
本次 主要介绍MySqL高可用集群环境的搭建。DRBD的英文全称为:Distributed Replicated Block Device(分布式块设备复制),是Linux内核存储层中的一个分布式存储系统,可利用DRBD在两台Linux服务器之间共享块设备、文件系统和数据,类似一个网络RAID1的功能。DRBD的架构如图所示:
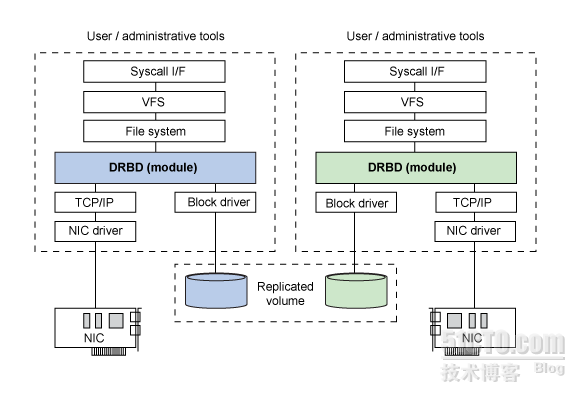
其他的就不多说了。下面来实现吧。
前提:
1)本配置共有两个测试节点,分别node1.zhou.com和node2.zhou.com,相的IP地址分别为192.168.35.11/24和192.168.35.12/24;
2)node1和node2两个节点上各提供了一个大小相同的分区作为drbd设备;我们这里为在两个节点上均为/dev/sda5,大小为2G;
3)调整两个节点的时间要同步
4)关闭两台服务器的selinux。
关闭方法:# setenforce 0
要开机就已经是关闭要编辑配置文件
# vim /etc/selinux/config
定位到:SELINUX 并修改为:SELINUX=permissive
5)配置好yum源
6)系统为rhel5.4,x86平台;
一、准备工作
两个节点的主机名称和对应的IP地址解析服务可以正常工作,且每个节点的主机名称需要跟"uname -n“命令的结果保持一致;因此,需要保证两个节点上的/etc/hosts文件均为下面的内容:
192.168.35.11 node1.zhou.com node1
192.168.35.12 node2.zhou.com node2
为了使得重新启动系统后仍能保持如上的主机名称,还分别需要在各节点执行类似如下的命令:
- Node1:
- # sed -i 's@\(HOSTNAME=\).*@\1node1.zhou.com@g'
- # hostname node1.zhou.com
- Node2:
- # sed -i 's@\(HOSTNAME=\).*@\1node2.zhou.com@g'
- # hostname node2.zhou.com
为了在两台服务器之间文件复制方便,下面来配置双机互信。
设定两个节点可以基于密钥进行ssh通信,这可以通过类似如下的命令实现:
- Node1:
- # ssh-keygen -t rsa
- # ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
- Node2:
- # ssh-keygen -t rsa
- # ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
配置完成了。以后两台服务器之间在复制文件时就不用输入密码了。这样就方便多了。
二、安装配置DRBD
下载所需的软件包:rbd83-8.3.8-1.el5.centos.i386.rpm kmod-drbd83-8.3.8-1.el5.centos.i686.rpm这两个软件包要根据自己的系统来定。
下载完成后直接安装即可:
- # yum -y --nogpgcheck localinstall drbd83-8.3.8-1.el5.centos.i386.rpm kmod-drbd83-8.3.8-1.el5.centos.i686.rpm
两台服务器上都要安装上。
下面的操作在node1.zhou.com上完成。
1)复制样例配置文件为即将使用的配置文件:
# cp /usr/share/doc/drbd83-8.3.8/drbd.conf /etc
2)
- 配置/etc/drbd.d/global-common.conf
- global {
- usage-count no;
- # minor-count dialog-refresh disable-ip-verification
- }
- common {
- protocol C;
- handlers {
- pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
- pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
- local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
- # fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
- # split-brain "/usr/lib/drbd/notify-split-brain.sh root";
- # out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
- # before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
- # after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
- }
- startup {
- #wfc-timeout 120;
- #degr-wfc-timeout 120;
- }
- disk {
- on-io-error detach;
- #fencing resource-only;
- }
- net {
- cram-hmac-alg "sha1";
- shared-secret "mydrbdlab";
- }
- syncer {
- rate 1000M;
- }
- }
- 3、定义一个资源/etc/drbd.d/web.res,内容如下:
- resource web {
- on node1.zhou.com {
- device /dev/drbd0;
- disk /dev/sda5;
- address 192.168.35.11:7789;
- meta-disk internal;
- }
- on node2.zhou.com {
- device /dev/drbd0;
- disk /dev/sda5;
- address 192.168.35.12:7789;
- meta-disk internal;
- }
- }
以上文件在两个节点上必须相同,因此,可以基于ssh将刚才配置的文件全部同步至另外一个节点。
# scp -r /etc/drbd.* node2:/etc
4、在两个节点上初始化已定义的资源并启动服务:
1)初始化资源,在Node1和Node2上分别执行:
# drbdadm create-md web
2)启动服务,在Node1和Node2上分别执行:
# service drbd start
3)查看启动状态:
# cat /proc/drbd
version: 8.3.8 (api:88/proto:86-94)
GIT-hash: d78846e52224fd00562f7c225bcc25b2d422321d build by mockbuild@builder10.centos.org, 2010-06-04 08:04:16
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:505964
也可以使用drbd-overview命令来查看:
# drbd-overview
0:web Connected Secondary/Secondary Inconsistent/Inconsistent C r----
到此DRBD就算配置好了。要把drbd服务配置成集群资源则服务不能开机自动启动,所以还要在两台服务器上把drbd服务关闭
# service drbd stop
# chkconfig drbd off 三、安装配置Corosync和pacemaker 1、安装corosync和pacemaker,首先下载所需要如下软件包至本地某专用目录(这里为/root/cluster): cluster-glue cluster-glue-libs heartbeat openaislib resource-agents corosync heartbeat-libs pacemaker corosynclib libesmtp pacemaker-libs 下载地址:http://clusterlabs.org/rpm/。请根据硬件平台及操作系统类型选择对应的软件包;这里建议每个软件包都使用目前最新的版本。 下载完成后安装软件: # 用yum来安装: # yum -y --nogpgcheck localinstall *.rpm 2、做相应的配置 1)配置corosync
- # cd /etc/corosync
- # cp corosync.conf.example corosync.conf
- totem {
- version: 2
- secauth: on --->这个要启用
- threads: 0
- interface {
- ringnumber: 0
- bindnetaddr: 192.168.35.0 ---->修改为相应的网络地址
- mcastaddr: 226.94.1.9 ----->这个组播地址也做一点修改以防与其他人的相同。
- mcastport: 5405
- }
- }
- logging {
- fileline: off
- to_stderr: no
- to_logfile: yes
- to_syslog: no ----->日志文件用一个就行了。所以要关闭一个
- logfile: /var/log/cluster/corosync.log
- debug: off
- timestamp: on
- logger_subsys {
- subsys: AMF
- debug: off
- }
- }
- amf {
- mode: disabled
- }
- service { ----->从这行开始到结束是要添加的内容
- ver: 0
- name: pacemaker
- }
- aisexec {
- user: root
- group: root
- }
2)生成节点间通信时用到的认证密钥文件: # corosync-keygen 3)将corosync和authkey复制至node2: # scp -p corosync authkey node2:/etc/corosync/ 4)分别为两个节点创建corosync生成的日志所在的目录: # mkdir /var/log/cluster # ssh node2 'mkdir /var/log/cluster' 5)下面来尝试启动,(以下命令在node1上执行): # service corosync start 查看corosync引擎是否正常启动:
- # grep -e "Corosync Cluster Engine" -e "configuration file" /var/log/cluster/corosync.log
- Jun 14 19:02:08 node1 corosync[5103]: [MAIN ] Corosync Cluster Engine ('1.2.7'): started and ready to provide service.
- Jun 14 19:02:08 node1 corosync[5103]: [MAIN ] Successfully read main configuration file '/etc/corosync/corosync.conf'.
- Jun 14 19:02:08 node1 corosync[5103]: [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1397.
- Jun 14 19:03:49 node1 corosync[5120]: [MAIN ] Corosync Cluster Engine ('1.2.7'): started and ready to provide service.
- Jun 14 19:03:49 node1 corosync[5120]: [MAIN ] Successfully read main configuration file '/etc/corosync/corosync.conf'.
查看初始化成员节点通知是否正常发出:
- # grep TOTEM /var/log/cluster/corosync.log
- Jun 14 19:03:49 node1 corosync[5120]: [TOTEM ] Initializing transport (UDP/IP).
