
1.5 Vedio: Supervised Learning
In this video, I'm going to define what is probably the most common type of Machine Learning problem, which is Supervised Learning. I'll define Supervised Learning more formally later, but it's probably best to explain or start with an example of what it is, and we'll do the formal definition later.
Let's say you want to predict housing prices. A while back a student collected data sets from the City of Portland, Oregon, and let's say you plot the data set and it looks like this.

Here on the horizontal axis, the size of different houses in square feet, and on the vertical axis, the price of different houses in thousands of dollars. So, given this data, let's say you have a friend who owns a house that is say 750 square feet, and they are hoping to sell the house, and they want to know how much they can get for the house.
So, how can the learning algorithm help you? One thing a learning algorithm might be want to do is put a straight line through the data, also fit a straight line to the data. Based on that, it looks like maybe their house can be sold for maybe about \$150,000. But maybe this isn't the only learning algorithm you can use, and there might be a better one.
For example, instead of fitting a straight line to the data, we might decide that it's better to fit a quadratic function, or a second-order polynomial to this data. If you do that and make a prediction here, then it looks like, well, maybe they can sell the house for closer to $200,000.
One of the things we'll talk about later is how to choose, and how to decide, do you want to fit a straight line to the data? Or do you want to fit a quadratic function to the data? There's no fair picking whichever one gives your friend the better house to sell. But each of these would be a fine example of a learning algorithm.
So, this is an example of a Supervised Learning algorithm. The term Supervised Learning refers to the fact that we gave the algorithm a data set in which the, called, "right answers" were given. That is we gave it a data set of houses in which for every example in this data set, we told it what is the right price. So, what was the actual price that that house sold for, and the task of the algorithm was to just produce more of these right answers such as for this new house that your friend may be trying to sell.
To define a bit more terminology, this is also called a regression problem. By regression problem, I mean we're trying to predict a continuous valued output. Namely the price. So technically, I guess prices can be rounded off to the nearest cent. So, maybe prices are actually discrete value. But usually, we think of the price of a house as a real number, as a scalar value, as a continuous value number, and the term regression refers to the fact that we're trying to predict the sort of continuous values attribute.
Here's another Supervised Learning examples. Some friends and I were actually working on this earlier.
Let's say you want to look at medical records and try to predict of a breast cancer as malignant or benign. If someone discovers a breast tumor, a lump in their breast, a malignant tumor is a tumor that is harmful and dangerous, and a benign tumor is a tumor that is harmless. So obviously, people care a lot about this.

Let's see collected data set. Suppose you are in your dataset, you have on your horizontal axis the size of the tumor, and on the vertical axis, I'm going to plot one or zero, yes or no, whether or not these are examples of tumors we've seen before are malignant, which is one, or zero or not malignant or benign. So, let's say your dataset looks like this, where we saw a tumor of this size that turned out to be benign, one of this size, one of this size, and so on.
Sadly, we also saw a few malignant tumors cell, one of that size, one of that size, one of that size, so on. So in this example, I have five examples of benign tumors shown down here, and five examples of malignant tumors shown with a vertical axis value of one. Let's say a friend who tragically has a breast tumor, and let's say her breast tumor size is maybe somewhere around this value, the Machine Learning question is, can you estimate what is the probability, what's the chance that a tumor as malignant versus benign?
To introduce a bit more terminology, this is an example of a classification problem. The term classification refers to the fact, that here, we're trying to predict a discrete value output zero or one, malignant or benign. It turns out that in classification problems, sometimes you can have more than two possible values for the output. As a concrete example, maybe there are three types of breast cancers. So, you may try to predict a discrete value output zero, one, two, or three, where zero may mean benign, benign tumor, so no cancer, and one may mean type one cancer, maybe three types of cancer, whatever type one means, and two mean a second type of cancer, and three may mean a third type of cancer. But this will also be a classification problem because this are the discrete value set of output corresponding to you're no cancer, or cancer type one, or cancer type two, or cancer types three.
