
Heartbeat V2.x双机热备安装
1 简述
本文档主要介绍linux-HA项目的新版本v2的安装和配置及相关算法,为以后架构linux-HA增加系统的可用性,以及对service_name项目的监控提供参考性意见和建议。
|
编号
|
术语
|
解释
|
|
1.
|
linux-HA
|
是一个开发用于linux操作系统的构建高可用性群集的软件的项目,软件主要是指Heartbeat软件,它同样可用于FreeBSD和 等操作系统。, Solaris,OpenBSD
|
|
2.
|
Heartbeat
|
它既可以指linux-HA项目的整个软件,也可以指负责通讯和基础架构的核心软件包。本文中前者我们用Heartbeat表示,后者用heartbeat表示。
|
|
3.
|
集群节点关系监控模块,用来维护和传递集群节点信息,包括新增节点,排除节点。
|
|
|
4.
|
是Linux-HA的“大脑”模块,它维护着配置信息,负责资源的分配,改变资源和节点的状态,它和Linux-HA的每一个模块都有交互。
本文主要是使用资源接管功能。
|
|
|
5.
|
本地资源管理器,它基本上是对resource agent的抽象,CRM主要是通过LRM对资源和节点进行对应操作,比如启动,停止和监控等。
|
|
|
6.
|
集群基本信息管理器,它包括静态地配置信息和资源定义信息,以及动态的节点和资源状态信息等。
|
|
|
7.
|
转化图,它作为PE的输出和TE的输入,描述了从CurrentClusterState转变到TargetClusterState的必要操作和依赖关系,以期望集群中的各资源都运行正常。
|
|
|
8.
|
PE/pengine/CRM policy engine
|
协议引擎,用于从当前的状态信息计算得到transition graph,它会考虑到resource的当前位置和状态,节点的正常与否以及当前的静态配置信息。
|
|
9.
|
TE/tengine/CRM Transition Engine
|
转化引擎,它利用PE生成的transition graph通过远程节点上的LRM发起具体的操作(start,stop),以期望达到TargetClusterState。
|
|
10.
|
资源,它是高可用性的基本单位,是集群资源管理器用于高可用性配置的服务或者相应的工具。注意:集群资源只能被集群启动和停止,而不能由操作系统的参与。
|
|
|
11.
|
资源代理,它对某种类型的集群资源进行了包裹,就像具体的硬件驱动程序一样。
|
|
|
12.
|
|
|
硬件环境:1台Dell PC机,配置:1块网卡,100G硬盘,2G内存,相当于intel P4 300G 的双核CPU。
软件环境:操作系统 Enterprise Linux Release 5(2.6.18-92.el5xen)。系统默认安装即可,运行两个虚拟机配置HA双机热备。
3 Service_name服务名称修改
由于heartbeat监控的资源进程与服务名称一致,需要将我们的service_name做一次进程与服务名称的统一且要添加service_name status参数。
1、 添加service_name status参数
命令如下:
cp /etc/rc.d/init.d/service_named /etc/rc.d/init.d/apcstart
vi /etc/rc.d/init.d/apcstart
在. /home/service_name/.bash_profile下面添加:
RETVAL=0
prog="apcstart"
在status)下面添加:
status $prog
RETVAL=$?
保存,即可
2、 修改启动服务名称
vi /etc/rc.local
将service_named修改为apcstart,保存退出。
4 Heartbeat安装及配置
Heartbeat V1的安装和配置比较简单,主要缺点是只能允许两个节点做高可用性配置,并且功能比较单一。具体的安装和配置可以参见IBM heartbeat 与 Apache Web 服务器。
Heartbeat V2的安装基本上和V1差不多,同样可以采用rpm包安装或者源代码包安装等不同的安装方式。建议采用源代码安装包安装的时候指定prefix,这样在安装的时候Heartbeat将安装在指定的目录。具体的安装步骤可以参见heartbeat installation guide。
2.x和1.x最主要的区别在于:
1) 2.x支持CRM管理,资源文件由原来的haresources变为cib.xml,
2) 支持OCF格式的resource agent,
3) 可以对多资源组进行独立监控
4)支持多节点(最多支持16节点)
Heartbeat V2的配置文件主要包括三个配置文件:ha.cf,authkey和cib.xml。和V1的区别主要在于cib.xml。在V1版本中替代cib.xml的是haresources。幸运的是从版本1到版本2的这个配置文件的过渡可以通过haresources2cib.py转换来实现,它将haresources资源文件转换成cib.xml。2.x里编译好后自带有转换脚本。
在启用Heartbeat之前,需要配置三个文件。这三个文件都在目录/usr/share/doc/heartbeat-2.1.3/下
第一个是ha.cf,该文件位于在安装后创建的/etc/ha.d目录中。该文件中包括为Heartbeat使用何种介质通路和如何配置他们的信息。在源代码目录中的ha.cf文件包含了您可以使用的全部选项,下面列出了部分选项,详细描述见linux-HA的ha.cf页:
bcast eth0
表示在eth0接口上使用广播heartbeat
keepalive 2
设定heartbeat之间的时间间隔为2秒。
warntime 10
在日志中发出“late heartbeat“警告之前等待的时间,单位为秒。
deadtime 30
在30秒后宣布节点死亡。
initdead 120
在某些配置下,重启后网络需要一些时间才能正常工作。这个单独的”deadtime”选项可以处理这种情况。它的取值至少应该为通常deadtime的两倍。
