
一:三副本的弊端
虽然分布式存储的SDS理念很好,横向扩展能力不错,自动添加和删除节点都是优势,但与传统集中式存储(磁盘阵列)相比,其稳定性和性能仍然存在明显的短板。以Ceph、VSAN为代表的软件定义存储(Software Defined Storage,SDS)是一个横向扩展、自动均衡、自愈合的分布式存储系统,将商用x86服务器、固态硬盘、机械硬盘等硬件资源整合为一个瘦供给的资源池,并以块存储、文件存储、对象存储、Restful API等多种接口方式提供存储服务。
无论是Ceph、VSAN,或者其演化版本,有一个共同的技术特征,即采用网络RAID方式实现数据保护,以3副本或纠删码为代表,其中3副本用于对小块数据读写性能有一定要求的应用场景,而纠删码则适用于视频数据、备份及归档等大文件场景。以3副本为例,业务数据被分割为固定大小的数据块,通常为4MB,每个数据块在不同的节点上保存3个副本(如图1所示),其分布机制是依照一致性哈希算法(Consistent Hashing)或CRUSH算法,将各个副本数据随机分布在不同节点、不同磁盘中,以实现数据自动平衡和横向扩展。当磁盘或节点遭遇故障或损坏时,系统会自动根据预先设定的规则,重新建立一个新的数据副本,称之为数据重建。
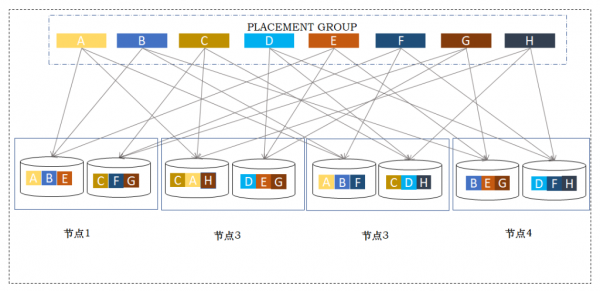
图 1 分布式存储副本机制
虽然分布式存储的SDS理念很好,横向扩展能力不错,自动添加和删除节点都是优势,但与传统集中式存储(磁盘阵列)相比,其稳定性和性能仍然存在明显的短板。
首先,在性能方面,三副本分布式存储容易受到IO分布不均匀和木桶效应的影响,导致大延迟和响应迟钝的现象。以Ceph为例,多个存储基本单元,Placement Group (PG),封装为一个OSD,每个OSD直接对应于某一个机械硬盘HDD;主流的7200转HDD,受到机械臂寻址限制,其单盘的读写性能仅为120 IOPS左右;由于数据在OSD上随机分布,因而单个硬盘上的IO负载不会固定在平均值上,而是总体呈现为正态分布,少数HDD上因正态分布的尾部效应,导致其IO负载远超平均值,以及远超单盘的性能阀值,造成拥堵。此外,分布式存储为保证数据完整性,必须定时进行数据完整性校验,即数据scrub/deep-scrub操作,而这些操作产生额外的IO负载,可能会加重磁盘阻塞现象。根据木桶效应原理,系统的性能取决于集群中表现最差的磁盘,因此个别慢盘严重拖累整个系统的性能,其可能的后果,就是带来大延迟、OSD假死,以及触发数据非必需的重建。
其次,三副本分布式存储还面临稳定性问题。当存储扩容、硬盘或节点损坏、网络故障、OSD假死、 Deep-scrub等多种因素叠加,可能导致多个OSD同时重建,引发重建风暴。在数据重建过程中,重建任务不仅消耗系统的内存、CPU、网络资源,而且还给存储系统带来额外的IO工作负载,挤占用户工作负载的存储资源。在此情形下,用户时常观察到,系统IO延迟大,响应迟钝,轻者引起业务中断,严重时系统可能会陷入不稳定的状态,OSD反复死机重启,甚至会导致数据丢失,系统崩溃。
此外,三副本分布式存储还面临数据丢失的风险。三副本最大可抵御两个HDD同时损坏。当系统处于扩容状态、或一个节点处于维护模式时,此时出现一个HDD故障,则该系统就会进入紧急状态,出现两个HDD同时故障,则可能导致数据丢失。对于一个具有一定规模的存储系统而言,同时出现两个机械硬盘故障的事件不可避免,尤其是当系统运行两三年之后,随着硬件的老化,出现Double、或Triple磁盘故障的概率急剧上升。此外,当系统出现大规模掉电或存储节点意外宕机时,也可能会导致多个机械硬盘同时出现损坏,危及三副本分布式存储的数据安全。
二:双重RAID机制
为了解决三副本分布式存储面临的性能问题、稳定性及可靠性等缺陷,道熵的铁力士分布式存储采用双重RAID保护机制,在前文中我们探讨了分布式存储的基本原理,分析了三副本分布式存储的潜在隐患:
- 性能问题:三副本分布式存储受到IO分布不均匀和木桶效应的影响,导致大延迟和响应迟钝的现象;
- 稳定性问题:频繁的数据重建会导致用户业务受到影响、甚至业务中断;
- 数据丢失风险:尤其是,当硬件老化,或出现大规模掉电或节点意外宕机时,可能会导致多个机械硬盘同时出现损坏,危及三副本分布式存储的数据安全。
为了解决三副本分布式存储面临的性能问题、稳定性及可靠性等缺陷,道熵的铁力士分布式存储采用双重RAID保护机制,除了继承网络RAID(节点间副本、跨节点纠删码)和一致性哈希随机分布数据的特点,铁力士将磁盘阵列特有的节点内RAID技术和存储虚拟化(池化)管理技术, 即Storage Virtualization Manager (SVM),与分布式技术相结合,如图2所示。
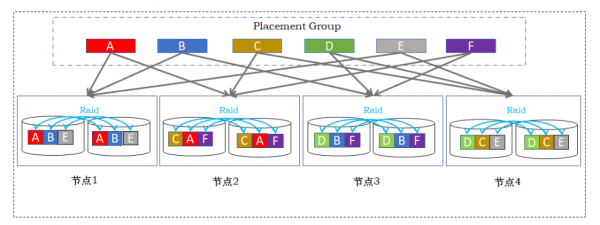
图 2 OneStack分布式存储双重Raid机制
网络Raid技术
在铁力士分布式存储中,每个数据块按照一致性哈希算法,随机选择两个不同存储节点来保存数据的两个副本,保证当任何一个节点宕机时,仍有一个数据副本保证读写操作,确保业务高可用和数据安全。
节点内Raid技术
在铁力士分布式存储的每个节点内,通过SVM存储虚拟化技术实现节点内的RAID数据保护,RAID级别选择可以是镜像,也可以是存储效率更高的RAID5或6。节点内RAID保护可抵御单个或多个硬盘损坏,故障修复限制在节点内部,无需触发网络数据重建,有效地避免了网络重建风暴。
节点内RAID结合网络Raid(跨节点的副本/EC码)技术,铁力士实现了双重RAID数据保护。在三副本架构中,一旦同时出现三块磁盘故障或受损,数据就可能丢失;而在双重RAID架构中,即使每个节点同时出现一块磁盘故障,数据仍然无忧,业务仍然持续。考虑到分布式存储可能包含数十个甚至上百个存储节点,双重RAID的数据可靠性明显超过三副本架构。
存储虚拟化技术
铁力士在每个存储节点运行在存储虚拟化管理软件(SVM)上,把该节点的存储资源整合为一个统一管理的存储池,为分布式系统提供vOSD资源。SVM采用宽条带机制(见图3),将每个vOSD的工作负载均匀分布在节点的每个磁盘上,大幅提高了单个vOSD的IOPS能力,可有效抵御三副本分布式存储中的IO分布不均匀现象。
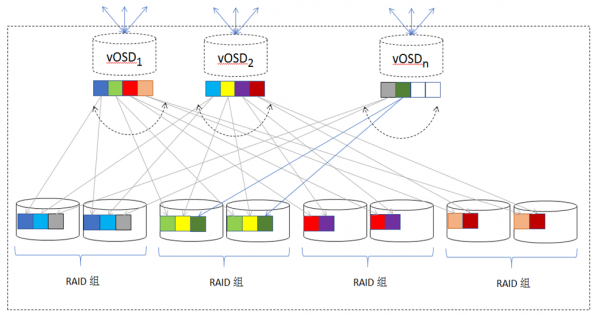
图 3 节点内Raid条带机制