Bottom of the previous picture
In classification problems, there is another way to plot this data. Let me show you what I mean. I'm going to use a slightly different set of symbols to plot this data. So, if tumor size is going to be the attribute that I'm going to use to predict malignancy or benignness, I can also draw my data like this. I'm going to use different symbols to denote my benign and malignant, or my negative and positive examples.
So, instead of drawing crosses, I'm now going to draw O's for the benign tumors, like so, and I'm going to keep using X's to denote my malignant tumors. I hope this figure makes sense. All I did was I took my data set on top, and I just mapped it down to this real line like so, and started to use different symbols, circles and crosses to denote malignant versus benign examples.
Now, in this example, we use only one feature or one attribute, namely the tumor size in order to predict whether a tumor is malignant or benign. In other machine learning problems, when we have more than one feature or more than one attribute. Here's an example, let's say that instead of just knowing the tumor size, we know both the age of the patients and the tumor size.

In that case, maybe your data set would look like this, where I may have a set of patients with those ages, and that tumor size, and they look like this, and different set of patients that look a little different, whose tumors turn out to be malignant as denoted by the crosses. So, let's say you have a friend who tragically has a tumor, and maybe their tumor size and age falls around there. So, given a data set like this, what the learning algorithm might do is fit a straight line to the data to try to separate out the malignant tumors from the benign ones, and so the learning algorithm may decide to put a straight line like that to separate out the two causes of tumors. With this, hopefully we can decide that your friend's tumor is more likely, if it's over there that hopefully your learning algorithm will say that your friend's tumor falls on this benign side and is therefore more likely to be benign than malignant.
In this example, we had two features namely, the age of the patient and the size of the tumor. In other Machine Learning problems, we will often have more features. My friends that worked on this problem actually used other features like these, which is clump thickness, clump thickness of the breast tumor, uniformity of cell size of the tumor, uniformity of cell shape the tumor, and so on, and other features as well. It turns out one of the most interesting learning algorithms that we'll see in this course, as the learning algorithm that can deal with not just two, or three, or five features, but an infinite number of features.
On this slide, I've listed a total of five different features. Two on the axis and three more up here. But it turns out that for some learning problems what you really want is not to use like three or five features, but instead you want to use an infinite number of features, an infinite number of attributes, so that your learning algorithm has lots of attributes, or features, or cues with which to make those predictions.
So, how do you deal with an infinite number of features? How do you even store an infinite number of things in the computer when your computer is going to run out of memory? It turns out that when we talk about an algorithm called the Support Vector Machine, there will be a neat mathematical trick that will allow a computer to deal with an infinite number of features. Imagine that I didn't just write down two features here and three features on the right, but imagine that I wrote down an infinitely long list. I just kept writing more and more features, like an infinitely long list of features. It turns out we will come up with an algorithm that can deal with that.
So, just to recap, in this course, we'll talk about Supervised Learning, and the idea is that in Supervised Learning, in every example in our data set, we are told what is the correct answer that we would have quite liked the algorithms have predicted on that example. Such as the price of the house, or whether a tumor is malignant or benign.
We also talked about the regression problem, and by regression that means that our goal is to predict a continuous valued output. We talked about the classification problem where the goal is to predict a discrete value output.

Just a quick wrap up question. Suppose you're running a company and you want to develop learning algorithms to address each of two problems. In the first problem, you have a large inventory of identical items. So, imagine that you have thousands of copies of some identical items to sell, and you want to predict how many of these items you sell over the next three months. In the second problem, problem two, you have lots of users, and you want to write software to examine each individual of your customer's accounts, so each one of your customer's accounts. For each account, decide whether or not the account has been hacked or compromised.
So, for each of these problems, should they be treated as a classification problem or as a regression problem? When the video pauses, please use your mouse to select whichever of these four options on the left you think is the correct answer.
