
1. 聚类
1.1 什么是聚类?
所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用算法将集合D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高,其中每个子集叫做一个簇。
1.2 KMeans 聚类算法
K-Means聚类算法主要分为如下几个步骤:
- 从D中随机取k个元素,作为k个簇的各自的中心
- 分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇
- 根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数
- 将D中全部元素按照新的中心重新聚类。
- 重复第4步,直到聚类结果不再变化。
1.2.1 什么是相异度
设 X={x1,x2.....,xn},Y={y1,y2......yn}其中X,Y是两个元素项,各自具有n个可度量特征属性
X和Y的相异度定义为: d(X,Y)=f(X,Y)->R,其中R为实数域,也就是两个元素的相异度。
1.2.2 相异度的算法
因为每个纬度的数字都是无方向意义的标度变量,可以通过距离来标示相异度
常见的几个距离计算公式:
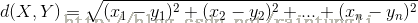
曼哈顿距离:
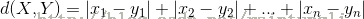
闵可夫斯基距离:
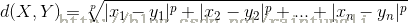
1.2.3 数据的规格化
在计算距离的时候,会发现取值范围大的属性对距离的影响高于取值范围小的属性,为了解决这个问题,一般要对属性值进行规格化。
规格化就是将各个属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。
最典型的规格化就是数据的归一化:将各个属性均映射到[0,1]区间
映射公式为:
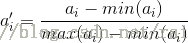
其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值
2. Spark Kmeans的实现
2.1 Kmeans 初始化的几个参数
class KMeans private (
private var k: Int,
private var maxIterations: Int,
private var initializationMode: String,
private var initializationSteps: Int,
private var epsilon: Double,
private var seed: Long) extends Serializable
参数 | 定义 |
K | 聚的总类 |
maxIterations | 迭代的次数 |
initializationMode | 有 random 和 k-means||两种 |
initializationSteps | 初始化的步长 |
epsilon | 最小中心距离的筏值 |
seed | 随机数的种子 |
2.2 步骤1:Kmeans 的初始化中心的选择
Kmeans 在数据集初始化的时候中选K个中心点有两种算法
- 随机选择:依据给的种子seed,随机生成K个随机中心点
- k-means||:默认的算法
- 随机生成一个中心点,基于这个中心点,找出一批距离这个中心点较远的点作为集合(分布式查找)
- 以这些找到的点的集合为新的中心点,依据initializationSteps作为重复查找步骤1,2的次数(分布式查找)
- 如果找到的这些点的数量小于k,那么就以这些点为中心点
- 不如2步骤找到的这些点大于k,那么将基于这些点作为样本进行k-means++的中心点查找,找到K个中心点。k-means++的查找是在有限的点上查找(driver端的本地权重查找)
if (initializationMode == KMeans.RANDOM) {
initRandom(data)
} else {
initKMeansParallel(data)
}
2.3 步骤2: 计算每个点的特征向量的norm
// Compute squared norms and cache them.
val norms = data.map(Vectors.norm(_, 2.0))
norms.persist()
我们来看一下norm的算法
else if (p == 2) {
var sum = 0.0
var i = 0
while (i < size) {
sum += values(i) * values(i)
i += 1
}
math.sqrt(sum)
假如:一个点的A(a1,b1) 那么norm的计算就是 sqrt(a1^2+b1^2),这也是 向量的L2范数
2.4 步骤3:计算每个点距离其他点的距离
在Spark使用的距离算法是欧式距离算法,我们先来看这个距离算法:对两个点 x(x1,x2....xn)和y(y1,y2....yn)
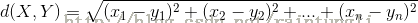
将方程式解开
sqrt(x1^2+x2^2+x3^2+.....+xn^2 + y1^2+y2^2+...+yn^2 -2(x1y1+x2*y2.....+xn*yn))
对x1^2+x2^2+x3^2+.....+xn^2 这部分可以提前算,但是-2(x1y1+x2*y2.....+xn*yn))这部分的计算是需要时时计算的
2.4.1 解开欧式距离计算需要考虑精度
Spark中精度的计算公式:
val sumSquaredNorm = norm1 * norm1 + norm2 * norm2
val normDiff = norm1 - norm2
val precisionBound1 = 2.0 * EPSILON * sumSquaredNorm / (normDiff * normDiff + EPSILON)
if (precisionBound1 < precision) {
sqDist = sumSquaredNorm - 2.0 * dot(v1, v2)
}如果在精度(precision: Double = 1e-6)满足条件的情况下,欧式距离sqDist = sumSquaredNorm - 2.0 * v1.dot(v2),sumSquaredNorm即为

,2.0 * v1.dot(v2)即为

如果精度不满足要求,则进行原始的距离计算公式了

即调用Vectors.sqdist(v1, v2)。
2.4.2 快速算法lowerBoundOfSqDist
在这种情况下,Spark实现了一个快速算法
我们以两个纬度作为例子,假如两个点 x(a1,b1) y(a2,b2)
算法 lowerBoundOfSqDist:

我们分别展开欧式距离和这种距离算法

可以简单的证明算法 lowerBoundOfSqDist小于欧式距离,
- 当lowerBoundOfSqDist大于bestdistance,那么可以推导欧式距离也大于bestdistance,不需要计算欧式距离
- 当lowerBoundOfSqDist小于bestdistance,需要继续计算欧式距离来保证正确性
lowerBoundOfSqDist算法的优势比较明显, sqrt(a1^2+a2^2) 就是前面计算的每个点的norm值
lowerBoundOfSqDist=(norm1-norm2)*(norm1-norm2)
private[mllib] def findClosest(
centers: TraversableOnce[VectorWithNorm],
point: VectorWithNorm): (Int, Double) = {
var bestDistance = Double.PositiveInfinity
var bestIndex = 0
var i = 0
centers.foreach { center =>
// Since `\|a - b\| \geq |\|a\| - \|b\||`, we can use this lower bound to avoid unnecessary
// distance computation.
var lowerBoundOfSqDist = center.norm - point.norm
lowerBoundOfSqDist = lowerBoundOfSqDist * lowerBoundOfSqDist
if (lowerBoundOfSqDist < bestDistance) {
val distance: Double = fastSquaredDistance(center, point)
if (distance < bestDistance) {
bestDistance = distance
bestIndex = i
}
}
i += 1
}
(bestIndex, bestDistance)
}2.4.3 加权欧式距离和lowerBoundOfSqDist
在有些应用场景可能会存在加权的情况,加权欧式距离:

w1,w2....wp 就是每个属性的权重
lowerBoundOfSqDist算法也需要加权:
(sqrt(W1Xi1^2+W2Xi2^2+....+WpXip^2)-sqrt(W1Xj1^2+W2Xj2^2+....+WpXjp^2))^2
lowerBoundOfSqDist也是小于加权欧式距离
2.5 步骤4: 在聚过的簇中重新定义中心点
在已经聚过的簇中,使用所有点的平均值作为新的聚类中心
totalContribs.foreach { case (j, (sum, count)) =>
scal(1.0 / count, sum)
val newCenter = new VectorWithNorm(sum)
if (converged && KMeans.fastSquaredDistance(newCenter, centers(j)) > epsilon * epsilon) {
converged = false
}
centers(j) = newCenter
}
重复步骤1-步骤4,直到迭代次数达到maxIterations初始化的参数为止
注意:
在我们前面的文章中,Spark做了一些算法的优化而这些优化是基于欧式距离的,Spark mllib里提供的Kmeans算法不支持其它的距离算法。
3. Kmeans的训练模型
Kmeans本身也提供了训练模型,模型的目的为了对新输入的向量进行判定到哪个类别,聚类的模型最终的目的是为了分类。
@Since("0.8.0")
class KMeansModel @Since("1.1.0") (@Since("1.0.0") val clusterCenters: Array[Vector])
extends Saveable with Serializable with PMMLExportable {
/**
* A Java-friendly constructor that takes an Iterable of Vectors.
*/
@Since("1.4.0")
def this(centers: java.lang.Iterable[Vector]) = this(centers.asScala.toArray)
/**
* Total number of clusters.
*/
@Since("0.8.0")
def k: Int = clusterCenters.length
/**
* Returns the cluster index that a given point belongs to.
*/
@Since("0.8.0")
def predict(point: Vector): Int = {
KMeans.findClosest(clusterCentersWithNorm, new VectorWithNorm(point))._1
}
/**
* Maps given points to their cluster indices.
*/
@Since("1.0.0")
def predict(points: RDD[Vector]): RDD[Int] = {
val centersWithNorm = clusterCentersWithNorm
val bcCentersWithNorm = points.context.broadcast(centersWithNorm)
points.map(p => KMeans.findClosest(bcCentersWithNorm.value, new VectorWithNorm(p))._1)
}
/**
* Maps given points to their cluster indices.
*/
@Since("1.0.0")
def predict(points: JavaRDD[Vector]): JavaRDD[java.lang.Integer] =
predict(points.rdd).toJavaRDD().asInstanceOf[JavaRDD[java.lang.Integer]]
/**
* Return the K-means cost (sum of squared distances of points to their nearest center) for this
* model on the given data.
*/
@Since("0.8.0")
def computeCost(data: RDD[Vector]): Double = {
val centersWithNorm = clusterCentersWithNorm
val bcCentersWithNorm = data.context.broadcast(centersWithNorm)
data.map(p => KMeans.pointCost(bcCentersWithNorm.value, new VectorWithNorm(p))).sum()
}
private def clusterCentersWithNorm: Iterable[VectorWithNorm] =
clusterCenters.map(new VectorWithNorm(_))
@Since("1.4.0")
override def save(sc: SparkContext, path: String): Unit = {
KMeansModel.SaveLoadV1_0.save(sc, this, path)
}
override protected def formatVersion: String = "1.0"
}
通过KMeansModel的训练模型,predict输入的向量所距离最近的中心点
@Since("0.8.0")
def predict(point: Vector): Int = {
KMeans.findClosest(clusterCentersWithNorm, new VectorWithNorm(point))._1
}看了熟悉的函数findClosest,那些中心点是在聚类结束创建中心点
new KMeansModel(centers.map(_.vector))
4. Spark Kmeans的评估
如何评估KMeans的聚类K的效果?可以通过computeCost函数来计算cost
@Since("0.8.0")
def computeCost(data: RDD[Vector]): Double = {
val centersWithNorm = clusterCentersWithNorm
val bcCentersWithNorm = data.context.broadcast(centersWithNorm)
data.map(p => KMeans.pointCost(bcCentersWithNorm.value, new VectorWithNorm(p))).sum()
}函数的算法:
通过计算所有数据点到其最近的中心点的距离平方和 (a1-c1)^2+(a2-c2)^2 +......
使用不同的K,相同的迭代次数,理论上值越小,聚类效果越好,但是这是需要可解释性,如果聚类K等于总数据点,当然聚类效果最好,cost是0,但没有意义。




