- Jun 14 19:03:49 node1 corosync[5120]: [TOTEM ] Initializing transmit/receive security: libtomcrypt SOBER128/SHA1HMAC (mode 0).
- Jun 14 19:03:50 node1 corosync[5120]: [TOTEM ] The network interface [192.168.35.11] is now up.
- Jun 14 19:03:50 node1 corosync[5120]: [TOTEM ] A processor joined or left the membership and a new membership was formed.
检查启动过程中是否有错误产生:
查看pacemaker是否正常启动:
- # grep ERROR: /var/log/cluster/corosync.log | grep -v unpack_resources
- # grep pcmk_startup /var/log/cluster/corosync.log
- Jun 14 19:03:50 node1 corosync[5120]: [pcmk ] info: pcmk_startup: CRM: Initialized
- Jun 14 19:03:50 node1 corosync[5120]: [pcmk ] Logging: Initialized pcmk_startup
- Jun 14 19:03:50 node1 corosync[5120]: [pcmk ] info: pcmk_startup: Maximum core file size is: 4294967295
- Jun 14 19:03:50 node1 corosync[5120]: [pcmk ] info: pcmk_startup: Service: 9
- Jun 14 19:03:50 node1 corosync[5120]: [pcmk ] info: pcmk_startup: Local hostname: node1.zhou.com
如果上面命令执行均没有问题,接着可以执行如下命令启动node2上的corosync # ssh node2 '/etc/init.d/corosync start' 注意:启动node2需要在node1上使用如上命令进行,不要在node2节点上直接启动; 使用如下命令查看集群节点的启动状态:
出现 这个结果显示Corosync安装成功了。 四、安装MySqL 下载软件:mysql-5.5.20-linux2.6-i686.tar.gz 在node1上操作 使node1为主节点:
- # crm status
- ============
- Last updated: Tue Jun 14 19:07:06 2011
- Stack: openais
- Current DC: node1.magedu.com - partition with quorum
- Version: 1.0.11-1554a83db0d3c3e546cfd3aaff6af1184f79ee87
- 2 Nodes configured, 2 expected votes
- 0 Resources configured.
- ============
- Online: [ node1.zhou.com node2.zhou.com ]
- # mkdir /mydata
- # mount /dev/drbd0 /mydata
- # mkdir /myata/data
- # groupadd -r -g 306 mysql
- # useradd -r -g mysql -u 306 -s /sbin/nologin -M mysql
- # chown -R mysql:mysql /mydata/data
- # tar xvf mysql-5.5.20-linux2.6-i686.tar.gz -C /usr/local/
- # cd /usr/local/
- # ln -sv mysql-5.5.20-linux2.6-i686 mysql
- # cd mysql
- # chown -R mysql:mysql .
- # ./scripts/mysql_install_db --user=mysql --datadir=/mydata/data/
- # chown -R root .
- # cp support-files/my-large.cnf /etc/my.cnf
- # cp support-files/mysql.server /etc/rc.d/init.d/mysqld
- # ln -sv /usr/local/mysql/include /usr/include/mysql
- # echo "/usr/local/mysql/lib" > /etc/ld.so.conf.d/mysql.conf
- # ldconfig -v | grep mysql
- # service mysqld start
- # service mysqld stop
- # chkconfig mysqld off
下面卸载/dev/drbd0 并让node2成为主节点 在node2上所要做的步骤: 同样要安装MySqL
- # scp node1:/root/mysql-5.5.20-linux2.6-i686.tar.gz ./
- # mkdir /mydata
- # mount /dev/drbd0 /mydata
- # mkdir /myata/data
- # groupadd -r -g 306 mysql
- # useradd -r -g mysql -u 306 -s /sbin/nologin -M mysql
- # chown -R mysql:mysql /mydata/data
- # tar xvf mysql-5.5.20-linux2.6-i686.tar.gz -C /usr/local/
- # cd /usr/local/
- # ln -sv mysql-5.5.20-linux2.6-i686 mysql
- # cd mysql
- # chown -R root:mysql .
