项目集介绍父模块SpringbootSeries此模块中只有一个pom.xml文件,是后面所有模块的父模块,主要功能有两个:子模块管理和依赖管理。类别必选可选基础框架jdk 17+ spring-boot-starter 3.2.4spring-boot-starter-web 3.2.4spring-cloud 2023.0.1spring-cloud-alibaba 2023.0.1.0数据库
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、智能路由、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
新专题来了,此课程以springcloud3.2.4为版本,共21篇文章并配套27个源码工程,合可免费下载,涵盖springboot,springcloud,alibaba nacos, dubbo, sentil, gataway, mybatis等基本所有的常用的框架功能。
Storm 是一个免费并开源的分布式实时计算系统。利用 Storm 可以很容易做到可靠地处理无限的 数据流,像 Hadoop 批量处理大数据一样,Storm 可以实时处理数据。在Storm中,topology的构建是一个有向无环图。结点就是Spout或者Bolt,而边就是Spout和Bolt之间或者是Bolt和Bolt之间连接关系。
本系列专题是围绕分布式系统展开的,如果您有意成为架构师或是进入一些大厂。这些知识可以说是必备的知识点。系列文档从java、中间件到设计依次展开。详细包含:java基础、中间件、存储、配置、架构设计共5方面的内容。
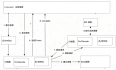
微服务本质上是一种设计模式,一种指导思想。在落地实现时有多种技术选型。在一些文献中也会对其概念、思想、以及与SP或单体服务做些一些对比。这些内容在笔者看来只能是靠个人的理解和悟性来归纳总结,所以就不在此进行描述了。本文会贴合技术来描述下微服务的一些基础知识点。一、基础完整的架构如下图所示:1.1、服务注册发现 服务注册就是维护一个登记簿,它管理系统内所有的服务地址。当新的
一、原理Netty 是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现。它提供了对 TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞 的,通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。 二、核心设计在 IO 编程过程中,
一、IO模型1.1、阻塞 IO 模型最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除 block 状态。典型的阻塞 IO 模型的比如socket(data = socket
本章简单聊下网络和LBS相关的内容,本文中描述的都是基础部分。一般的公司会在基础上封装成需要的基础服务。网络分4层和7层:4层:网络访问层、网络层、传输层、应用层;7层:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层;一、网络1.1、TCP/IP原理TCP/IP 协议不是 TCP 和 IP 这两个协议的合称,而是指因特网整个 TCP/IP 协议族。从协议分层 模型方面来讲,TCP/IP
一、概念 RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。 AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言 等条件的限制。 RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用
一、概念Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用 Scala 语言编写,目前是 Apache 的开源项目。broker:Kafka 服务器,负责消息存储和转发;topic:消息类别,Kafka 按照 topic 来分类消息;partition:topic 的分区,一个 topic 可以包含多个 partition,topic 消息保存在
在业务开发范围内,加密算法一般在gateWay、Token类以及IM类的应用经常使用。一般不会用到太深,但都需要经过仔细设计。因为这类代码一般都涉及到底层和上下游的交互。后期改造的成本比较大,笔者曾经做过几个登陆程序,有时间总结下设计思路。本章先简单介绍下常用的加密算法概念和基础的原理,一点皮毛的不能再皮毛的简介了。一、AES高级加密标准(AES,Advanced Encryption Stand
一、集成<dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</version&
本章围绕两个主题展开,会话管理和事务的处理(数据处理)流程,目的是了解下zk的CS模式是如何运转的。一、服务端启动详细的启动过程可参考https://blog.51cto.com/arch/5363898 文章中的描述,那么服务端启动后主要要做哪些工作呢,主要有以下三个:设置默认Watcher;设置Zookeeper服务器地址列表;创建ClientCnxn;二、会话2.1、创建会话创建的流
本节所涉及的内容多数都可以由zoo.cfg文件来配置一、内存数据Zookeeper的数据模型是树结构,Zookeeper会定时将数据存储到磁盘上,通过zoo.cfg文件来配置。在内存中存储了整棵树的内容,包括所有的节点路径、节点数据、ACL信息。这也是zk性能比较好的一个原因。1.1、DataTreeDataTree是内存数据存储的核心,它是一个树结构代表了内存中一份完整的数据。DataTree不