udpport 694
使用端口694进行bcast和ucast通信。这是默认的,并且在IANA官方注册的端口号。udpport必须在bcast和ucast之前指定,否则udpport指定的端口无效,bcast和ucast将采用默认的694端口
auto_failback on
当auto_failback设置为on时,一旦主节点重新恢复联机,将从从节点取回所有资源。若该选项设置为off,主节点便不能重新获得资源。在V2中如果crm开启了,那么它是无效的,被cib.xml中的default_resource_stickiness取代了。
node node1
node node2
集群中机器的主机名,与“uname –n”的输出相同。
respawn <userid> <cmd>
可选的:列出将要执行和监控的命令。例如:要执行ccm守护进程,则要添加如下的内容:
respawn hacluster /usr/lib/heartbeat/ccm
使得Heartbeat以userid(在本例中为hacluster)的身份来执行该进程并监视该进程的执行情况,如果其死亡便重启之。对于ipfail,则应该是:
respawn hacluster /usr/lib/heartbeat/ipfail
注意:如果结束进程的退出代码为100,则不会重启该进程。
需要配置的第二个文件authkeys决定了您的认证密钥。共有三种认证方式:crc,md5,和sha1。您可能会问:“我应该用哪个方法呢?”简而言之:
如果您的Heartbeat运行于安全网络之上,如本例中的交叉线,可以使用crc,从资源的角度来看,这是代价最低的方法。如果网络并不安全,但您也希望降低CPU使用,则使用md5。最后,如果您想得到最好的认证,而不考虑CPU使用情况,则使用sha1,它在三者之中最难破解。
文件格式如下:
auth <number>
<number> <authmethod> [<authkey>]
因此,对于sha1,示例的/etc/ha.d/authkeys可能是
auth 1
1 sha1 key-for-sha1-any-text-you-want
对于md5,只要将上面内容中的sha1换成md5就可以了。 对于crc,可作如下配置:
auth 2
2 crc
不论您在关键字auth后面指定的是什么索引值,在后面必须要作为键值再次出现。如果您指定“auth 4”,则在后面一定要有一行的内容为“4 <signaturetype>”。
确保该文件的访问权限是安全的,如600。其实也并不是“any text you want” 都可以,可以使用的字母个数是有限制的。
1、 V2.x版本配置cib.xml首先需要配置haresources,然后通过haresources2cib.py转换cib.xml。
将所要监控的服务名称(例如apcstart)加入到haresources。
转换名利如下:
/usr/lib/heartbeat/haresources2cib.py --stout -c /etc/ha.d/ha.cf /usr/share/doc/heartbeat-2.1.3/haresources
2、Cluster Information Base (CIB)主要存储了两类集群的相关信息。一类主要是静态的配置信息以及该集群中resource, cluster nodes和constraints的定义。另一类信息是集群的当前状态信息。从这里我们可以看到:cib.xml是一个动态的在运行过程中会改变的文件。也就是说当heartbeat启用的时候,无法手工修改cib.xml,即使修改保存了也无效。这里有个小技巧利用cibadmin工具在Heartbeat运行时修改某些配置信息。
下面是一个空CIB文件。
<cib>
<configuration>
<crm_config/>
<nodes/>
<resources/>
<constraints/>
</configuration>
<status/>
</cib>
它展示了CIB文件可能包含的一些主要元素。其中crm_config可能包含一些集群的配置信息,下面有一个示例:
<crm_config>
<cluster_property_set id="cib-bootstrap-options">
<attributes>
<nvpair id="cib-bootstrap-options-symmetric-cluster" name="symmetric-cluster" value="true"/>
<nvpair id="cib-bootstrap-options-no-quorum-policy" name="no-quorum-policy" value="stop"/>
<nvpair id="cib-bootstrap-options-default-resource-stickiness" name="default-resource-stickiness" value="0"/>
<nvpair id="cib-bootstrap-options-default-resource-failure-stickiness" name="default-resource-failure-stickiness" value="0"/>
<nvpair id="cib-bootstrap-options-stonith-enabled" name="stonith-enabled" value="false"/>
<nvpair id="cib-bootstrap-options-stonith-action" name="stonith-action" value="reboot"/>
<nvpair id="cib-bootstrap-options-startup-fencing" name="startup-fencing" value="true"/>
<nvpair id="cib-bootstrap-options-stop-orphan-resources" name="stop-orphan-resources" value="true"/>