SVM存储池由节点内多个RAID小组构成,通过虚拟卷为上层分布式系统提供vOSD存储服务。每个vOSD对应于三副本中由物理HDD承载的OSD。由分布式一致性哈希算法分配来的数据块,将写入SVM存储池中、由虚拟卷支撑的vOSD,而非直接写入物理硬盘。SVM 利用宽条带技术,将vOSD的工作负载均匀分布在各个物理磁盘上:每个大小为4MB的vOSD 对象数据块,被分割为32KB的数据块,依次被安排在RAID组的逻辑地址空间中;SVM 对各个RAID小组的逻辑地址空间采取顺序写优化策略:首次写按各个小组的逻辑地址分配地址空间,按顺序写入数据;后续重写,则优先填满空闲地址空间,尽可能实现硬盘顺序寻址,最大限度降低机械硬盘较慢的寻址操作次数,利用机械硬盘顺序写较快的特点来提升IO性能。
二级DRAM+Flash 缓存加速
磁盘阵列中常见的性能加速手段是共享缓存加速,中高端磁盘阵列与低端磁盘阵列的在性能方面的一个重大区别,除了控制器个数,就是缓存加速的能力。典型的中高端磁盘阵列能支持的共享缓存加速在512GB到1TB上下。铁力士借鉴了磁盘阵列的设计,通过SVM虚拟化实现DRAM与Flash相结合的二级缓存加速:通过自适应算法,自动识别动态或静态热数据(高频率读写或最近读写数据),将最热的数据保存在延迟最小的DRAM中,而将次热的数据保存在更大容量、基于Flash的固态硬盘上;并由于分布式技术的加持,形成一个容量巨大的分布式二级缓存系统。与中高端磁盘阵列相比较,铁力士分布式存储系统支持数10TB、甚至100TB以上的分布式缓存,相当于其10倍、甚至100倍的缓存容量。
数据完整性校验与数据自修复
SVM存储虚拟化管理借鉴了WAFL(NetApp) 、Btrfs(SuSE)、ZFS(Oracle)、Storage Spaces(微软)等文件系统的先进经验,对底层存储的每个数据块增加一个256比特的校验码,并单独保存在一对固态硬盘镜像中,用于快速实现在线数据完整性校验。一旦校验码检查到数据受损,通过节点内RAID功能实现数据自修复。该功能可快速定位硬件故障,并实现硬件故障自动隔离。
三:双重RAID机制与三副本对比
双重RAID究竟能否有效解决三副本的缺陷?让我们从二者之间的对比开始。在前面我们分析了三副本的潜在隐患,也介绍了双重RAID架构的工作原理与技术特点。双重RAID究竟能否有效解决三副本的缺陷?让我们从二者之间的对比开始。
故障修复时间更短,业务影响更小
硬盘损坏时,双重RAID机制优先通过节点内RAID恢复数据,该恢复机制可自动调节速度以避让工作负载,前端业务无感知。无需触发网络数据重建,从而有效地避免了网络重建风暴。
节点故障时,可通过迁移磁盘到另一台物理服务器,实现节点迁移(无需拷贝或重建数据)。SVM存储池上每个磁盘记载关于存储池构成的全部信息,分布式存储的vOSD的ID号及用户数据,保存在SVM存储池的虚拟卷上,自动随着SVM存储池的迁移从一台物理服务器迁移到另一台物理服务器,主机名及vOSD的ID号保存不变,实现快速节点修复。
容错性更强,可允许多节点同时有磁盘损坏
三副本分布式存储通过跨节点的副本保护,可有效防止单个或两个磁盘损坏对业务数据的影响,但是容错性受到限制,如在三副本的情况下,不同故障域内之间,最多只能允许2个节点有磁盘损坏,超出2个节点出现磁盘故障,则极有可能发生数据丢失,如图1所示。

图 1 三副本分布式存储多节点硬盘损坏导致数据丢失
铁力士分布式存储通过双重RAID 机制,能够将容错性提升一个数量级。如图2所示,以节点内RAID 10+节点间2副本为例,当每个节点都出现磁盘故障的时候,可以通过节点内RAID 分别修复,保障整个系统数据无丢失,业务无中断。
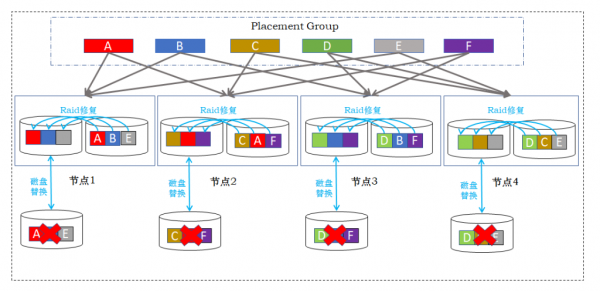
图 2 双重RAID容忍多节点磁盘损坏
数据持久性(Durability)高出一个数量级
下面通过具体数值来比较三副本与双重RAID的数据持久性(可靠性)。数据持久性指标可通过存储系统的AFR(Annual Failure Rate)来衡量。考虑一个1000个6TB硬盘的存储集群,每个机械硬盘的MTTF(Mean Time to Failure)为1000,000小时。在计算中需要运用两个著名的MTTF公式,一个是关于RAID6,其MTTF=(MTTF)*(MTTF)*(MTTF)/(N*(N-1)*(N-2)*MTTR), 另一个是关于RAID5,其MTTF=(MTTF)*(MTTF)/(N*(N-1)MTTR), 其中MTTR(Mean Time to Repair)是硬盘平均修复时间。
在三副本条件下,存储系统共有333组三副本,每组三副本的MTTF相当于N=3的RAID6,在分布式并发修复的条件下,MTTR通常为3小时(每半小时修复1TB数据),因此每组三副本的MTTF =1000000*1000000*1000000/(3*2*1*3)=5.56x 1016 小时,而整个系统的MTTF = 5.56x 1016 /333 =1.67x 1014 小时。折算为AFR(一年共8760小时),AFR=8760/(1.67x 1014) =5.2x 10-11。
在双重RAID情况下,考虑节点内采用(2+1) RAID5,存储系统共有333组RAID5,为简化计算,考虑每组RAID对应于两个vOSD,12TB数据。据测算,RAID5的MTTR为30小时,每组RAID5 (vOSD)的MTTF=1000000*1000000/(3*2*30)=5.56x 109 小时。当一个RAID5组损坏时,由于vOSD在跨节点之间有镜像保护(其可靠性相当于N=2 RAID5),采用分布式并发修复12TB数据,每半小时修复1TB数据,需6小时,因此,其MTTR=(5.56x 109 )* (5.56x 109 )/(2*1*6)=2.58x 1018 小时。考虑到整个存储系统有333组RAID5, 因此整个系统的MTTF=2.58x 1018/333 =7,75x 1015 小时,相当于三副本MTTF的46倍。折算为AFR,双重RAID的AFR=8760/(7.75x 1015)= 1.1x 10-12 。
对比三副本和双重RAID的数据持久性,可见双重RAID的数据可靠性高于三副本一个数量级以上。
总结
铁力士分布式存储将传统磁盘阵列的RAID技术、存储虚拟化管理技术与分布式存储技术相结合,有效地解决了普通分布式存储面临的IO分布不均匀和木桶效应导致的性能缺陷,大幅度提升系统IOPS性能,并避免了普通分布式存储因网络重建风暴而可能导致的稳定性隐患。同时,双重RAID架构的数据可靠性高于三副本分布式存储一个数量级以上。
转载:https://stor.51cto.com/art/202103/649016.htm


















