
下图来自:https://baijiahao.baidu.com/s?id=1683481435616221574&wfr=spider&for=pc
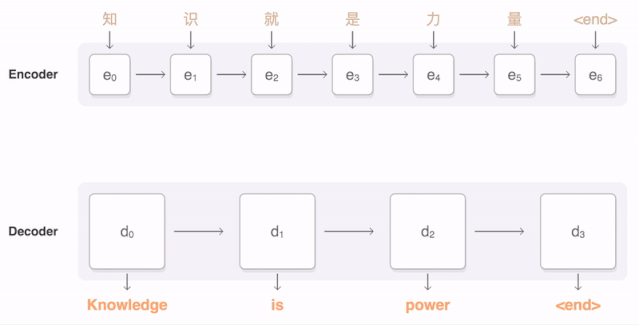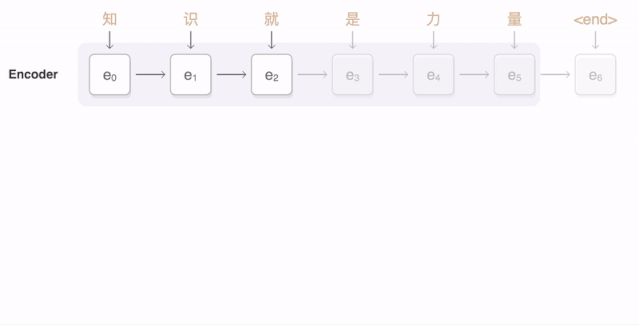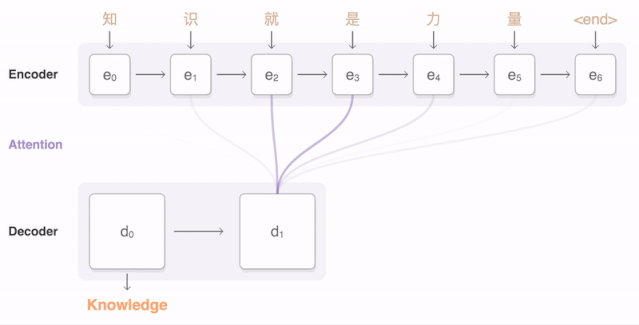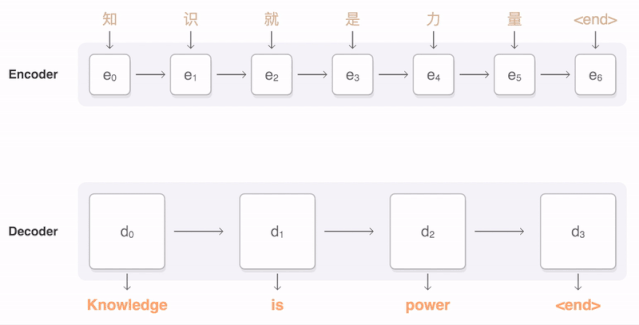

该任务是实现图文转换。

这里编码器是VGG,解码器是LSTM。LTSM输入是不同时刻的图片的关注点信息,然后生成当前时刻的单词。

注意力机制
注意力机制是一种在编码器-解码器结构中使用到的机制, 现在已经在多种任务中使用:
- 机器翻译(Neural Machine Translation, NMT)
- 图像描述(Image Captioning (translating an image to a sentence))
- 文本摘要(Summarization(translating to a more compact language))
而且也不再局限于编码器-解码器结构, 多种变体的注意力结构, 应用在各种任务中.
总的来说, 注意力机制应用在:
- 允许解码器在序列中的多个向量中, 关注它所需要的信息, 是传统的注意力机制的用法. 由于使用了编码器多步输出, 而不是使用对应步的单一定长向量, 因此保留了更多的信息.
- 作用于编码器, 解决表征问题(例如Encoding Vector再作为其他模型的输入), 一般使用自注意力(self-attention)
1. 编码器-解码器注意力机制
1.1 编码器-解码器结构

如上图, 编码器将输入嵌入为一个向量, 解码器根据这个向量得到输出. 由于这种结构一般的应用场景(机器翻译等), 其输入输出都是序列, 因此也被称为序列到序列的模型Seq2Seq.
对于编码器-解码器结构的训练, 由于这种结构处处可微, 因此模型的参数可以通过训练数据和最大似然估计得到最优解, 最大化对数似然函数以获得最优模型的参数, <br />
全局注意力
global attention 在计算context vector Ct 的时候会考虑encoder所产生的全部hidden state。

层级注意力
对于一个NLP问题, 在整个架构中, 使用了两个自注意力机制: 词层面和句子层面. 符

self attention
这里的self attention 指的是用到自身的信息来计算attention。传统的attention都是考虑用外部信息来计算attention。


