
1. 项目背景
Hadoop C++ Extension(HCE)由百度开发的Hadoop MapReduce C++扩展框架,其诞生源于baidu/dpf组对Hadoop MapReduce稳定性、扩展性和高效率的追求。HCE将MapReduce任务的执行迁移到C++环境,从而可以避免java虚拟机由于GC机制以及JNI调用所产生的不必要内存和性能开销,提供更加精确的内存控制。同时,HCE提供了可与hadoop原生java接口想媲美的API,使得用户可以方便的编写HCE的Map和Reduce任务。
之前,我们已经对HCE进行了一系列性能测试,数据表明,比起Streaming框架的管道式数据交互处理和纯Java MapReduce的Java空间数据处理效率,HCE框架直接基于C++空间的数据处理具备先天优势。框架测试HCE对比纯Java框架约有21 – 41%的性能提升,对比streaming框架的性能提升更高。
但是,到目前为止,我们的性能测试还不够完善,并没有形成一套完整的测试和评价标准。随着HCE的不断完善,HCE也会被更多的线上应用所使用,如何准确的评估系统、线上应用甚至集群硬件配置的优劣,都会成为实际的问题。基于以上的考虑,本项目应运而生:为HCE,或者说Hadoop设计一套完善的benchmark,从而用于实现以下目标(包含但不限于):
(1) 对比Hadoop 其他接口和HCE接口的性能,体现HCE的性能优势。
(2) 对HCE的不同版本间进行性能基准测试,从而知道HCE的进一步开发和完善。
(3) 指导服务器选型。通过不同的硬件搭配,测试Hadoop应用的性能,确定哪些硬件配置更适合Hadoop集群。
2. 相关工作
为了实现一套更加贴切实际的benchmark,我们进行了一系列调研工作,对目前存在的几个benchmark,如gridmix以及Intel HiBench做了详细的研究,同时,作为hadoop自带的benchmark gridmix,我们对其进行了更加深入的研究,并将其所包含的用例全部迁移至HCE,并进行了性能对比。
Intel HiBench 调研
Intel在Hadoop benchmark做了一些重要工作,提供了一套Benchmark suite – HiBench来对其Hadoop集群做benchmark,并通过HiTune进行性能数据采集。
HiBench选取的计算模型较为全面和综合,既包含Micro Benchmarks,又包含web search,machine learning等应用,如下表所示:
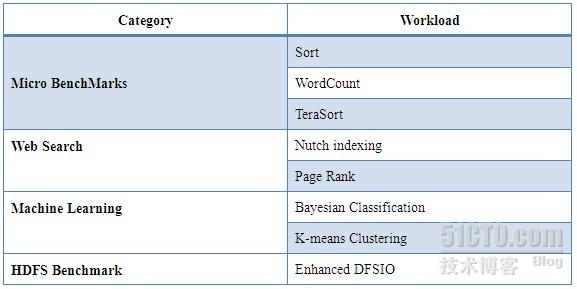
这些Benchmark程序代表的计算模型,实现方式和输入数据如下表所示:
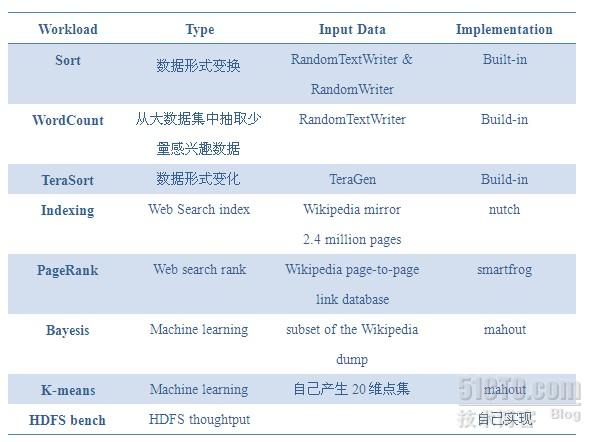
这些benchmark程序负载的特点如下表所示:
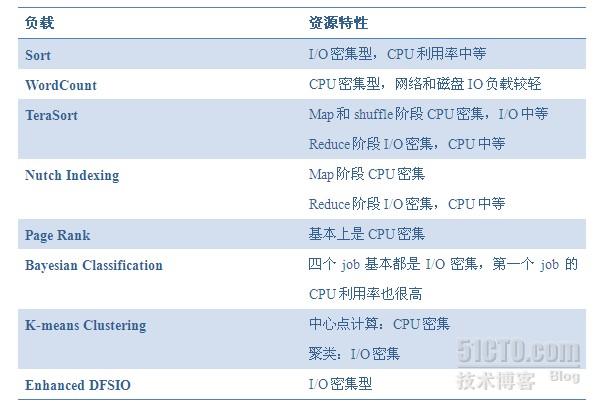
HiBench并没有和一般的benchmark一样,给出一组性能指标,在论文中,HiBench做性能分析时用到了如下指标:
※完成时间(在做不同版本hadoop性能比较时使用)
*任务完成总时间
*各个Task的map,shuffle,sort,reduce 时间 (通过统计JobHistory获得)
※CPU使用率
*System,User,I/O wait
※内存
*Used,Cached,Swapped
※Disk I/O 吞吐率
Gridmix调研
Gridmix是hadoop自带的一个benchmark,这套benchmark实现的比较简单,仅仅使用hadoop examples包中的GenericMRLoader来产生负载,当然Gridmix使用GenericMRLoader进行不同参数以及不同迭代层次的组合,产生了几个具有一定代表性的负载:

以下是每一类负载所使用输入数据的特征,所用数据使用RandomTextWriter来生成

这些benchmark程序负载的都比较简单,没有任何复杂计算,准确的说,没有任何计算。
Gridmix并没有和一般的benchmark一样,给出一组性能指标,也没有指定任何需要得到的任何性能数据,它仅仅提供了一组典型用例。
Gridmix的HCE迁移和测试
Gridmix作为hadoop自带的一个benchmark,如果用于HCE与java原生接口以及bistreaming接口的性能比较,获得的性能结果更容易得到社区的承认,因此,我们将gridmix的所有用例都是用HCE实现了一遍,并对其进行java原生接口与HCE进行了性能评测,测试结果显示,在大数据量下(gridmix所使用的大数据量是2T),HCE相比java性能提升了接近10%,内存使用也由于java。
不过,gridmix所使用的用例并不能代表所有的hadoop使用场景,经过我们分析,gridmix的用例中,并没有明显的CPU-Bound的用例,不存在比较复杂的计算。而现实应用中,不仅存在很多I/O密集型的应用,也存在很多的CPU密集型的应用,如聚类算法,倒排索引等等。因此,gridmix并不完全符合我们的预期。
3. Benchmark设计
一个完整的benchmark应该由三部分组成:输入数据集,计算模型以及性能指标。其中最重要的是计算模型,考虑到我们的benchmark必须集专用和通用于一身的特点,我们选择了如下一些用例:
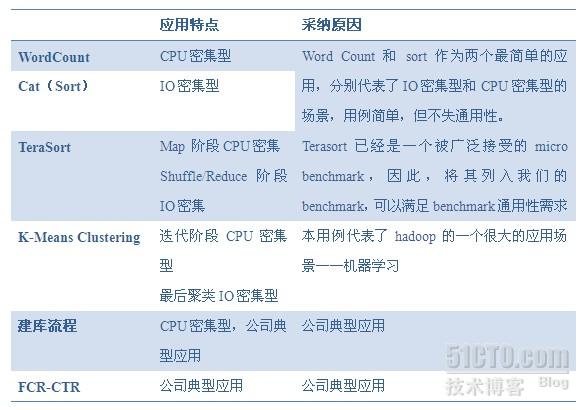
其次,根据实际的应用需要,并不是每个用例都会实现java、bistreaming、HCE三个版本,下表中给出了目前计划的每个用例的实现版本(打钩的均为计划实现,其中红色钩表示还未实现,蓝色钩表示目前有实现,但还需要进一步抽取和完善):

4. 进展
在我们选择的计算模型中,有一部分已经有现成的实现,稍加改动就可以使用,有一部分需要完全从头实现,有一部在于公司产品中已经实现,但需要抽取出来,成为benchmark的一部分,目前已经计划的主要工作如下:

5. Benchmark初步实验数据
我们对目前已实现的部分(Java和Hce版的kmeans, terasort, sort, wordcount)的部分进行了多次实验,并对实验结果进行了简单分析。
实验环境
Hadoop/HCE版本
集群信息

实验内容
在集群上分别对运行java以及HCE版的kmeans、terasort、sort、wordcount,并对其作业完成时间、作业各阶段完成时间、集群资源使用情况的进行统计和分析。考虑到作业完成时间有一定偶然性,每个作业均重复运行三次,统计数据取平均。
数据量

实验结果
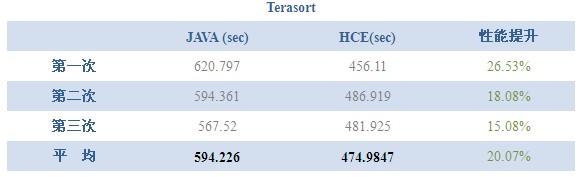
作业完成时间比较
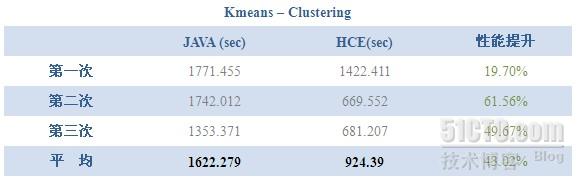



