
Oracle数据库宕机案例分享
如何完整处理一个故障,聊聊我的思路。
技术人人都可以磨炼,但处理问题的思路和角度各有不同,希望这篇文章可以抛砖引玉。
以一个例子为切入点
一、故障现象
-
应用无法访问,报错无法获取数据库连接,应用宕机。
-
数据库报错同期有报错,超过最大连接及异常被kill。
Mon Nov 23 00:06:23 2020
the next minute. Please look at trace files to see all the ORA-20 errors.
Mon Nov 23 00:06:54 2020
........
Current time = 520601892, process death time = 520541771
Attempting to kill process 0x0xa394305a8 with OS pid = 16729OSD kill succeeded for process 0xa394305a8
Instance Critical Process (pid: 9, ospid: 16729, DBRM) died unexpectedly
PMON (ospid: 16372): terminating the instance due to error 56710
二、故障说明
-
通过宕机前DB 监控agent 采集的实例运行数据,定位异常开始具
体时间,从关键指标的趋势变化和历史监控数据,关联到OS 的内
存瓶颈,结合数据库和操作系统的监控数据,判断出故障链:应用
宕机是因为获取不到数据库连接(数据库宕机),数据库宕机是因
为OS 内存耗尽,OS 内存耗尽是因为应用发起了大量连接,应用
大量连接创建,是因为应用的连接复用出现异常。
-
这是数据库实例监控数据,OS 监控数据二者结合在一起,用实际
监控数据来验证我们的推断,排除掉其它干扰因素,定位数据库
宕机的根本原因,帮助其他同事快速修复。
三、故障原因
先总结一下DB端排查的原因:
-
应用端创建大量的连接,数据库OS 内存逐渐耗尽并出现swap 使用,最终整个os 系统hang 住,数据库DBRM 进程检测到Heavy swapping observed 异常,最终数据库被异常终止。
-
(说明:应用发起新的数据库连接创建时,数据库服务器需要分配相应端口,打开对应的文件句柄,创建相应的OS 进程,分配相应的OS 内存(大约每个8MB 左右),随着应用连接数的增加,OS 内存逐渐耗尽并出现swap 使用)
四、疑问点排查及分析思路
1、故障时段数据库有多少连接?瞬间过来的连接还是均匀建立的连接?
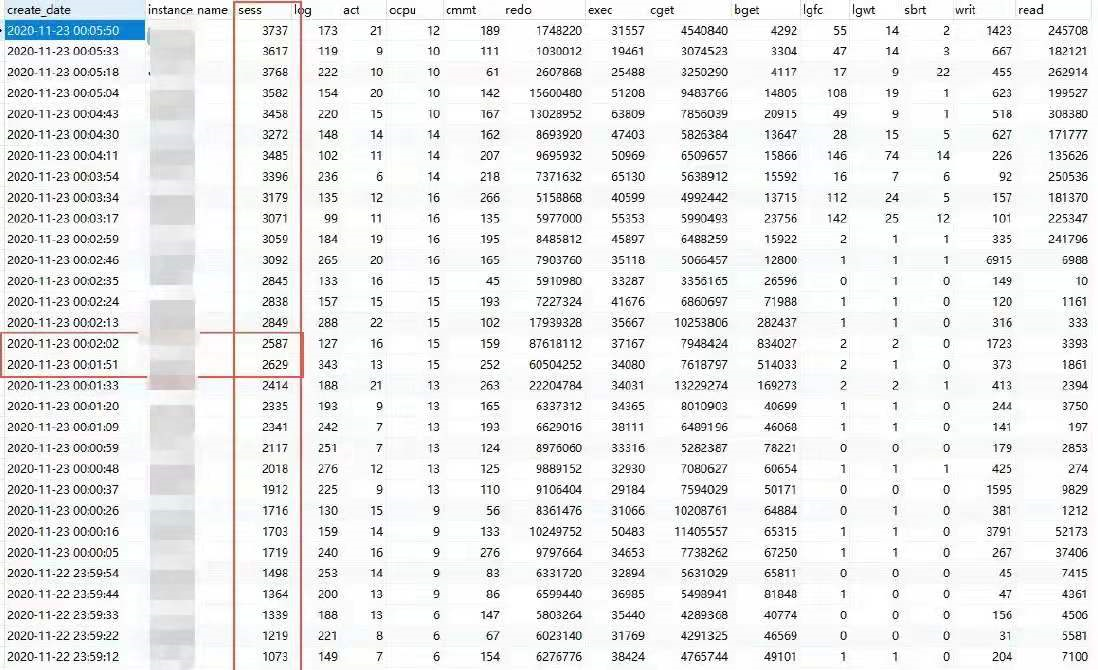
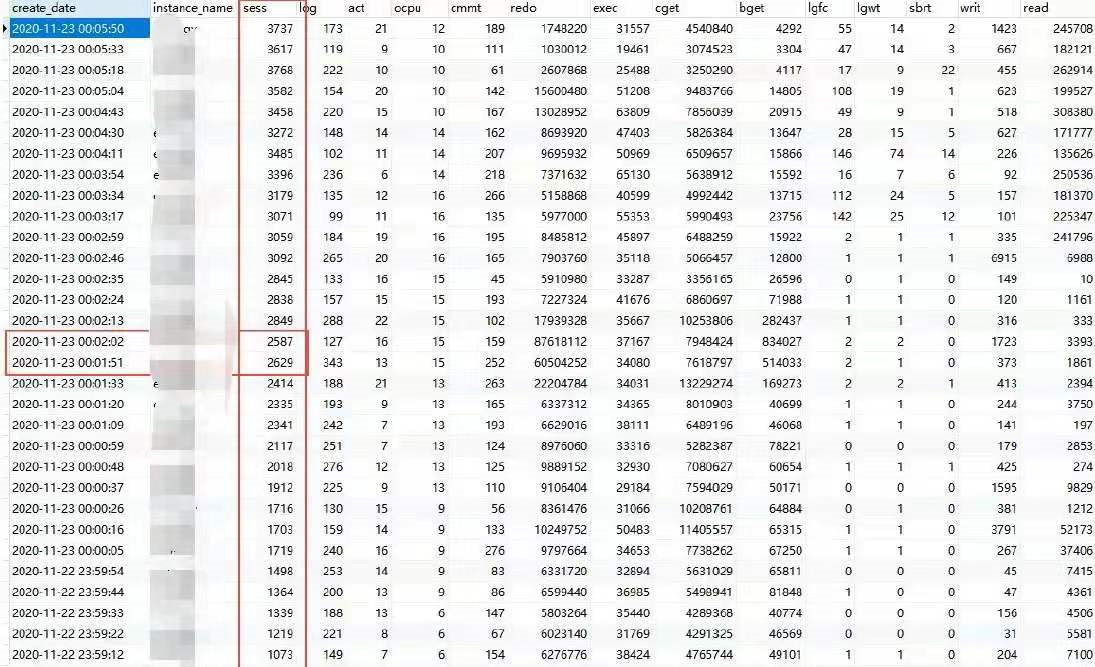
监控数据显示至少有3700 个连接(实际上如果包括创建中的,已经超过4000 了),从sess指标来,连接是在8 分钟内均匀建立的, 而且分布在8 台机器上。
DB agent 监控数据:
2、什么时间点开始有异常?