So hopefully, you got that. This is the answer. For problem one, I would treat this as a regression problem because if I have thousands of items, well, I would probably just treat this as a real value, as a continuous value. Therefore, the number of items I sell as a continuous value. For the second problem, I would treat that as a classification problem, because I might say set the value I want to predict with zero to denote the account has not been hacked, and set the value one to denote an account that has been hacked into. So, just like your breast cancers where zero is benign, one is malignant. So, I might set this be zero or one depending on whether it's been hacked, and have an algorithm try to predict each one of these two discrete values. Because there's a small number of discrete values, I would therefore treat it as a classification problem. So, that's it for Supervised Learning.
In the next video, I'll talk about Unsupervised Learning, which is the other major category of learning algorithm.
unfamiliar words
-
a while back 不久前
I gave it up as well, a while back. 我也放弃了,不久前。 -
quadratic [kwɒˈdrætɪk] adj.平方的;
exp: ADJ involving an unknown quantity that is multiplied by itself once only
a quadratic equation
二次方程式 -
polynomial [ˌpɒli'nəʊmiəl] adj.多项式的 n. 多项式;
A complete quartic polynomial consists of 15 terms.
一个完整四次的多项式由15项组成。 -
no fair [noʊ fer] 不公平的 没有合理的
Life is no fair, get used to it.
生活是不公平的,要学会适应 -
regression [rɪˈɡreʃn] n. 回归
Multiple Linear Regression Model of the Real Estate Market in China
中国房地产价格的多元线性回归模型 -
Estate [ɪˈsteɪt] n. 住宅 住宅区
-
round adj. 圆形的,整数的 n. 局,轮
-
rounded off PHRASAL VERB 使…圆满结束
The performance was rounded off with a one act play.
演出以一个独幕剧圆满结束。 -
discrete [dɪˈskriːt] adj. 离散的; 分离的
Social structures are not discrete objects; they overlap and interweave.
社会结构之间不是离散的,他们相互重叠交织。 -
cent [sent] n. 分币
-
scalar [ˈskeɪlə(r)] adj.标量的;无向量的 n.数量,标量
The quality is called value, which is a scalar.
评估卡组性能的指标是一维的,被称为“价值”。 -
breast cancer [brest ˈkænsər] n. 乳腺癌
Breast cancer is the most common form of cancer among women in this country.
乳腺癌是这个国家妇女中最常见的一种癌症。 -
malignant [məˈlɪɡnənt] adj.恶性的;恶意的;恶毒的
exp: ADJ that cannot be controlled and is likely to cause death
malignant cells
恶性癌细胞 -
benign [bɪˈnaɪn] adj. 温和的;良性的;
It wasn't cancer, only a benign tumour.
这不是癌症,只是良性肿瘤。 -
lump [lʌmp] n. 肿块 ,哽咽(激动的)
He was unhurt apart from a lump on his head.
除了头上起了个包,他没有别的伤。
I stood there with a lump in my throat and tried to fight back tears...
我站在那里,喉咙哽塞,拼命想止住眼泪。 -
corresponding [ˌkɒrəˈspɒndɪŋ] adj. 符合的;相应的;相关的
Give each picture a number corresponding to its position on the page.
按所在页面位置给每一幅画编上相对应的号码。 -
denote [dɪˈnəʊt] v. 标志;预示;
exp: VERB to be a sign of sth
A very high temperature often denotes a serious illness.
高烧常常说明病得很重。 -
uniformity [ˌjuːnɪˈfɔːməti] n.统一(性);一致(性);规则(性)
They tried to ensure uniformity across the different departments.
他们努力保证各部门之间的统一。 -
clump [klʌmp] n. (尤指树或植物的)丛,簇,束,串;
a clump of trees/bushes
树 / 灌木丛 -
cue [kjuːz] n. 暗示;提示;信号;
The actors not performing sit at the side of the stage in full view, waiting for their cues...