<nvpair id="cib-bootstrap-options-stop-orphan-actions" name="stop-orphan-actions" value="true"/>
<nvpair id="cib-bootstrap-options-remove-after-stop" name="remove-after-stop" value="false"/>
<nvpair id="cib-bootstrap-options-short-resource-names" name="short-resource-names" value="true"/>
<nvpair id="cib-bootstrap-options-transition-idle-timeout" name="transition-idle-timeout" value="5min"/>
<nvpair id="cib-bootstrap-options-default-action-timeout" name="default-action-timeout" value="20s"/>
<nvpair id="cib-bootstrap-options-is-managed-default" name="is-managed-default" value="true"/>
<nvpair id="cib-bootstrap-options-cluster-delay" name="cluster-delay" value="60s"/>
<nvpair id="cib-bootstrap-options-pe-error-series-max" name="pe-error-series-max" value="-1"/>
<nvpair id="cib-bootstrap-options-pe-warn-series-max" name="pe-warn-series-max" value="-1"/>
<nvpair id="cib-bootstrap-options-pe-input-series-max" name="pe-input-series-max" value="-1"/>
<nvpair id="cib-bootstrap-options-dc-version" name="dc-version" value="2.1.3-node: 552305612591183b1628baa5bc6e903e0f1e26a3"/>
</attributes>
</cluster_property_set>
</crm_config>
而node项一般不用用户来填充,Heartbeat将自己进行填充,填充以后的示例如下:
<nodes>
<node id="07c1c19a-51d4-47d6-9437-784651c28907" uname="node2" type="normal"/>
<node id="c766d38b-709e-4439-97b8-49533d904014" uname="node1" type="normal"/> </nodes>
resources项定义集群的各个资源和资源组,下面是一个简单的示例,Heartbeat将每2分钟检测资源运行情况(interval="120s"),如果发现资源不在,则尝试启动资源;如果60s后还未启动成功(timeout="60s"),则资源切换向另节点。这里的时间都可以由用户修改。
<resources>
<group id="group_1">
<primitive class="lsb" id="apcstart_2" provider="heartbeat" type="apcstart">
<operations>
<op id="apcstart_2_mon" interval="120s" name="monitor" timeout="60s"/>
</operations>
</primitive>
</group>
</resources>
另外一个例子是对VIP的监控,每5S监控一次,若vip失效,则尝试重启vip,timeout时间为5s,若5s后启动不成功,则切换向另节点。
<primitive class="ocf" id="IPaddr_192_168_86_237" provider="heartbeat" type="IPaddr">
<operations>
<op id="IPaddr_192_168_86_237_mon" interval="5s" name="monitor" timeout="5s"/>
</operations>
<instance_attributes id="IPaddr_192_168_86_237_inst_attr">
<attributes>
<nvpair id="IPaddr_192_168_86_237_attr_0" name="ip" value="192.168.86.237"/>
</attributes>
</instance_attributes>
</primitive>
由于Heartbeat V2和V1不同,它可以运行在多个节点上,所以它引入了constraints项来定义各节点和各个资源之间的关系。有三种不同种类的constraints,它们分别为:Locational,Co-Locational和Ordering约束条件。Co-Locational用于指定两个资源是否必须或者不能运行在同一个节点上;Locational规则使用rules and expressions来指明资源可以运行在哪个节点上以及优先度;而Ordering规则指定资源启动的先后顺序。详细的信息和示例可以查看ClusterInformationBase/SimpleExamples。
所有的constraints都有一个score分值,它用来调整某个资源在某个符合条件的节点上的优先程度。score分值有正有负,资源不会被分配到score为负的节点上。另外,Heartbeat还定义了两个特殊的值:INFINITY和-INFINITY,分别表示正无穷大和负无穷大。它们的运算关系如下。
