
集群(cluster)是什么?就是单台服务器无法满足现况(容量,高可用,处理能力)了,就使用多台协同处理问题的方法,而外部看来,它们仅仅是一个系统。
一.集群的常见类型
为了完成某种特定需求,常见集群类型分为以下三类:
LB:Load Balancing 负载均衡集群。
LB是利用一个集群中的多台服务器完成许多小的工作。简单说来,一个应用使用的人多了,那么资源的需求也就更大,单台的服务器性能会受到影响,而负载均衡集群作用就是将用户的请求,选择分配给当时负载最小,且能够提供最好服务的服务器来处理用户请求。并且还需要检查每台提供服务的服务器的状态,避免将用户请求分配给产生故障的服务器。LB主要应用于访问请求很大的web和在线网游场景。
HA:High Availability 高可用集群
HA是利用集群中系统冗余,时刻以特定的方式对正在工作的服务器进行检测,当系统中某台机器发生损坏的时候,其他后备的机器可以立刻接替它的工作,最大限度的保证服务的可用性。HA则主要关键型业务场景,例如银行,电信等。
HP:High Performance 高性能集群
HP是利用一个集群中多台及其共同完成同一件任务,使得完成任务的速度和可靠性都远远高于单机运行效果,弥补了单机性能的不足。HP主要用于大数据的计算场景,例如天气预报、环境监控、搜索引擎数据检索,复杂的大型运算需求。其实,如果把服务需求看成运算需求,那么LB在某种意义上来说,和HP似乎的是一样的。
必须要说的是,生产环境中,这些集群几乎都不会独立存在,一个完善的工作场景必须是混合的。试想一下:google、facebook、taobao和金融类网站,面对海量的访问,首先必须由负载均衡平衡大访问,而其访问的关键数据又必须保证其有效性,以及其服务不能随意中断,尤其是金融类网站,这就必须有高可用集群支持其不间断工作;而面对客户海量的请求处理和自身海量的数据,以及自身对于数据的分析,没有高性能的集群,怎么可能玩的转呢?
二 浅谈负载均衡集群
迄今为止,负载均衡集群相关技术已经相当成熟了,不管是硬件还是软件。先简单说一下硬件,除了价格,其他都很不错,如果企业不差钱,直接上硬件吧,以F5、Citix、IBM等众多商家都有相关产品其并发处理一般都在500W以上,当然,性能越好,价格越高。再啰嗦一句,20W起的价格,考虑避免单点故障,一次最少来俩、要求的高的话,100W+/台也是有的...
软件负载均衡之LVS
LVS是一个开源的软件,可以实现LINUX平台下的简单负载均衡。LVS是Linux Virtual Server的缩写,意思是Linux虚拟服务器。
LVS采用三层结构:负载调度器,服务器池,共享存储。
负载调度器(Director)工作在TCP/IP协议的四层,转发协议以来于内核模块完成,转发规则由管理员定义,所以,LVS是两段式的架构设计,在内核空间中工作的是ipvs,而在用户空间中工作的,用来让管理员定义集群服务规则的是ipvsadm。这跟iptabels的工作原理几乎一样了,只是跟运行路线不一样,如下图

先简单介绍一下LVS中各种IP的说明:如图:
VIP:Director(负载调度器)用来向客户端提供服务的IP。
RIP:集群节点(提供服务的服务器)的IP。
DIP:Director用来和RIP 通信的IP。
CIP:外网IP,客户端的请求IP。
LVS的三种转发模型:
LVS-NAT:网络地址转换 Network address translation
其实上图画出的就是一个LVS-NAT模型,此模型就是iptabels的DNAT穿了个马甲,再多话点妆而已,但是缺点太明显:Director既要处理请求报文,又要处理响应报文,所以Director会hold不住的。因此,生产环境中,很少用到此模型,笔者也不推荐您使用这个。数据包地址转换过程如下:
S:CIP D:VIP-->Director-->S:CIP D:RIP-->Real Server-->S:RIP D:CIP--> Director-->S:VIP D:CIP
此模型的特点如下:
1.RS必须和集群节点在同一子网
2.RIP通常使用私有地址,仅用于本地通信
3.Director工作在Clients和RS中间,负责处理进出的全部报文
4.RS网关都要指向DIP
5.可以实现端口映射
6.RS可以是任何操作系统
7.Director在比较大的规模应用中会成为性能瓶颈
LVS-DR:直接路由 Direct routing
此模型中Director仅处理客户端请求报文,而响应报文由客户端自己搞定。数据包地址转换过程如下:S:CIP-->D:VIP-->Director-->S:CIP D:RIP-->Real Server-->S:VIP D:CIP
图例如下:

此模型有如下特点:
1.RS必须和集群节点在同一物理网络上.
2.RIP可以使用公网地址
3.Director仅处理请求报文
4.RS的网关不能指向DIP
5.不能使用端口映射(RS直接响应)
6.大多数OS都可以用于RS
7.DR模型的Director能够处理比NAT模型多的多的请求.
8.每个RS必须要隐藏自己的VIP
需要注意的是:基于此种模型的集群所在物理网络,最好有两个公网IP,并将其DIP和40%RIP指向网关出口,剩余60%RIP指向另外一个网关出口;如果此集群系统所在的物理网络只有一公网IP,那么这个管理网关路由性能将会是整个系统的性能瓶颈。
LVS-TUN:IP隧道 IP tunneling
与DR的网络结构一样,但Director和Real Server可以在不同的网络当中,DIP----->RS的VIP 基于隧道来传输,在数据包外层额外封装了S:DIP D :RIP 的地址.图例如下:
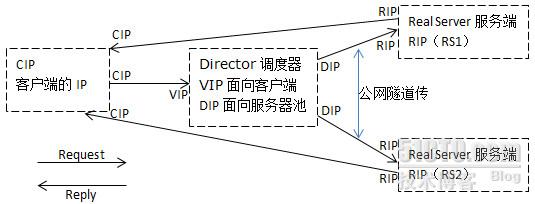
此模型特点如下:
1.RS和Director不必在同一物理网络中;
2.RIP一定不能使用私有地址;
3.大多数Director仅处理入站请求
4.响应报文不能经过Director(技术可以使用经过,但无逻辑需要)
5.不能使用端口映射;
6.仅允许支持隧道协议的OS用于RS
LVS的调度方法
调度方法,就是Director(调度器)在接收到用户请求后,要根据神马算法把请求发给服务器池的哪个服务器。其中调度方法又分为静态方法和动态方法。
静态调度方法 fixed scheduling
不关心当前连接的活动和非活动状态,不检查RS的连接状态,相应算法如下:
RR: (Round-Robin Scheduling)轮叫调度
把请求依次分配给服务器池中的服务器,这种算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。说起这个算法,其实最早的DNS的资源记录给1个域名,多个IP的负载均衡就是这种算法,一直沿用至今,如下图:
WRR加权轮叫调度(Weighted Round-Robin Scheduling)
管理员可以根据后端服务器的处理性能,分配不同的权重比例,例如RS1依次能处理100个请求,为其分配权重为10;而RS2一次可以处理200,那么可以为其配置权重为20即可。
注:权重用整数来表示,有时候也可以将其设置为atomic_t;其有效表示值范围为24bit整数空间,即(2^24-1);
DH(Destination Hashing Scheduling)
目标地址唯一性.简单来说:此算法会产生一个hash算法的表来记录客户的这次请求所用CIP和建立连接RIP,根据首次为其分配的的RIP,在hash表的缓存时间内,使其每次的新请求,都定向访问到这个RIP。
SH(Source Hashing Scheduling)
保证响应地址和进来的地址,从同一个防火墙通过.算法和DH一致,只是根据请求的源IP地址进行判定。需要注意的是,此算法的前提是,当前局域网必须有2个或2个以上的网关出口,否则无意义。
动态调度方法 dynamic scheduling
由于静态调度算法不考虑RS的当前状态,因此对于动态网站而言,动态调度算法才是最合适的,因为其能够给予后台服务器当前的活动连接数进行请求分配,避免了一台服务器负载太多,而其它则闲置。
两种标准:
非活动状态的连接(此连接未断,但也啥事不干)
活动状态的连接(连着呢,使用服务中)
例如:ssh,telnet均是基于状态的连接,需要实时进行检查连接的状态,而http则是无状态的连接
相应的算法如下:
LC: Least Connections 最少连接调度
把新请求分给当前连接最少的服务器。判断值为Overhead,它的值等于活动连接乘以256+非活动连接(Overhead = active*256+inactive)
WLC: Weight LC 加权重的最少连接
考虑到服务器池的每台服务器性能不统一,也就意味着,活动连接数大并不意味着其能力弱,因此加上权重,判断值为:Overhead = (active*256+inactive)/weight
SED: Shortest Expected Delay 最短的期望的延迟
不计算非活动连接;如果两个性能不同,但是计算权重后的值一样的服务器,则选择性能较强的服务器来处理新请求,其计算方法为:Overhead = (active+1)*256/weight
NQ: Never Queue永不排队
不计算非活动连接;不论权重,只要没有活动连接,就依次先分配给此RS一个请求,此RS性能不一定是最快的。如果所有服务器都忙,则按SED的调度方法计算。
LBLC: Loaclity-Based Least Connection
基于本地最少链接,如果客户请求之前连接过并产生缓存且缓存未失效,则直接将请求发给之前连接过的RS,否则,则以LC算法调度。
LBLCR:Locality-Based Least Connections with Replication :
带复制的基于本地最少链接;假设两台RS,由于缓存的缘故,一个非常忙,一个要非常闲,为了负载均衡,将忙的RS的缓存发送给不忙的RS,然后使用LC调度算法重新负载均衡即可;此算法要求RS之间要配置缓存共享。
SED和NQ不计算非活动连接.所以大多情况下WLC和LC最常用.