还未轮到演出的演员坐在舞台旁边能看得一清二楚的地方,等待着他们的出场提示。 -
neat [niːt] n.整洁的;整齐的;
exp: N tidy and in order; carefully done or arranged
a neat desk
整洁的课桌 -
recap [ˈriːkæp] v.概括;扼要重述;简要回顾
Let me just recap on what we've decided so far.
让我来概括一下到目前为止我们所作的决定吧。 -
wrap up p.v. 包,裹;穿得暖和;圆满完成
exp: If you wrap up something such as a job or an agreement, you complete it in a satisfactory way.
NATO defense ministers wrap up their meeting in Brussels today...
北约各国国防部长今天圆满结束了在布鲁塞尔的会议。 -
inventory [ˈɪnvəntri] n. 库存,存货 财产清单
inventory control
库存管理 -
identical [aɪˈdentɪkl] adj. 完全相同的
a row of identical houses
完全一样的一排房子
1.6 Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
unfamiliar words
-
categorize [ˈkætəɡəraɪz] vt. 分类;将…分类;把…加以归类
His latest work cannot be categorized as either a novel or an autobiography.
他最近的作品既不属于小说也不属于自传。 -
intead [ɪnˈsted] adv. 相反;代替;反而;顶替;却
Lee was ill so I went instead.
李病了,所以我去了。
He didn't reply. Instead, he turned on his heel and left the room.
他没有回答,反而转身离开了房间。
1.7 Unsupervised Learning
In this video, we'll talk about the second major type of machine learning problem, called Unsupervised Learning. In the last video, we talked about Supervised Learning.

Back then, recall data sets that look like this, where each example was labeled either as a positive or negative example, whether it was a benign or a malignant tumor. So for each example in Supervised Learning, we were told explicitly what is the so-called right answer, whether it's benign or malignant.

In Unsupervised Learning, we're given data that looks different than data that looks like this that doesn't have any labels or that all has the same label or really no labels. So we're given the data set and we're not told what to do with it and we're not told what each data point is. Instead we're just told, here is a data set. Can you find some structure in the data? Given this data set, an Unsupervised Learning algorithm might decide that the data lives in two different clusters. And so there's one cluster and there's a different cluster. And yes, Unsupervised Learning algorithm may break these data into these two separate clusters. So this is called a clustering algorithm.
