
Web browser的系统架构及未来的演进
Web browser的发展史
1990年 Tim Berners-Lee开发了第一个web browser WorldWideWeb。到了1993年,NCSA国家超级计算机应用中心开发出了第一个多平台的浏览器Mosaic, 后来的Navigator以及IE都是在Mosaic的基础上发展出来的。到了90年代末,由于微软对于IE的捆绑销售战略,终于挤垮了一度的领先者Navigator, 后者最终被美国在线收购收场。
2002年,依托于在操作系统上的优势以及捆绑的策略, IE一度达到了96%的浏览器市场份额。历史一再告诉我们,巅峰之后的道路只有一条,那就是下坡路,IE也不例外。从2003年开始,一批新的browser风起云涌,如雨后春笋般的发展起来,并逐渐蚕食IE的市场分额,主要包括从Navigator发展起来的Firefox, Google 的Chrome, Apple的Safari以及特立独行的Opera。2012年9月,在市场份额方面,Chrome终于取代IE的第一位置,而 Firefox和IE的份额几乎不相上下。
Web Browser的功能
在web user的眼里,web browser如同连接用户与web server的桥梁,web browser主要承担的角色包括接受web user的输入,向web server发送检索信息的请求,处理web server的反馈的信息,并呈现给web server.
而在web developer的眼里,web application 之于web browser如同native application 之于PC机上的OS, web browser呈现给web application的是所有web上的资源,包括文档、图片、文字、音频视频等等,而OS呈现给native application的是整个PC上的资源,包括硬件资源以及OS系统中的软件资源。
也许可以从功能和过程的角度对现阶段的web browser的下一个这样的定义:通过与用户的交互,向远端的server发出检索信息的请求,并处理server的反馈信息,最终通过显示屏传达给用户。web browser承担的更细节化的功能还包括:
- 缓存
- 连接状态维护
- 身份认证
- 请求支撑性数据
- 显示复杂的对象
- 错误处理
- 根据response的状态信息采取行动;
我们还可以从HTTP的请求产生以及响应处理的角度来描述browser的具体功能。当用户的某种行为触发了HTTP请求产生的时候,通常browser会采取如下的动作,
- browser检查caching中是否已经有相关信息;
- browser检查是否要提供认证信息;
- browser检查是否需要提供cookie信息;
- browser产生最终的HTTP 请求;
browser收到HTTP的响应后的处理过程:
当browser收到某个HTTP的响应,通常会采取如下的动作,
- 确认是否需要解码?
- 确认是否需要回传认证信息?
- 确认是否需要存储cookie信息?
- 确认是否需要缓存?
- 确认是否需要进一步请求其他的资源?
- 呈现响应的处理结果给用户
Web Browser的架构
通过对当时的几个主流的开源web browser(包括Mozilla, Konqueror,Safari, Firefox等)的研究,Alan Grosskurth 等人给出了一个通用的web browser架构[1],如下图1所示。
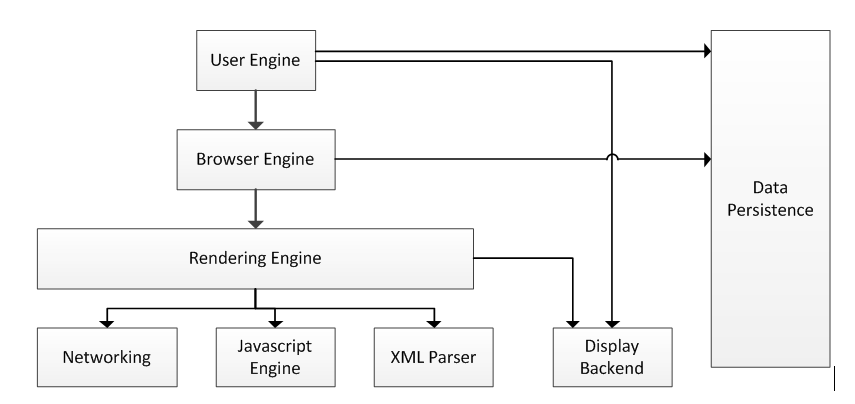
在[1]中,user engine被定义为用户管理、配置browser的各种工具, 一种更好的理解方式是进一步细分为如下两个子部:
- User interface
- User configuration
user interface可以认为是用户与browser上的应用或者功能的交互接口,一个主要的功能是把browser处理过的,来自server的响应信息,呈现用户;而user configuration主要是用户可以定义的、配置的有关browser的相关参数或者工具,例如在IE中的internet options,文件菜单等等;更常见的user interface 还包括bookmarking、 历史访问记录、前进及后退等功能。
如果要细说各种browser的差异,可能要数user interface上的差异最大了。由于普通用户的体验很大程度上决定于user interface的设计,因此拥有良好user interface设计的browser总是能够获得用户的青睐。例如国内的Maxthon浏览器很早的时候就实现了用户的favourites的在线同步功能,而且操作及其简单,你唯一需要的是就是记住你的帐户名以及密码,所以多年来我一直是Maxthon的忠实用户。如果你有兴趣体验一下Firefox的favourites在同步操作上繁琐与复杂,你或许会更好的理解这一点。
正如系统架构图显示的那样,Browser engine在user interface和rendering engine之间有一个承上启下的作用,例如browser engine提供了操控rendering engine的接口。在很多文章中,browser engine和rendering engine合二为一,命名为browser engine或者layout engine.
