Android四大基本组件介绍与生命周期
Android四大基本组件分别是Activity,Service服务,Content Provider内容提供者,BroadcastReceiver广播接收器。一:了解四大基本组件Activity :应用程序中,一个Activity通常就是一个单独的屏幕,它上面可以显示一些控件也可以监听并处理用户的事件做出响应。Activity之间通过Inten
转载
2023-08-31 01:17:53
23阅读
一、Hadoop的组件: 1、HDFS 一个高可靠、高吞吐量的分布式文件系统 存储海量数据 分布式 安全性 副本数据 数据是以block的方式进行存储的,128M 比如:200M---128M 72M 2、MapReduce 一个分布式的离线并行计算框架 &nbs
转载
2023-07-06 18:36:16
133阅读
javaWeb有三大组件:Filter、Servlet、Listenerjsp有九大内置对象:application、session、request、response、out、page、pagecontent、config、exceptionjavaEE三大组件技术:Servlet,JSP,EJB Servlet(Server Applet),全称Java Servlet,未有中文译文。是用Ja
记录学习,有错欢迎指正目录前言1、hadoop简介2、hadoop的组成3、HDFS(Hadoop Distributed File System)4、Yarn5、MapReduce6、Common前言大数据(Big Data)是什么:指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
转载
2023-07-12 13:42:01
104阅读
点赞

目录概述Docker的优点三大组件部署镜像加速优化网络相关命令相关镜像操作创建镜像标签删除镜像 概述Docker是基于容器技术的轻量级虚拟化解决方案,docker是由容器引擎,把linux的cgroup、namespace等容器底层技术进行完美的封装、并抽象为用户提供从创建和管理容器的便捷界面(Cli、api等)C/SDocker的优点docker把容器化技术做成了标准化平台CAAS (dock
HadoopHDFS组成HDFS主要有两个要素组成,NameNode和DataNodeNameNode元数据节点,类似于数据的目录,在响应请求的时候,会现在NameNode中查找数据存放在哪个DataNode中,类似与一本书的目录管理HDFS的名称空间配置副本策略管理数据块(Block)映射信息处理客户端读写请求DataNode数据节点,真正存放数据的地方存储实际的数据块HDFS的文件是按块进行存
转载
2023-07-12 13:41:36
285阅读
STL三大组件一、容器二、算法三、迭代器#define _CRT_SECURE_NO_WARNINGS#include<iostream>#include<vector>#include<algorithm>using namespace std;//STL 中的容器 算法 迭代器void test01(){ vector<int> v; //STL 中的标准容器之一 :动态数组 v.push_back(1); //vect
原创
2021-08-14 00:01:37
428阅读
Kubernetes是一个开源的容器编排平台,用于自动化管理、部署和扩展容器化应用程序。它通过使用三个核心组件来实现这个目标:kube-apiserver、kube-controller-manager和kube-scheduler。本文将详细介绍这三个组件的作用和使用方法,并提供相应的代码示例。
### 一、Kubernetes三大组件
在使用Kubernetes之前,我们需要了解三个核心组
# OpenStack三大组件科普
在云计算领域,OpenStack可以说是一个非常重要的开源项目,它由一系列的软件组件组成,用于搭建和管理公有云和私有云。其中,OpenStack最核心的就是三大组件:Nova、Neutron和Cinder。这三大组件分别负责计算、网络和存储的管理,是构建云计算基础设施的重要组成部分。
## Nova
Nova是OpenStack的计算服务组件,主要负责虚拟
## Hadoop三大组件科普
Hadoop是一个开源的分布式计算框架,旨在解决大规模数据处理和分析的问题。它由三个核心组件组成:Hadoop分布式文件系统(HDFS),Hadoop MapReduce和Hadoop YARN。本文将介绍这三个组件,并提供相应的代码示例。
