我们知道,在LVS中Director很可能会成为整个系统的瓶颈,一旦Director宕机,服务便停止了,这在生产环境中是不允许的,所以要保证服务可用性,这就用到了高可用集群。
所谓高可用集群就是我们的主机中任何一个节点或者是节点中的服务出现故障的时候,我们可以将此节点的资源(或者说此节点上的高可用服务)能够转移到其他正常运行的节点上并继续提供服务的这样一个架构。
思考这样一个问题:对于集群中的节点来讲,我们是怎么知道这个节点出现故障了呢?? 一旦出现故障,又是怎么通知其他节点的呢??
这些信息我们必须得通过一种机制能够实现在各节点之间进行通信,这些基本信息是靠信息层(Messaging Layer)来实现的,在信息层我们需要传递各节点的心跳信息(heartbeat)以及各种集群事务信息,还包括一些数据报文的重传信息等等。这些信息对于各节点之间的通信至关重要,我们又把它称之为高可用集群的基础架构—基础架构层,基于这个层次,各节点本身运行的信息以及一些集群事务信息就能够向上进行输出了。
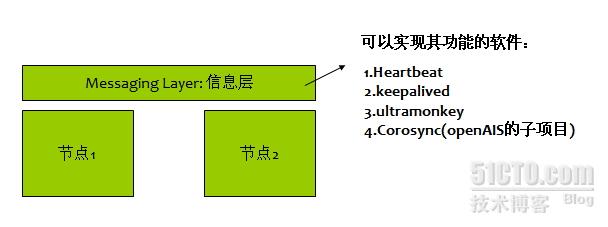 能够提供信息层功能的软件有:
能够提供信息层功能的软件有:
Heartbeat
keepalived
ultramonkey
Corosync(OpenAIS 的子项目)
这样一来,上层运行的应用程序自身只要能够调用基础架构层的功能,并且自己能够根据收集过来的信息来判定当前这个服务应该在哪个节点上运行,那么这个应用程序就是一种高可用的应用。但是此时,这种应用程序必须是ha-aware的。
Ha-aware: 它意味着应用程序自身能够从信息层收集高可用信息或者事务信息,并在我们节点发生状态转换的时候能够自动采取一些动作来控制节点上资源的调度,但是大多数的应用程序都不具备高可用的能力,所以在信息层之上又附加了一个通用层:CRM
CRM--资源管理器层:它是一个粘合层,完成了对不具备ha-aware的软件提供了ha的能力,借此来监控各节点的运行状况并且管理各节点的资源,一旦节点出现故障,它就会将该节点上的资源转移到其他正常运行的节点之上。
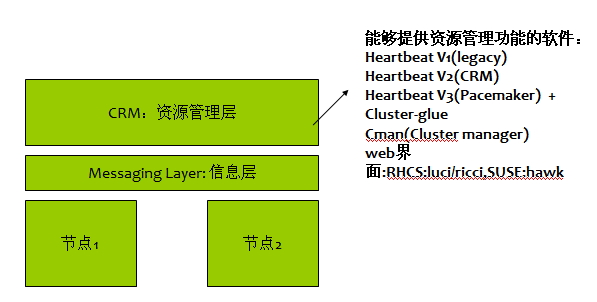
能够提供资源管理这一功能的软件有:
Heartbeat V1(legacy)
Heartbeat V2(CRM)
Heartbeat V3(Pacemaker) + Cluster-glue
Cman(Cluster manager)
web界面:RHCS:luci/ricci,SUSE:hawk
CRM要管理的资源的类型有:
primitive : 也称为local类型,同一时刻只能运行在一个节点上
group :组资源,将多个资源定义成一个组,这个组在同一时刻运行在一个节点上
clone :需要同时运行在多个节点上的资源
Master-slave :需要运行在2个节点,并且是一主一从的
知道有这些资源了,那么如何使这些资源在各节点上运行起来呢??
这就需要有一个资源代理(RA),在某一时刻资源代理来管理各节点上资源的动作,即资源代理就是当某一节点上的资源出现故障,它可以将该资源在另外节点上启动起来的一个脚本程序。
RA的类型有:
Heartbeat v1
LSB:linux standard base--linux标准库
OCF:open cluster framework 能力比LSB更强
STONITH:隔离
再想另外的问题:我们知道节点可能有多个,那么当一个节点上的资源出现故障,它要向哪个节点进行转移呢??如果某一节点故障,那么其他节点是否还能够以一个集群的身份运行??