一、节点Zookeeper的数据节点称为ZNode,ZNode是Zookeeper中数据的最小单元,每个ZNode都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,称为树,如下图所示:每个数据节点都是由生命周期的,类型不同则会不同的生命周期,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)、顺序节点(SEQUENTIAL)三大类,可以通过组合生成
Zookeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。典型应用场景数据发布/订阅负载均衡命名服务分布式协调/通知集群管理Master选举分布式锁分布式队列数据发布/订阅数据发布/订阅系统,即配置中心。需要发布者将数据发布到Zookeeper的节点上
一、配置参数dataDir 用于配置走开服务器的快照文件目录,默认情况下,如果没有配置dataLogDir,那么事务日志也会存储在这个目录中。考虑到事务日志的写性能直接影响zookeeper整体的服务能力,因此建议同时设置dataDir和dataLogDir。dataLogDir 存储事务日志文件,zookeeper在返回客户端事务请求响应之前,必须将本次请求对应的事务日志写入到磁盘中,因此,事务
一、概述相比单体应用而言分布式应用(因系统的范围比较大,所以笔者习惯使用“应用”这个概念,下文同)具有分布性、对等性、并发性等特点。同样也需要解决缺少全局时钟、通信异常、脑裂(分区异常)、三态(成功、失败、超时)、节点故障等问题;其中最重要的就是数据一致性问题。分布式一致性一般分为强一致性、弱一致性和最终一致性三种模式,最常被应用的是弱一致性和最终一致性这两种模式(最终一致性是弱一致性的一种特例,
本章基于java的sdk演示下es的操作。例子稍简单一点,读者可自己扩展。本发环境如下:mac os 11、es7.8.0、idea2022maven引入 <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>e
一、基础知识ES的搜索由两部分组成:1、查询;2、获取 ;一般来讲,ES很少用match_all查询,正常是通过查询+过滤器组合的方式来完成;后者不计算得分,且结果可被缓存,性能会更好。具体采用哪种查询类型取决于数据在索引中是如何存储的;查询过滤器用于过滤查询结果用,一般用在查询和聚合查询的body条件中。查询 格式说明适用场景match_allmatch_all:{}匹配所有文档全文检查,不太建
一、概要在ES中会分为4种,常用的有度量和桶。后者其实就是前者的细分。比如参加此次活动的人数为1000人,男生占400人女生占 600人。这个1000可以看成是度量,后面的男生女生可看成是桶。分类桶(bucket):每个桶都与键和文档关联;度量:在一组文档上跟踪和计算度量值;矩阵:对多个字段进行操作并根据从请求的文档字段中撮的值生成矩阵结果;管道:聚合其它聚合的输出;处理的逻辑如下图所示:使用时会
此章依然是es的restfulAPI,因为es的映射是可选的操作,又由于其比较重要,所以单拿一节告别说明。除了API还有字段定义(相当于mysql的create table)相关的知识点,这些对优化es比较有意义。一、概要说明简单示例对索引字段的定义,包括数据类型、存储属性、分析器、词向量等。put customer { "mappings":{ "properties":{
此章内容比较简单,是官方的一个主要API,精选了一些日常开发中需要使用的,罗列一下。一、通用规则操作原则索引操作:索引建议只增不改,因为修改过程相当于删除+重索引;更新数据:这是一个先查询确认文档存在、修改内容、删除旧文档、在原有位置重新索引的过程。ES默认是采用版本号的方式来控制的删除数据:删除文档:ES会先标记,再异步物理删除;删除索引:直接删除整个文件;关闭索引:类似删除,但会在磁盘上保留文
es简介 纯java开发,采用倒排索引进行文档的索引,同时通过TF-IDF(词频-逆文档词频)排序算法确保结果的相关性。在索引过程中还可以通过脚本的方式自定义:1、处理拼写错误;2、关键词变体,分词;3、查询内容时附带统计信息;4、自动提示功能等。可以用于主存储也可以用于文档搜索。需要注意的是es不支持事务,所以用做主存储时需要留意。es的优点是:1、以文档为基础,可用作nosql存储;
今天笔者新开一个系列es(以后简称es),原因是笔者在日常工作中发现大部分研发同学只了解其API开发,对于技术评估和索引优化基本是黑盒的状态,而这个中间件又是互联网公司面试和工作中的非常得要的一个。纯B端的应用开发基本不会接触到es,在此笔者不会描述太深,主要围绕核心原理和日常开发这两点,假如有意愿的同学建议全篇通读一下。对于日常工作和面试基本够用了。简单概括一下ES的使用场景:1、可做过目录索引
上面4章围绕索引讲索了一些通用的实现原因,但并没涉及到具体的数据库。因笔者接触最多的是就是mysql数据库,所以综合以上知识点罗列下mysql数据库的特点。存储引擎存储引擎是基于表的,而不是数据库。在mysql中会有:MyISAM、InnoDB、BDB(BerkeleyDB)、Merge、Memory(Heap)、Example、Federated、Archive、CSV、Blackhole、Ma
查询慢语句show processlist; 查看Mysql的最大缓存show global variables like "global max_allowed_packet" 查看当前正在进行的事务select * from information_schema.INNODB_TRX 查看当前Mysql的连接数show status like 'thread%' 查看连接情
mysql索引
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号