
本文推荐本周值得关注的已开源论文,包含图像超分辨率、利用疼痛类型之间的域迁移来识别马的疼痛表情的研究、人脸检测识别、图像去噪、分割、手写文本行分割、妆容迁移与卸妆、伪装物体检测等共计 12 篇。
其中值得关注的是由深圳神目科技所提出的基于 YOLOv5 目标检测器的人脸检测器 YOLO5Face,获得 WiderFace 上的 SOTA。
01
LAPAR: Linearly-Assembled Pixel-Adaptive Regression Network for Single Image Super-Resolution and Beyond
来自港中文&思谋科技
LAPAR 用于 SISR。在下图显示中可以看到,在所有现有的轻量级网络中,LAPAR 以最少的模型参数和 MultiAdds 取得了最先进的结果。不同以往方法的是,作者预先定义一组有意义的滤波器基数,并转向以像素方式优化装配系数。并通过大量的实验证明这种学习策略的优势,以及它在准确性和可扩展性方面的优势。基于同样的框架,LAPAR 也可以很容易地适用于其他图像修复任务,例如,图像去噪和 JPEG 图像解锁,并可以获得不错的性能结果。
- 论文链接:https://arxiv.org/abs/2105.10422
- 项目链接:https://github.com/dvlab-research/Simple-SR

标签:NeurIPS2020+图像超分辨率
02
Sharing Pain: Using Domain Transfer Between Pain Types for Recognition of Sparse Pain Expressions in Horses
来自瑞典皇家理工学院&Silo AI& 瑞典农业科学大学&加利福尼亚大学戴维斯分校&Univrses
本文是对利用疼痛类型之间的域迁移来识别马的疼痛表情的研究。
骨科疾病是对马进行安乐死的一个常见原因,这些病症往往会造成不同程度的细微但长期的疼痛。而用描述这种疼痛的视频数据来训练视觉疼痛识别方法是很有挑战性的,因为所产生的疼痛行为也是微妙的、稀疏的和变化的,即使是专家级的人类标注者也难以为数据提供准确的基础事实。
作者在本次工作中表示,从急性痛觉疼痛的马数据集中迁移特征(标签不那么模糊)可以帮助学习识别更复杂的骨科疼痛。此外,为该问题提出 human expert baseline,以及对各种域迁移方法和对骨科数据集中急性疼痛训练的疼痛识别方法所检测到的内容进行了研究。最后,围绕现实世界的动物行为数据集所带来的挑战以及如何为类似的细粒度动作识别任务建立最佳实践进行了讨论。
- 论文链接:https://arxiv.org/abs/2105.10313
- 项目链接:https://github.com/sofiabroome/painface-recognition

标签:马表情识别+行为识别
03
EMface: Detecting Hard Faces by Exploring Receptive Field Pyraminds
来自眼控科技
Scale variation(尺度变化)是人脸检测中最具挑战性的问题之一。现代人脸检测器采用特征金字塔来处理尺度变化问题。但它的局限性在于可能会破坏不同尺度的人脸的特征一致性。
本次工作提出的该方法简单而有效,receptive field pyramids(RFP),可以提高特征金字塔的表示能力。它可以根据检测到的人脸的不同尺度,自适应地在每个特征图中学习不同的 receptive fields( 感受野)。在两个人脸检测基准数据集(即WIDER FACE和UFDD)上的实证结果表明,所提出方法可以大大加快推理速度,同时又获得最先进的性能。
作者还表示对于未来的工作,将考虑把receptive field pyramids 应用到目标检测和语义分割任务中,期待可以有同等好的结果。
- 论文链接:https://arxiv.org/abs/2105.10104
- 项目链接:https://github.com/emdata-ailab/EMface

标签:人脸检测
04
FBI-Denoiser: Fast Blind Image Denoiser for Poisson-Gaussian Noise
来自成均馆大学&首尔大学
本次工作所提出的 FBI-Denoiser,通过设计 PGE-Net 和 FBI-Net 解决了 BP-AIDE 的计算复杂性问题,其中 PGE-Net比传统的 Gaussian noise estimation(×2000)快得多,FBI-Net 是一个高效的 blind spot(盲点)网络。并通过实验证明 FBI-Denoiser 在各种合成/真实噪声基准数据集上,仅基于“single” 噪声图像就达到了最先进的盲图像去噪性能,而且推理时间更快。
- 论文链接:https://arxiv.org/abs/2105.10967
- 项目链接:https://github.com/csm9493/FBI-Denoiser

