
什么是微服务
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
– James Lewis and Martin Fowler (2014)
简而言之,微服务架构样式是一种将单个应用程序开发为一组小型服务的方法,每个小型服务都在自己的进程中运行并与轻量级机制(通常是HTTP资源API)进行通信。这些服务围绕业务功能构建,并且可以 由全自动部署机制独立部署。有一个集中管理的最低限度的这些服务,可以用不同的编程语言和使用不同的数据存储技术。
——詹姆斯·刘易斯和马丁·福勒(2014)
1、演进
微服务架构几乎都是从 ALL IN ONE 的单体架构演进而来,中间又经历了分布式架构、面向服务架构的演进过程。
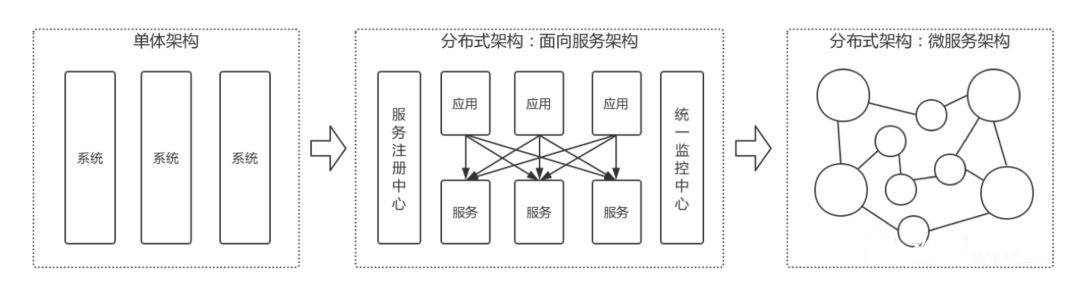
单体架构往往以烟筒式方式发展,往往存在两个主要问题:中心化和耦合度高。所谓中心化,就是数据集中存储在单个数据库中,业务系统集中部署在单台服务器上,通过集群部署方式提供服务能力,然而中心化的问题,也就是单点问题。而耦合度高,主要是指其中一个功能模块升级,其它的模块都得一起升级。这里要说明下,模块依赖度高不是单体架构的错,是因为本来架构可能就没有设计好,但是,在实际场景中,随着快速迭代开发,研发换了一波又一波,产品走了一茬又一茬,难免系统架构腐化严重。
看到了单体架构的诸多问题,系统开始通过按功能或模块进行拆分,拆分成多个独立的子系统,系统间通过 RPC、MQ 方式调用,由此逐渐演变为分布式的服务架构。分布式服务架构主要通过服务化和层次化进行解耦拆分,《架构整洁之道》书中提到一点,系统可以降解为策略和层次,而架构设计就是把相同的策略分到同一个组件中,反之,分属于不同的组件。所以,架构设计可以通过分层设计,由高层次服务调用低层次服务,低层次服务通过接口向上提供服务,以实现系统之间的解耦。也正是在这一阶段,单体架构一下子被拆分成几个或几十个系统。
但是随着架构的发展,问题又接踵而来,在没有做好边界的划分之前,系统拆分的服务往往是松散的。正如《架构整洁之道》所讲:软件架构设计本身就是一门划分边界的艺术。所以,很多系统在这一阶段,又往往进行了服务内聚和去层次化的演变过程。所谓服务内聚,就是以领域驱动设计为原则,重新界定领域边界,对模块进行服务整合,对系统进行合并。而去层次化,则是去除服务层次高低之分,按服务调用最优链路提供服务请求,降低深度,以此保证系统的稳定性能。
2、微服务技术
2.1 服务拆分