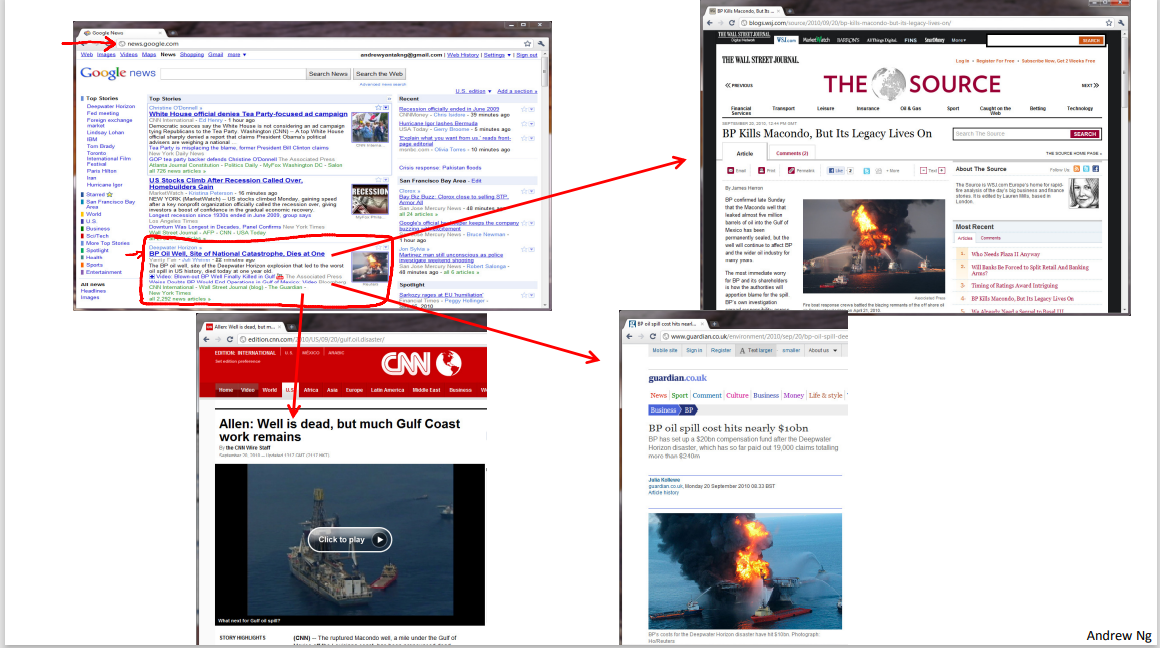
And this turns out to be used in many places. One example where clustering is used is in Google News and if you have not seen this before, you can actually go to this URL news.google.com to take a look. What Google News does is everyday it goes and looks at tens of thousands or hundreds of thousands of new stories on the web and it groups them into cohesive news stories. For example, let's look here. The URLs here link to different news stories about the BP Oil Well story. So, let's click on one of these URL's and we'll click on one of these URL's. What I'll get to is a web page like this. Here's a Wall Street Journal article about, you know, the BP Oil Well Spill stories of "BP Kills Macondo", which is a name of the spill and if you click on a different URL from that group then you might get the different story. Here's the CNN story about a game, the BP Oil Spill, and if you click on yet a third link, then you might get a different story. Here's the UK Guardian story about the BP Oil Spill. So what Google News has done is look for tens of thousands of news stories and automatically cluster them together. So, the news stories that are all about the same topic get displayed together.
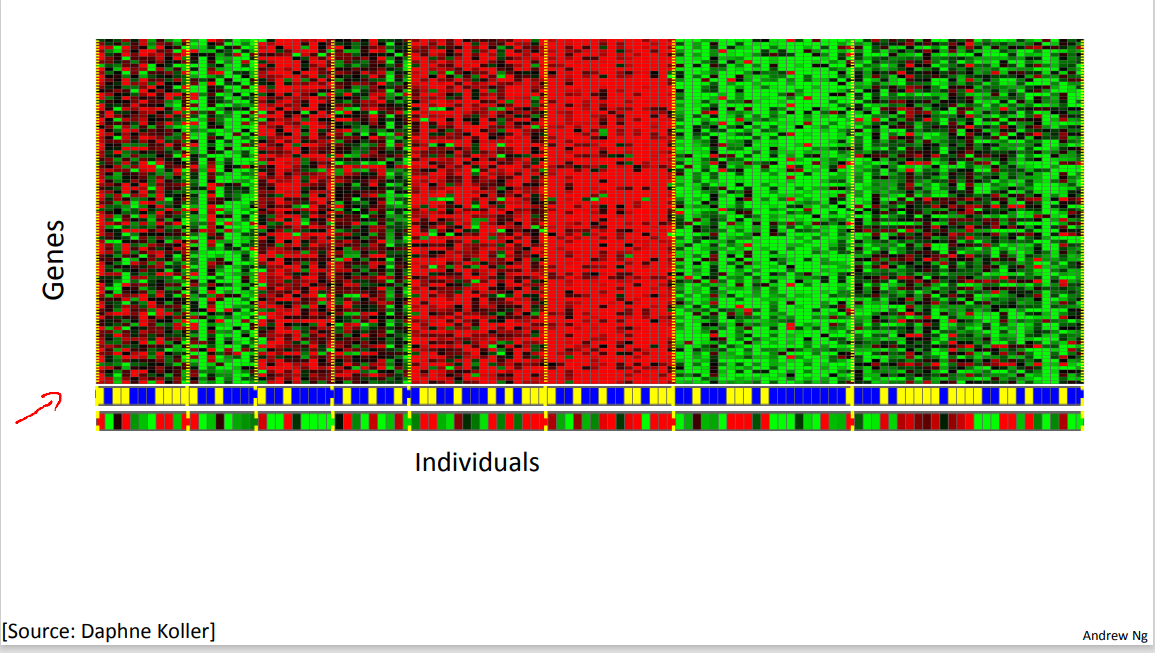
It turns out that clustering algorithms and Unsupervised Learning algorithms are used in many other problems as well. Here's one on understanding genomics. Here's an example of DNA microarray data. The idea is put a group of different individuals and for each of them, you measure how much they do or do not have a certain gene. Technically you measure how much certain genes are expressed. So these colors, red, green, gray and so on, they show the degree to which different individuals do or do not have a specific gene. And what you can do is then run a clustering algorithm to group individuals into different categories or into different types of people.