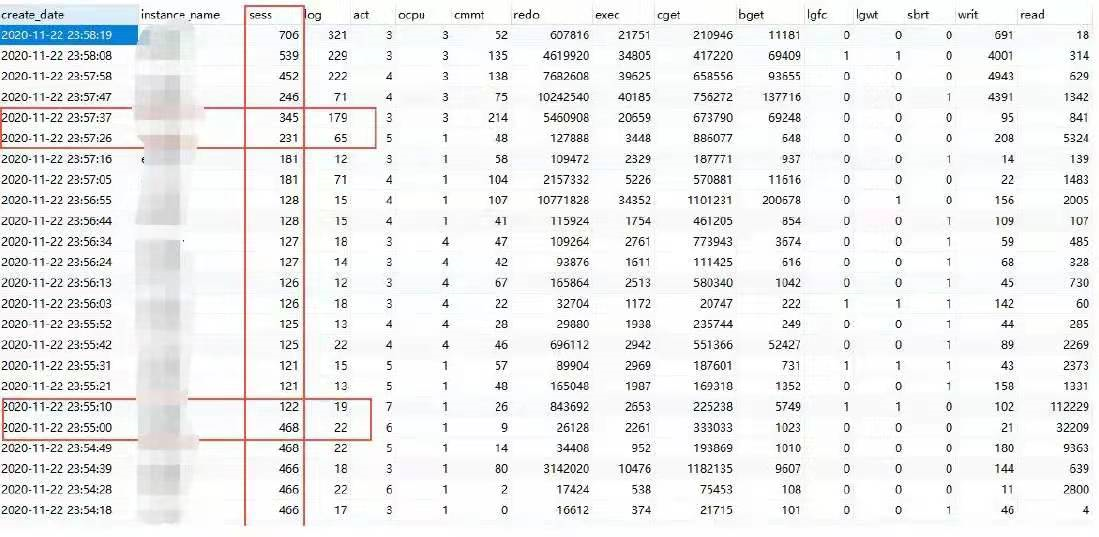
从数据库的监控数据看,11 月22 号23 点55 分以前,sess 连接数指标稳定在468 左右,从55 分开始,下降到127 左右,57 分开始又逐渐上升,58 分以后,数据库端连接数明显超过了之前的468,可以认为异常大概开始于22 号23:58 分。
DB agent 监控数据:
3、什么时候数据库无法连接?
一直到23 号0 点05 分,alert 日志出现达到最大连接数报错,数据库监控也无法连接进行数据采集,数据库监控数据停留在这个时间点。
4、数据库OS 主机性能指标数据有没有异常?
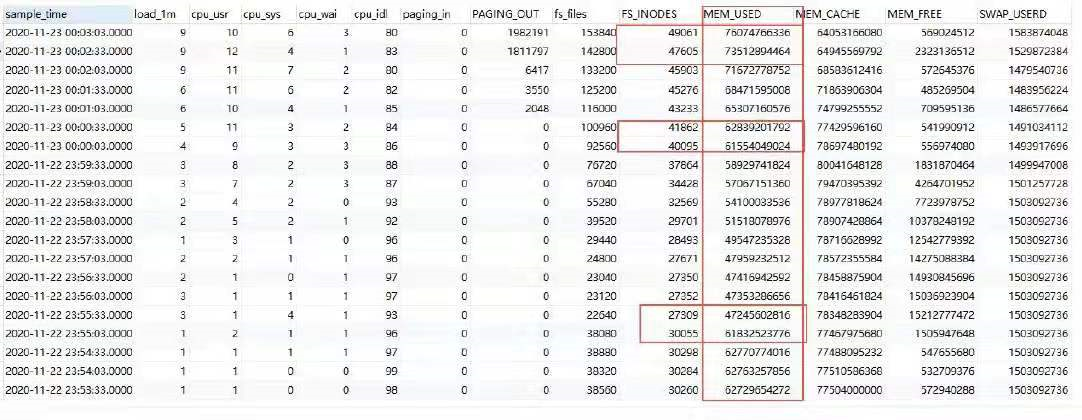
通过OS 采集到的监控数据,OS 层面出现了内存使用异常,可以看到mem_used 内存使用,随着23:55 的连接下降,出现内存释放(14635MB),随着57 分应用重启,连接数增加,内存使用开始增加,到23 号0 点01 分时,内存使用就和重启之前差不多了,后面随着时间的推移,OS 内存逐渐耗尽。
DB agent 监控数据(OS 指标):
5、OS 内存耗尽,是什么原因?