INFINITY +/- -INFINITY : ERROR
INFINITY +/- int : INFINITY
-INFINITY +/- int : -INFINITY
另外,在使用某些resource时,constraints包含了一些缺省的或者说是不言自明的规则。比如:对一个资源组resource group来说,我们就没有必要特地在constraints中指明资源组中的resource必须允许在同一个节点,并且它们应该按照列出来的顺序启动和按照逆序停止了。
跟node项一样,用户也不应该配置status项,它是Heartbeat用来记录和修改集群节点的地方。
4.5 Heartbeat管理工具
Heartbeat提供了一系列的管理工具,包括GUI工具和crm_*命令工具等,Heartbeat GUI Guide能够实时的监控节点和资源的运行情况,并且还能修改配置文件,比较方便使用。不过它主要用于Linux的X server环境下。其他的crm_*命令工具主要包括:crm_attribute, crm_failcount, crm_mon, crm_sh, crm_uuid, crm_diff, crm_master, crm_resource , crm_standby, crm_verify等。另外Heartbeat软件包还附带了hb_standby,hb_takeover和cl_status 等一些其他的工具。大部分工具都可以在prefix/sbin目录中找到(prefix是指你在安装Heartbeat时configure的—prefix指定的目录)。我们这里仅仅介绍一下用户查看和管理资源的crm_resource工具,其他的工具可以在Linux-HA官方网页上找到相关的用法。
CRM管理程序crm_resource功能示例:
Examples
1)查看所有资源
crm_resource -L
2)查看资源跑在哪个节点上
crm_resource -W -r apcstart_2
resource apcstart _2 is running on: server1
crm_resource -W -r apcstart _2
resource apcstart _2 is NOT running
4)启动/停止资源
crm_resource -r apcstart_2 -p target_role -v started
crm_resource -r apcstart_2 -p target_role -v stopped
5)查看资源在cib.xml中的定义
crm_resource -x -r apcstart_2
6)将资源从当前节点移动向另个节点
crm_resource -M -r apcstart_2
7)将资源移向指定节点
crm_resource -M -r apcstart_2 -H c001n02
8)允许资源回到正常的节点
crm_resource -U -r apcstart_2
NOTE: the values of resource_stickiness and default_resource_stickiness may mean that it doesnt move back. In such cases, you should use -M to move it back and then run this command.
9)将资源从CRM中删除
crm_resource -D -r apcstart_2 -t primitive
10)将资源组从CRM中删除
crm_resource -D -r my_first_group -t group
11)将资源从CRM中禁用
crm_resource -p is_managed -r apcstart_2 -t primitive -v off
12)将资源从新从CRM中启用
crm_resource -p is_managed -r apcstart_2 -t primitive -v on
13)Resetting a failed resource after having been manually cleaned up
crm_resource -C -H c001n02 -r apcstart_2
14)检查所有节点上未在CRM中的资源
crm_resource -P
15)检查指定节点上未在CRM中的资源
crm_resource -P -H c001n02
Querying a parameter of a resource. Say the resource is the following:
<primitive id="example_mail" class="ocf" type="MailTo" provider="heartbeat">
<instance_attributes id="example_mail_inst">
<attributes>
<nvpair id="example_mail_inst_attr0" name="email" value="root"/>
<nvpair id="example_mail_inst_attr1" name="subject" value="Example Failover"/>
</attributes>
</instance_attributes>
</primitive>
You could query the email address using the following:
crm_resource -r example_mail -g email
16)设置资源的某个属性
crm_resource -r example_mail -p email -v "myemailaddress@somedomain.com"
5 Heartbeat基础架构
Heartbeat基本上可以分为三层:heartbeat层,CCM层和CRM层。
heartbeat层主要负责底层信息交互和基础构架;CCM层比heartbeat更加抽象一点,主要负责节点之间的通信和它们之间的关系的维护;CRM层则更加抽象,它是整个Heartbeat的“大脑”,它不区分各个resource的不同点,只是负责各resource的在各节点之间的分配,当某节点崩溃时,将该节点的资源转移到其他节点。