Rendering engine的基本功能是显示一个URI上的内容,这些内容包括HTML/XML,CSS style以及其它外部资源例如p_w_picpath,借助于各种插件,还可以显示其它的文件类型,例如PDF文件。需要理解的是,rendering engine绝不仅仅限于web browser的应用中,例如在email-client上,e-book, on-line helper system上都可以看到rendering engine的身影。
目前几大主流browser的Rendering Engine如下,
· Firefox: Gecko
· IE : Trident
· Chrome/Safari: Webkit
· Opera : Presto
尽管Rendering engine不与普通用户有直接的联系,但作为开发者,不论其专注于前端还是后端,毫无疑问,Rendering process都是理解web browser的一个基础。Rendering process完成从server端取数据,处理数据并显示数据给用户功能。一个rendering过程通常又包含如下的子过程,
1) Loading
这个过程中的一个重要问题就是协调或者优化各种资源的loading顺序。通常情况下HTML doc的loading与其它资源(例如p_w_picpath等)的loading是分开的,前者在其通道上会按照DOM的结构按顺序进行,而后者完全是不同的loading 通道和顺序。
另外一个问题是,script的loading和执行可能会阻止HTML doc的loading, 因此存在一种如何协调的机制。例如,简单的阻止HTML的loading,等待script的loading和执行完毕,可能会带来非常不好的用户体验。这一点对于web开发者尤其重要。
2) Parsing HTML
Parsing HTML的主要目的是形成DOM tree。在HTML的解析方面,现有的browser的实现 各不相同,这种现象可能是因为早期的web 标准在这方面的缺失。另一方面,因为早期web标准的松散,很多web 开发者对于HTML的理解有偏差甚至本身就是实现上的错误(至少相对标准定义而言,目前在网络遍布着众多实现错误的web page),这种差异不仅给web 开发者造成了大量的不便,同时也带来了不好的用户体验。
· Quirk mode
· Standards mode
· Almost standards mode
不过,随着HTML5的出现,这种在HTML parsing 各有千秋的browser也许会逐渐走到一起。在HTML5 标准中[2],定义了如下的一个解析过程,

3) Parsing styling information
结合已经形成的DOM tree, Styling 的解析能够形成content tree.
4) Framing
5) Layout
6) Painting
用于解析和执行javascript code的一个解释器,最早由Brendan Eich用c实现,命名为SpiderMonkey,后来出现了用java实现的Rhino。目前的几大主流browser的Javascript Engine如下,
· Firefox: TraceMonkey/JagerMonkey
· IE : Chakra
· Chrome: V8
· Safari: Nitro
· Opera : Carakan
在这些不断涌现的engine中,有一点不得不引起我们的重视: open source, 例如:spidermonkey, V8都是开源的; 就ECMAScript的支持情况而言,Google的V8, Firefox的Rhino以及opera的Carakan都已经支持到了ECMA-262, edition 5.
Javascript Engine主要的应用平台是隶属于client-side的 web browser,,但是为了能够在client-side和server-side进行代码共享,javascript engine也逐渐在web server端得到了应用。如果说对普通开发者而言,user interface提供了管理、操作browser的接口,那么对开发者而言,javascript Engine则提供了一套丰富的控制接口来控制web browser, 这些接口包括:HTML5 canvas, video,networking, external events, DOM handling, data storage等。
Web Browser的未来
作为web技术中最重要的一个创新,web browser在某种意义上算得上是连接user和web 的桥梁,尽管自web技术兴起以来,web browser的领域不乏残酷的争斗,但是自2003年以来的争斗才真正开启了web browser的百家争鸣时代,而从2008年以来争斗愈发激烈,斗争的领域不断的扩大,从desktop PC到tablet,再到mobile device。
随着google在web browser领域的攻城略地,曾几何时的统治者MSIE渐现颓势,新web技术的发展以及成熟,例如HTML5, mobile internet,cloud computing也许会更快地加速web browser发展,如果说最近5年来mobile OS引爆了人们的眼球,那么web的未来的会不会产生在根植于web browser的web OS呢?作为web OS的browser, 一方面提供与用户的丰富的交户接口,一方面直接管理本地的硬软件资源,更重要的一方面是管理、搜索整个web上的资源,个人认为,如下的几点将是web OS-based browser的有利推动因素,
· web app逐渐替代native app的趋势,不同于早期的browser仅仅满足web page的信息显示,未来的browser需要支持更多的来自web app需要的交互功能;
· Clouding computation and storage的推动, 本地存储以及管理的复杂性,给普通用户带来太多的复杂性和烦恼,尤其安全性的烦恼以及软件的频繁升级带来的烦恼;
· 应用环境的拓展,从传统PC向一切可能的终端的拓展;
· 物联网的发展和推动,一切设备都有联网的可能,从而使得远程的访问和控制成为可能;Browser逐渐增强和硬件平台资源直接交户的接口,各种终端的操作系统的概念会被弱化;而browser的相应的功能会增强, 硬件资源会大大增加,尤其是传感器部分;
· 终端的计算功能会逐渐减弱,图形处理功能、多媒体功能会增强,例如对于音频、视频的处理;终端包括:传统的PC, tablet, mobile smartphone以及一切可以联网的设备,例如家用电器;
· HTML 5标准的发展
[1]. Alan Grosskurth, Michael W. Godfrey , Architecture and evolution of the modern we browser, 2006


















