在工作中,透彻的理解hive sql执行mapreduce的过程是非常有必要的;
以下2种使用场景;
1)SQL执行过程慢,要理解整个mapreduce过程,对于排查原因是非常有帮助的;
2)面试的时候,有经验的从业人员都会问到这个问题;
官网explain参考wiki:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
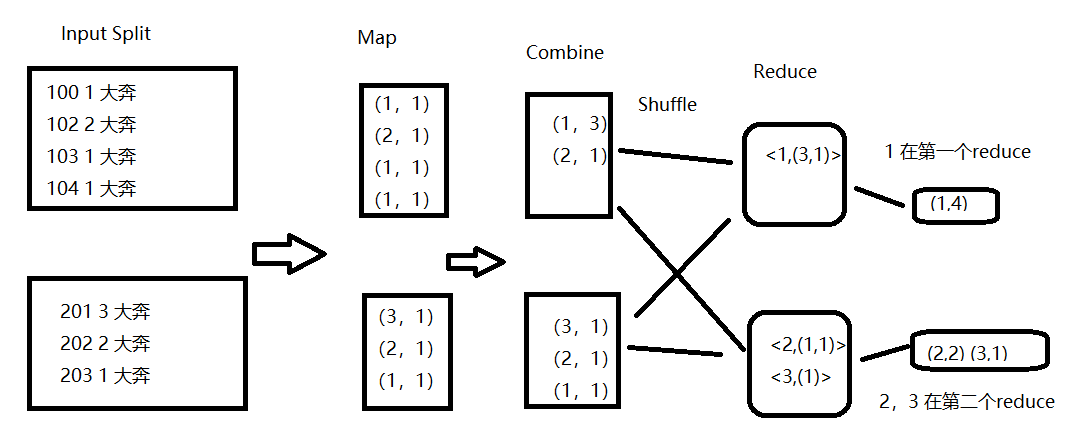
通过图示,来说明SQL转换为MapReduce的过程:

SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
1.SQL Parse:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树(AST) 2.Analyzer:遍历AST,抽象出查询的基本组成单元QueryBlock(QB) 3.Logical Plain:遍历QueryBlock,翻译为执行操作树Operator Tree 4.Logical Optimizer:逻辑层优化器进行Operator Tree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量; 5.Phsical Plain:遍历Operator Tree,翻译为MapReduce任务 6.Phsical Optimizer:物理层优化器对MapReduce任务的优化(如使用MapJoin优化器),生成最终的执行计划;
参考:https://www.cnblogs.com/Dhouse/p/7132476.html
对整个hive sql进行分析,无非是以下两种格式的复杂写法:
写法一,group by场景:select yyy, 聚合函数 from xxx group by yyy;
写法二,join场景:select a.*, b.* from a join b on a.id=b.id;
这两种sql框架,概括了所有的大数据sql,几乎不可能有第三种写法,区别可能是业务复杂,写的复杂点儿而已。
select实现原理:
select a.id, a.city, a.cate from access a where a.day='20190414' and a.cate='大奔'
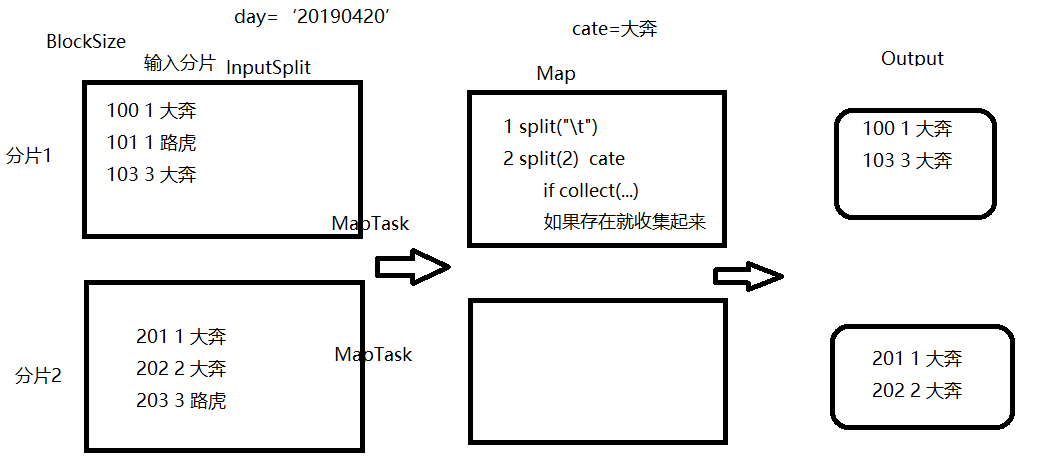
没有shuffle、仅仅就是过滤而已
group by实现原理:
select city, count(1) cnt from access where day='20190414' and cate='大奔' group by city