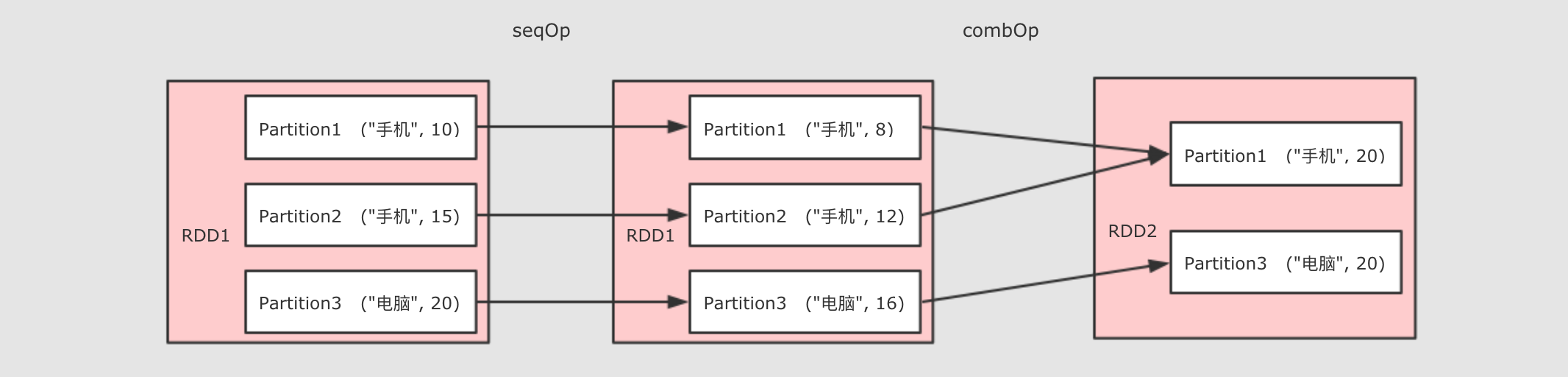
| aggregateByKey()
|
val rdd = sc.parallelize(Seq(("手机", 10.0), ("手机", 15.0), ("电脑", 20.0)))
val result = rdd.aggregateByKey(0.8)(
seqOp = (zero, price) => price * zero,
combOp = (curr, agg) => curr + agg
).collect()
println(result)

作用
调用
参数
-
zeroValue 初始值
-
seqOp 转换每一个值的函数
-
comboOp 将转换过的值聚合的函数
注意点 * 为什么需要两个函数? aggregateByKey 运行将一个 RDD[(K, V)] 聚合为 RDD[(K, U)], 如果要做到这件事的话, 就需要先对数据做一次转换, 将每条数据从 V 转为 U, seqOp 就是干这件事的 ** 当 seqOp 的事情结束以后, comboOp 把其结果聚合
|
|---|
| foldByKey(zeroValue)((V, V) ⇒ V)
|
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.foldByKey(zeroValue = 10)( (curr, agg) => curr + agg )
.collect()


作用
调用 foldByKey(zeroValue)(func)
参数
注意点
|
|---|
| join(other, numPartitions)
|
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12)))
rdd1.join(rdd2).collect()

