
有时候我们的系统主要是对输入的数据进行处理和转换,这些处理和转换是互相独立的,在这种情况下,输入的数据经过转换之后被放到指定的输出中去。
在日常的工作中,我们会经常遇到这种数据处理的任务,那么对于这样的任务我们就可以采用数据流架构。
数据流架构在实际工作中的流有很多种,最常见的就是I/O流,I / O缓冲区,管道等。不同的组件或者模块通过这些流进行连接。数据的流向可以是带有循环的拓扑图,没有循环的线性结构或者树形结构等。
数据流架构的主要目的是实现重用和方便的修改。 它适用于在顺序定义的输入和输出上进行一系列定义明确的独立数据转换或计算,例如编译器和业务数据处理应用程序。 一般来说有三种基本的数据流结构。
顺序批处理
顺序批处理是最常见也是最基础的数据流架构。数据作为一个整体,会经过一个一个的处理单元,在上一个处理单元处理结束之后,才会进入到下一个处理单元。
我们看下顺序批处理的流程图:

数据被作为一个整体,从一个处理器传到另外一个处理器。主要通过临时文件进行交互。每个处理器的输出被作为下一个处理器的输入,经过一次次的数据处理,最终得到要得的结果。
顺序批处理的优点是每个处理都是独立的,他们进行组合得到一个整体的顺序处理架构。
当然缺点就是不能并行,只能串行执行,吞吐量也不够。各个处理器之间只通过中间文件进行交互,交互程度不高。
管道和过滤器
顺序批处理中各个处理器的功能差异比较大,通常来说他们是不同的系统。如果在同一个系统中处理数据流任务,那么就需要用到管道和过滤器。
java 8引入了stream和管道的概念。一个集合可以转换成stream,通过对stream的操作,可以对整个数据流进行变换,最终得到想要的结果。
这种方法强调连续组件对数据的增量转换。 在这种方法中,数据流由数据驱动,整个系统可以分解为数据源、过滤器、管道和数据接收器等组件。
模块之间的连接是数据流,它是先进/先出的缓冲区,可以是字节流、字符流或任何其他类型的此类流。 这种架构的主要优点在于它的并发和增量执行。
这种模式下,最重要的组件就是过滤器,过滤器是独立的数据流转换器。 它转换输入数据流的数据,对其进行处理,并将转换后的数据流写入管道以供下一个过滤器处理。 它以增量模式工作,一旦数据通过连接的管道到达,它就会开始工作。
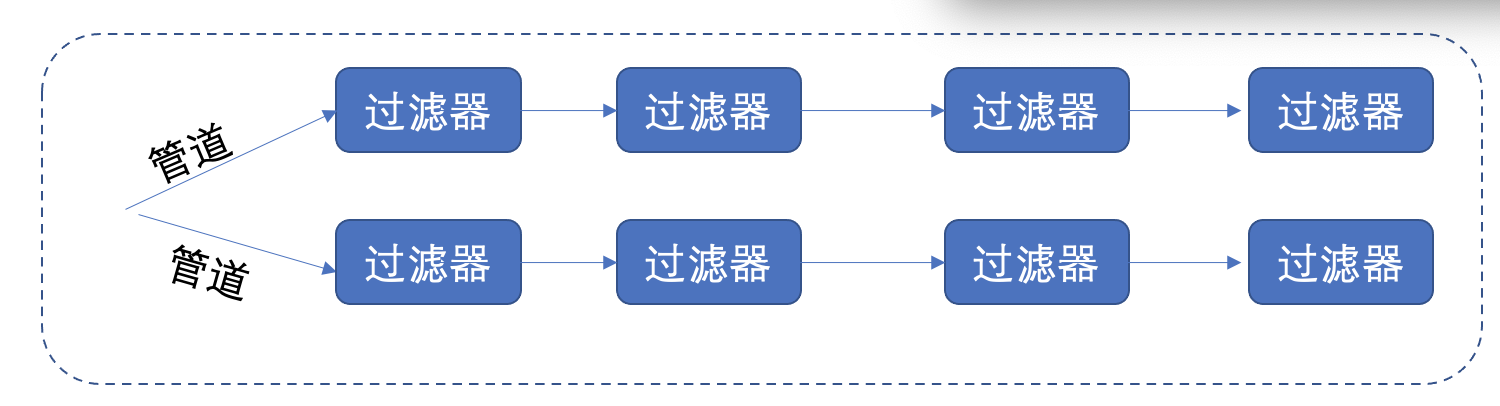
上图中的数据从管道出发,经过一个个的过滤器,最终得到处理过后的结果。
过滤器有两种类型,分别是主动型过滤器和被动型过滤器。主动型过滤器可以主动从管道中拉取数据,并将处理过后的数据推出。这种模式主要用于UNIX 管道。而被动型过滤器则是负责接收管道推入的数据。
这种模式的优点是可以提供高并发和高吞吐量。缺点就是不适合动态交互。
流程控制
还有一种模式,既不是批量处理也不是管道模式,他是根据输入内容的不同,来控制不同的执行流程。类似于我们程序中使用的判断语句。
总结上面我们介绍了几种数据流的架构方式,希望大家能够喜欢。
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/07-data-flow-architecture/
本文来源:flydean的博客
欢迎关注我的公众号:「程序那些事」最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!




