微服务讲究拆分,那么多微才是微,以及,怎么才是比较合理的拆分。在架构设计领域,有一个大家都在讲的著名定律:康为定律,可以理解为:一个系统架构的组织关系是和团队的组织关系相匹配的。如交易系统会对应一个交易系统的研发团队,商品系统会对应一个商品系统的研发团队,这种职责明确的组织结构会使得系统开发更高效。
拆分可以分为系统拆分、功能拆分和读写拆分。如一个单体系统中,按照用户的交互场景看,门户首页可以拆分为前台系统,类目、商品、搜索等功能可以拆分到商品中心,订单、结算、发票等功能则可以拆分到交易中心,这就是简单的系统拆分和功能拆分。而有些功能较为特殊,如商详页,在读取时需要聚合读取,所以又可以进行读写拆分
2.2 服务化
微服务首先需要有微服务基础设施,没有微服务基础设施,实践微服务就是一场灾难。以 SOA 落地方式为例,SOA 落地方式主要有:分布式服务化和集中式管理(ESB),分布式服务化的技术手段有 dubbo 或 spring cloud 等等,必须有整套的如服务发现、服务订阅、服务监控、服务追踪、服务日志等微服务基础设置,才能进行微服务架构。不能简单只有 p2p 的服务调用就开始服务化,那是不现实的。
2.3 服务治理
当服务拆分的设计方案确认完毕,而服务化的基础设施也部署到位,那么系统往往一下子就会突然发布出成百上千个服务接口,就像一个网络一样,每个服务或微服务就像网中的一个节点,彼此之间关联和联系。但是,服务网络应该被设计成为一个有向无环图,否则,就是一团麻。如开始的时候,只是 A 调用 B,但随着业务发展,需要修改,但是因为对 A 不了解,就加个环节 B 调用 A,如此形成了环形调用,不仅逻辑复杂了,还降低了稳定和性能。
这里的服务治理不是讲中间件团队的服务治理,如超时优化、启动优化等等,而是作为应用平台对服务的治理。服务治理又分为三个阶段:服务梳理、服务界定和服务编排。所谓服务梳理就是梳理系统对外开放的服务化接口,包括服务的 provider 和 consumer,以及服务分组、动态路由等依赖的梳理,然后对拆散的服务进行归类、界定,确定服务领域从属性,依据领域模型重新界定服务边界,最后通过服务迁移、切换,对同一领域的服务接口进行服务整合,提供统一的服务出口,实现服务编排。
为什么要进行服务治理?那先来看看不进行服务治理的坏处。
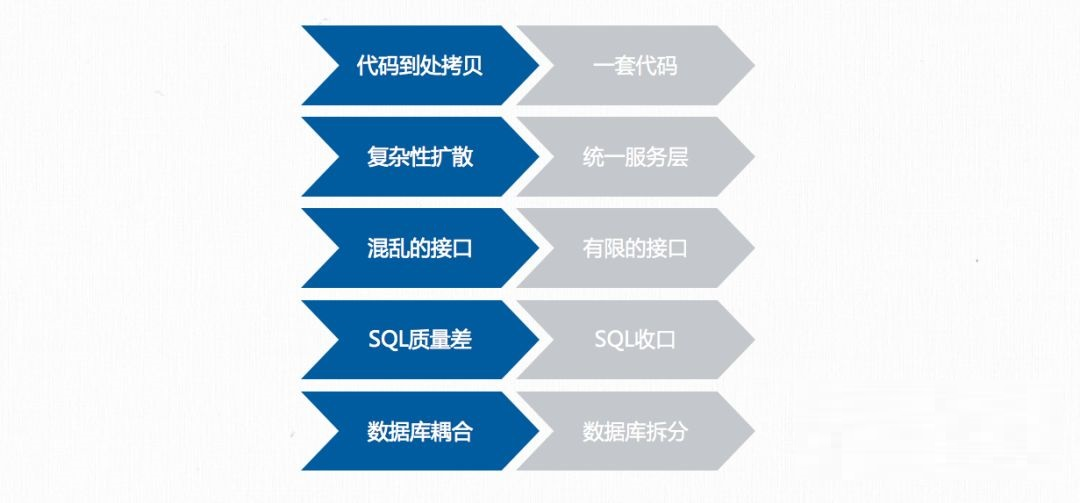
微服务化拆分必然会在初期产生代码到处拷贝,没有一套代码,必然会造成复杂的扩散,如同样语意的 A、B 两个接口,如果 A 接口存在性能问题需要加缓存,那么 B 接口也会存在同样的问题,并需要同样的改造,这样复杂度就会到处蔓延,同时也无法实现统一的服务层架构,还有,如果同样语意或相似语意的接口太多,那么接口就是混乱的,无法实现有限接口的治理,如果系统出了问题,可能很难定位问题。业务逻辑是依赖于数据的,如果接口是混乱的,那么慢 SQL 等质量差的 SQL 就无法进行有效收口改造,同样就更加难以实现数据库拆分和解耦。综上,服务治理的过程就是从无序到有序的过程。
总结一下看从拆分到服务化的过程,就是将原来一个整体的服务打碎,碎成一块一块的零碎服务,然后再对服务重新归类、整合,形成一个一个新领域的、独立的服务。如单体架构就像一个宏伟的城堡,如果相对其中一个点进行调整和改造,那么可能面临着牵一发而动全身的风险。
微服务化就是以一系列小的服务去支撑一个应用的方法论。简明扼要的说,就是:分而治之。
2.4 服务高可用
服务拆分并服务化之后,是不是就完事了,不!真正的微服务实践才刚刚开始,简单提供了一个接口,是没有意义的,它必须具备高可用、高性能、高并发的三高特性,尤以高可用最为重要。保障服务高可用的方法有很多,如数据异构、多级缓存、超时与重试、熔断、异步并发、降级、限流、消息队列、压测与预案等。
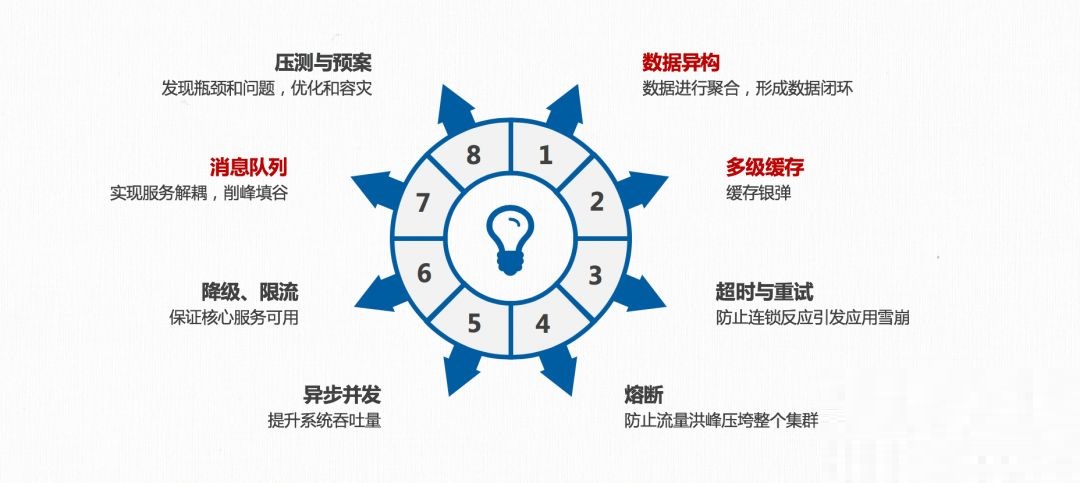
重点说下数据异构,所谓数据异构,就是将通过顺序消费或并发消费的方式,订阅 MySQL 数据库的 binlog,然后通过消息,如 Kafka 等 MQ 方式,异地存储到缓存或其它数据源中,如 Redis、Elasticsearch 等。数据异构现在被普通使用,实现数据聚合,形成数据闭环。
在进行数据异构的过程中,需要关注几个关键点,一是 CAP 原则,即强一致性往往被舍弃,而采用最终一致性的设计。二是缓存,缓存在微服务架构中,不能被当成银弹来使用,使用缓存必须正视的问题有:热点缓存 & 大 Value 缓存、缓存穿透等问题。三是消息,消息现在还存在的问题有:延迟问题、消息的不稳定性(如丢消息)、消息的不确定性(如 timeout)、消息补偿、柔性事务等问题。而这些是微服务高可用架构实践中,不能不面对的问题。
2.5 服务隔离
隔离也是服务拆分的一种,为什么单独讲?因为服务拆分、服务化、服务治理和服务高可用都是在事前或事中可以做的,然而,有些系统已经成了某个样子,那么我们接收时,首先能做到的就是迅速对系统进行隔离,保证业务之间不互相影响,具体实践包括:进程线程隔离、集群/机房隔离、读写隔离、动静隔离、爬虫/热点隔离等。
从单体架构开始,到分布式架构设计、微服务架构,再到现在领域驱动设计,作为实践微服务的架构师,思想上又有什么变化?
我觉得,程序员都是很闷骚的,但每个程序员心里都住一个大侠,金庸《笑傲江湖》里有气宗和剑宗之分,什么是剑宗,我理解就像是剑招、招数,如 spring、spring boot、spring cloud,还有 tomcat、netty、serviceless 等,这些技术、中间件、框架等就像脚手架一样可以帮助我们提高效率,但是,我们是否需要出现一个新技术就学习一个技术呢?而这就让我想到了气宗,它就像是通过对内在规律的掌握,打通任督二脉,实现融会贯通,正如《九阳神功》所说:他强任他强,清风拂山岗,我自一口真气足。如 Kakfa、Flink、Hbase 等分区可用性保障的设计思想都是基于 BigTable 的分区复制策略。
正是重心由外到内的转变,让我认知到,现在系统架构的发展,很多系统架构的复杂度,已经不是简简单单通过引入一些新技术或框架,就能降低系统复杂的。它需要大大的提前对风险、问题、隐患的预知,做到未雨绸缪。《从零开始学架构》书中提到:架构设计的发展历程就是在于降低软件系统复杂的历程。
《架构整洁之道》书中提到:一个软件系统存在的意义,是系统用来赚钱或省钱的那部分代码,那才是整个系统的皇冠明珠。所以,当拿到一个需求的时候,首先考虑的是要解决什么问题,它的问题域是什么,而不是先考虑用哪种技术去实现或解决这个问题,这是本末倒置的处理方法。
从领域驱动设计的角度来看,需求首先是问题域,属于业务边界的事情,梳理了解要实现什么功能和需求,然后在外延到工作边界,确认团队合作的方式,因为很多需求都可能需要跨团队合作的,最后才会到应用边界,即技术实现的解决问题领域。
3、为什么采用微服务
就像很难用一个绝对的方式去判断架构好坏一样,在大多数场景下,我们也很难从一个外部的视角去判断服务拆分粒度的合理性,需要对上下文非常了解才能做出一个好决策。例如,团队规模多大,代码规模多大,有没有平台化,有没有工具链,是否需要持续交付,团队文化如何等。因此,一个外部的架构师是很难在短时间内将架构规划合理的,这需要一个过程,当真正了解这一切之后,不断权衡,最终确定。在划分之前,有必要参考表2-1,综合各方面的情况,最终做出决策。
单体架构VS微服务架构
| 因素 | 单体架构 | 微服务架构 | 说明 |
|---|---|---|---|
| 交付速度 | 较慢 | 较快 | 服务拆分后,各个服务可以独立并行开发、测试、部署,交付效率提升,产品的更新速度会更快,用户体验更好。代码规模越大,微服务的优势越明显 |
| 故障隔离范围 | 线程级 | 进程级 | 服务独立运行,通过进程的方式隔离,使故障范围得到有效控制、架构变得更简单可靠。根据业务的重要程度划分服务,把核心的业务划分为独立的服务,这样可以从数据库到服务,保持有效的故障隔离,进而保持稳定 |
| 整体可用性 | 较低 | 更高 | 微服务架构由于故障范围得到有效隔离,整体可用性更高,降低一点故障对整体的影响 |
| 架构持续演进 | 困难 | 简单 | 由于微服务的粒度更小,架构演进的影响面就更小。不存在大规模重构导致的各种问题。微服务架构对架构演进更友好 |
| 沟通效率 | 低 | 高 | 业界普遍认为团队规模越大,沟通效率越低,微服务架构按业务构建全功能团队,把权利下放,不会出现决策瓶颈点,降低沟通规模,提升沟通效率 |
| 技术栈选择 | 受限 | 灵活 | 如果某个业务需要独立的技术栈,可以通过服务划分,接口集成的方式实现。例如搜索,技术栈、专业细分领域都不相同,通常采用独立的服务实现 |
| 可扩展性 | 受限 | 灵活 | 微服务架构可以根据服务对资源的要求以服务为粒度扩展,符合AKF扩展立方体中的Y轴扩展,而单体架构只能整体扩展,只能做到AKF扩展立方体中的X轴扩展 |
| 可重用性 | 低 | 高 | 微服务架构可以实现以服务为粒度通过接口共享重用 |
| 实现业务复杂性分解难度 | 困难 | 容易 | 微服务架构通过将业务分解为更多的服务,业务边界更清晰,更容易把一个复杂的问题分解为简单的小问题 |
| 产品创新复杂度 | 困难 | 容易 | 微服务架构以服务为粒度独立演进,团队有更多的自主决策权,更多的试错机会,更利于创新 |
| 一致性实现成本 | 低 | 高 | 服务划分后,如果服务A同时调用服务B和服务C,如何保证同时成功或失败?单体架构下的单库事务变成了分布式事务问题 |
| 时延 | 低 | 高 | 服务划分后,调用次数增加,响应时间必然升高,吞吐量降低,如何弥补 |
| 资源成本 | 低 | 高 | 吞吐量的下降意味着要增加更多的资源,对于交付型项目,特别是小规模部署的场景下,是比较致命的 |
| 关联查询复杂度 | 简单 | 复杂 | 微服务架构的一个非常明显的特征就是一个服务所拥有的数据只能通过这个服务的API来访问。通过这种方式来解耦,这样就会带来查询问题。以前通过join就可以满足要求,现在如果需要跨多个服务集成查询就会非常麻烦 |
| 远程调用 | 不涉及 | 涉及 | 微服务存在更多的远程调用,需要额外考虑序列化、通信协议、数据压缩、服务间的负载均衡、容错等问题 |
| 服务治理 | 不涉及 | 涉及 | 由于服务数量变多,微服务架构需要额外考虑服务的注册发现、依赖关系、治理等问题 |
| 对开发人员的要求 | 低 | 高 | 微服务架构更复杂,开发人员端到端负责,既要考虑接口定义,又要考虑数据库设计,对开发人员的水平要求更高 |
| 对工具的依赖 | 较低 | 较高 | 微服务架构中服务的数量较多,使用工具的效果更明显,依赖程度更高 |
| 运维复杂度 | 低 | 高 | 微服务架构中服务的数量较多,对服务的监控、健康检查要求更高,整体运维复杂度更高 |
4、设计原则
在微服务架构的设计过程中,我们应该遵循哪些原则?以下原则在微服务架构中经常被提起,遵循这些原则能够让我们少走弯路。
4.1 垂直划分优先原则
应该根据业务领域对服务进行垂直划分,因为水平划分服务可能会导致如下问题。
• 调用次数更多导致性能大幅下降。
• 实现一个功能要跨越更多服务,沟通成本升高。
垂直划分服务可以以最简单的方式缓解上述问题,并且可以让团队从上至下关注业务实现,端到端负责,持续改进。图2-2简单描述了一个按业务领域垂直划分的微服务架构示例,在业务垂直方向切分服务,通过API Gateway聚合内容。
4.2 持续演进原则
服务数量快速增长带来架构复杂度急剧升高,开发、测试、运维等环节很难快速适应,会导致故障率大幅增加,可用性降低,非必要情况,应逐步划分,持续演进,避免服务数量的爆炸性增长,这等同于灰度发布的效果,先拿出几个不太重要的功能拆分出一个服务做试验,如果出现故障,则可以减少故障的影响范围。另外,除了业务服务数量的增加,还需要准备持续交付的工具、微服务框架等,加强监控。
4.3 服务自治、接口隔离原则
尽量消除对其他服务的强依赖,这样可以降低沟通成本,提升服务稳定性。服务通过标准的接口隔离,隐藏内部实现细节。这使得服务可以独立开发、测试、部署、运行,以服务为单位持续交付。
直接访问对方的数据库会造成一定的耦合性,应该尽量避免。
4.4 自动化驱动原则
部署与运维的成本会随着服务的增多呈指数级增长,每个服务都需要部署、监控、日志分析等运维工作,成本会显著提升。在服务划分之前,应该首先构建自动化的工具及环境。开发人员应该以自动化为驱动力,简化服务在创建、开发、测试、部署、运维上的重复性工作,通过工具实现更可靠的操作。避免微服务数量增多带来的开发、管理复杂度问题。自动化可以从多个方面节省时间、提升效率,它可以快速跟踪整个交付过程并实时向所有参与者报告这个过程,赋予参与者责任感和成就感,如研发过程中,推行持续集成的文化就特别重要,而持续集成所依赖的工具就是一种自动化的体现。
很多互联网公司都遵循“一切皆自动化”的原则,特别是存在跨地域的研发模式时,使用自动化工具将是至关重要的,如开源的协作模式。
5、服务化分
5.1 拆分前
*在服务划分之前,应该保证基础设施及公共基础服务已经准备完毕,可以通过监控快速定位故障,通过工具自动化部署、管理服务,通过服务化框架降低服务开发的复杂度,通过灰度发布提升可用性,通过资源调度服务快速申请、释放资源,通过弹性伸缩快速扩展应用。*
摘自Martin Fowler的博客。
As I hear stories about teams using a microservices architecture, I’ve noticed a common pattern.
