
pandas 库
- Pandas
- 创建一个 Series 对象 pd.Series()
- 创建一个 DataFrame 对象 pd.DataFrame()
- 数据清洗
- 缺失值 NaN
- 查找缺失值 isna()
- 删除缺失值 dropna()
- 重复值
- 查找重复值 df.duplicated()
- 删除重复值 df.drop_duplicates()
- 异常值
- 检查异常值 df.describe()
- 筛选数据 df = [ df[列名] < num ]
- 数据整理
- 转换日期数据 pd.to_datetime()
- 添加新列 df['要添加的新列的名字']
- 数据写入 df.to_csv(path, encoding, index)
- 分组与聚合
Pandas
# 导入 pandas 库
import pandas as pdpandas 的数据结构有 Series、DataFrame。
Series 主要由一组数据及其对应的索引组成。
以下是一个 Series 对象例子:
import pandas as pd
s = pd.Series(['读书', '健身', '余闲', '投资'], index=[0, 1, 2, 3])
print(s)输出:
0 读书
1 健身
2 余闲
3 投资
dtype: object左边的数字是索引,右边的是数据。
数据底部的 dtype 指的是,pandas 库中的数据类型,而对应的 object 是 pandas 自定义的字符串类型。
创建一个 Series 对象 pd.Series()
import pandas as pd
s = pd.Series(['读书', '健身', '余闲', '投资'], index=[0, 1, 2, 3])
# pd.Series(data) 创建一个 Series 对象,默认索引是从 0 开始,以 0, 1, 2, 3,… 的形式按序分配给列表中的元素。
print(s)以上是传入链表来创建 Series 对象,还有传入字典等方式:
data = {'《三国演义》':'罗贯中', '《水浒传》':'施耐庵'} # 字典
data = 1 # 常量
import numpy as np
data = np.array( [1, 2, 3] ) # n维数组
data = 'hello' # 字符串
s = pd.Series( data ) # 创建一个 Series 对象
创建一个 DataFrame 对象 pd.DataFrame()
DataFrame 对象是一种表格型的数据结构,包含行索引、列索引以及一组数据。
import pandas as pd
data = [['《三国演义》', '罗贯中'], ['《水浒 传》', '施耐庵']]
df = pd.DataFrame(data, columns=['书籍', '作者'], dtype=float)
print(df)输出:
书籍 作者
0 《三国演义》 罗贯中
1 《水浒 传》 施耐庵行索引:0、1,列索引:书籍、作者,表格里面的是数据。
创建 DataFrame 对象的方法是:pd.DataFrame()。
Series 对象和 DataFrame 对象之间的联系就在于:DataFrame 对象可以被看作是由 Series 对象所组成的。
- series,只是一个一维数据结构,由 index 和 value 组成。
- dataframe,是一个二维结构,除了拥有 index 和 value 之外,还拥有 column。
用 df['列索引'] 提取 DataFrame 对象中某一列的数据,其实是一个 Series 对象。
import pandas as pd
data = [['《三国演义》', '罗贯中'], ['《水浒 传》', '施耐庵']]
df = pd.DataFrame(data, columns=['书籍', '作者'], dtype=float)
print(df['书籍'])
print(type(df['书籍']))输出:
Name: 书籍, dtype: object
<class 'pandas.core.series.Series'>
数据清洗
df.info(),显示整体的数据的基本信息,有一个大概的印象。
主要包括:整体数据的总行数、各列数据类型统计、各列的列名、各列总共有多少非空数据、表格占用的系统空间等。
缺失值 NaN
当非空数据与数据总量不一致时,说明这份数据有可能存在缺失值,处理这些缺失值的第一步,就是找到它们。