WLC和LBLC用的比较多,WLC用于正常的服务场景,LBLC带缓存的请求.
LVS的共享存储(Shared storage)
共享存储实际上也是物理磁盘等存储介质,命名只是其应用环境的特殊性。
准确来说,共享存储适用于各种环境,且共享存储在LVS集群系统是可选项;它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务。
共享存储通常是数据库、网络文件系统或者分布式文件系统。服务器结点需要动态更新的数据一般存储在数据库系统中,还需保证并发访问时数据的一致性。静态的数据可以存储在网络文件系统(如NFS/CIFS)中,但网络文件系统的伸缩能力有限,一般来说,NFS/CIFS服务器只能支持3~6个繁忙的服务器结点。对于规模较大的集群系统,可以考虑用分布式文件系统,如AFS[1]、GFS[2.3]、Coda[4]和Intermezzo[5]等。分布式文件系统的分布式锁管理器(Distributed Lock Manager)是保证数据一致性的有效手段。
共享存储的简单分类:
DAS: Direct Attached Storage
直接连接到主机的存储设备,一般需要PCI总线的支持,速度比较快。直连式存储的数据量越大,备份和恢复的时间就越长,对服务器硬件的依赖性和影响就越大。此类设备一般接口为IDE,SCSI,USB,SATA。
NAS: Network Attached Storage 网络附加存储
NAS 是一种通过网络介质实现数据存储的机制。优点是:适用于共享存储,有文件锁,易于部署,跨平台等。实现方式一般为NFS、SAMBA,win共享等。缺点也很明显,其一般提供都是共享能力,在文件级实现,因此传输和响应速度必然有所欠缺。
SAN: Storage Area Network 存储网络
SAN一般是局域网磁盘阵列,具有磁盘阵列的所有特征:大容量、高效能、可靠。易于安装,维护,良好的扩展,响应快速。SAN的缺点:由于其工作更底层,因此没有文件管理系统,也就意味着,两个请求同时对一个文件操作,会导致文件系统崩溃,这是无法接受的,因此这需要软件级别的高可用集群实现分布式文件锁。
SAN则由服务器、HBA卡、集线器/交换机和存储装置所组成。SAN可以分为FC SAN和IP SAN,其中FC SAN除了价格高,似乎也没啥大缺点,一个企业如果考虑使用FC SAN,就不得不购买HBA、光纤交换机、光纤磁盘阵列、管理软件……这并不是中小企业能够承受得起的.
咱们说说IP SAN,IP SAN的成本更合理,基于iSCSI搭建的IP SAN,千兆以太网交换机代替了昂贵的FS SAN专用的光纤交换机,客户端的Initiator或iSCSI代替了价格较高的主机HBA卡(光纤存储卡),具有iSCSI接口的高性价比的存储设备代替了光纤磁盘阵列。而且IP SAN的扩展性也非常出色,并且随着网络的飞速发展,IP SAN的性能会得到大部的提升。
本文出自 “自强不息” 博客,请务必保留此出处http://mos1989.blog.51cto.com/4226977/1067734




















