
一、什么是Structured Streaming
结构化流(Structured Streaming)是一个建立在Spark SQL引擎之上可扩展且容错的流处理引擎。你可以使用与静态数据批处理计算相同的方式来表达流计算。当不断有流数据到达时,Spark SQL引擎将会增量地、连续地计算它们,然后更新最终的结果。最后,系统通过检查点和预写日志的方式确保端到端只执行一次的容错保证。总之,结构化流(Structured Streaming)提供了快速的、可扩展的、容错的和端到端只执行一次的(end-to-end exactly-once)流处理,用户无需考虑流本身。
结构化流查询(Structured Streaming Query)内部默认使用微批处理引擎( micro-batch processing engine),它将数据流看作一系列小的批任务(batch jobs)来处理,从而达到端到端如100毫秒这样低的延迟以及只执行一次容错的保证。然而,从Spark 2.3,我们已经引入了一个新的低延迟处理方式——连续处理(Continuous Processing),可以达到端到端如1毫秒这样低的延迟至少一次保证。不用改变查询中DataSet/DataFrame的操作,你就能够选择基于应用要求的查询模式。
我们来看一个单词计数的示例:
package com.leboop.streaming
import org.apache.spark.sql.SparkSession
object StructuredStreamingTest {
def main(args: Array[String]): Unit = {
//创建Spark SQL切入点
val spark=SparkSession.builder().appName("Structrued-Streaming").getOrCreate()
//读取服务器端口发来的行数据,格式是DataFrame
val linesDF=spark.readStream.format("socket").option("host","192.168.189.21")
.option("port",9999).load()
//隐士转换(DataFrame转DataSet)
import spark.implicits._
//行转换成一个个单词
val words=linesDF.as[String].flatMap(_.split(" "))
//按单词计算词频
val wordCounts=words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}
}
程序监听192.168.189.21服务器端口9999发来的句子。
执行步骤:
1、启动netcat
执行如下命令,启动netcat,等待发送句子。
[root@hdp21 ~]# nc -lk 9999
2、启动程序
将程序打成wc.jar包上传至服务器,执行命令
spark-submit --class com.leboop.streaming.StructuredStreamingTest --master yarn wc.jar 参数说明:
(1)spark-submit
提交程序到spark集群执行的命令
(2)--class
主程序类名
(3)--master
spark集群的运行方式:yarn
(4)wc.jar
程序jar包名称
程序启动后将监听服务器端口,统计发送的句子中的单词。
3、发送语句
通过netcat,模拟发送一些句子,如下:
[root@hdp21 ~]# nc -lk 9999
we hava a cat
we hava a pig
4、程序执行结果
+-----+-----+
|value|count|
+-----+-----+
| cat| 1|
| pig| 1|
| a| 2|
| hava| 2|
| we| 2|
+-----+-----+
二、Structured Streaming的模型
结构化流的关键思想是将活生生的数据流看作一张正在被连续追加数据的表。产生了一个与批处理模型非常相似的新的流处理模型。可以像在静态表之上的标准批处理查询一样,Spark是使用在一张无界的输入表之上的增量式查询来执行流计算的。如图:

数据流Data Stream看成了表的行数据,连续地往表中追加。结构化流查询将会产生一张结果表(Result Table),如图:
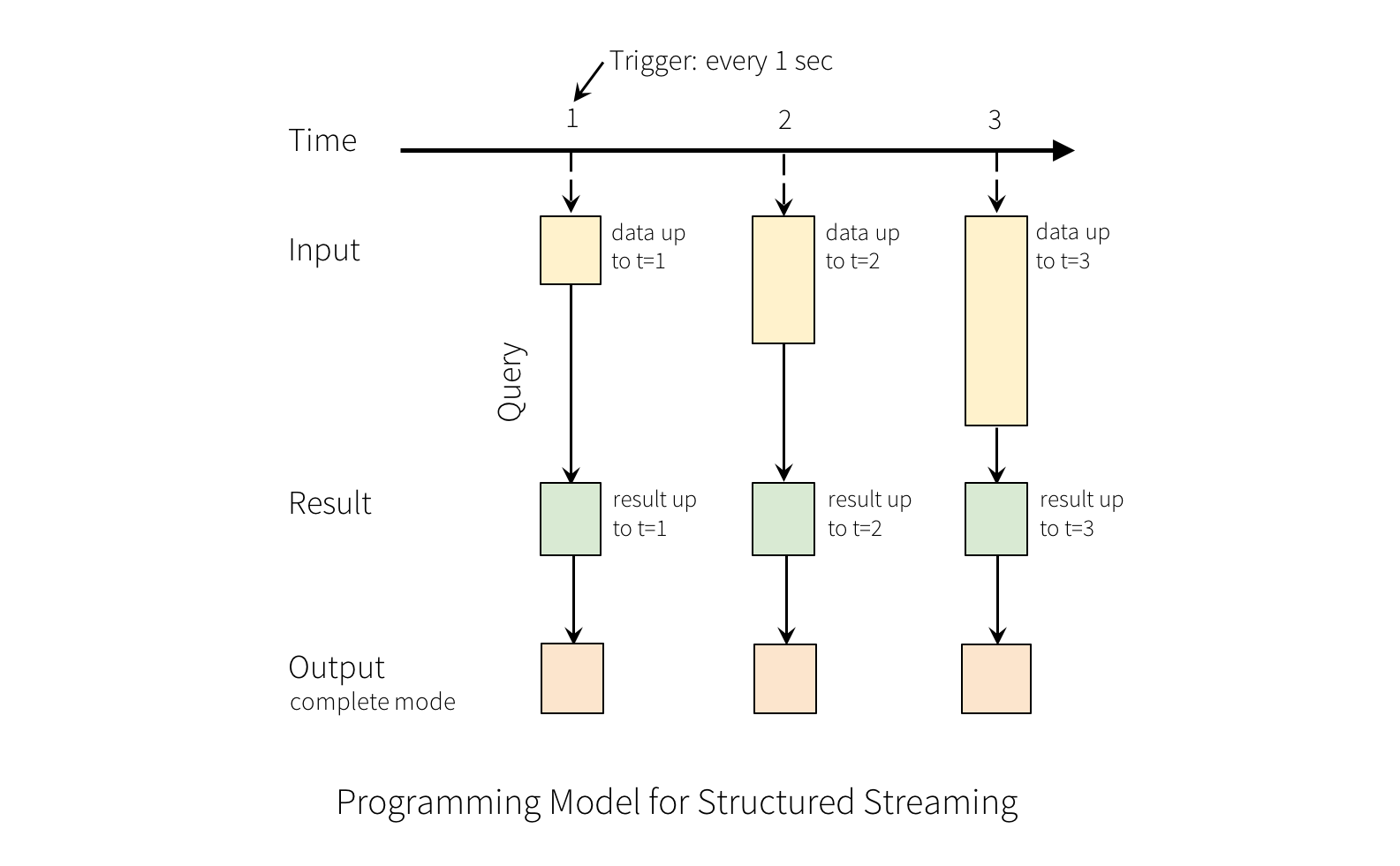
第一行是Time,每秒有个触发器,第二行是输入流,对输入流执行查询后产生的结果最终会被更新到第三行的结果表中。第四行驶输出,图中显示的输出模式是完全模式(Complete Mode)。图中显示的是无论结果表何时得到更新,我们将希望将改变的结果行写入到外部存储。输出有三种不同的模式:
(1)完全模式(Complete Mode)
整个更新的结果表(Result Table)将被写入到外部存储。这取决于外部连接决定如何操作整个表的写入。
(2)追加模式(Append Mode)
只有从上一次触发后追加到结果表中新行会被写入到外部存储。适用于已经存在结果表中的行不期望被改变的查询。
(3)更新模式(Update Mode)
只有从上一次触发后在结果表中更新的行将会写入外部存储(Spark 2.1.1之后才可用)。这种模式不同于之前的完全模式,它仅仅输出上一次触发后改变的行。如果查询中不包含聚合,这种模式与追加模式等价的。