查找缺失值 isna()
在 pandas 库中,用 isna() 方法来查找 DataFrame、Series 对象中的缺失值。
df.isna() 返回的是 DataFrame 对象,Series.isna() 返回的就是 Series 对象。
返回对象中的内容都是布尔值:
- 缺失数据会用 True 来表示
- False 则代表这里的数据不缺失
对 DataFrame 对象使用 df.head() 方法默认可以查看数据的前 5 行,df.tail() 方法则默认可以查看数据的后 5 行。
pandas 库中,NaN 代表的就是缺失数据。
删除缺失值 dropna()
对于缺失值,最简单的方法就是将含有缺失值的行直接删除。
如果总体的数据量比较大,缺失值占总数据量的比重也比较低,将含有缺失值的行删除后并不会妨碍后续的分析。
当然除了删除之外还有其它处理方法,比如给缺失值填充数据。
在 pandas 库中,用 df.dropna() 会删除 DataFrame、Series 对象中有缺失值的行。
如果我们需要针对某几列的缺失数据进行删除,就需要用到 df.dropna() 的 subset 参数。
df.dropna(subset = ['书籍', '作者'])
重复值
查找重复值 df.duplicated()
用 df.duplicated()方法来查找 DataFrame 对象中的重复数据。
返回一个 Series 对象,找出所有重复值。重复为 True,不重复为 False。
删除重复值 df.drop_duplicates()
df = df.drop_duplicates()
异常值
检查异常值 df.describe()
describe() 方法返回出来的统计信息分别代表数值型数据的频数统计、平均值、标准差、最小值、第一四分位数、中位数、第三四分位数以及最大值。
只需要观察最大最小值、平均数、中位数就好,一般异常值都在特殊位置。
筛选数据 df = [ df[列名] < num ]
# 查看单价小于等于 200 的数据,再重新赋值给就能过滤掉所有单价大于 200 的异常值
df = df[ df['单价'] <= 200 ]
数据整理
数据整理指的是我们在数据分析前对所需字段(表格的列)进行数据排序、数据转换、数据抽取、数据合并、数据计算等准备操作。
转换日期数据 pd.to_datetime()
Python 中有专门储存时间日期的数据类型 —— datetime,我们对日期数据进行操作都需要 TA。
但 Pandas 中的日期数据(如 2021-10-08),日期列数据并不是 datetime 类型,而是 objeect(pandas自定义的字符串类型)。
在 pandas 库中我们可以使用 pd.to_datetime(arg, format) 来将 DataFrame 对象或者 Series 对象的数据类型转换成 datetime 类型。
其中的 arg 参数为我们要转换的数据,它可以是 DataFrame 对象或 Series 对象。
format 参数为 datetime 类型的日期格式,如数据,是以年-月-日的形式出现的,那对应的 format 就是 ‘%Y-%m-%d’。
# 转换日期数据,并设置对应的日期格式
Series = pd.to_datetime(mask_data['日期'], format = '%Y-%m-%d')将 ‘日期’ 字段转换成 datetime 类型后,我们就可以直接进行增、删、改、查等各种操作。如:
# 提取年份
year_data = Series.dt.year# 提取月份
month_data = Series.dt.month# 提取某日
day_data = Series.dt.day
添加新列 df[‘要添加的新列的名字’]
df['月份'] = n
数据写入 df.to_csv(path, encoding, index)
数据整理完了,写入 csv 文件中。
df.to_csv(path, encoding='utf-8')
分组与聚合
分组是指根据一个或多个键将数据拆分为多个组的过程,这里的键可以理解为分组的条件。
聚合指的是任何能够从数组产生标量值的数据转换过程。
分组、聚合操作一般会同时出现,用于计算分组数据的统计值或实现其他功能。

除此之外,不只有单层分组聚合操作,还有多层分组聚合操作。
单层分组聚合操作:
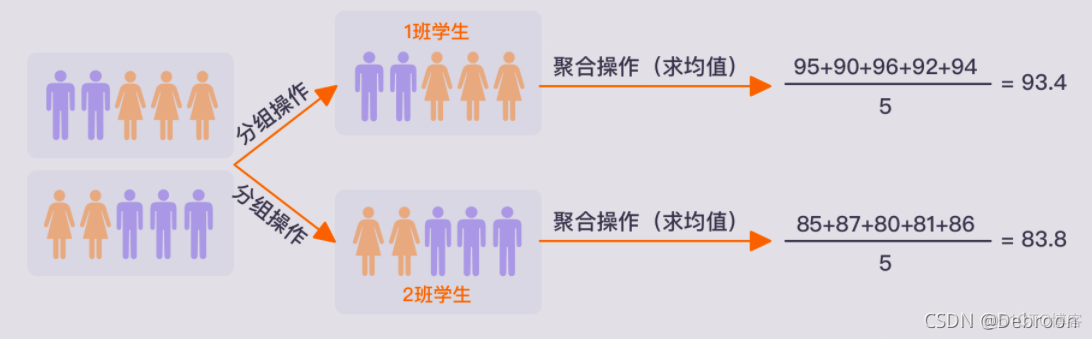
df = df.groupby('班级')['成绩'].mean()多层分组聚合操作:

df = df.groupby(['班级', '性别'])['成绩'].mean()


















