
环境:
- OS:Ubuntu 18.04.5 LTS
- Kubernetes:v1.20.7
- CoreDNS:1.6.7
背景:
在以二进制方式部署的Kubernetes集群中部署CoreDNS组件的时候,对应的pod一直处于CrashLoopBackOff状态,其错误日志如下:
# kubectl logs -f coredns-6cc56c94bd-nlnzm -n kube-system
.:53
[INFO] plugin/reload: Running configuration MD5 = a4809ab99f6713c362194263016e6fac
CoreDNS-1.6.7
linux/amd64, go1.13.6, da7f65b
[FATAL] plugin/loop: Loop (127.0.0.1:48691 -> :53) detected for zone ".", see https://coredns.io/plugins/loop#troubleshooting. Query: "HINFO 1853319330074714968.7855677413137606265."
问题分析:
从日志中来看,已经提示我们去查看https://coredns.io/plugins/loop#troubleshooting,在该文档中,可以找到这个问题的原因,如下图所示:
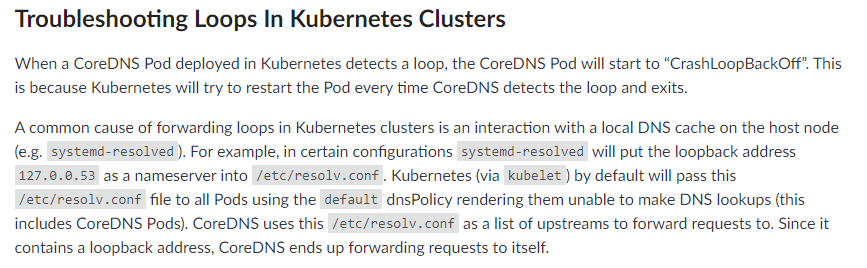
翻译成中文,大致意思如下:
当Kubernetes中部署的CoreDNS Pod检测到循环时,CoreDNS Pod将开始“ CrashLoopBackOff”。 这是因为,每当CoreDNS检测到循环并退出时,Kubernetes都会尝试重新启动Pod。
Kubernetes集群中转发循环的常见原因是与主机节点上的本地DNS缓存进行交互(例如systemd-resolved)。 例如,在某些配置中,systemd-resolved会将回送地址127.0.0.53作为名称服务器放入/etc/resolv.conf中。 默认情况下,Kubernetes(通过kubelet)将使用默认的dnsPolicy将此/etc/resolv.conf文件传递给所有Pod,从而使它们无法进行DNS查找(包括CoreDNS Pods)。 CoreDNS将此/etc/resolv.conf用作将请求转发到的上游列表。 由于它包含回送地址,因此CoreDNS最终将请求转发给自己。
问题解决:
解决该问题的方法,亲测有效的有两种,分别为:
(推荐)方法一:将/run/systemd/resolve/resolv.conf添加到kubelet的yml文件中,格式如下:
resolvConf: <path-to-your-real-resolv-conf-file>
操作步骤:
1、添加内容到kubelet的yml文件中
vim .../kubelet-config.yml
resolvConf: "/run/systemd/resolve/resolv.conf"
2、重启kubelet服务
systemctl restart kubelet
3、重新部署CoreDNS组件
先删除
kubectl delete -f coredns.yaml
再创建
kubectl apply -f coredns.yaml
方法二:编辑名为coredns的configmap,删除Corefile中的loop
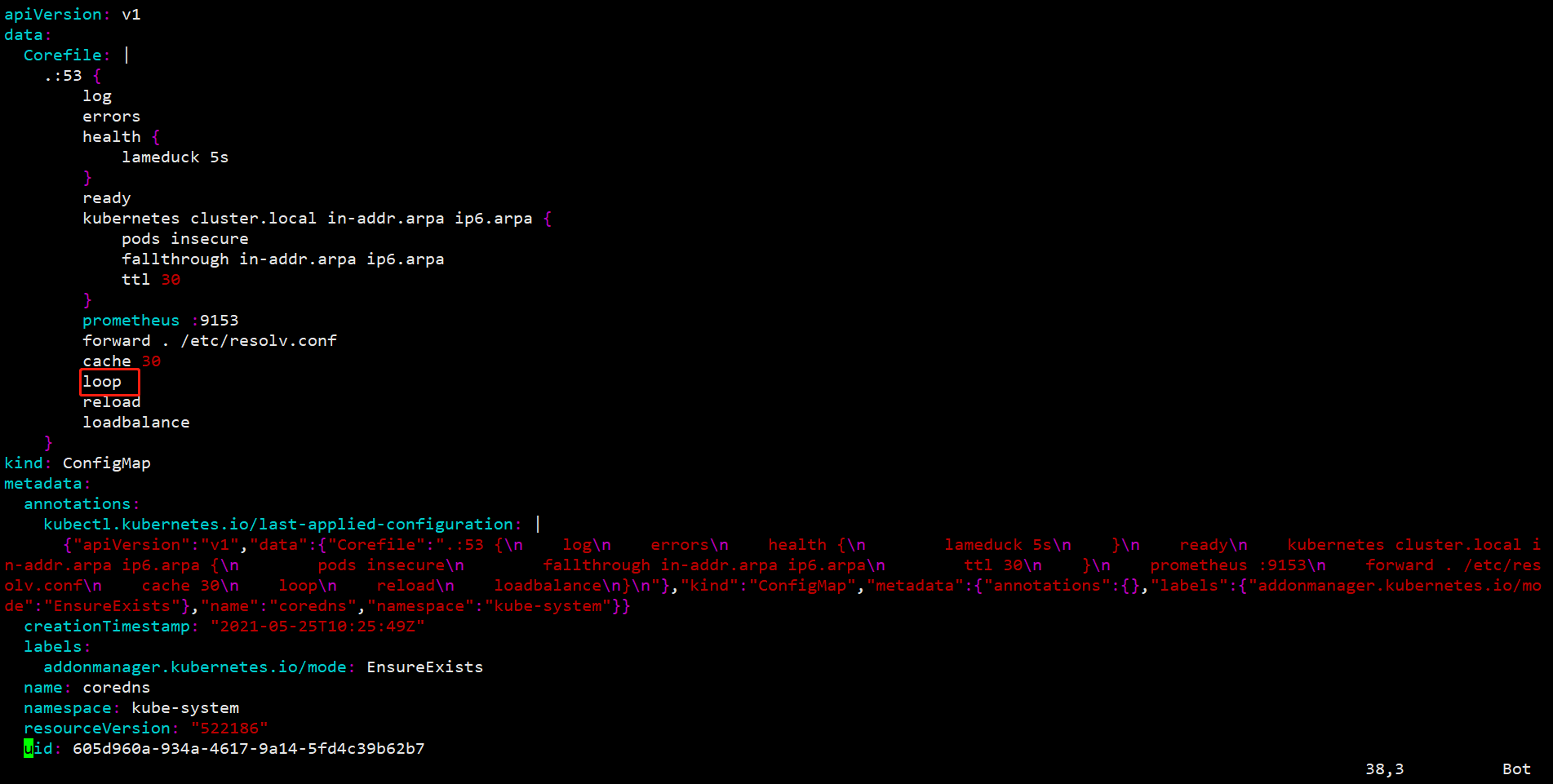
执行以下命令:
kubectl -n kube-system edit configmap coredns
然后删除显示loop的行,并且保存配置。当部署coredns组件的对应pod在下次重启时,将会应用名为coredns的configmap的内容,它将会运行为running状态,并且准备就绪。
参考资料:
https://coredns.io/plugins/loop/#troubleshooting
https://github.com/coredns/coredns/issues/2087



