- # scp node1:/etc/my.cnf /etc/
- # scp node1:/etc/rc.d/init.d/mysqld /etc/rc.d/init.d/
- # ln -sv /usr/local/mysql/include /usr/include/mysql
- # scp node1:/etc/ld.so.conf.d/mysql.conf /etc/ld.so.conf.d/
- # ldconfig -v | grep mysql
- # service mysqld start
- # service mysqld stop
- # chkconfig mysqld off
这样两个服务器上都安装上了MySqL 接着要的是让两个节点的drbd服务都处在slave状态,并把服务给停止了。为下面做集群服务做准备。 下面来在crm命令行中来配置集群资源
- # crm configure
- crm(live)configure# property stonith-enabled="false"
- crm(live)configure# property no-quorum-policy="ignore"
- crm(live)configure# rsc_defaults resource-stickiness=100
-------------这三个是全局配置------------------------
- crm(live)configure# verify
- crm(live)configure# commit
- crm(live)configure# show
- node node1.zhou.com
- node node2.zhou.com
- property $id="cib-bootstrap-options" \
- dc-version="1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
- cluster-infrastructure="openais" \
- expected-quorum-votes="2" \
- stonith-enabled="false" \
- no-quorum-policy="ignore"
- rsc_defaults $id="rsc-options" \
- resource-stickiness="100"
--------------下面来配置drbd资源并配置成主从资源-----------------------------
- crm(live)configure# primitive drbd ocf:linbit:drbd params drbd_resource="web" op monitor interval=29s role="Master" op monitor interval=31s role="Slave" op start timeout=240s op stop timeout=100s
- crm(live)configure# show
- crm(live)configure# show
- crm(live)configure# ms ms_drbd drbd meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
--------------drbd的主从资源定义完成--------------------------------
- crm(live)configure# primitive fs ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/mydata" fstype="ext3" op start timeout=60s op stop timeout=60s
----------------------这是定义一个文件系统-------------------------
- crm(live)configure# primitive myip ocf:heartbeat:IPaddr params ip="192.168.53.4"
- crm(live)configure# primitive mysqld lsb:mysqld
--------------这是定义VIP资源和mysqld服务----------------------------- 好了,所要用到的资源都以定义完成了。 --------------------下面来定义资源间的位置和次序的约束关系------------------------
- crm(live)configure# colocation fs_with_ms_drbd inf: fs ms_drbd:Master --->让fs与ms_drbd的主节点在一起
- crm(live)configure# order fs_after_ms_drbd inf: ms_drbd:promote fs:start ---->让ms_drbd先于fs启动
- crm(live)configure# colocation ip_with_ms_drbd inf: ip ms_drbd:Master ---> 让ip地址与ms_drbd的主节点在一起
- crm(live)configure# order fs_after_ip inf: ip fs:start ----> 让fs晚于ip启动
- crm(live)configure# colocation mysqld_with_fs inf: mysqld fs ------> 让mysql服务与fs在一起
- crm(live)configure# order mysqld_after_fs inf: fs mysqld:start -------> 让fs先于mysql服务启动
- 最要检测一下,并提交。
- crm(live)configure# verify
- crm(live)configure# show
- crm(live)configure# commit
下面来用命令来查看服务的运行情况:
- # crm_mon
- 如下所示的结果:
- Online: [ node1.zhou.com node2.zhou.com ]
- Master/Slave Set: ms_drbd [drbd]
- Masters: [ node2.zhou.com ]
- Slaves: [ node1.zhou.com ]
- fs (ocf::heartbeat:Filesystem): Started node2.zhou.com
- ip (ocf::heartbeat:IPaddr): Started node2.zhou.com
- mysqld (lsb:mysqld): Started node2.zhou.com
从上面可以看出:主节点是node2,从节点是node1 ,下面来让node2变为standby,查看服务是否转移到node1上。 在node2上执行如下命令:
- # crm node standby
- # crm_mon
- Node node2.zhou.com: standby
- Online: [ node1.zhou.com ]
- Master/Slave Set: ms_drbd [drbd]
- Masters: [ node1.zhou.com ]
- Stopped: [ drbd:0 ]
- fs (ocf::heartbeat:Filesystem): Started node1.zhou.com
- ip (ocf::heartbeat:IPaddr): Started node1.zhou.com
- mysqld (lsb:mysqld): Started node1.zhou.com
从上可知所有的服务都移到node1上了。说明整个服务和配置完成了,并检测了MySqL的高可用性。在两个节点之间可以正常的切换。



