标签:CVPR 2021+图像去噪
05
Attention-guided Temporal Coherent Video Object Matting
来自浙江大学&阿里巴巴&阿里达摩院&得克萨斯大学奥斯汀分校
本次研究,提出全新的基于深度学习的视频目标抠图方法,可以实现时间上的连贯抠图结果。关键部分是一个基于注意力的时间聚合模块,可以最大限度地发挥图像抠图网络对视频抠图网络的作用。该模块计算了特征空间中沿时间轴彼此相邻像素的时间相关性,以便对运动噪声具有鲁棒性。还设计一个新的损失项来训练注意力权重,极大地提高了视频抠图的性能。
另外还解释了如何通过用一组稀疏的用户标注的关键帧来微调最先进的视频物体分割网络来有效解决 trimap generation 问题。
实验结果表明,所提出方法可以为各种具有外观变化、遮挡和快速运动的视频生成高质量的 alpha mattes。
- 论文链接:https://arxiv.org/abs/2105.11427
- 项目链接:https://github.com/yunkezhang/TCVOM

标签:视频目标抠图
06
LineCounter: Learning Handwritten Text Line Segmentation by Counting
来自澳门大学&Amazon Alexa Natural Understanding
文章中为 HTLS(Handwritten Text Line Segmentation)提出一种新的行数计算方法,即从每个像素位置的顶部开始计算文本行数。该方法有助于学习一个端到端的 HTLS 解决方案,直接预测给定文档图像的每像素行数。此外,提出一个深度神经网络(DNN)模型:LineCounter,通过行数计算公式来执行 HTLS。
在三个公共数据集(ICDAR2013-HSC、HIT-MW和VML-AHTE)上进行的广泛实验表明,LineCounter 的性能优于最先进的 HTLS 方法。
- 论文链接:https://arxiv.org/abs/2105.11307
- 项目链接:https://github.com/Leedeng/LineCounter

标签:手写文本行分割
07
SiamMOT: Siamese Multi-Object Tracking
来自亚马逊
本次工作主要 focus 改善线上多目标跟踪(MOT)。具体来说,作者引入一个基于 region 的 Siamese Multi-Object Tracking 网络:SiamMOT,包括一个运动模型,该模型估计实例在两帧之间的运动。通过所提出的 Siamese 跟踪器的两个变体来探索运动建模是如何影响其跟踪能力的,其中一个是隐式运动模型,一个是显式运动模型。
作者在 MOT17、TAO-person 和 Caltech Roadside Pedestrians 这三个不同的 MOT 数据集上进行了广泛的定量实验。证明了运动建模对 MOT 的重要性以及 SiamMOT 可以大幅超越最先进水平的能力。SiamMOT 在 HiEve 数据集上的表现也超过了 ACM MM'20 HiEve 挑战的获胜者。此外,SiamMOT 很有效率,在单个现代 GPU 上以 17 FPS 的速度运行 720P 视频。
- 论文链接:https://arxiv.org/abs/2105.11595
- 项目链接:https://github.com/amazon-research/siam-mot
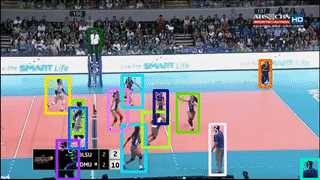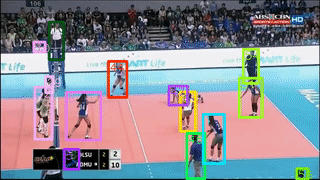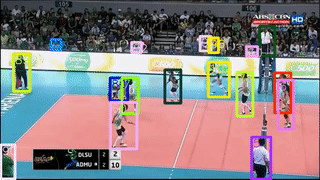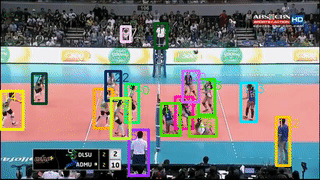
标签:CVPR2021+多目标跟踪
08
Disentangled Face Attribute Editing via Instance-Aware Latent Space Search
来自北京理工大学&微软亚洲研究
提出全新的人脸属性编辑框架:Instance-Aware Latent-Space(IALS),在 GAN 隐空间中搜索 instance-aware 的语义方向,明确地促进属性变化的解耦。进一步提出 "Disentanglement-Transformation"(DT)指标来量化属性转换和分离的效果,并在此基础上找到attribute-level(属性层面)和 instance-specific(特定实例)方向之间的最佳控制因素。实验结果表明在 GAN 生成的图像和真实图像上都取得了高质量的结果,大大超过了现有的方法。
- 论文链接:https://arxiv.org/abs/2105.12660
- 项目链接:https://github.com/yxuhan/IALS