每种模式适用于特定类型的查询。下面以单词计数的例子说明三种模式的区别(单词计数中使用了聚合)
(Complete Mode)
package com.leboop.streaming
import org.apache.spark.sql.SparkSession
/**
* 结构化查询各种模式Demo
*/
object StructruedStreamingQueryModeDemo {
def main(args: Array[String]): Unit = {
//创建Spark SQL切入点
val spark=SparkSession.builder().appName("Structrued-Streaming").getOrCreate()
//读取服务器端口发来的行数据,格式是DataFrame
val linesDF=spark.readStream.format("socket").option("host","192.168.189.21")
.option("port",9999).load()
//隐士转换(DataFrame转DataSet)
import spark.implicits._
//行转换成一个个单词
val words=linesDF.as[String].flatMap(_.split(" "))
//按单词计算词频
val wordCounts=words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete") //与.outputMode(OutputMode.Complete)等价
.format("console")
.start()
query.awaitTermination()
}
}分两次发送如下内容:
[hdfs@hdp21 ~]$ nc -lk 9999
I hava a cat
I love Beijing
程序运行结果如下:
+-----+-----+
|value|count|
+-----+-----+
| cat| 1|
| I| 1|
| a| 1|
| hava| 1|
+-----+-----+
+-------+-----+
| value|count|
+-------+-----+
|Beijing| 1|
| love| 1|
| cat| 1|
| I| 2|
| a| 1|
| hava| 1|
+-------+-----+第二次显示了全部的单词计数。
(Update Mode)
val query = wordCounts.writeStream
.outputMode("update") //与.outputMode(OutputMode.Update)等价
.format("console")
.start()程序成果如下:
+-----+-----+
|value|count|
+-----+-----+
| cat| 1|
| I| 1|
| a| 1|
| hava| 1|
+-----+-----+
+-------+-----+
| value|count|
+-------+-----+
|Beijing| 1|
| love| 1|
| I| 2|
+-------+-----+第二次只显示了更新的单词。
(Append Mode)
val query = wordCounts.writeStream
.outputMode("append") //与.outputMode(OutputMode.Append)等价
.format("console")
.start()程序运行结果如下:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Append output mode not supported
when there are streaming aggregations on streaming DataFrames/DataSets without watermark;在单词计数代码中linesDF相当于一张无界的输入表(input table),最终的wordCounts是结果表(result table),它只有两个列,分别为value和count。注意到基于流linesDF的查询产生的wordCounts确实与在静态数据上的查询是一样的。但是,当查询开始后,Spark会不断地检查从socket连接中发来的新数据。如果有了新的数据,Spark会结合之前的counts结果和新的数据来计算出最新的counts。如图:

三、事件-时间(Event-time)和延迟数据(Late Data)
Event-time是嵌入到数据本身的时间,所以首先event-time它是一个时间,是一个基于事件的时间。对于许多的应用来说,你可能希望操作这个事件-时间。例如,如果你想获得每分钟物联网设备产生的事件数量,然后想使用数据产生时的时间(也就是数据的event-time),而不是Spark接收他们的时间。每个设备中的事件是表中的一行,而事件-时间是行中的一个列值。这就允许将基于窗口的聚合(比如每分钟的事件数)看成是事件-时间列的分组和聚合的特殊类型——每个时间窗口是一个组,每行可以属于多个窗口/组。
进一步,这个模型自然处理那些比期望延迟到达的事件-时间数据。当Spark正在更新结果表时,当有延迟数据,它就会完全控制更新旧的聚合,而且清理旧的聚合去限制中间状态数据的大小。从Spark 2.1开始,我们已经开始支持水印(watermarking ),它允许用户确定延迟的阈值,允许引擎相应地删除旧的状态。