我们一个一个解决;
1、资源间的约束关系可以定义故障节点上的资源进行转移的位置:
资源约束类型:
位置约束:定义了某个资源更倾向于运行在哪个节点上
顺序约束:定义了资源的启动顺序,例如,共享存储要先于web服务进行启动
排列约束:它定义了资源间的排列关系,如:ip地址要不要和web服务运行在一起等
有了这样一个约束,我们的RA代理就可以根据其约束关系来判定某一资源到底要运行在哪一个节点上。
2、split-brain:脑裂,脑裂即集群的各节点之间无法互相通知集群信息了,但是节点本身仍然是运行的,这样一来,各节点间无法探测到彼此的心跳信息了,那么彼此就会以为对方节点出现故障了,因此就会在彼此之间产生资源争用,这在集群中是不允许的;
那么一旦出现这种状况,首先要解决的问题就是,一旦某一节点故障,其他节点是否还能称之为集群继续运行,这要取决于一种仲裁机制:quorum—法定票数,我们每个节点都持有票数,当一个节点出现故障的时候,可以根据当前状态的集群所持有的票数占上一个状态上的集群票数的多少来判定它是否还能够以集群的身份予以运行,如果法定票数超过半数以上,我们就称之为集群继续运行,如果不到一半,各节点就会认为其不再是集群中的一员,再运行资源也没有什么意义了,它就会自动放弃自身资源,不再运行,这就避免了资源间的争用;
计算节点是否能当做集群来运行,这要有一个节点来作为DC:Designated Coordinator—指定的协调员完成。
有一种特殊的情况:如果是2节点的集群,当其中一个节点出现故障了,按照我们此前的说法,任一节点持有的票数都不超过一半,那么它就会自动放弃本身的资源了,显然是不行的,在这种情况下,就不能采取法定票数这种策略了,这种情况下,RHCS套件借助了额外手段:在2节点集群中,引入一个共享磁盘,2节点可以通过和共享磁盘通信 机制来判定它是否正常运行,如果某一节点不再和共享磁盘进行通信,就可以认为它故障了,另一节点可以继续提供服务,这时的共享磁盘就是一个伪节点的存在,称之为仲裁磁盘。

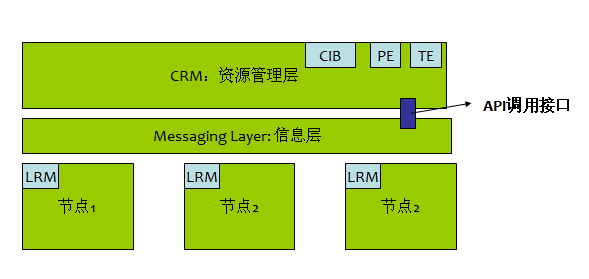
这一问题解决了,我们接着回到CRM资源管理层上,在CRM上有几个相关概念:
CIB: 在CRM中,要知道一个节点上到底有哪些资源,资源间的约束关系有哪些以及刚刚我们提及的一个节点故障后剩余节点还有多少票等待,在CRM中都要定义其相关的配置文件,这个配置文件就叫做CIB—cluster information base :集群信息库,也可以理解为它是在每个节点上运行的一个进程,它在每个节点上都要保持一致。
PE: 集群策略引擎,它负责收集信息层中各节点信息,并判定接下来的节点还能否成为一个集群继续运行;
TE:集群事务引擎,PE是负责判定能不能运行,它则是负责将PE计算的结果指挥着各资源代理进行响应的操作;
LRM:本地资源代理,它即是TE要通知的代理,管理各资源的启动;
LRM,CIB是运行在各个节点上的,而PE,TE 是运行在DC上的。
汇总:
我们将这些概念结合起来,从宏观上解析下高可用工作机制:
首先,通过信息层获取各节点间的信息,这些信息通过资源管理层来进行管理,如果某一节点出现故障,DC来计算剩下的票数,PE判断各节点是否能作为一个集群进行运行,如果可以运行,它将通知给TE,TE就要根据这一结果指挥着LRM来进行资源的转移等动作,而RA则是提供执行这一动作的脚本,而这一系列的动作都保存在CIB库中。
总结:
高可用集群软件的解决方案:
Heartbeat + v1 + haresource
Heartbeat + v2 + crm
Heartbeat + v3 + pacemaker
Corosync + pacemaker
Cman(openais) + rgmanager
下面我们基于一个简单的高可用实验来看下高可用集群实现的过程:
前提:准备2台主机作为高可用集群的2个节点(特殊集群),让这2个节点基于高可用来提供web服务。
高可用集群配置条件:
1. 在一个节点上一定要能够解析集群中各节点的主机名
2. 各节点上时间要同步
3. 主机名要和“uname –n”的结果保持一致
4. 在各节点上所提供的服务不要开机自动启动
5. 节点间相互通信(这个是非必须的)
环境:
两台主机分别是:
172.16.9.1 node1.test.com
172.16.9.2 node2.test.com
配置:
设置2主机名和uname –n 保持一致
编辑/etc/sysconfig/network 修改其HOSENAME名称即可
解析节点间主机名
- vim /etc/hosts
- 172.16.9.1 node1.test.com node1
- 172.16.9.2 node2.test.com node2
双机互信:
node1节点
- ssh-keygen -t rsa -P ''
- ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
node2 节点:
- ssh-keygen -t rsa -P ''
- ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
时间同步:
- date 11281315;ssh node2 'date 11281315'
在2节点安装http服务,并为各节点提供web服务网页
- yum –y install httpd
- echo “<h1>node1.test.com</h1>” > /var/www/html/index.html
为了演示高可用的效果,在第二个节点上提供了不同的web页面
- echo “<h1>node2.test.com</h1>” > /var/www/html/index.html
先开启httpd服务,看能否正常访问该页面
如果可以正常访问,再关闭该服务,并且不要让其开机自动启动:
Chkconfig httpd off
安装高可用所需要的rpm包:
- cluster-glue-1.0.6-1.6.el5.i386.rpm
- libesmtp-1.0.4-5.el5.i386.rpm