作用
调用 join(other, [partitioner or numPartitions])
参数
注意点
-
Join 有点类似于 SQL 中的内连接, 只会再结果中包含能够连接到的 Key
-
Join 的结果是一个笛卡尔积形式, 例如 "a", 1), ("a", 2 和 "a", 10), ("a", 11 的 Join 结果集是 "a", 1, 10), ("a", 1, 11), ("a", 2, 10), ("a", 2, 11
|
|---|
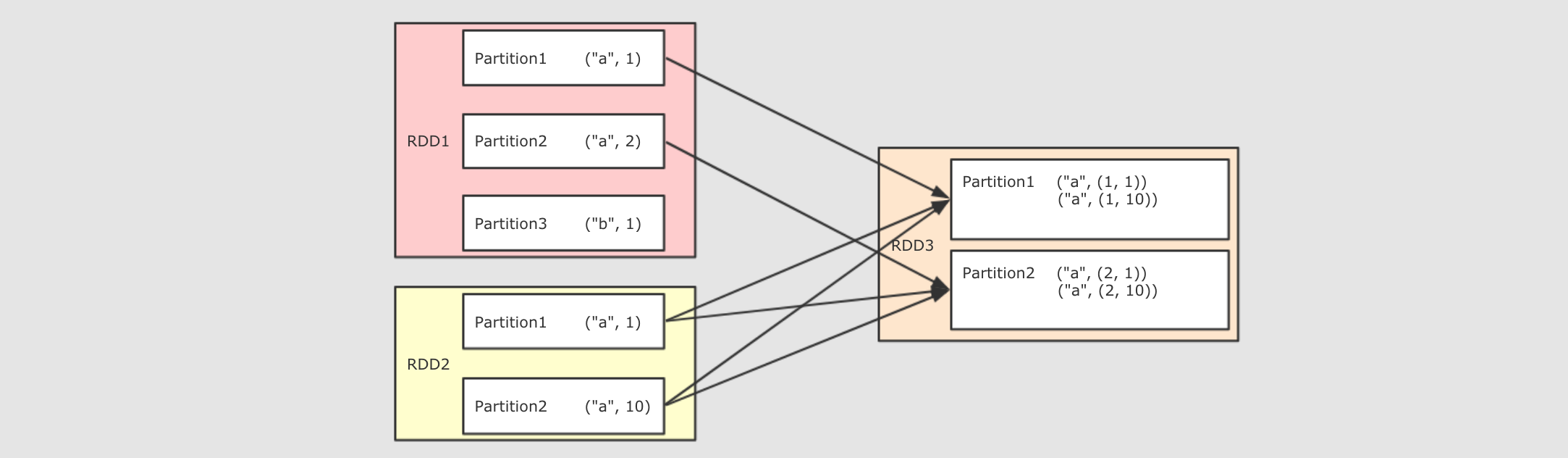
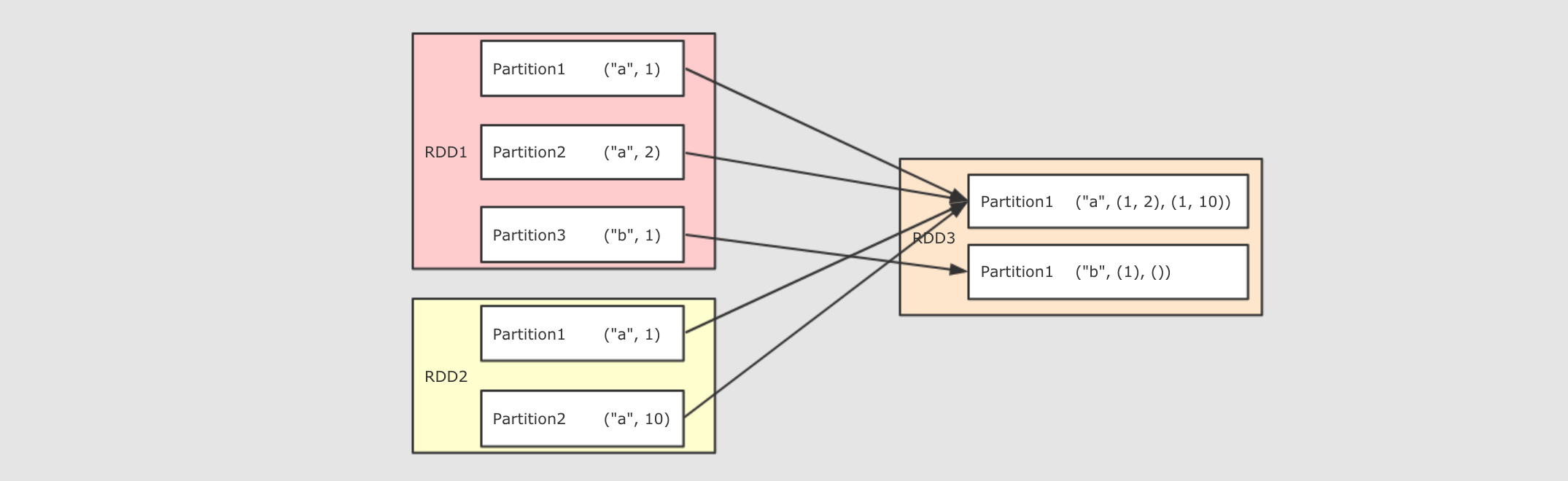
| cogroup(other, numPartitions)
|
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 5), ("b", 2), ("b", 6), ("c", 3), ("d", 2)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("b", 1), ("d", 3)))
val rdd3 = sc.parallelize(Seq(("b", 10), ("a", 1)))
val result1 = rdd1.cogroup(rdd2).collect()
val result2 = rdd1.cogroup(rdd2, rdd3).collect()
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3))),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10))),
(b,(CompactBuffer(2, 6),CompactBuffer(1))),
(c,(CompactBuffer(3),CompactBuffer()))
)
*/
println(result1)
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3),CompactBuffer())),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10),CompactBuffer(1))),
(b,(CompactBuffer(2, 6),CompactBuffer(1),Co...
*/
println(result2)

作用
调用
参数
-
rdd… 最多可以传三个 RDD 进去, 加上调用者, 可以为四个 RDD 协同分组
-
partitioner or numPartitions 可选, 可以通过传递分区函数或者分区数来改变分区
注意点
-
对 RDD1, RDD2, RDD3 进行 cogroup, 结果中就一定会有三个 List, 如果没有 Value 则是空 List, 这一点类似于 SQL 的全连接, 返回所有结果, 即使没有关联上
-
CoGroup 是一个需要 Shuffled 的操作
|
|---|
| cartesian(other)
|
(RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成两个 RDD 的笛卡尔积 |
|---|
| sortBy(ascending, numPartitions)
|
val rdd1 = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1)))
val sortByResult = rdd1.sortBy( item => item._2 ).collect()
val sortByKeyResult = rdd1.sortByKey().collect()
println(sortByResult)
println(sortByKeyResult)
作用
调用 sortBy(func, ascending, numPartitions)
参数
-
func 通过这个函数返回要排序的字段
-
ascending 是否升序
-
numPartitions 分区数
注意点
-
普通的 RDD 没有 sortByKey, 只有 Key-Value 的 RDD 才有
-
sortBy 可以指定按照哪个字段来排序, sortByKey 直接按照 Key 来排序
|
|---|
| partitionBy(partitioner)
|
使用用传入的 partitioner 重新分区, 如果和当前分区函数相同, 则忽略操作 |
|---|
| coalesce(numPartitions)
|
减少分区数 val rdd = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1)))
val oldNum = rdd.partitions.length
val coalesceRdd = rdd.coalesce(4, shuffle = true)
val coalesceNum = coalesceRdd.partitions.length
val repartitionRdd = rdd.repartition(4)
val repartitionNum = repartitionRdd.partitions.length
print(oldNum, coalesceNum, repartitionNum)
作用
调用
参数
注意点
|
|---|
| repartition(numPartitions)
|
重新分区 |
|---|
| repartitionAndSortWithinPartitions
|
重新分区的同时升序排序, 在 partitioner 中排序, 比先重分区再排序要效率高, 建议使用在需要分区后再排序的场景使用 |
|---|