1、窗口操作
在滑动的事件-时间窗口上的聚合对于结构化流是简单的,非常类似于分组聚合。在分组聚合中,聚合的值对用户确定分组的列保持唯一的。在基于窗口的聚合中,聚合的值对每个窗口的事件-时间保持唯一的。
修改我们前面的单词计数的例子,现在当产生一行句子时,附件一个时间戳。我们想每5分钟统计一次10分钟内的单词数。例如,12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20等。注意到12:00 - 12:10是一个窗口,表示数据12:00之后12:10之前到达。比如12:07到达的单词,这个单词应该在12:00 - 12:10和12:05 - 12:15两个窗口中都要被统计。如图:

现在基于窗口的单词技术代码,应该如下:
package com.leboop.streaming
import java.sql.Timestamp
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
/**
* DataFrame窗口操作Demo
*/
object WindowOnEventTimeDemo {
case class TimeWord(word:String,timestamp:Timestamp)
def main(args: Array[String]): Unit = {
//输入参数个数
if (args.length < 3) {
System.err.println("Usage: WindowOnEventTimeDemo <host地址> <端口号>" +
" <窗口长度/秒> [<窗口滑动距离/秒>]")
System.exit(1)
}
//host地址
val host = args(0)
//端口号
val port = args(1).toInt
//窗口长度
val windowSize = args(2).toInt
//窗口滑动距离,默认是窗口长度
val slideSize = if (args.length == 3) windowSize else args(3).toInt
//窗口滑动距离应当小于或等于窗口长度
if (slideSize > windowSize) {
System.err.println("窗口滑动距离应当小于或等于窗口长度")
}
//以秒为单位
val windowDuration = s"$windowSize seconds"
val slideDuration = s"$slideSize seconds"
//创建Spark SQL切入点
val spark=SparkSession.builder().appName("Structrued-Streaming").getOrCreate()
import spark.implicits._
// 创建DataFrame
val lines = spark.readStream
.format("socket")
.option("host", host)
.option("port", port)
.option("includeTimestamp", true)//添加时间戳
.load()
// 分词
val words = lines.as[(String, Timestamp)]
.flatMap(line => line._1.split(" ")
.map(word => TimeWord(word, line._2))).toDF()
// 计数
val windowedCounts = words.groupBy(
window($"timestamp", windowDuration, slideDuration), $"word"
).count().orderBy("window")
// 查询
val query = windowedCounts.writeStream
.outputMode("complete")
.format("console")
.option("truncate", "false")
.start()
query.awaitTermination()
}
}
程序中,窗口的长度和滑动的距离都由用户输入。
先启动NetCat,然后启动程序,在端口中发送三条语句,如下:
[hdfs@hdp21 ~]$ nc -lk 9999
I have a cat
I love Beijing
I love Shanghai程序运行结果:
+---------------------------------------------+--------+-----+
|window |word |count|
+---------------------------------------------+--------+-----+
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|a |1 |
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|I |2 |
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|have |1 |