图1、HeartBeat的基础架构图
6 Heartbeat各模块分析
整个Heartbeat软件的通信模块,各个节点之间的任何通信都是通过这个模块完成。这个模块会根据不同类型的通信启动不同的事件 handler,当监听到不同类型的通信请求后会分给不同的handler来处理。这个从整个Heartbeat的启动日志中看出来。
从这个名字就可以看出这个模块基本上就是v2的heartbeat的一个集群中心,整个系统的一个大脑了,他主要负责整个系统的各种资源的当前配置信息,以及各个资源的调度。也就是根据各资源的配置信息,以及当前的运行状况来决定每一个资源(或者资源组)到底该在哪个节点运行。不过这些事情并不是他直接去做的,而是通过调度其他的一些模块来进行。
他通过heartbeat模块来进行节点之间的通信,调度节点之间的工作协调。随时将通过heartbeat模块收集到的各个成员节点的基本信息转交给CCM某块来更新整个集群的membership信息。他指挥LRM(local resource manager)对当前节点的各资源执行各种相应的操作(如start、stop、restart和monitor等等),同时也接收LRM在进行各种操作的反馈信息并作出相应的决策再指挥后续工作。另外CRM模块还负责将各个模块反馈回来的各种信息通过调用设定的日志记录程序记录到日志文件中。
LRM是整个Heartbeat系统中直接操作所管理的各个资源的一个模块,负责对资源的监控,启动,停止或者重启等操作。这个模块目前好像支持有四种类型的资源代理(resource agent):heartbeat自身的,ocf(open cluster framework),lsb(linux standard base,其实就是linux下标准的init脚本),还有一种就是stonith。stonith这种我还不是太清楚是一个什么类型的。
四种类型的resource agent中的前三种所调用的脚本分别存如下路径:
heartbeat:/etc/ha.d/resource.d/
ocf:/usr/lib/resource.d/heartbeat/
lsb:/etc/init.d/
LRM就是通过调用以上路径下面的各种脚本来实现对资源的各种操作。每一种类型的脚本都可以由用户自定义,只要支持各类型的标准即可。实际上这里的标准就是接受一个标准的调用命令和参数格式,同时返回符合标准的值即可。至于脚本中的各种操作时如何的LRM并不care。
他主要负责将CRM发过来的一些信息按照配置文件中的各种设置来进行计算,分析。然后将结果信息按照某种固定的格式通过CRM提交给 TE(Transition engine)去分析出后续需要采取的相应的action。PE需要计算分析的信息主要是当前有哪些节点,各节点的状况,当前管理有哪些资源,各资源当前在哪一个节点,在各个节点的状态如何等等。
主要工作是分析PE的计算结果,然后根据配置信息转换成后续所需的相应操作。个人感觉PE和TE组合成一个类似于规则引擎实现的功能,而且 PE和TE这两个模块只有在处于active的节点被启动。另外PE和TE并不直接通信,而都是通过Heartbeat的指挥中心CRM来传达信息的。
CIB在系统中充当的是当前集群中各资源原始配置以及之后动态变化了的状态,统计信息收集分发中心,是一个不断更新的信息库。当他收集到任何资源的变化,以及节点统计信息的变化后,都会集成整合到一起组成当前集群最新的信息,并分发到集群各个节点。分发动作并不是自己和各个节点通信,同样也是通过heartbeat模块来做的。
CIB收集整理并汇总出来的信息是以一个xml格式保存起来的。实际上Heartbeat v2的资源配置文件也就是从haresources迁移到了一个叫cib.xml文件里面。该文件实际上就是CIB的信息库文件。在运行过程中,CIB可能会常读取并修改该文件的内容,以保证信息的更新。
CCM的最主要工作就是管理集群中各个节点的成员以及各成员之间的关系。他让集群中各个节点有效的组织称一个整体,保持着稳定的连接。heartbeat模块所担当的只是一个通信工具,而CCM是通过这个通信工具来将各个成员连接到一起成为一个整体。
一个无阻塞的日志记录程序,主要负责接收CRM从各个其他模块所收集的相关信息,然后记录到指定额度日志文件中。当logd接收到日志信息后会立刻返回给CRM反馈。并不是一定要等到将所有信息记录到文件后再返回,日志信息的记录实际上是一个异步的操作。
apphbd模块实际上是给各个模块中可能需要用到的计时用的服务,是通过watchdog来实现的。这个模块具体的细节我还不是太清楚。
主要功能是进程恢复管理,接受从apphbd所通知的某个(或者某些)进程异常退出或者失败或者hang住后的恢复请求。RMD在接受到请求后会作出restart(如果需要可能会有kill)操作。
在 V2的Heartbeat中,为了将资源的监控和切换结合起来,同时支持多节点集群,Heartbeat提供了一种积分策略来控制各个资源在集群中各节点之间的切换策略。通过该积分机制,计算出各节点的的总分数,得分最高者将成为active状态来管理某个(或某组)资源。
如果在CIB的配置文件中不做出任何配置的话,那么每一个资源的初始分数(resource-stickiness)都会是默认的0,而且每一个资源在每次失败之后所减掉的分数(resource-failure-stickiness)也是0。如此的话,一个资源不论他失败多少次,heartbeat都只是执行restart操作,不会进行节点切换。一般来说,resource-stickiness的值都是正数,resource-failure-stickiness的值都是负数。另外还有一个特殊值那就是正无穷大(INFINITY)和负无穷大(-INFINITY)。如果节点的分数为负分,那么不管什么情况发生,该节点都不会接管资源(冷备节点)。随着资源的各种状态的发生,在各节点上面的分数就会发生变化,随着分数的变化,一旦某节点的分数大于当前运行该资源的节点的分数之后,heartbeat就会做出切换动作,现在运行该资源的节点将释放资源,分数高出的节点将接管该资源。