以上数据是所有作业执行时间的比较,从平均时间上来看,除了Sort之外,HCE的执行效率均比原生Java接口要高,特别是Kmeans的两个作业,性能分别提升了32%和43%,当然,考虑到Kmeans的HCE和Java实现有细微差别(Vector的实现方式有些不同,因为找不到mahout的Vector底层实现,因此无法做到实现细节完全相同),所以Kmeans的实验结果并不是最具说服力的。Kmeans的HCE实现有待后期改善。
性能提升最不明显的是Sort,在三次执行中,其中有两次HCE的执行时间比Java短,但平均时间上来看,HCE比Java慢0.5%。考虑到Sort的三次执行中作业完成时间太不稳定,因此,其实验结果也不具有太大说服力。
在所有四个用力中,最具说服力的可能应该是Terasort了。HCE的执行时间比Java块20%左右。且三次执行结果比较也相对稳定。此外,WordCount性能提升也相当显著(30%)。
作业各阶段(平均)时间比较
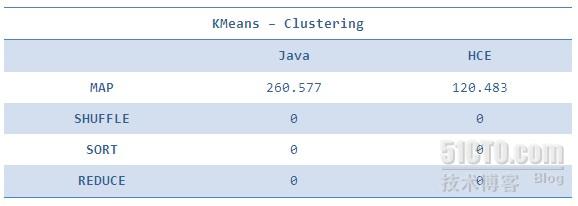



以上表格中给出了作业各个阶段的平均完成时间。从表中可以发现,在执行时间很短的一些步骤中(如各个作业的Sort,以及WordCount的Reduce阶段),Java的执行效率比HCE要高,从这个现象可以看出,HCE在数据量较少的情况下优势并不明显,而JNI之类的调用开销成了决定其执行时间较长的因素。而在数据量比较大时(比如出WordCount之外其他作业的Reduce阶段,以及所有作业的Map和Shuffle阶段)HCE的优势就逐渐展现出来了。
这里我们还要特别关注Sort用力,在上一节的作业执行时间比较中,我们发现Sort的Java和HCE版本并没有什么差距,但当我们关注各阶段时间时会发现,HCE的四个阶段均比Java快。
集群资源使用情况
以下集群资源使用图,只采集了benchmark某一次运行的数据,“HCE作业执行期间”表示Benchmark中四个用例的Hce版本全部运行的时间段,同样,“Java作业执行期间”表示所有四个作业的Java版本执行的时间段。


以上两个曲线图分别展示了Java和Hce版本的用例在执行期间集群CPU的使用情况。相比之下,Java版用例执行期间花费了更多的CPU(Java 77.06% vs HCE 70.86%)。此外,考虑到Java版用例执行时间比HCE的执行时间还要长,更加能够体现出HCE能够更加有效的利用CPU资源这一特性。

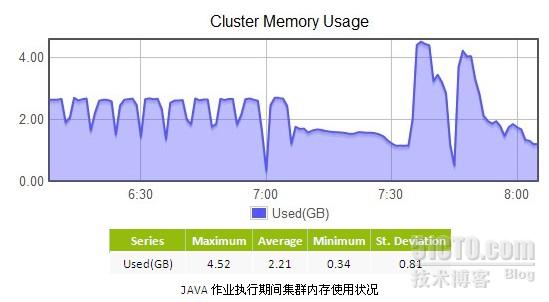
以上两个曲线图分别展示了Java和Hce版本的用例在执行期间集群内存的使用情况。从中可以看出,HCE所使用的内存量比Java略大(Java 2.21G vs HCE 2.62G)。这可以看出,虽然HCE的C++环境下,手动内存管理相比Java的GC机制可以节省一些由于内存回收不及时带来的内存开销,但HCE环境毕竟比Java环境多开了一些进程。这些方面导致了HCE会比Java多一些内存开销。当然,这仅仅是一次作业执行的资源使用情况,不能太说明问题。
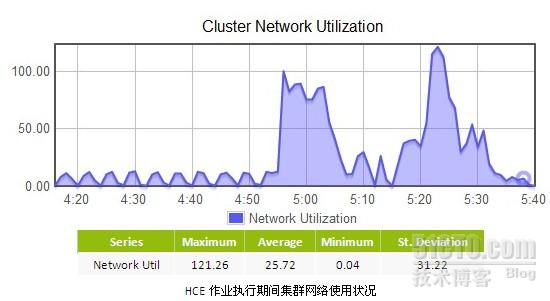
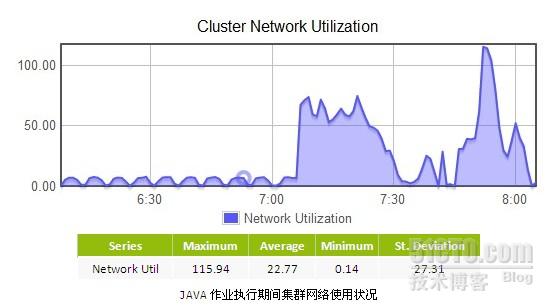
网络设备使用率方面,考虑到Java和HCE都是使用HDFS,且作业调度机制是一样的,所以网络数据流量应该相差不大,但综合考虑时间和平均网络使用率,Java版的网络流量相比更多一些,通过分析作业日志发现,Java版的Sort程序执行期间出现了比较严重的异常,导致部分作业重新执行的次数比较多,所以流量也更多一些。
(作者:xuyinfei)




