标签:IJCAI 2021+人脸属性编辑
09
Context-aware Cross-level Fusion Network for Camouflaged Object Detection
来自内蒙古大学&IIAI&南京理工大学&INSA
在伪装物体检测任务中,所存在的挑战在于物体与周围环境的边界对比度很低,另外,物体的大小和形状,也加剧了的 COD 准确度的难度。
在本次工作中,作者提出 Context-aware Cross-level Fusion 网络(C2F-Net)来解决上述挑战。设计一个 Attention-induced Cross-level Fusion (ACFM)模块,将多级特征与有益的注意力系数进行整合。然后,融合后的特征被送入所设计的 Dual-branch Global Context(DGCM)模块,该模块产生多尺度特征表示,以利用丰富的全局上下文信息。在 C2F-Net 中,这两个模块采用级联的方式对高级特征进行处理。
在三个广泛使用的基准数据集上进行的广泛实验表明,C2F-Net 是一个有效的 COD 模型,并且明显地超过了最先进的模型。
- 论文链接:https://arxiv.org/abs/2105.12555
- 项目链接:https://github.com/thograce/C2FNet

标签:IJCAI 2021+伪装物体检测
10
PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal
来自北航&中科院&新加坡国立大学
PSGAN++,可以进行保留细节的妆容迁移和有效的卸妆。对于妆容迁移,它使用 Makeup Distill 网络来提取妆容信息,这些信息被嵌入到空间感知的 makeup matrices。设计一个 Attentive Makeup Morphing 模块,指定源图像中的妆容是如何从参考图像中变形的,以及一个妆容细节损失来监督选定的妆容细节区域内的模型。
另一方面,对于卸妆,PSGAN++ 应用 Identity Distill 网络,将带妆图像的身份信息嵌入 identity matrices(身份矩阵)中。最后,获得的 makeup/identity matrices(妆容/身份矩阵)被送入风格迁移网络,该网络能够编辑特征图以实现化妆迁移或去除。
又收集一个包含不同姿势和表情图像的 Makeup Transfer In the Wild(自然妆容迁移)数据集和一个包含高清晰度图像的 Makeup Transfer High-Resolution(妆容迁移高分辨率)数据集,用来对 PSGAN++ 的有效性进行评估。
实验证明,PSGAN++ 不仅在姿势/表情差异较大的情况下实现了最先进的完美妆容细节结果,而且还能进行部分或可控程度的妆容迁移。
- 论文链接:https://arxiv.org/abs/2105.12324
- 项目链接:https://github.com/wtjiang98/PSGAN

标签:GAN+妆容迁移与卸妆+TPAMI 2021
11
YOLO5Face: Why Reinventing a Face Detector
来自深圳神目科技&LinkSprite Technologies(美国)
提出基于 YOLOv5 目标检测器的人脸检测器 YOLO5Face,实现了八个模型。最大的模型 YOLOv5l6 和超小的模型 YOLOv5n在 WiderFace 验证的Easy、Medium 和 Hard 子集上都达到了接近或超过 SOTA 的性能。YOLO5Face 不仅实现了最佳性能,而且运行速度也很快。
- 论文链接:https://arxiv.org/abs/2105.12931
- 项目链接:https://github.com/deepcam-cn/yolov5-face



标签:人脸检测+YOLO5Face
12
ViPTT-Net: Video pretraining of spatio-temporal model for tuberculosis type classification from chest CT scans
来自康考迪亚大学&North South University
ViPTT-Net,在 1300 多个带有人类活动标签的视频片段上进行训练,然后在带有结核病类型标签的胸部 CT 扫描上进行微调。发现,在视频上预训练模型表现更好,并大大改善了模型的验证性能,kappa score 从 0.17 到 0.35,特别是对于代表性不足的类别样本。其中最好的方法在 ImageCLEF 2021 结核病-TBT分类任务中获得了第二名,在只有图像信息(不使用临床元数据)的最终测试集上的 kappa score 为 0.20。
- 论文链接:https://arxiv.org/abs/2105.12810
- 项目链接:https://github.com/hasibzunair/viptt-net

本文仅做学术分享,如有侵权,请联系删文。
—THE END—



