- cluster-glue-libs-1.0.6-1.6.el5.i386.rpm
- pacemaker-1.1.5-1.1.el5.i386.rpm
- corosync-1.2.7-1.1.el5.i386.rpm
- pacemaker-cts-1.1.5-1.1.el5.i386.rpm
- corosynclib-1.2.7-1.1.el5.i386.rpm
- pacemaker-libs-1.1.5-1.1.el5.i386.rpm
- heartbeat-3.0.3-2.3.el5.i386.rpm
- perl-TimeDate-1.16-5.el5.noarch.rpm
- heartbeat-libs-3.0.3-2.3.el5.i386.rpm
- resource-agents-1.0.4-1.1.el5.i386.rpm
将相同包复制node2上一份:
- scp *rpm node2:/root
这里包含所有依赖的包,yum 安装即可:
yum –y localinstall –nogpgcheck “rpm_name”
修改配置文件:
- cd /etc/corosync
- cp corosync.conf.example corosync.conf
vim corosync.conf
添加如下内容
- service {
- ver: 0
- name: pacemaker
- # use_mgmtd: yes
- }
- aisexec {
- user: root
- group: root
- }
同时将原来内容做下修改:
- secauth: on
- bindnetaddr: 172.16.0.0 #修改为主机所在网段
- to_syslog: no
生成节点间通信时用到的认证密钥文件:
- corosync-keygen
将corosync.conf和authkey复制至node2:
- scp -p corosync.conf authkey node2:/etc/corosync/
分别为两个节点创建corosync生成的日志所在的目录:
- mkdir /var/log/cluster
- ssh node2 'mkdir /var/log/cluster'
接下来就可以启动corosync服务了
- Service corosync start
- Ssh node2 ‘service corosync start‘
两节点启动成功,接下来将http服务添加为高可用资源:
- [root@node1 ~]# crm configure
- crm(live)configure# property stonith-enabled=false #红帽5版本中并没有隔离的设备,所以在这里手动将隔离功能取消
- crm(live)configure# property no-quorum-policy=ignore #2节点间并不存在法定票数的定义,这里将其忽略不计
- crm(live)configure# primitive IP ocf:heartbeat:IPaddr params ip=172.16.66.1
- crm(live)configure# primitive Httpd lsb:httpd
- crm(live)configure# colocation IP_with_Httpd inf: IP Httpd
- crm(live)configure# verify
- crm(live)configure# commit
- crm(live)configure# exit
资源定义完成,查看资源启动情况:
- [root@node1 ~]# crm status
- ============
- Last updated: Wed Nov 28 13:58:42 2012
- Stack: openais
- Current DC: node1.test.com - partition with quorum
- Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
- 2 Nodes configured, 2 expected votes
- 2 Resources configured.
- ============
- Online: [ node2.test.com node1.test.com ]
- IP (ocf::heartbeat:IPaddr): Started node2.test.com
- Httpd (lsb:httpd): Started node2.test.com
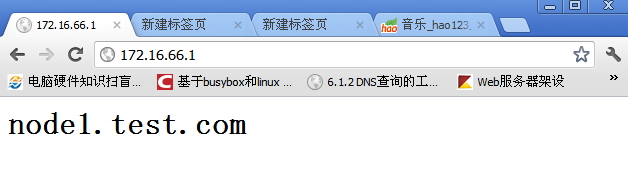
在这里看到资源在节点2上启动了,我们访问下172.16.66.1.会出现节点2上定义的页面
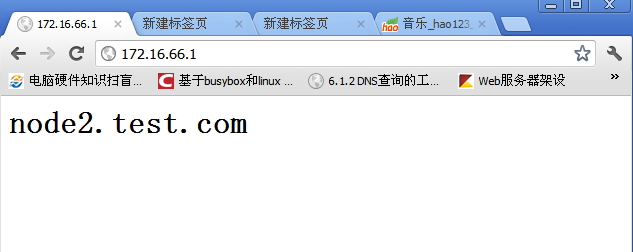
下面手动模拟节点故障,看资源转移状况:
- [root@node2 ~]# crm node standby
- [root@node2 ~]# crm status
- ============
- Last updated: Wed Nov 28 13:59:09 2012
- Stack: openais
- Current DC: node1.test.com - partition with quorum
- Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
- 2 Nodes configured, 2 expected votes
- 2 Resources configured.
- ============
- Node node2.test.com: standby
- Online: [ node1.test.com ]
- IP (ocf::heartbeat:IPaddr): Started node1.test.com
- Httpd (lsb:httpd): Started node1.test.com
再访问172.16.66.1就会出现在节点1上定义的页面了: