
技术架构选型
在数据模型设计之前,您需要首先完成技术架构的选型。本教程中使用阿里云大数据产品MaxCompute配合DataWorks,完成整体的数据建模和研发流程。
完整的技术架构图如下图所示。其中,DataWorks的数据集成负责完成数据的采集和基本的ETL。MaxCompute作为整个大数据开发过程中的离线计算引擎。DataWorks则包括数据开发、数据质量、数据安全、数据管理等在内的一系列功能。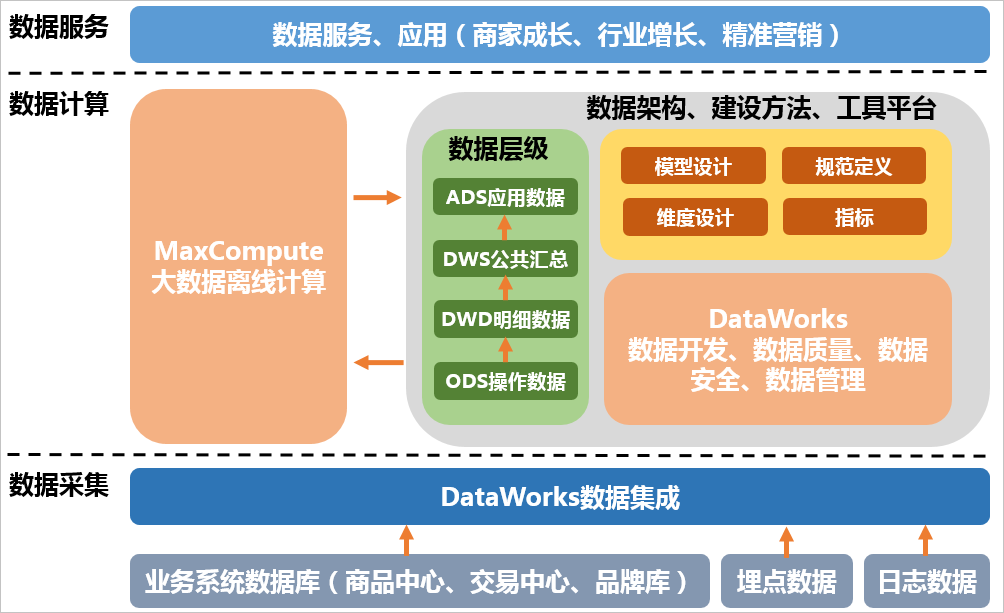
数仓分层
我们建议将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。
数据仓库的分层和各层级用途如下图所示。
- 数据引入层ODS(Operation Data Store):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到MaxCompute的职责,同时记录基础数据的历史变化。
- 数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
- 公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。 公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
- 公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。 公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
- 明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。 明细粒度事实层的表通常也被称为逻辑事实表。
- 数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。整体数据分类架构如下图所示。 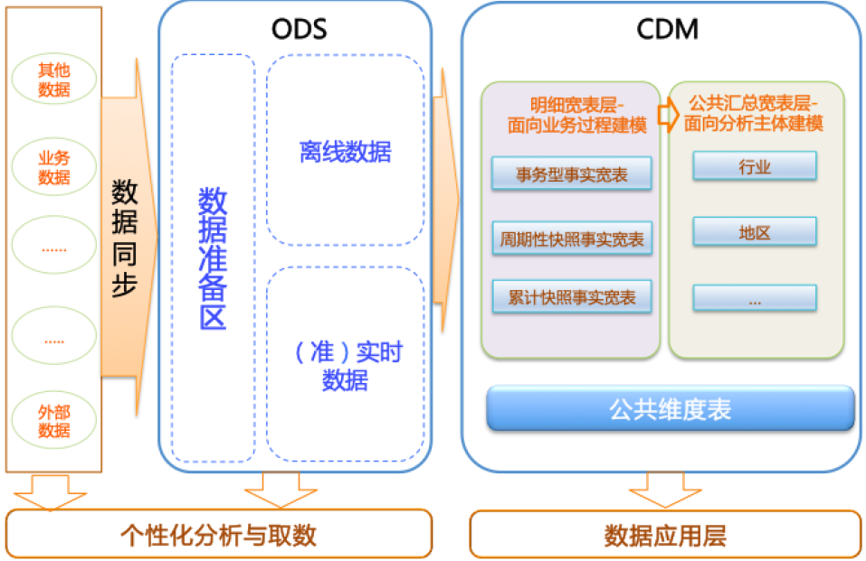
整体的数据流向如下图所示。其中,ODS层到DIM层的ETL(萃取(Extract)、转置(Transform)及加载(Load))处理是在MaxCompute中进行的,处理完成后会同步到所有存储系统。ODS层和DWD层会放在数据中间件中,供下游订阅使用。而DWS层和ADS层的数据通常会落地到在线存储系统中,下游通过接口调用的形式使用。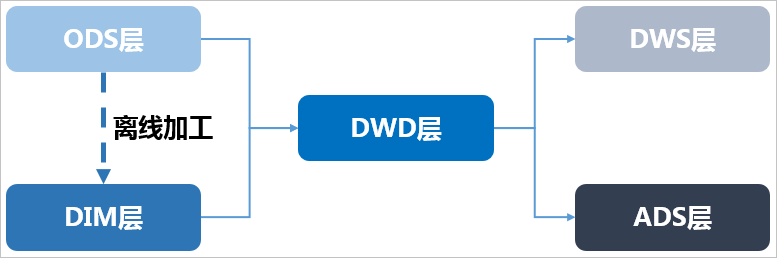
层次调用规范
在完成数据仓库的分层后,您需要对各层次的数据之间的调用关系作出约定。
层次调用规范
ADS应用层优先调用数据仓库公共层数据。如果已经存在CDM层数据,不允许ADS应用层跨过CDM中间层从ODS层重复加工数据。CDM中间层应该积极了解应用层数据的建设需求,将公用的数据沉淀到公共层,为其他数据层次提供数据服务。同时,ADS应用层也需积极配合CDM中间层进行持续的数据公共建设的改造。避免出现过度的ODS层引用、不合理的数据复制和子集合冗余。总体遵循的层次调用原则如下:
- ODS层数据不能直接被应用层任务引用。如果中间层没有沉淀的ODS层数据,则通过CDM层的视图访问。CDM层视图必须使用调度程序进行封装,保持视图的可维护性与可管理性。
- CDM层任务的深度不宜过大(建议不超过10层)。
- 一个计算刷新任务只允许一个输出表,特殊情况除外。
- 如果多个任务刷新输出一个表(不同任务插入不同的分区),DataWorks上需要建立一个虚拟任务,依赖多个任务的刷新和输出。通常,下游应该依赖此虚拟任务。
- CDM汇总层优先调用CDM明细层,可累加指标计算。CDM汇总层尽量优先调用已经产出的粗粒度汇总层,避免大量汇总层数据直接从海量的明细数据层中计算得出。
- CDM明细层累计快照事实表优先调用CDM事务型事实表,保持数据的一致性产出。
- 有针对性地建设CDM公共汇总层,避免应用层过度引用和依赖CDM层明细数据。
数据模型
下一期揭晓,未完待续……


