从数据库监控采集的数据分析,随之数据库连接数的增加,os 的内存使用也同步增加,连接数增加。
DB agent 监控的连接数:
-
2020-11-22 23:54 连接数468
-
2020-11-22 23:58:08 连接数539
-
2020-11-22 23:59:01 连接数1107
-
2020-11-22 23:59:54 连接数1498
-
2020-11-23 00:01:51 连接数2629
-
2020-11-23 00:03:54 连接数3396
从上面的连接数增量和os 内存的增量来算,每个连接os 分配了8MB 内存
SQL> select trunc((78426853376-47416942592)/1024/1024/3300) from dual;TRUNC((78426853376-47416942592
------------------------------8
DB agent 监控数据(OS 指标):
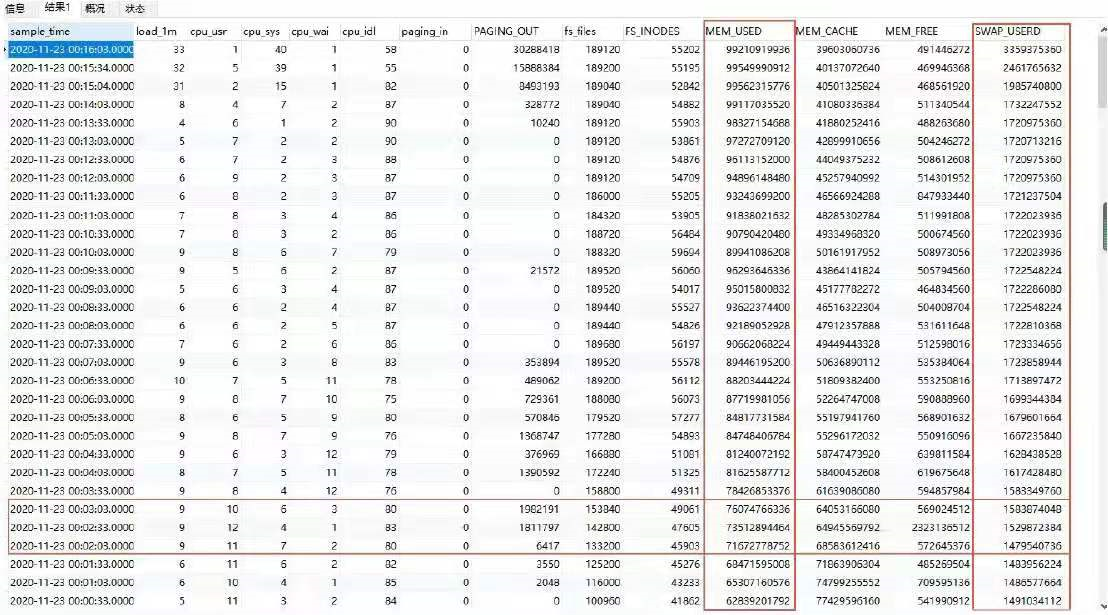
从02 分之后,内存使用逐渐增加,swap 使用也随之增加,直到15 分左右,os 的内存被完全使用完,随后swap 使用快速增加。
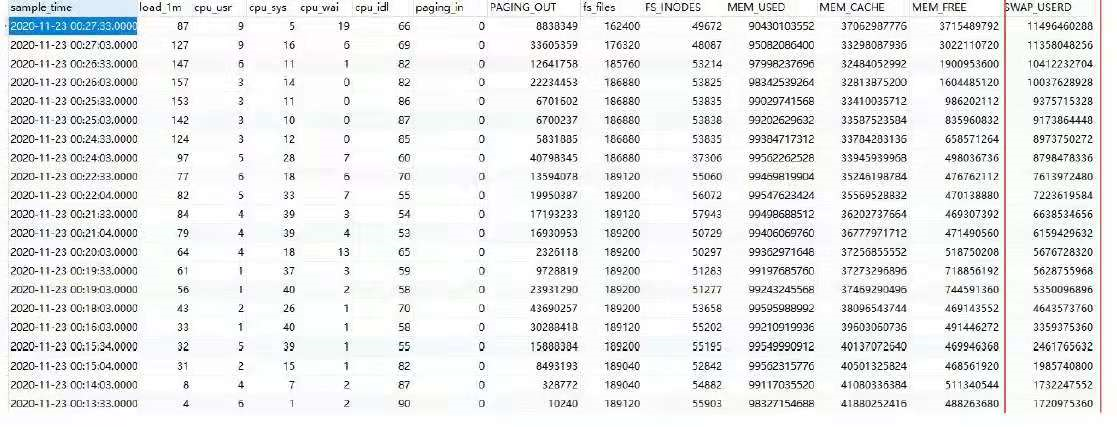
6、OS 内存耗尽,有没有大的SQL 查询?
DB agent 监控数据(图形化展示):
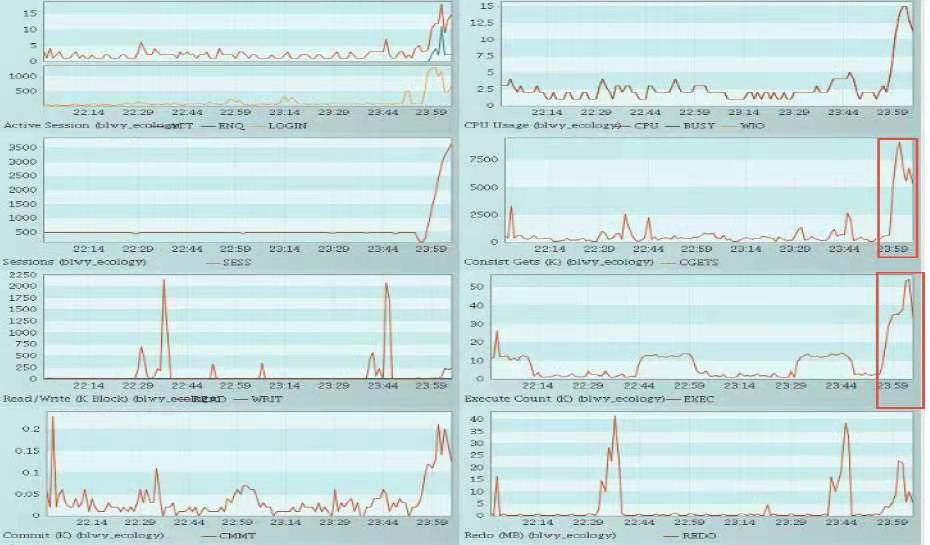
22 号23 的监控数据显示,指标变化最大的是数据库的cget 逻辑读和SQL 执行次数,从趋势图上,可以判断应为sql 执行次数增加导致了数据库的cget 逻辑读的增加;大查询,高消耗IO 等相应指标没有明显突变。
7、故障时段的SQL 执行次数异常是什么语句?
DB agent 监控数据(SQL 运行数据):
从采集的SQL 监控数据,按执行次数排序查询,集中在3 个sql 上: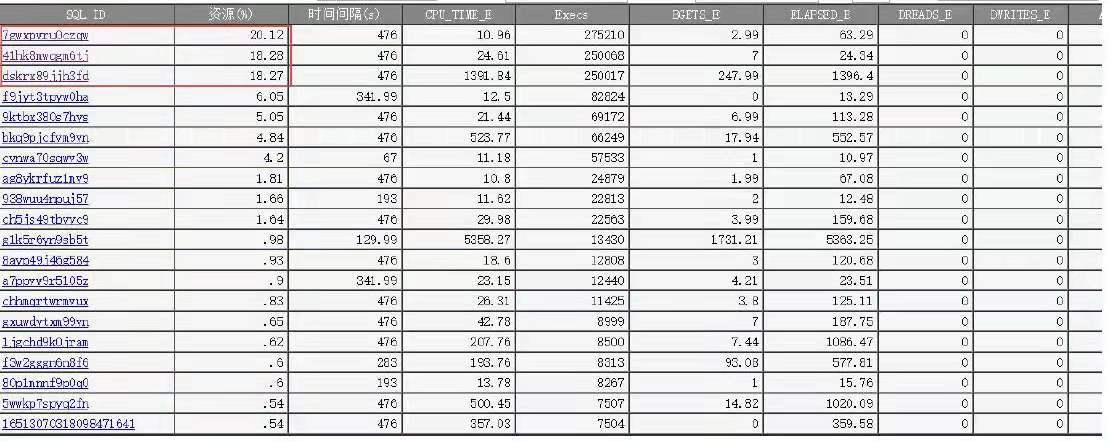
具体的sql文本我就不贴了。
8、故障时段,有没有行锁或者死锁?
如上监控图,没有明显的行锁或死锁,排查这个可能
9、为什么会有大量连接创建?
从23 点57 分到00:05,8 分钟左右时间,一共创建了8018 个数据库连接,但数据库端记录的sess 指标是3700 左右,排除掉正在创建的连接,推测有大量的连接创建后,又被应用连接池主动释放了,而这些频繁创建和释放的连接,一个可能是在执行高频但非常快的SQL(下面有列出来),也有可能是连接池代码,或者应用代码问题。
经最终确认,应用端的连接复用出现问题,又是程序的锅
。


