在CIB的配置中,可以给每个资源定义一个分数,通过resource-stickiness来设置,同样也可以设置一个失败后丢失的分数,通过resource-failure-stickiness来设置。如下:
<primitive id=”mysql_db” class=”ocf” type=”mysql” provider=”heartbeat”>
<meta_attributes id=”mysql_db_meta_attr”>
<attributes>
<nvpair name=”resource_stickiness” id=”mysql_db_meta_attr_1″ value=”100″/>
<nvpair name=”resource_failure_stickiness” id=”mysql_db_meta_attr_2″ value=”-100″/>
</attributes>
</meta_attributes>
…
<primitive />
上面的配置就是给mysql_db这个resource配置了两个分数,成功运行的时候所得到的分数(resource_stickiness)和运行失败会丢失的分数(resource_failure_stickiness),两项分数值一样多,成功则得100分,失败则-100分。
除了可以通过给每个资源单独设置两项的分数之外,也可以将所有的resource设置成相同的分数,如下:
<configuration>
<crm_config>
<cluster_property_set id=”cib-bootstrap-options”>
<attributes>
…
<nvpair id=”default-resource-failure-stickiness” name=”default-resource-failure-stickiness” value=”-100″/>
<nvpair id=”default-resource-stickiness” name=”default-resource-stickiness” value=”100″/>
…
</attributes>
</cluster_property_set>
</crm_config>
…
在这个配置中,就是给所有资源设置了两个默认的分数,省去单独每个资源都设置的麻烦。当然,如果在设置了这个default分数之后,同时也给部分或者全部资源也设置了这两个分数的话,将取单独设置的各个资源设置的分数而不取默认分数。
除了资源的分数之外,节点自身同样也有分数。节点分数可以如下设置:
…
<constraints>
<rsc_location id=”rsc_location_group_mysql” rsc=”group_mysql”>
<rule id=”mysql1_group_mysql” score=”200″>
<expression id=”mysql1_group_mysql_expr” attribute=”#uname” operation=”eq” value=”mysql1″/>
</rule>
<rule id=”mysql2_group_mysql” score=”150″>
<expression id=”mysql2_group_mysql_expr” attribute=”#uname” operation=”eq” value=”mysql2″/>
</rule>
</rsc_location>
</constraints>
…
注意这里节点分数的设置是放在configuration配置项里面的constraints配置项下的,通过rule来设置。这里是通过节点主机名来匹配的(实际上heartbeat的很多配置中对主机名都是很敏感的)。这里的value值就是节点的主机名,rule里面的score就是一个节点的分数。
通过上面的配置,我们可以作出如下计算:
a、在最开始,两边同时启动heartbeat的话,两边都没有开始运行这个resource,resource本身没有分数,那么仅仅计算节点的分数:
mysql1的分数:node+resource+failcount*failure=200+0+(0*(-100))=200
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
heartbeat会做出选择在mysql1上面运行mysql_db这个资源,然后mysql1的分数发生变化了,因为有资源自身的分数加入了:
mysql1的分数:node+resource+failcount*failure=200+100+(0*(-100))=300
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
b、过了一段时间,heartbeat的monitor发现mysql_db这个资源crash(或者其他问题)了,分数马上会发生变化,如下:
mysql1的分数:node+resource+failcount*failure=200+100+(1*(-100))=200
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
heartbeat发现mysql1节点的分数还是比mysql2的高,那么资源不发生迁移,将执行restart类操作。
c、继续运行一段时间发现又有问题(或者是b后面restart没有起来)了,分数又发生变化了:
mysql1的分数:node+resource+failcount*failure=200+100+(2*(-100))=100
mysql2的分数:node+resource+failcount*failure=150+0+(0*(-100))=150
这时候heartbeat发现mysql2节点比mysql1节点的分数高了,资源将发生迁移切换,mysql1释 mysql_db相关资源,mysql2接管相关资源,并在mysql2上运行mysql_db这个资源。这时候,节点的分数又会发生变化如下:
mysql1的分数:node+resource+failcount*failure=200+0+(2*(-100))=0
mysql2的分数:node+resource+failcount*failure=150+100+(0*(-100))=250
这时候如果在mysql2上面三次出现问题,那么mysql2的分数将变成-50,又比mysql1少了,资源将迁移回 mysql1,mysql1的分数将变成100,而mysql2的分数将变成-150,因为又少了资源所有者的那100分。到这里,mysql2节点的分数已经是负数了。heartbeat还有一个规则,就是资源永远都不会迁移到一个分数分数是负数的节点上面去。也就是说从这以后,mysql1节点上面不管mysql_db这个资源失败多少次,不管这个资源出现什么问题,都不会迁移回mysql2节点了。一个节点的分数会在该节点的heartbeat重启之后被重置为初始状态。或者通过相关命令来对集群中某个节点的某个资源或者资源组来重置或者查看其failcount,如下:
crm_failcount -G -U mysql1 -r mysql_db #将查看mysql1节点上面的mysql_db这个资源的failcount
crm_failcount -D -U mysql1 -r mysql_db #将重置mysql1节点上面的mysql_db这个资源的failcount
当然,在实际应用中,我们一般都是将某一些互相关联的资源放到一起组成一个资源组,一旦资源组中某资源有问题的时候,需要迁移整个资源组的资源。这个和上面针对单个资源的情况实际上没有太多区别,只需要将上面mysql_db的设置换到资源组即可,如下:
…
<group id=”group-mysql”>
<meta_attributes id=”group-mysql_meta_attr”>
<attributes>
<nvpair id=”group-mysql_meta_attr-1″ name=”resource_stickiness” value=”100″/>
<nvpair id=”group-mysql_meta_attr-1″ name=”resource_failure_stickiness” value=”-100″/>
</attributes>
</meta_attributes>
<primitive>
…
</primitive>
…
</group>
…
这样,在该资源组中任何一个资源出现问题之后,都会被认为该资源组有问题,当分数低于其他节点出现切换的时候就是整个资源组的切换。
另外,对于INFINITY和-INFINITY这两个值,实际上主要用途就是为了控制永远不切换和只要失败必须切换用的。因为代表的意思就是拥有正无穷大的分数和失败就到负无穷大,主要用来满足极端规则的简单配置项。
总的来说,一项资源(或者资源组)在一个节点运行迁移到另一个节点之前,可以失败的次数的计算公式可以如下表示:
(nodeA score - nodeB score + stickiness)/abs(failure stickiness),即为A节点分数减去B节点分数,再加上资源运行分数后得到的总分数,除以资源失败分数的绝对值。
CRM可以忽略各resource之间的区别的诀窍在于resource agent。resource agent就像是硬件驱动程序一样,把底层的resource包裹在自己内部,而提供给CRM的是统一的操作接口。resource agent在Heartbeat中主要分为三类,按照Heartbeat推荐度从大到小排列分别为:OCF,LSB和Heartbeat自身定义的resource agent。按照复杂度和健壮性而言,它们也是按照从大到小的顺序排列的。
LSB resource agent一般是由操作系统或者软件发行者定义的shell脚本,但是为了能够应用于Heartbeat V2,它们必须符合LSB Spec的限制。它必须实现的三种操作分别是:start, stop, status。注意:LSB resource agent不能附带参数和选项值。对于start操作来说,在节点中启动已存在resource时,不应该返回错误信息,而应该返回0以表示成功(非0表示失败)。同样的,stop一个已经停止的resource也是允许的,并应该返回0以表示成功。status操作用来确定resource的运行状态。在resource正确运行的节点上进行status操作,应该返回0以及其他正常的打印输出,在resource已经停止的节点上进行status操作应该返回3以及其他正常的打印输出。另外,你可以通过某些操作检查提供的初始化脚本是否符合Heartbeat对LSB resource agent的要求。
Heartbeat resource agent基本上和LSB resource agent差不多,但是在状态信息操作(status)上和LSB resource agent存在差异。它要求定义三种必须的操作,分别是start, stop, status。和LSB一样,Heartbeat resource agent的start操作将仅仅在status显示某个resource没有被启动时,才开启某个节点的resource;并且在一个集群中,Heartbeat不会在同一时间在不同的节点上开启同一个resource。stop操作保证节点上的resource不再运行,在stop某个resource时,Heartbeat resource agent会去查看它是否已经被停止了,但是对于那些它不知道是否停止的resource,Heartbeat将采取强制措施,来保证resource被明确的停止掉了。比如,Heartbeat有可能在stop失败以后重启某个节点以清除错误。status操作用来确定resource的运行状态。对于Heartbeat resource agent来说,它应该正确的报告它的运行状况:在resource运行正常的时候打印OK或者running,否则就不应该打印这样的信息。注意:Heartbeat resource agent不检查status的返回值(它是为了兼容早期的Linux脚本,这些脚本status操作并不返回正确的返回值,但是会正确的打印OK或running值)。status操作可以发生在start操作之前以检查resource是否已经在运行了,它也可以用于释放资源。在V1版本中,如果stop后的status操作表明该资源仍然在运行,那么机器将被重启以保证resource确实被停止,但是在开启了CRM的V2版本中并不这么做,它使用stonith。Heartbeat和LSB另外的一个不同点在于,它可以接受参数。这些参数将被置于操作名称之前,如下所示:
如果在haresources行中IPaddr脚本(Heartbeat resource agent)的参数为10.10.10.1,表示为:
IPaddr::10.10.10.1
那么实际上Heartbeat调用真正的IPaddr脚本的start操作时对应为:
IPaddr 10.10.10.1 start
OCF specification实际上是对LSB的扩展,它的一些resource agent脚本文件可以在/usr/lib/ocf/resource.d/中找到,/usr/lib/ocf/resource.d/heartbeat中的那些都是随Heartbeat软件包附带的OCF resource agent脚本。{provider}表示提供者,你可以在/usr/lib/ocf/resource.d/增加你自己的目录,然后把OCF resource agent脚本放在这个目录中。为了方便编写OCF resource agent,很多返回码和通用的OCF函数被放在/usr/lib/heartbeat/ocf-shellfuncs(实际上在最新的版本中(V2.1.3),现在这个文件只是引用了$OCF_ROOT/resource.d//heartbeat/.ocf-shellfuncs),你可以方便的把它include进来。注意:Heartbeat实现的OCF Spec和标准本身并不完全一致,但是,这些改变并没有违反OCF specification。另外,Heartbeat提供了一个ocf-tester的脚本用于方便用户编写和测试OCF resource agent。
普通的OCF resource agent必须包括以下四个操作:start, stop, monitor, meta-data。start操作启动resource。如果resouce被正确启动了,那么返回0,否则返回除7以外的任何错误值。stop操作停止resource。当resouce被正确启动时,返回0,否则返回除7以外的任何错误值。monitor操作监控resource的健康状况,返回0表示resource正常运行,7表示它已经被停止,其他任何值表示错误。meta-data操作以xml摘要(xml snippet)的形式提供这个resource的信息。OCF Spec实际上严格定义了每个操作的返回值。我们必须遵守这些规定,如果返回了错误的返回值,Heartbeat将会出现一些莫名其妙的错误。特别要注意的是,Heartbeat必须区分resource的完全停止状态和有错误的,不确定的状态。另外,OCF resource agent应该支持validate-all操作,该操作用于验证环境中的配置paremeters。如果这些参数有效的的,返回0;如果无效返回2;如果resource未配置返回6;如果找不到了那个被resource agent认为正常运行的软件返回5。对于cloned和multi-state resources来说应该支持其他的操作:promote, demote和notify。promote操作把本地的resource提升为master/primary状态,应该返回为0;demote操作把本地的resource降级为slave/secondary状态,应该返回为0;notify被heartbeat程序用来给agent发送pre和post通知事件,通知resource正在发生或者已经发生的事情,必须返回0。另外还有两个OCF指定的但是Heartbeat目前不支持的操作:reload和recover。reload操作在不影响服务的情况下resource的配置信息。recover操作是start操作的一个变体,它尝试着在本地恢复一个resource。
另外,OCF也能够接受参数,这些参数可以告诉它要控制的是resource的哪一个实例,或者告诉它对这个实例应该怎么做。OCF的参数和Heartbeat resource agent不同。OCF参数通过环境变量传递参数,这些参数都以:OCF_RESKEY_开头。比如,以ip作为参数传递给脚本将设置环境变量:OCF_RESKEY_ip。
另外,linux-HA列举了一些用户在编写OCF脚本中经常容易犯的错误。我们应该要注意避免。详细的OCF resource agent信息可以查看OCF Spec。
下面的列表详细列出的三类resource agent的一些特性:
表1、三类resource agent的一些特性
9.1 安装node1的脚本

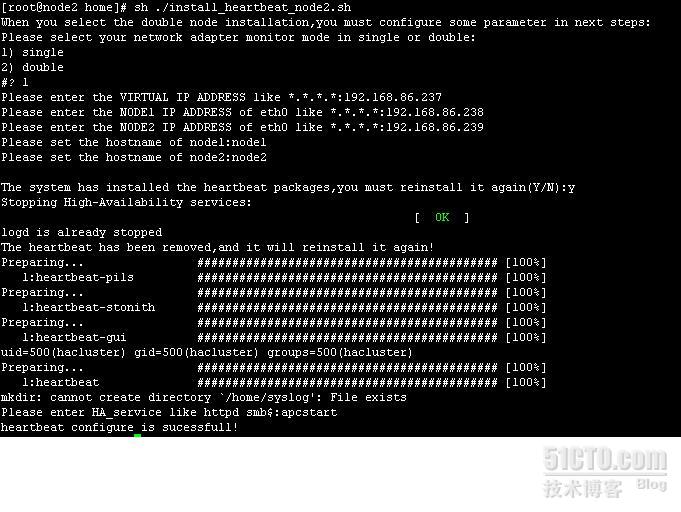
9.2 安装node2的脚本
10.1 测试重启down掉的服务
1、 在node1主机上启动apcstart,然后再启动heartbeat
/etc/init.d/apcstart start
/etc/init.d/heartbeat start
2、 在node2主机上启动heartbeat
/etc/init.d/heartbeat start
3、 在node1主机上停掉apcstart
/etc/init.d/apcstart stop
查看apcstart进程是否会重新启动
ps -ef | grep apcstart或者/etc/init.d/apcstart status
1、 首先down掉node1主机的网卡,node2是否会自动启动apcstart服务,接管服务。
ifconfig eth0 down
2、 当node1正常后,资源是否会切换会node1主机,同时node2会停掉apcstart,释放浮动地址。


