So this is Unsupervised Learning because we're not telling the algorithm in advance that these are type 1 people, those are type 2 persons, those are type 3 persons and so on and instead what were saying is yeah here's a bunch of data. I don't know what's in this data. I don't know who's and what type. I don't even know what the different types of people are, but can you automatically find structure in the data from the you automatically cluster the individuals into these types that I don't know in advance?
Because we're not giving the algorithm the right answer for the examples in my data set, this is Unsupervised Learning.

Unsupervised Learning or clustering is used for a bunch of other applications. It's used to organize large computer clusters. I had some friends looking at large data centers, that is large computer clusters and trying to figure out which machines tend to work together and if you can put those machines together, you can make your data center work more efficiently.

This second application is on social network analysis. So given knowledge about which friends you email the most or given your Facebook friends or your Google+ circles, can we automatically identify which are cohesive groups of friends, also which are groups of people that all know each other?

Market segmentation. Many companies have huge databases of customer information. So, can you look at this customer data set and automatically discover market segments and automatically group your customers into different market segments so that you can automatically and more efficiently sell or market your different market segments together? Again, this is Unsupervised Learning because we have all this customer data, but we don't know in advance what are the market segments and for the customers in our data set, you know, we don't know in advance who is in market segment one, who is in market segment two, and so on. But we have to let the algorithm discover all this just from the data.

Finally, it turns out that Unsupervised Learning is also used for surprisingly astronomical data analysis and these clustering algorithms gives surprisingly interesting useful theories of how galaxies are formed.
All of these are examples of clustering, which is just one type of Unsupervised Learning. Let me tell you about another one. I'm gonna tell you about the cocktail party problem. So, you've been to cocktail parties before, right? Well, you can imagine there's a party, room full of people, all sitting around, all talking at the same time and there are all these overlapping voices because everyone is talking at the same time, and it is almost hard to hear the person in front of you.

So maybe at a cocktail party with two people, two people talking at the same time, and it's a somewhat small cocktail party. And we're going to put two microphones in the room so there are microphones, and because these microphones are at two different distances from the speakers, each microphone records a different combination of these two speaker voices. Maybe speaker one is a little louder in microphone one and maybe speaker two is a little bit louder on microphone 2 because the 2 microphones are at different positions relative to the 2 speakers, but each microphone would cause an overlapping combination of both speakers' voices. So here's an actual recording of two speakers recorded by a researcher.
Let me play for you the first, what the first microphone sounds like. One (uno), two (dos), three (tres), four (cuatro), five (cinco), six (seis), seven (siete), eight (ocho), nine (nueve), ten (y diez). All right, maybe not the most interesting cocktail party, there's two people counting from one to ten in two languages but you know. What you just heard was the first microphone recording, here's the second recording. Uno (one), dos (two), tres (three), cuatro (four), cinco (five), seis (six), siete (seven), ocho (eight), nueve (nine) y diez (ten). So we can do, is take these two microphone recorders and give them to an Unsupervised Learning algorithm called the cocktail party algorithm, and tell the algorithm - find structure in this data for you. And what the algorithm will do is listen to these audio recordings and say, you know it sounds like the two audio recordings are being added together or that have being summed together to produce these recordings that we had.
Moreover, what the cocktail party algorithm will do is separate out these two audio sources that were being added or being summed together to form other recordings and, in fact, here's the first output of the cocktail party algorithm. One, two, three, four, five, six, seven, eight, nine, ten. So, I separated out the English voice in one of the recordings. And here's the second of it. Uno, dos, tres, quatro, cinco, seis, siete, ocho, nueve y diez.
Not too bad, to give you one more example, here's another recording of another similar situation, here's the first microphone : One, two, three, four, five, six, seven, eight, nine, ten. OK so the poor guy's gone home from the cocktail party and he 's now sitting in a room by himself talking to his radio. Here's the second microphone recording. One, two, three, four, five, six, seven, eight, nine, ten. When you give these two microphone recordings to the same algorithm, what it does, is again say, you know, it sounds like there are two audio sources, and moreover, the album says, here is the first of the audio sources I found. One, two, three, four, five, six, seven, eight, nine, ten. So that wasn't perfect, it got the voice, but it also got a little bit of the music in there. Then here's the second output to the algorithm. Not too bad, in that second output it managed to get rid of the voice entirely. And just, you know, cleaned up the music, got rid of the counting from one to ten.
So you might look at an Unsupervised Learning algorithm like this and ask how complicated this is to implement this, right? It seems like in order to, you know, build this application, it seems like to do this audio processing you need to write a ton of code or maybe link into like a bunch of synthesizer Java libraries that process audio, seems like a really complicated program, to do this audio, separating out audio and so on.
[W,s,v] = svd((repmat(sum(x.x,1),size(x,1),1).x)*x');
It turns out the algorithm, to do what you just heard, that can be done with one line of code - shown right here. It take researchers a long time to come up with this line of code. I'm not saying this is an easy problem, But it turns out that when you use the right programming environment, many learning algorithms can be really short programs. So this is also why in this class we're going to use the Octave programming environment.
Octave, is free open source software, and using a tool like Octave or Matlab, many learning algorithms become just a few lines of code to implement. Later in this class, I'll just teach you a little bit about how to use Octave and you'll be implementing some of these algorithms in Octave. Or if you have Matlab you can use that too. It turns out the Silicon Valley, for a lot of machine learning algorithms, what we do is first prototype our software in Octave because software in Octave makes it incredibly fast to implement these learning algorithms. Here each of these functions like for example the SVD function that stands for singular value decomposition; but that turns out to be a linear algebra routine, that is just built into Octave. If you were trying to do this in C++ or Java, this would be many many lines of code linking complex C++ or Java libraries. So, you can implement this stuff as C++ or Java or Python, it's just much more complicated to do so in those languages.
What I've seen after having taught machine learning for almost a decade now, is that, you learn much faster if you use Octave as your programming environment, and if you use Octave as your learning tool and as your prototyping tool, it'll let you learn and prototype learning algorithms much more quickly. And in fact what many people will do to in the large Silicon Valley companies is in fact, use an algorithm like Octave to first prototype the learning algorithm, and only after you've gotten it to work, then you migrate it to C++ or Java or whatever. It turns out that by doing things this way, you can often get your algorithm to work much faster than if you were starting out in C++.
So, I know that as an instructor, I get to say "trust me on this one" only a finite number of times, but for those of you who've never used these Octave type programming environments before, I am going to ask you to trust me on this one, and say that you, you will, I think your time, your development time is one of the most valuable resources. And having seen lots of people do this, I think you as a machine learning researcher, or machine learning developer will be much more productive if you learn to start in prototype, to start in Octave, in some other language.
Finally, to wrap up this video, I have one quick review question for you. We talked about Unsupervised Learning, which is a learning setting where you give the algorithm a ton of data and just ask it to find structure in the data for us. Of the following four examples, which ones, which of these four do you think would will be an Unsupervised Learning algorithm as opposed to Supervised Learning problem. For each of the four check boxes on the left, check the ones for which you think Unsupervised Learning algorithm would be appropriate and then click the button on the lower right to check your answer. So when the video pauses, please answer the question on the slide.

So, hopefully, you've remembered the spam folder problem. If you have labeled data, you know, with spam and non-spam e-mail, we'd treat this as a Supervised Learning problem. The news story example, that's exactly the Google News example that we saw in this video, we saw how you can use a clustering algorithm to cluster these articles together so that's Unsupervised Learning. The market segmentation example I talked a little bit earlier, you can do that as an Unsupervised Learning problem because I am just gonna get my algorithm data and ask it to discover market segments automatically. And the final example, diabetes, well, that's actually just like our breast cancer example from the last video. Only instead of, you know, good and bad cancer tumors or benign or malignant tumors we instead have diabetes or not and so we will use that as a supervised, we will solve that as a Supervised Learning problem just like we did for the breast tumor data.
So, that's it for Unsupervised Learning and in the next video, we'll delve more into specific learning algorithms and start to talk about just how these algorithms work and how we can, how you can go about implementing them.
unfamiliar words
-
cohesive [kəʊˈhiːsɪv] adj. 结成一个整体的
exp: ADJ forming a united whole
a cohesive group
一个紧密团结的群体 -
A Combined Method Applied to the Classification of Microarray Gene Expression Data
混合法用于基因芯片数据的分类分析 -
astronomical [ˌæstrəˈnɒmɪkl] adj. 天文学的;
astronomical observations
天文观测 -
cocktail [ˈkɒkteɪl] n. 鸡尾酒;
a cocktail bar/cabinet/lounge
鸡尾酒酒吧 / 陈列柜 / 酒吧间 -
cocktail party 鸡尾酒派对
A cocktail party is a party, usually held in the early evening, where cocktails or other alcoholic drinks are served. People often dress quite formally for them. -
overlap [ˌəʊvəˈlæp ] v. 重叠;(物体或时间上)部分重叠
exp: V if one thing overlaps another, or the two things overlap , part of one thing covers part of the other
A fish's scales overlap each other.
鱼鳞一片片上下交叠。 -
synthesizer [ˈsɪnθəsaɪzə(r)] n. 音响合成器
-
prototype [ˈprəʊtətaɪp] n. 原型;雏形;最初形态
exp: N the first design of sth from which other forms are copied or developed
the prototype of the modern bicycle
现代自行车的雏形 -
singular [ˈsɪŋɡjələ(r)] adj. 单数的;奇特的;
a singular noun/verb/ending
单数名词 / 动词 / 词尾 -
decomposition [ˌdiːˌkɒmpəˈzɪʃn] n. 分解;腐烂
Research on decomposition of decision table based on decision making
基于决策分类的决策表分解方法研究 -
singular value decomposition n.奇異值分解;
The Singular Value Decomposition and its Application in Identification and Control
奇异值分解法及其在辨识和控制中的应用 -
migrate [maɪˈɡreɪt] v. (随季节变化)迁徙;移居;迁移;
exp: V to move from one part of the world to another according to the season
Swallows migrate south in winter.
燕子在冬天迁徙到南方。 -
instructor [ɪnˈstrʌktə(r)] n. 教练;导师;(大学)讲师
-
finite [ˈfaɪnaɪt] adj. 有限的;有限制的;限定的
exp: ADJ having a definite limit or fixed size
The world's resources are finite.
世界的资源是有限的。 -
diabetes [ˌdaɪəˈbiːtiːz] n. 糖尿病;
1.8 Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mess of sounds at a cocktail party).
unfamiliar words
-
derive [dɪˈraɪv] v. 得到;获得;
-
derive from sth
exp1: V to come or develop from sth 源自
The word ‘politics’ is derived from a Greek word meaning ‘city’.
politics一词源自希腊语,意思是city。 -
derive sth from sth
exp2: V to get sth from sth 得到
He derived great pleasure from painting.
他从绘画中得到极大的乐趣。
-


















