
前言
大家好,本篇我们主要分享数据结构中最基础的两种数据结构数组和链表,我们话不多开,正文开始!
正文
数组
我们先来说说数组结构,什么是数组?数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
线性表数据结构:就是数据排列像一条线一样的结构,只有前后的方向,
连续的内存空间:就是存储数据在内存中的地址是连续的,例如存储一个长度为3的整数int[3]数组,int类型数据在内存中占4个字节,所以数组的起止地址为1000~1003,1004~1007,1008~1010是连续的。
数组优点:
随机访问,通过索引访问数组数据,由于是连续的内存空间,所以支持随机访问,通过下标随机访问的时间复杂度是O(1)。
查找快,可以通过数组的所以快速定位到要查找的数据
支持动态扩容,当我们开始预定义数组的长度是10,当数组存储了10个数据后,我们继续添加第11个数据的时候,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入
数组缺点:
插入、删除数据慢,因为数组连续的内存空间,所以在插入一个数据的时候会使插入位置后面的每个数据都向后位移一个位置,所以比较低效,删除同理,会使删除位置之后的每个数据向前位移一个。
操作不当会引起数组的访问越界问题,比如我定义的数组长度是10,索引长度从0~9,但是当我访问位置10的时候,超过数组长度,所以会发生越界问题
查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间。
删除和添加某个元素时,同样需要耗费 O(n) 的时间
习题练习
数组介绍基本就这些了,虽然数组比较简单,但确是面试中最容易的超高频数据结构,我找了几个在经常在面试中出现的题目,下面和大家分享一下
/** * LeetCode344题目描述: * 输入字符数组 char[a,b,c,d] ,输出字符数组cahr[d,c,b,a],实现数组翻转 * 不要给另外的数组分配额外的空间,你必须原地修改输入数组、 * 使用 O(1) 的额外空间解决这一问题 * 解题思路: * 两个指针,一个指向字符串的第一个字符 a,一个指向它的最后一个字符 d, * 然后互相交换。交换之后,两个指针向中央一步步地靠拢并相互交换字符,直到两个指针相遇。 * */public class CharDemo1 { public static void main(String[] args) { char[] arr={'a','b','c','d'}; char[] reverse = reverse(arr); //输出reverse打印出d c b a System.out.println(reverse); } //left就是左指针,right是右指针 public static char[] reverse(char[] arr){ int size=arr.length; for (int left = 0, right = size-1; left < right; ++left, --right) { char tmp = arr[left]; arr[left] = arr[right]; arr[right] = tmp; } return arr; }}链表
相比数组,链表是有一系列不必在内存中连续的结构组成,是一种稍微复杂一点的数据结构。但是他和数组都是面试中经常出现的,先来说说什么是链表?与数组相比,数组需要一块连续的内存空间来存储,假如申请100MB大小的数组,但是连续内存空间不够,就无法创建数组,但是链表并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请 100MB内存空间如果不是连续的内存空间,就是可以的。
所以链表是通过指针将一组零散的内存块串联在一起的一种数据结构,链表又分为:单链表、双向链表和循环链表。我们首先来看最简单、最常用的单链表。
单链表结构:
单链表每一个节点均包含数据元素和指向下一个节点的指针元素,指针元素存储的是下一个节点的地址信息,最后一个节点的next指针指向NULL,类似下图结构:
我们把第一个结点叫作头结点,把最后一个结点叫作尾结点。
插入节点和删除节点图如下:
单链表优点:
插入和删除快,和数组相比,链表的插入和删除不需要其他的节点的位移,我们只需要修改节点之间的next指针指向,就可以完成插入和删除,时间复杂度已经是 O(1)
链表能灵活地分配内存空间。
单链表缺点:
查询相比数组低效,因为链表的内存地址不是连续的,所以不能像数组一样通过索引随机访问,所以链表在查找某个节点时候只能通过从头遍历链表节点来查找。
查询第 n 个元素需要 O(n) 时间
双向链表结构:
与单点链表相比,双向链表增加了一个指向前面节点的pre指针,同事需要额外的一个空间来存储前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间,双向链表结构如下:
双向链表优点:
支持双向遍历,双向链表增加了操作的灵活性
循环链表结构:
单链表的循环链表结构就是在单链表的基础上将尾节点的next指针指向头节点
也可以是双向循环链表,头节点的pre指针指向尾节点,尾节点的next指针指向头节点。
循环链表的优点是从链尾到链头比较方便,一般用于处理具有循环结构的数据时采用循环列表。
单链表和双向链表的对比:
查询对比:查询某个元素的时间复杂度都是O(n),都需要从头或者从尾开始遍历链表。
删除某个元素的时候,单链表第一次查询找到该元素,但是他不能控制前一个节点的next的指向,例如删除q节点,为了找到前驱结点,我们还是要从头结点开始遍历链表,直到 p->next=q,然后通过修改p节点的next指针指向被删除节点q的next指针指向的节点。然而双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度内就可以搞定,插入操作同理,单链表时间复杂度是O(n),双链表是O(1)。
如果都是有序的链表查找,就查找速率而言,双向链表也比但链表要高,因为双向链表可以记录上次的查询值,通过对比值的大小,通过前驱指针和后驱指针双向遍历,但是但链表只能从头遍历。
习题练习
LeetCode第25题,链表翻转,以下解题思路和图来自力扣,附加一些本盟主的理解和注释,方便大家更好的理解。题目描述:给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。代码如下:
package com.example.demo.testdemo.listdemo;import java.util.HashMap;/*** 解题思路:* 1.链表分为已翻转区,待翻转区,未翻转区* 2.每次翻转前,需要通过k值确定翻转的范围* 3.需要记录翻转的前驱和后继,以便翻转完后,把已翻转的和未翻转的连接起来* 4.初始化需要两个变量,pre和end,pre代表翻转链表的前驱,end代表翻转链表的后继* 5.通过k次循环,end到达末尾,记录带翻转的末尾next=end.next。* 6.翻转列表,将三部分连接起来,重置pre和end的指针,然后进入下一次翻转* 7.特殊情况,当翻转部分长度不足k时,在定位end完成后end==null已经到达末尾,说明题目已完成,直接返回即可* 8.时间复杂度为 O(n*K) 最好的情况为 O(n) 最差的情况为O(n^2)O* 9.空间复杂度为O(1);*/public class demo1 {public static void main(String[] args) {//我们先定义单链表结构1->2->3->4->5->null,那么如果k传2,// 最终返回的结构就是2->1->4->3->5ListNode listNode1=new ListNode(1);ListNode listNode2=new ListNode(2);ListNode listNode3=new ListNode(3);ListNode listNode4=new ListNode(4);ListNode listNode5=new ListNode(5);listNode1.next=listNode2;listNode2.next=listNode3;listNode3.next=listNode4;listNode4.next=listNode5;listNode5.next=null;//返回的listNode,结构2->1->4->3->5,我们先看reserveGroup方法ListNode listNode = reserveGroup(listNode1, 2);}
以下图解均来自leetCode,我把图分开来解释,方便大家理解。
图1:

图2:

图3:

图4:

图5:

图6:
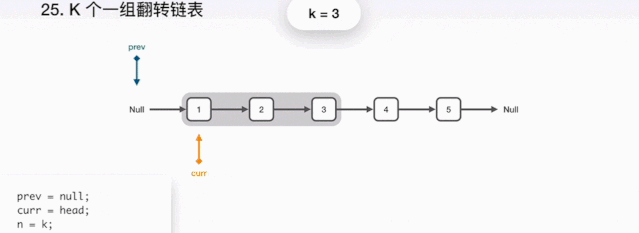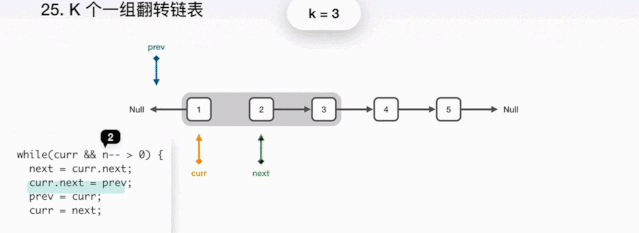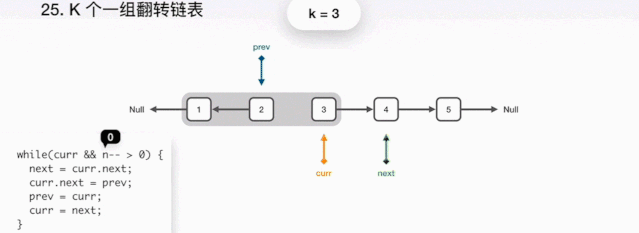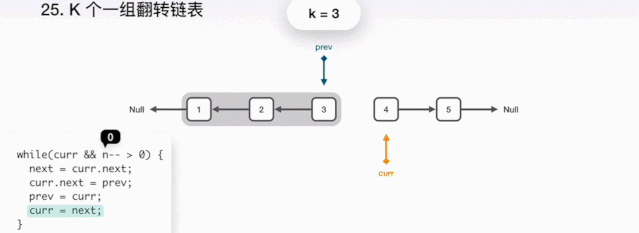
public static ListNode reserveGroup(ListNode head,int k){//dummy保存链表head的前驱节点ListNode dummy=new ListNode(0);//讲dummy的next节点指向head,此时链表结构dummy->1->2->3->4->5dummy.next=head;//初始化pre和end指针的位置,如 **图1**ListNode pre = dummy;ListNode end = dummy;//每次循环,判断end后面还有节点,才有继续翻转的可能。while(end.next != null){//看end后继节点是不是够k个,并且每次循环end指针向后移动,// k次之后end指向3,如 **图2**for(int i=0;i<k && end != null; i++){end=end.next;}//如果end为空,说明链表的长度不够k个,不需要翻转直接跳出循环if(end == null){break;}//记录开始翻转的位置ListNode start = pre.next;//保存翻转之后的后继节点ListNode next=end.next;//将要翻转的链表的后继节点置空,如**图3**end.next=null;//翻转链表ListNode reverse = reverse(start);//连接前驱节点和后继节点,如**图4**,**图5**pre.next=reverse;start.next=next;//重置pre和end的位置,准备开始下一轮翻转,如**图5**,然后开始下一轮的翻转pre=start;end=pre;}//返回翻转完后链表的头节点return dummy.next;}//翻转方法,通过三个指针,pre、cu人、next指针进行翻转,这个通过网上找的**图6**,// 来给大家解释,图中的意思就是代码描述的意思,翻转本身并不复杂。public static ListNode reverse(ListNode head){ListNode pre =null;ListNode cur=head;while (cur != null){ListNode next=cur.next;cur.next=pre;pre=cur;cur=next;}return pre;}//我们定义简单的链表结构,每个节点有节点的data和节点的后继节点next组成static class ListNode{int data;ListNode next;ListNode(int data){this.data=data;}}}
总结
本期我们主要讲解了数组和链表的基本结构和简单的一些对比,通过一些面试经常问的算法题让大家对其结构能有更加深入的理解,有关数组和链表的算法题还有很多,感兴趣的同学可以多去leetCode刷刷题,那么,我们下期见!


















