
1 内容介绍
提出一种基于K-Means聚类的麻雀算法,该算法利用麻雀算法鲁棒性较强且不易陷入局部最优值的特点,动态的确定了聚类的数目和中心,解决了K-Means聚类初始点选择不稳定的缺陷,在此两种算法融合的基础上进行图像分割处理,经试验证明该算法效果理想.
2 仿真代码
%_________________________________________________________________________%
% 麻雀优化算法 %
%_________________________________________________________________________%
function [Best_pos,Best_score,curve]=SSA(pop,Max_iter,lb,ub,dim,fobj)
ST = 0.6;%预警值
PD = 0.7;%发现者的比列,剩下的是加入者
SD = 0.2;%意识到有危险麻雀的比重
PDNumber = pop*PD; %发现者数量
SDNumber = pop - pop*PD;%意识到有危险麻雀数量
if(max(size(ub)) == 1)
ub = ub.*ones(1,dim);
lb = lb.*ones(1,dim);
end
%种群初始化
X0=initialization(pop,dim,ub,lb);
X = X0;
%计算初始适应度值
fitness = zeros(1,pop);
for i = 1:pop
fitness(i) = fobj(X(i,:));
end
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
GBestF = fitness(1);%全局最优适应度值
for i = 1:pop
X(i,:) = X0(index(i),:);
end
curve=zeros(1,Max_iter);
GBestX = X(1,:);%全局最优位置
X_new = X;
for i = 1: Max_iter
BestF = fitness(1);
WorstF = fitness(end);
R2 = rand(1);
for j = 1:PDNumber
if(R2<ST)
X_new(j,:) = X(j,:).*exp(-j/(rand(1)*Max_iter));
else
X_new(j,:) = X(j,:) + randn()*ones(1,dim);
end
end
for j = PDNumber+1:pop
% if(j>(pop/2))
if(j>(pop - PDNumber)/2 + PDNumber)
X_new(j,:)= randn().*exp((X(end,:) - X(j,:))/j^2);
else
%产生-1,1的随机数
A = ones(1,dim);
for a = 1:dim
if(rand()>0.5)
A(a) = -1;
end
end
AA = A'*inv(A*A');
X_new(j,:)= X(1,:) + abs(X(j,:) - X(1,:)).*AA';
end
end
Temp = randperm(pop);
SDchooseIndex = Temp(1:SDNumber);
for j = 1:SDNumber
if(fitness(SDchooseIndex(j))>BestF)
X_new(SDchooseIndex(j),:) = X(1,:) + randn().*abs(X(SDchooseIndex(j),:) - X(1,:));
elseif(fitness(SDchooseIndex(j))== BestF)
K = 2*rand() -1;
X_new(SDchooseIndex(j),:) = X(SDchooseIndex(j),:) + K.*(abs( X(SDchooseIndex(j),:) - X(end,:))./(fitness(SDchooseIndex(j)) - fitness(end) + 10^-8));
end
end
%边界控制
for j = 1:pop
for a = 1: dim
if(X_new(j,a)>ub)
X_new(j,a) =ub(a);
end
if(X_new(j,a)<lb)
X_new(j,a) =lb(a);
end
end
end
%更新位置
for j=1:pop
fitness_new(j) = fobj(X_new(j,:));
end
for j = 1:pop
if(fitness_new(j) < GBestF)
GBestF = fitness_new(j);
GBestX = X_new(j,:);
end
end
X = X_new;
fitness = fitness_new;
%排序更新
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
for j = 1:pop
X(j,:) = X(index(j),:);
end
curve(i) = GBestF;
end
Best_pos =GBestX;
Best_score = curve(end);
end
3 运行结果
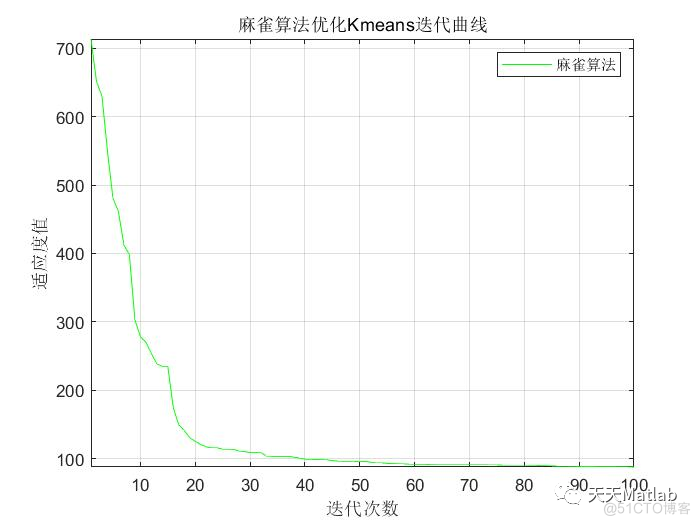







4 参考文献
[1]杨雨航. "动态粒子群优化K-means的图像分割算法研究." 现代计算机 8(2019):5.
[2]张宏峰, 倪受东, 赵亮,等. 基于麻雀搜索算法的摄像机标定优化方法[J]. 激光与光电子学进展, 2021, 58(22):2215004.
[3]李志杰, 王力, 张习恒. 改进樽海鞘群优化K-means算法的图像分割[J]. 包装工程, 2022, 43(9):10.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。


