### Hadoop分布式文件系统(HDFS)
HDFS是Hadoop的存储系统,用于存储和管理大规模数据集。它的设计目
原创
2023-07-23 04:17:08
169阅读
Hadoop三大组件HDFS见名知意HDFS:分布式文件系统,基本是围绕着这几部分走的Client,NameNode、Secondary NameNode、DateNode。 Client:上传文件时按照Block块大小进行文件的切分;和NameNade交互,获取文件位置信息;和DataNode交互,读取和写入数据;管理和访问整个HFDS; NameNode:管理命名空间NameSpace;管理B
文章目录HDFS(分布式文件存储系统)NameNode与Datanode的总结概述3.1.namenode 元数据管理3.2.Datanode 数据存储HDFS的架构图HDFS的执行过程HDFS的文件读取过程HDFS基本Shell操作HDFS的api操作Mapreduce(分布式计算组件)Hadoop MapReduce设计构思WordCount实例yarn(资源调度管理器)yarn当中的调度器
转载
2023-07-12 13:41:55
124阅读
目录一、前言二、角色描述1、角色类比2、角色划分三、组件介绍1、DAGScheduler2、TaskScheduler3、SchedulerBackend四、总结回顾一、前言认识了 Spark 进程模型中的 Driver 和 Executors、以及它们之间的交互关系。Driver 负责解析用户代码、构建计算流图,然后将计算流图转化为分布式任务,并把任务分发给集群中的 Executors 交付运行
转载
2023-08-11 20:23:03
98阅读
Hadoop是什么?由Apache基金会开发的分布式系统基础架构海量数据的存储和分析计算 Hadoop架构历史:1.0 HDFS和MapReduce2.0 在1.0基础上增加了YARN(任务调度),解放了MapReduce3.0 和2.0类似,着重优化 Hadoop优势:1)高可靠性 多数据副本2)高扩展性 动态扩展,动态删除(有案例)3)高效性:并行工作,加快任务处理速度3
转载
2023-07-01 12:02:10
158阅读
一、hadoop三大核心组件HDFS(Hadoop Distribute File System):hadoop的数据存储工具。YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。Hadoop MapReduce:分布式计算框架二、HDFS文件系统的读写原理在HDFS中,关键的三大角色为:NameNode(命名节点)、DataN
1、容器是 Docker 又一核心概念。简单的说,容器是独立运行的一个或一组应用,以及它们的运行态环境。对应的,虚拟机可以理解为模拟 运行的一整套操作系统(提供了运行态环境和其他系统环境)和跑在上面的应用。1.1、启动容器1.1.1、docker run 启动[root@bfd-v7 ~]# docker run ubuntu:12.04 /bin/echo 'Hello docker'
Hel
Broadcast 是 Android 四大组件之一,是一种广泛运用在应用程序之间异步传输信息的机制。Broadcast 本质上是一个Intent 对象,差别在于 Broadcast 可以被多个 BroadcastReceiver 处理。Broadcast...
转载
2017-09-15 08:02:00
93阅读
2评论
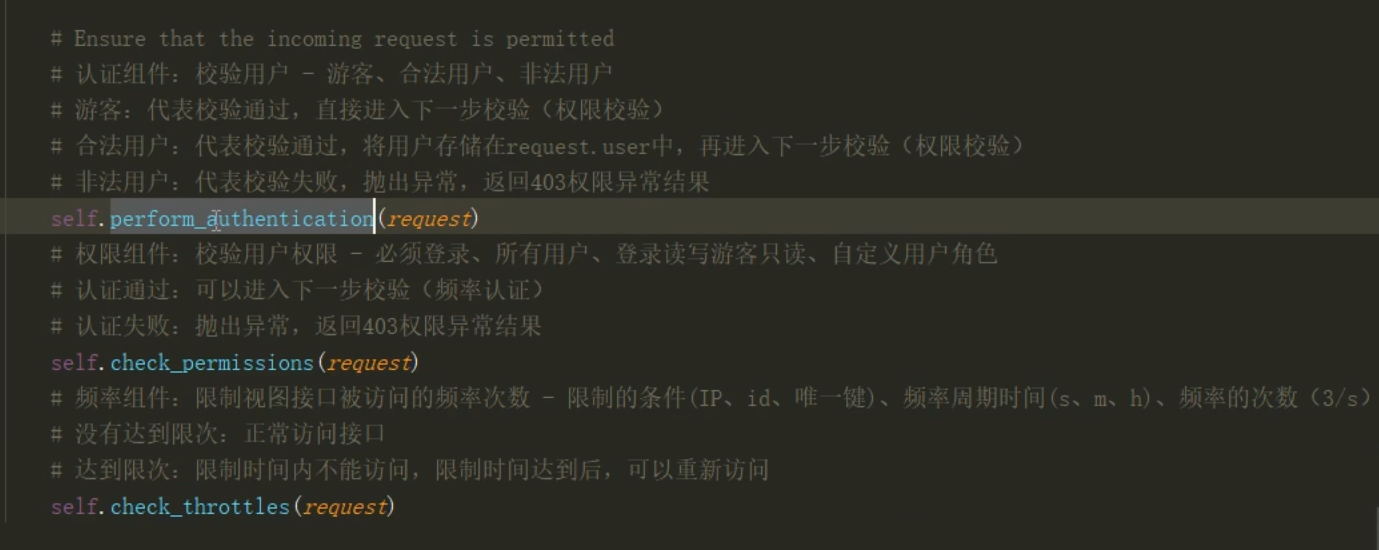 ...
转载
2021-08-22 15:58:00
72阅读
2评论
Java EE中常用的四个框架 Struts Struts是一个基于Sun Java EE平台的MVC框架,主要是采用Servlet和JSP技术来实现的。 Struts框架可分为以下四个主要部分,其中三个就和MVC模式紧密相关: 1、模型
搭建zabbix监控1.zabbix重要组件 zabbix主要由以下几个重要组件构成,具体作用如下。Zabbix Server:负责接收Agent发送报告信息的核心组件,所有的配置、数据统计.数据操 作都由它组织进行。Database storage:负责存储所有的配置信息以及收集的数据。Web interface:是zabbix的GU接口,通常情况下与Zabbix Server运行在同一台主机上



