- Almost all the successful microservice stories have started with a monolith that got too big and was broken up
- Almost all the cases where I’ve heard of a system that was built as a microservice system from scratch, it has ended up in serious trouble.
当我听到关于使用微服务架构的故事的时候,我注意到了一种通用的模式。
几乎所有成功的微服务故事都是从一个庞然大物开始的,它变得太大,然后被分解
几乎所有我听说过的作为微服务系统从零开始构建的系统都遇到了严重的麻烦。
5.2 微服务拆分粒度决策参考表
| 序号 | 因素 | 决策占比 | 说明 |
|---|---|---|---|
| 1 | 团队规模 | 50% | 当团队规模变大,会出现决策瓶颈点,即所有的决策都要依赖于某个会议或某个人,没有人愿意承担责任,效率十分低下 |
| 2 | 交付速度要求 | 30% | 毫无疑问,拆分粒度越小,交付时受到的约束越小,速度就越快 |
| 3 | 其他 | 20% | 例如,对占用资源的要求、对性能的要求、对一致性的要求、对架构演进速度的要求、对创新速度的要求 |
5.3 拆分前先做好解耦
解耦这个词汇来源于数学,是指使含有多个变量的数学方程变成能够用单个变量表示的方程组,即变量不再同时共同直接影响一个方程的结果,从而简化分析计算。
在软件世界里,解耦强调的是每个单元可以独立变化,尽量减少外界的影响。说白了也就是,如果把Memcache换成Redis,那么需要多少工作量,涉及的修改面有多大。但是,解耦也会带来工作量的增加,架构或者代码变得复杂等问题。例如很多人会假设把Oracle换成MySQL,Memcache换成Redis,但是在实际的情况中,并不是所有的业务发展速度都有这么快,如果能预料到短期将发生变化,为什么不直接使用MySQL呢?通常这是一个伪命题。如果在未来几年后才发生变化,那么现在去做相应的适配,这不符合敏捷开发的哲学思想,也不是一个高效率的思路。
在转向微服务架构之前,业务服务存在状态、数据库中存在触发器和存储过程、服务之间绕过接口调用等问题是我们首先要解决的。
5.4 拆分前注意事项
5.4.1 独立于业务服务
以下三种常见的状态需要和业务服务拆分开来,否则扩展性将受到很大限制。
(1)定时任务。
因为大多数任务不能重复触发,轻则重复做无用功(幂等的情况下),重则会导致不一致。例如从A表中把数据迁移到B表中,如果在两个服务中同时处理,没有一个协调器的话,会导致重复拉取。所以,需要把定时任务从业务服务中提取出来,通过分布式任务调度统一协调。
(2)本地存储。
在本地存储文件也是比较常见的,当有多个实例的时候,要么全部同步一遍,要么需要根据用户路由到同一个实例,并且在伸缩的过程中,需要迁移。
(3)本地缓存。
某些业务会将数据存放在本地做缓存,例如Session数据,如果要去掉本地缓存,则可以通过分布式缓存和Cookie解决业务服务带状态的问题。
当然,本地缓存也有适用的业务场景,不能一概而论。