采用multi-head attention为的就是让不同head学习到不同的子空间语义。显然实验也证实这种形式的结果较好。

在self attention中其实在做的当前文本句中单词依赖关系分数的计算。比如“Think Machines”两个单词

优点:
- 由于self attention 是对整个文本句求attention的,所以他能抓取到当前单词和该文本句中所有单词的依赖关系强度。这方面的能力显然比RNN的获取长依赖的能力强大的多。
- 此时不在用RNN的这种串行模式,即每一步计算依赖于上一步的计算结果。因此可以像CNN一样并行处理,而CNN只能捕获局部信息,通过层叠获取全局联系增强视野
缺点:很显然,既是并行又能全局,但他不能捕捉语序顺序。这是很糟糕的,有点像词袋模型。因为相同单词不同词序的含义会有很大差别。为了克服这个问题,作者引入了Position embedding。
Transform是一大法宝,影响深远。

从上图粗看,Transform仍延续着一个Encoder一个Decoder的形式。重要部件:
- Positional embedding:正如上面所说,self attention缺乏位置信息,这是不合理的。为了引入位置信息,这里用了一个部件position embedding。
这里考虑每个token的position embedding的向量维度也是d维的,与input embedding的输出一样,然后将input embedding和position embedding 加起来组成最终的embedding输入到上面的encoder/decoder中去。这里的position embedding计算公式如下:

其中pos表示位置的index,i表示dimension index。Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有

这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
- residual connection无论是encoder还是decoder我们都能看到存在这residual connection这种跳跃连接。
随着深度的增加会导致梯度出现弥散或者爆炸,更为严重的是会导致模型退化 (也就是在训练集上性能饱和甚至下降,与过拟合不同)。深度残差网络就是为了解决退化的问题。其实引入残差连接,也是为了尽可能保留原始输入x的信息。
- Layer Normalization
与 BN 不同,LN 是一种横向的规范化

LN针对单个训练样本进行,不依赖于其他数据。避免了受mini batch中其他数据的影响。BN适用于不同mini batch数据分布差异不大的情况,而且BN需要开辟变量存每个节点的均值和方差,空间消耗略大;而且 BN适用于有mini_batch的场景。
- Masked Multi-Head Attention
这里用mask来遮蔽当前位置后面的单词。实现也很简单,采用一个上三角都为1,下三角为0的矩阵。
《An Attentive Survey of Attention Models》今年提出香农科技提出的一篇关于attention的综述论文。

本文给attention作出了分类,分为四种分类方法:
- number of sequences:a) distinctive: 只考虑了涉及单个输入和相应输出序列的情况(例如seq2seq中的attention)
b) co-attention: 同时对多个输入序列进行操作,并共同学习它们的注意权重,以捕获这些输入之间的交互(例如前面介绍的ABCNN)
c) inner attention: 使用注意力来学习输入序列中对应于相同输入序列中的每个标记的相关标记.(例如self attention)
- Number of abstraction levels
按照输入特征的抽象层次来分,这里的抽象层次可以是词粒度、短语粒度、句子粒度、文档粒度。
a) single-level:只为原始输入序列计算注意权重
b) multi-level: 注意力可以按顺序应用于输入序列的多个抽象层次[例如在两个不同的抽象层次(即单词级别和句子级别)上使用了注意力模型来完成文档分类任务]
- Number of positions a) soft attention:它使用输入序列所有隐藏状态的加权平均值来构建上下文向量
b) hard attention: 其中上下文向量是从输入序列中随机采样的隐藏状态计算出来的
c) global attention:与soft attention一样
d) local attention: 是hard attention和soft attention的一种折中
- Number of representations
a) multi-Representational Attention model: 通过多个特征表示捕捉输入的不同方面,注意可以用来为这些不同的表示分配重要权重,这些表示可以确定最相关的方面,而忽略输入中的噪声和冗余。
b) multi-dimensional: 这种attention 作用在维度上。attention的权重表示各个维度上的重要性。

https://zhuanlan.zhihu.com/p/75750440?ivk_sa=1024320u

BERT
BERT,全称 Bidirectional Encoder Representations from Transformers
BERT特点:
- 使用
Transformer Block代替 RNN,通过堆叠Transformer Block将模型变深; - 使用随机 Mark 的方式训练;
- 使用双向编码的形式;






REF
https://www.zhihu.com/question/68482809/answer/264632289
https://www.jianshu.com/p/e27c15bfd970
https://www.jianshu.com/p/3968af85d3cb
https://zhuanlan.zhihu.com/p/362366192?utm_medium=social&utm_oi=710944035610562560


