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|love |1 |
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|cat |1 |
|[2018-08-14 00:13:00.0,2018-08-14 00:13:10.0]|Beijing |1 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|cat |1 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|love |2 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|Beijing |1 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|have |1 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|Shanghai|1 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|I |3 |
|[2018-08-14 00:13:05.0,2018-08-14 00:13:15.0]|a |1 |
|[2018-08-14 00:13:10.0,2018-08-14 00:13:20.0]|Shanghai|1 |
|[2018-08-14 00:13:10.0,2018-08-14 00:13:20.0]|I |1 |
|[2018-08-14 00:13:10.0,2018-08-14 00:13:20.0]|love |1 |
+---------------------------------------------+--------+-----+从结果中可以看到,有三个窗口:[00.0,10.0],[05.0,15.0],[10.0,20.0]。窗口长度10秒,滑动距离5s,也就是说每隔5秒统计10秒内的单词数。
2、延迟数据和水印操作
现在考虑如果一个事件延迟到达这个应用将会发生什么。例如,12:04产生了一个word,可能在12:11才能被应用接收到。应用应该使用12:04这个时间去更新窗口12:00-12:10中的单词计数,而不是12:11。这在基于窗口的分组中自然发生——结构化流可以维持部分聚合的中间状态很长一段时间以满足延迟数据来正确更新旧窗口中的聚合。如下所示

延迟数据dog,在12:11才被应用接受到,事实上,它在12:04已经产生。在前两次结果表中都未被统计,但是统计在了最后一次结果表中。这次在统计中,Spark引擎一致维持中间数据状态,直到延迟数据到达,并统计到结果表中。
对于一个运行好几天的查询来说,有必要绑定累计中间内存状态的数量。这意味着系统需要知道什么时候可以从内存状态中删除旧聚合,由于应用对那个聚合不再接收延迟数据。在Spark 2.1中,引入了水印,它使引擎自动跟踪当前数据中的事件时间,尝试一致地删除旧的状态。通过确定事件时间列和按照事件时间数据预期延迟的阈值可以定义查询的水印。对于一个以时间T开始的特定窗口,引擎将会维持状态,并且允许延迟数据更新状态直到(max event time seen by the engine - late threshold > T
)。换句话说,阈值内的延迟数据将会倍聚合,但是比阈值更延迟的数据将被删除。让我们来看个例子,late threshold=10分钟,输出模式为Update Mode。

图中的圆点表示数据,由数据产生的时间和word组成。坐标轴的横坐标表示数据被应用看到或接收的时间,纵坐标表示数据产生的时间。圆点有三类,
黄色实心圆:准时到达应用的数据,例如第一个dog单词,12:07产生,12:07到达(产生和到达可能相差一些秒)。
红色实心圆:延迟到达应用的数据,例如12:09产生的cat单词,12:09+10分钟=12:19,实际到达时间小于12:15,在水印之内。
红色空心圆:延迟到达应用的数据,例如donkey这个词在12:04产生,但在12:04+10分钟=12:14之后到达应用,在水印之外。
为了说清楚整个过程,我们对圆点进行标记,格式(序号,事件时间,单词),如下:
黄色实心圆从左到右标记为
(1,12:07,dog),(2,12:08,owl),(3,12:14,dog),(4,12:15,cat),(5,12:21,owl);
红色实心圆从左到右标记为
(6,12:09,cat),(7,12:08,dog),(8,12:13,owl),(9,12:17,owl),
红色空心圆标记为(10,12:04,donkey)
第一次统计:
窗口12:00-12:10,单词序号1,2
12:05-12:15,单词序号2,3
也就是说第二个黄色实心圆在两个窗口中都有统计。
第二次统计:
12:00-12:10窗口新增了一个延迟的单词6
12:05-12:15窗口新增了两个延迟的单词6和7。
增加了一个窗口12:10-12:20,统计延迟的单词7。
第四次统计:
统计的时间是12:25,单词donkey在12:04产生,大约在12:22到达应用,超过了水印的10分钟阈值(应当要在12:04+10=12:14内到达),所以12:00-12:10窗口不再统计这个单词。
(1)水印删除聚合状态的条件
水印清除聚合查询中的状态需要满足下面的条件:
a、输出模式必须是追加(Append Mode)和更新模式(Update Mode),完全模式(Complete Mode)要求所有聚合数据持久化,所以不能使用水印删除中间状态。
b、聚合必须有事件-时间列或者一个事件-时间列上的窗口。
c、withWatermark必须在相同的列上调用,如聚合中使用的时间戳列。例如,
df.withWatermark("time", "1 min").groupBy("time2").count()在Append Mode中是无效的,因为对于聚合的列水印定义在了不同的列上。
d、withWatermark必须在水印聚合被使用前调用。例如
df.groupBy("time").count().withWatermark("time", "1 min")在Append Mode中是无效的。
在窗口操作中,水印如下使用:
// 计数(添加水印 阈值是)
val late =windowDuration
val windowedCounts = words.withWatermark("timestamp", late)
.groupBy(window($"timestamp", windowDuration, slideDuration), $"word")
.count().orderBy("window")late为数据允许延迟的时间,等于窗口长度,由执行命令时输入。
四、流动的DataFrames和DataSets
1、创建
流动的DataFrames可以通过SparkSession.readStream()返回的DataStreamReader接口创建,和创建静态的DataFrame的read接口类似,你可以确定具体的源——包括数据的格式(format),模式(schema),选项(options)等等。例如单词计数例子中:
val linesDF=spark.readStream.format("socket").option("host","192.168.189.21").option("port",9999).load()输入源:
(1)File source
读取写在一个目录下的文件作为数据流。支持的文件格式有text,csv,json,orc,parquet。对于每个文件格式支持选项。注意到文件必须原子地放入到给定的目录,在大多数文件系统中可以通过文件移动操作到达。
(2)Kafka source
从Kafka读取数据。兼容Kafka broker版本0.10.0或者更高
(3)Socket source
从一个socket连接中获取UTF8文本数据。注意到因为这种数据源不提供端到端的容错保证,应该仅仅作为测试被使用。
(4)Rate soruce
每秒产生特定行数的数据,每个输出行包含一个时间戳(timestamp)和一个值(value)。时间戳是一个Timestamp类型包含消息分派的时间,值是一个Long类型包含消息的数量,第一行从0开始。Rate source打算作为测试和标杆校准。
| Source | Options | Fault-tolerant | Notes |
|---|---|---|---|
| File source | path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to processs the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to `true`, the following files would be considered as the same file, because their filenames, "dataset.txt", are the same: "file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" For file-format-specific options, see the related methods in DataStreamReader(Scala/Java/Python/R). E.g. for "parquet" format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for "parquet", see Parquet configuration section. |
Yes | Supports glob paths, but does not support multiple comma-separated paths/globs. |
| Socket Source | host: host to connect to, must be specifiedport: port to connect to, must be specified |
No | |
| Rate Source | rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second.rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark's default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. |
Yes | |
| Kafka Source | See the Kafka Integration Guide. | Yes |
下面以File source为例,从本地file:///home/hdfs/data/structured-streaming(支持从HDFS文件系统读取,将目录地址地址改为hdfs://192.168.189.21:8020/input/structured-streaming即可)目录下读取csv文件,结构化查询模式为Append Mode。代码如下:
package com.leboop.streaming
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.StructType
object StructuredStreamingTest {
def main(args: Array[String]): Unit = {
//创建Spark SQL切入点
val spark=SparkSession.builder().appName("Structrued-Streaming").master("local").getOrCreate()
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")//name和age分隔符
.schema(userSchema) // Specify schema of the csv files
.csv("file:///home/hdfs/data/structured-streaming") // Equivalent to format("csv").load("file:///home/hdfs/data/structured-streaming")
// Returns True for DataFrames that have streaming sources
println("=================DataFrames中已经有流=================|"+csvDF.isStreaming +"|")
//打印csvDF模式
csvDF.printSchema
//执行结构化查询,将结果写入控制台console,输出模式为Append
val query = csvDF.writeStream
.outputMode(OutputMode.Append)
.format("console")
.start()
query.awaitTermination()
}
}
先在/home/hdfs/data/structured-streaming目录下创建一个文件person1,如图:

文件内容如下:
Tom;21
Lucy;24
Jack;49
将程序打成structruedstreamingsource-append-mode.jar包上传服务器,执行如下命令
spark-submit --class com.leboop.streaming.StructuredStreamingTest --master yarn structruedstreamingsource-append-mode.jar程序部分执行结果如下:
=================DataFrames中已经有流=================|true|
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
18/08/13 20:11:30 INFO FileSourceScanExec: Pushed Filters:
-------------------------------------------
Batch: 0
-------------------------------------------
18/08/13 20:11:34 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1107 bytes result sent to
driver18/08/13 20:11:34 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 134 ms on localhos
t (executor driver) (1/1)18/08/13 20:11:34 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from
pool 18/08/13 20:11:34 INFO DAGScheduler: ResultStage 1 (start at StructuredStreamingTest.scala:27) fini
shed in 0.135 s18/08/13 20:11:34 INFO DAGScheduler: Job 1 finished: start at StructuredStreamingTest.scala:27, too
k 0.210005 s+----+---+
|name|age|
+----+---+
| Tom| 21|
|Lucy| 24|
|Jack| 49|
+----+---+
将文件person2移动到/home/hdfs/data/structured-streaming目录下,会触发新的查询,将person2文件数据处理运行如下:
18/08/13 20:15:50 INFO Executor: Running task 0.0 in stage 4.0 (TID 4)
18/08/13 20:15:50 INFO Executor: Finished task 0.0 in stage 4.0 (TID 4). 1089 bytes result sent to
driver18/08/13 20:15:50 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 4) in 13 ms on localhost
(executor driver) (1/1)18/08/13 20:15:50 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from
pool 18/08/13 20:15:50 INFO DAGScheduler: ResultStage 4 (start at StructuredStreamingTest.scala:27) fini
shed in 0.014 s18/08/13 20:15:50 INFO DAGScheduler: Job 5 finished: start at StructuredStreamingTest.scala:27, too
k 0.051298 s+-----+---+
| name|age|
+-----+---+
| Mick| 78|
|Kitty| 56|
+-----+---+
18/08/13 20:15:50 INFO StreamExecution: Streaming query made progress: {
"id" : "1df04106-5899-489e-8c43-bf160d73ef78",
"runId" : "b8485b0e-dc78-4c30-9220-2aa364ad4338",
"name" : null,
这里没有使用聚合,所以结构化查询模式不能使用Complete Mode,错误如下:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Complete output mode not support
ed when there are no streaming aggregations on streaming DataFrames/Datasets;我们得到这样一个使用技巧:如果程序中有聚合,使用Complete Mode或者Update Mode查询,如果程序中没有使用聚合,使用Append Mode查询。
2、操作——选择(Selection)、投射(Projection)和聚合(Aggregation)
以单词计数为例,代码如下:
package com.leboop.streaming
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
/**
* 结构化查询各种模式Demo
*/
object StructruedStreamingOperationsDemo {
def main(args: Array[String]): Unit = {
//创建Spark SQL切入点
val spark=SparkSession.builder().appName("Structrued-Streaming").getOrCreate()
//读取服务器端口发来的行数据,格式是DataFrame
val linesDF=spark.readStream.format("socket").option("host","192.168.189.21")
.option("port",9999).load()
//隐士转换(DataFrame转DataSet)
import spark.implicits._
//行转换成一个个单词
val words=linesDF.as[String].flatMap(_.split(" "))
//按单词计算词频(聚合)
val wordCounts=words.groupBy("value").count()
//操作流动的DataFrame(选择和投射)
val operationDF=wordCounts.select("value").where("count>5")
val query = operationDF.writeStream
.outputMode(OutputMode.Complete)
.format("console")
.start()
query.awaitTermination()
}
}
程序中将出现总数达到5次以上的单词打印到了控制台。where属于Selection操作,select属于Projection操作,groupBy属于Aggregation操作。
启动NetCat,发送三条语句,如下:
[hdfs@hdp21 ~]$ nc -lk 9999
I hava a cat and a pig
I love a cat and a pig
I hava a car and a dog
程序执行结果如下:
+-----+
|value|
+-----+
| a|
+-----+
五、Join操作
1、Stream-static Joins
从Spark 2.0,结构化流已经支持流和静态DataFrame/DataSet的连接(内连接和外连接)。
2、Stream-steam Joins




