5.4.2 去触发器、存储过程
触发器、存储过程在系统规模比较小的时候,的确非常简单实用。但是,随着业务的发展,业务服务比较容易扩展,数据库通常变成了伸缩的瓶颈,许多方案都是为了平衡数据库的压力,触发器、存储过程可能会带来如下问题。
• 整体的伸缩受到数据库的限制,因为触发器、存储过程难以扩展。
• 当存在水平分表的时候,可能无法满足需求。
• 如果触发器、存储过程过多,则会导致运维复杂度升高。
解决方案通常是通过外部的业务服务或者定时任务替换触发器及存储过程。
5.4.3 通过接口隔离
直接访问其他服务的数据库,如图2-3所示。CRM直接调用OA的数据库,没有通过接口调用,当我们对CRM进行微服务架构拆分之前,需要先理清系统的外部依赖关系,如果存在多个系统共享一个数据库,就会导致耦合问题,影响可用性和扩展性,可能出现如下问题。
• 当CRM中的数据结构发生变化的时候,OA也要跟着变化,导致开发的过程互相依赖。
• 有可能在CRM进行的限流是没用的,因为OA没有通过CRM提供的接口进行调用。
• 假设随着业务的发展,需要在CRM的数据库上做缓存,可能存在多个地方要考虑缓存的问题。
总之,接口应该作为唯一对外提供的访问方式,这代表的是控制力。解决方法就是通过接口调用,逐步去除数据库的直接访问。
5.5 划分模式
5.5.1 基于业务复杂度选择服务划分方法
根据业务复杂度划分服务,如图所示。当业务复杂度足够高的时候,应该基于领域驱动划分服务,而领域驱动本身足够复杂,很多概念比较抽象,应用范围并不是特别广泛,所以当业务复杂度较低时,可以选择基于数据驱动模式划分服务,数据驱动模式更容易理解和上手,也就是说,除非业务复杂度非常高,否则应该优先以数据驱动模式划分服务。这里的业务复杂度专指业务逻辑,而非数据量、并发量等相关复杂度。
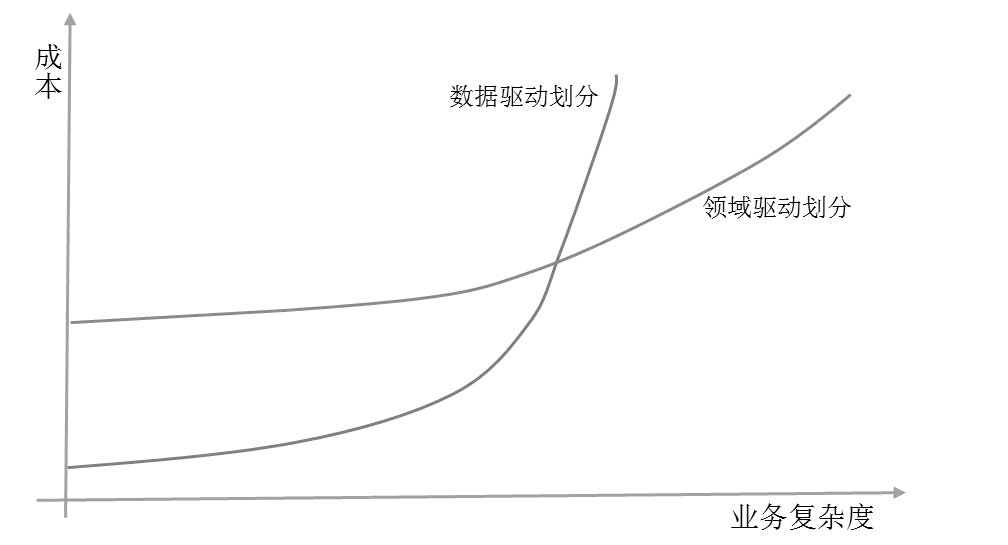
在做出选择的时候,还有一个参考指标是,团队以前是否已经基于领域驱动开发业务,也就是说如果产品已经基于领域驱动开发了一段时间,具备了领域驱动开发的能力,那么当然推荐继续选择领域驱动划分服务。如果是一个全新的产品,则可以灵活选择。
选择服务划分的方法要重点考虑的条件如下。
• 业务复杂度。
• 团队对领域驱动的熟悉程度。
5.5.2 基于数据驱动划分服务
数据驱动是一个自下而上的架构设计方法,数据驱动强调的是数据结构,也就是通过分析需求,确定整体数据结构,根据表之间的关系划分服务。
通常基于数据驱动划分服务的步骤如下。
-
第一步,需求分析。通过领域专家(或者产品经理)确定目标,然后总结user story,确定核心的业务流程。通过工具呈现比较粗糙的界面,内部讨论。不断迭代此环节,直到满意为止。
-
第二步,抽象数据结构。根据需求总结use case,协助分析需求,从中抽象数据结构。
-
第三步,划分服务。分析数据结构,识别服务,服务应该满足高内聚、低耦合、单一职责等特征。
-
第四步,确定服务调用关系。先分析出主要流程,根据请求需要调用的服务确定服务调用关系。如果存在问题,需要从第一步重新开始。
-
第五步,业务流程验证。重新回到user story,以服务为粒度实现时序图,注意此阶段重点是要验证服务划分是否合适,要关注如下问题。
• 一次更新操作如果要跨越更多服务,那么一致性的要求是什么。
