
COW(Copy-On-Write) 和 MRO(Merge-On-Read)是 Hudi 中两种不同类型的表,它们的主要区别在于读写操作的性能以及内存占用。
1. COW(Copy-On-Write)
COW 表是在写入操作时进行复制的表,每次写入操作都会创建一个新的 COW 表,并将原表覆盖。COW 表的主要优点是可以减少内存占用和提高写入性能。由于每次写入操作都会创建一个新的COW 表,因此COW表适用于频繁进行写入操作的场景,例如批量更新、数据批量插入等。COW表的缺点是需要额外的内存管理能力,需要进行内存管理和回收。
1.1 COW 表的原理
COW 表是一种数据复制技术,其主要思想是在内存中创建一个新的副本,并将原对象和副本进行关联。当用户对副本进行修改时,原对象会被更新以反映副本的修改。当用户释放对象时,内存中的对象会被销毁,而内存空间可以被重新使用。
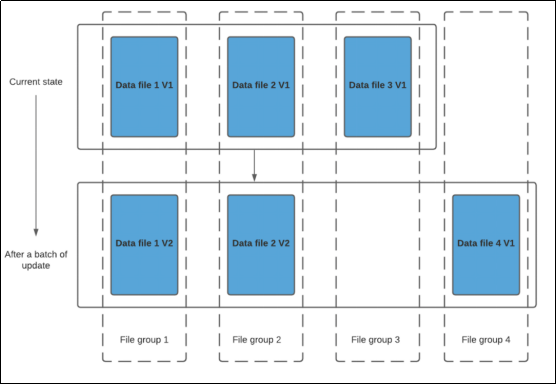
在 Hudi 中,COW 表是在写入操作时创建一个新的 COW 表,并将原表覆盖。新的 COW 表会保存在内存中,而原表会被释放。当用户读取数据时,Hudi 会查找原表是否还在内存中,如果在,则直接读取原表;如果不在,则需要读取新的 COW 表,并将其与原表进行关联。在COW表中,只有数据文件/基本文件(.parquet),没有增量日志文件(.log.*)。对每一个新批次写入都将创建相应数据文件的新版本(新的FileSlice),新版本文件包括旧版本文件的记录以及来自传入批次的记录(全量最新)。
1.2 COW 表的优缺点
COW 表具有以下优点:
- 减少内存占用:每次写操作都会创建一个新的
COW表,而不是直接修改原来的表,因此可以减少内存占用,提高系统的性能。 - 提高可扩展性:
COW表可以动态创建和销毁,可以根据实际需要动态调整表的大小,从而提高系统的可扩展性。 - 适合频繁写操作:
COW表适用于对表进行频繁的写操作,因为每次写操作都会创建一个新的COW表,可以避免内存溢出和竞争问题,从而提高系统的性能和可扩展性。
COW 表也具有以下缺点:
- 降低读取性能:
COW表是在写入操作时创建的,因此在读取数据时,需要先查找新的COW表,然后再与原表进行关联,会降低读取性能。 - 需要内存管理:
COW表需要在内存中管理原表和COW表之间的关系,因此需要额外的内存管理能力,需要进行内存管理和回收。
1.3 在 Hudi 中的应用
Hudi 表是一种基于内存的数据存储系统,用于快速读取和写入大量数据。COW表在Hudi表中得到了广泛的应用,尤其是在需要频繁进行写操作的场景中。
例如,在需要对大量数据进行批量更新的场景下,可以使用 Hudi中的 COW表来减少内存占用和提高效率。在批量更新时,Hudi会创建一个新的 COW表,并将原表覆盖。新的 COW 表可以用来存储更新后的数据,而原表可以被释放,从而减少内存占用和提高性能。
此外,COW表还可以用于 Hudi 中的索引结构。由于索引通常是读取频率较高的数据,因此使用COW表可以减少索引的内存占用,提高索引的性能和可扩展性。在 Hudi中,可以使用 COW 表来创建动态索引,以适应不断变化的数据需求。
总的来说,COW表是 Hudi 中一种非常有用的数据复制技术,可以用于减少内存占用、提高性能和可扩展性等方面。在实际应用中,可以根据具体场景选择合适的 COW表类型,以实现更好的性能和可扩展性。
2. COW(Copy-On-Write)
MRO 表是在读取操作时进行合并的表,每次读取操作都会将新的数据合并到已有的表中,而不是直接替换已有的数据。MRO表的主要优点是可以提高读取性能和可扩展性。由于每次读取操作都会将新的数据合并到已有的表中,因此 MRO表适用于频繁进行读取操作的场景,例如数据查询、数据批量读取等。MRO表的缺点是需要额外的内存管理能力,需要进行内存管理和回收。
2.1 原理
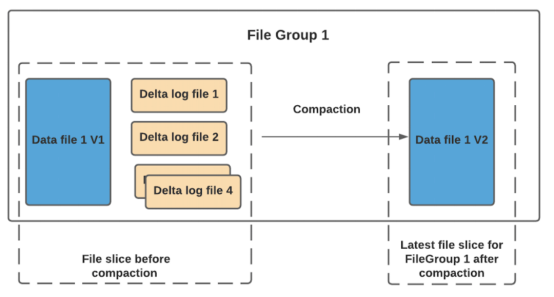
MRO(Merge-On-Read)是一种数据合并技术,它在读取数据时进行数据合并。具体来说,当读取某个表时,Hudi 会先读取多个版本的数据,然后对这些版本进行合并,得出最新的数据。在数据合并的过程中,Hudi 会根据数据版本的时间戳、数据模型和操作方式等因素,采取不同的合并策略。例如,对于一些数据冲突,Hudi可以使用And/Or 策略进行解决,对于一些数据缺失,Hudi 可以使用求和策略进行填充。MOR表中,包含列存的基本文件(.parquet)和行存的增量日志文件(基于行的avro格式,.log.*)。顾名思义,MOR表的合并成本在读取端。因此在写入期间我们不会合并或创建较新的数据文件版本。标记/索引完成后,对于具有要更新记录的现有数据文件,Hudi创建增量日志文件并适当命名它们,以便它们都属于一个文件组。
2.2 优缺点
MRO具有以下优点:
-
提高数据处理的效率和鲁棒性。
MRO可以在读取数据时进行数据合并,从而减少数据的读取次数,提高数据处理的效率。此外,MRO还可以避免数据丢失和冲突无法解决等问题。 -
适用于大规模数据处理场景。
MRO适用于大规模数据处理场景,因为它可以减少数据的读取次数和存储量,从而提高数据处理的效率和鲁棒性。 -
提高数据的可靠性和完整性。
MRO可以在读取数据时进行数据合并,从而避免数据丢失和冲突无法解决等问题,从而提高数据的可靠性和完整性。
MRO 也具有以下缺点:
-
实现复杂度较高。
MRO需要在读取数据时进行数据合并,因此需要考虑到多个因素,如数据模型、操作方式、时间戳、内部版本等,从而实现复杂的数据合并算法,从而导致实现复杂度较高。 -
冲突处理策略不同导致性能差异大。
MRO中不同的冲突处理策略会导致性能差异很大,因此需要根据具体的场景和数据特点选择合适的冲突处理策略。
2.3 应用
MRO可以应用于多种场景,例如:
-
大规模数据处理。
MRO可以用于大规模数据处理场景,例如数据仓库、商业智能等场景,从而提高数据处理的效率和鲁棒性。 -
数据备份和恢复。
MRO可以用于数据备份和恢复场景,例如数据库灾备等
在 Hudi 中,可以根据具体应用场景选择合适的表类型。对于频繁进行写入操作的场景,可以选择COW表;对于频繁进行读取操作的场景,可以选择MRO表。同时,Hudi还提供了动态表结构功能,可以根据实际需要动态调整表的大小和类型,以实现更好的性能和可扩展性。


















