
好程序员大数据学习路线分享MapReduce全流程总结,首先,MapReduce是什么?干什么用的?
MapReduce是一个基于yarn的分布式、离线、并行的计算框架,主要职责是处理海量数据集,是Hadoop生态圈中一个非常重要的一个工具,所以MapReduce是大数据学习的一个很关键的知识点,需要大家好好掌握!
MapReduce其中包含许多组件,但最主要的还是Job提交和Map、Reduce的全流程这两个部分,学习中只要把握好这两条主线理清楚细节串成一个知识体系,那么MapReduce的学习就会得心应手了。关于Job作业的提交流程在Hadoop权威指南这本书上有相当详细的步骤解析和图示说明,那么这次总结主要关于MapReduce过程中海量数据是怎么被提取并在MapTask和ReduceTask中被处理,以及其中涉及运用的组件,让我们一起来看看吧。
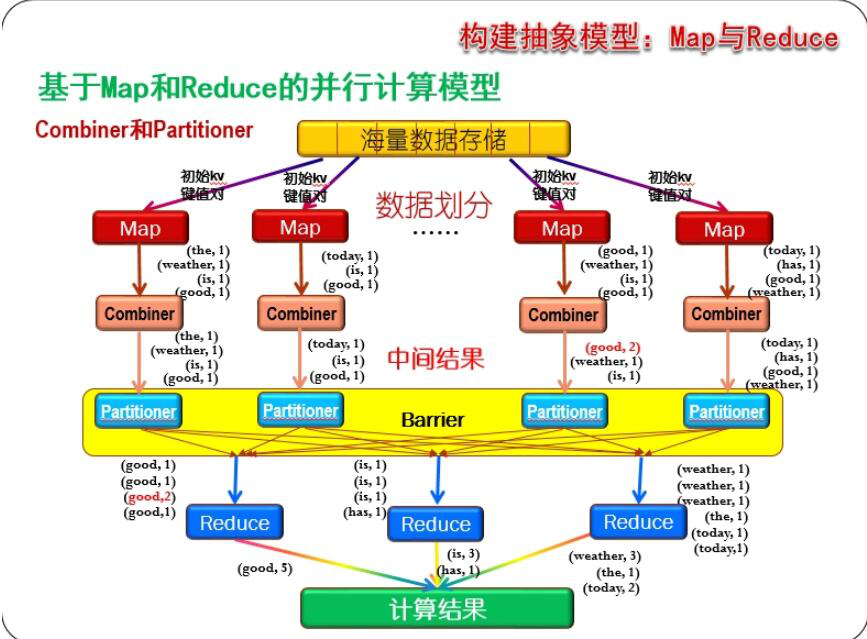
上面的图从整体上描述了整个MapRduce流程,大致分为五个步骤
1、input(map端读取分片数据)--->2、Map处理--->3、shuffle过程--->4、reduce处理--->5、output(reduce端输出处理结果)现在我们一步步来分析解释这个过程。注:MP的整个过程中数据结构为:key-value
1、 Map端读取数据:
a、在读取之前,客户端会对数据进行切片处理,分片机制如下,一个分片对应一个map,可调整客户端的块大小,minSize,maxSize改变map数量,minSize默认值是1,maxSize默认是long的最大值
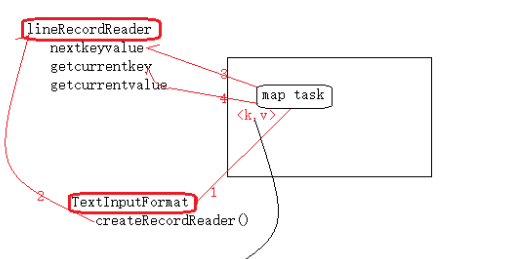
b、如下图所示,先对数据进行TextInputFormat格式化,然后lineRecordReader循环调用
nextKeyValue、getCurrentKey、getCurrentValue等方法将数据以<K,V>形式获取到MapTask
c、切片读取细节:每次读取都往下多读取一行(第一个切片);下一个切片永远抛弃第一行;最后一个切片不能多读一行
2、 Map处理
a、在Map端,调用我们按照业务逻辑编写的map()方法,每一行调用一次map()方法对数据进行处理,有且仅有一次,分别在调用map方法前调用setup()方法和在在调用map方法后调用cleanup()方法
在这个阶段,数据会被分解成一个个<K,V>形式的键值对
b、在这个阶段,可以有一个combiner过程,将数据进行局部整合(当数据量太大时),combiner能调用

3、 shuffle过程:是指数据从Map端输出到Reduce端输入这中间对数据的操作过程(数据分区、排序、缓存)
a、输出从map端输出后,会进入到outputCollector,一个数据收集器,然后由数据收集器将数据传进一个有20%保留区的环形缓冲区(一般是100M)
b、当数据在环形缓冲区溢出时,会有一个spiller溢出器,在溢出器中会将数据调用getPartition(k,v,num)方法分区,然后根据hashcode在分区内进行快速排序,之后将数据发往Reduce
4、 reduce处理
a、经过shuffle过程处理的数据,是分区并排序的index索引文件,而reducetask框架从文件中读取一个key传递给reduce方法,同时传一个value迭代器
b、Value迭代器的hasnext方法会判断文件中的下一个key是否是传入时的key(如果是,则返回该value,如果不是,则停止,转而调用下一个key)
c、看起来的效果,reducetask是将数据事先分组,每组调用一次reduce方法(其实不是)
d、reducetask处理完后,将所有分区文件进行归并排序生成大文件输出(默认输出到hdfs)
e、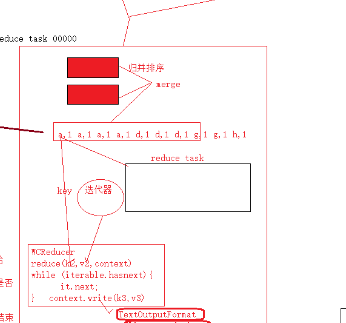
5、 output(reduce端输出处理结果)
对数据进行TextOutputFormat处理,然后lineRecordWritor循环调用
nextKeyValue、getCurrentKey、getCurrentValue,输出到外部文件系统(hdfs)
以上就是mapreduce对数据处理的全流程,这个阶段的代码比较简单,只要把逻辑和数据处的思路和方向把握好,写代码也就手到擒来了


