• 跨服务查询时,是否要做关联查询,一个服务内是否能解决问题。
• 性能是否能满足要求。
• 成本是否满足要求。
-
第六步,持续优化。
5.5.3 基于领域驱动划分服务
领域驱动是一个自上而下的架构设计方法,通过和领域专家建立统一的语言,不断交流,确定关键业务场景,逐步确定边界上下文。领域驱动更强调业务实现效果,认为自下而上的设计可能会导致技术人员不能更好地理解业务方向,偏离业务目标。
通常基于领域驱动划分服务的步骤如下。
- 第一步,通过模型和领域专家建立统一语言。建立统一语言是为了更深入的理解需求,通用语言尽量以业务语言为主,而非技术语言。通用语言和代码一样,需要不断的重构。
- 第二步,业务分析。确定核心的业务流程,然后逐步扩展到全部。最好通过工具呈现比较粗糙的界面,内部讨论。
- 第三步,寻找聚合。显式地定义了领域模型的边界。为大家介绍一下最近比较热门的事件风暴,事件风暴是一种基于领域驱动分析业务,划分服务的方法。
事件风暴就是把所有的关键参与者都召集到一个很宽敞的屋子里来开会,并且使用便利贴来描述系统中发生的事情,如图2-5所示。
• 用桔黄色的便利贴代表领域事件,在上面用一句话描述曾经发生过什么事情。
• 用蓝色的便利贴代表命令。命令的发起者可能是人,是注入系统中的外部事件,或是定时器等。
• 用黄色的便利贴代表聚合,聚合是一组相关领域对象的集合,高内聚,低耦合,聚合内保证数据一致性。

** **
-
第四步,确定服务调用关系。先分析出主要流程,根据一次请求需要调用的服务确定服务调用关系。如果存在水平划分,则需要根据服务依赖原则确定关系。如果存在问题,则需要从第一步重新开始。
-
第五步,业务流程验证。以服务为粒度实现时序图,注意此阶段重点是要验证服务划分是否合适,重点要关注的问题如下。
• 一次更新操作如果要跨越更多服务,那么一致性的要求是什么。
• 跨服务查询时,是否要做关联查询,一个服务内是否能解决问题。
• 性能是否能满足要求。
• 成本是否满足要求。
-
第六步,持续优化。
5.5.4 从已有单体架构逐步划分服务
6 小结
- 架构决定了软件的各种非功能性因素,比如可维护性、可测试性、可部署性和可扩展性,它们会直接影响开发速度。
- 微服务架构是一种架构风格,它给应用程序带来了更高的可维护性、可测试性、可部署性和可扩展性。
- 微服务中的服务是根据业务需求进行组织的,按照业务能力或者子域,而不是技术上的考量。
有两种分解模式:
- 按业务能力分解,其起源于业务架构。
- 基于领域驱动设计的概念,通过子域进行分解。
- 可以通过应用DDD并为每个服务定义单独的领域模型来消除上帝类,正是上帝类引起了阻碍分解的交织依赖项。
上帝类一般指的是维护了太多功能的类。
上帝类:有些开发者为了贪图简便,看到一个现成的类,也不管这个类是做什么的,需要追加功能时,就向这个类里面添加功能代码。久而久之,使得一些类变成了“上帝类”。什么是“上帝类”?上帝类也叫万能类,意指做了太多“事情”的类。
https://martinfowler.com/articles/microservices.html
https://blog.csdn.net/ioniconline/article/details/84099394


















