
本用户指南将简要介绍SymmetricDS配置中基础的和高级的概念。读完本指南,你将对SymmetricDS的能力和其中的概念有一个更好的理解。
1.1. System Requirements
SymmetricDS使用Java编写,需要JRE或者JDK 6.0及以上版本。
任何一个拥有Trigger技术和JDBC驱动的数据库都可能能够使用SymmetricDS。数据库通过Database Dialect被抽象,以支持不同的数据库特性。下面的数据库方言已经被包含进此发行版中(version 3.6.14):
1. MySQL 5.0.2及以上版本
2. MariaDB及以上版本
3. Oracle 10g及以上版本
4. PostgreSQL 8.2.5及以上版本
5. Sql Server 2005及以上版本
6. Sql Server Azure
7. HSQLDB 2.x
8. H2 1.x
9. Apache Derby 10.3.2.1及以上版本
10. IBM DB2 9.5及以上版本
11. Firebird 2.0及以上版本
12. Interbase 2009及以上版本
13. Greenplum 8.2.15及以上版本
14. SQLite 3及以上版本
15. Sybase Adaptive ServerEnterprise 12.5及以上版本
16. Sybase SQL Anywhere 9及以上版本
附录C Database Notes,可以查看你选用的数据库的兼容性问题和其他细节。
1.2. Concepts
1.2.1 Notes
SymmetricDS是一个基于Java的应用,提供了一个同步引擎,这个引擎在数据同步中作为一个agent(代理,代理后边说的那个数据库实例),提供一个数据库实例和网络中其他同步引擎之间的数据同步。
一个SymmetricDS引擎叫做一个Node。SymmetricDS被设计为可以扩展到成千上万个节点。属性配置文件中提供的数据库连接字符串,数据库用户名和数据库密码配置数据库连接信息。SymmetricDS可以同步数据库连接可以访问的任意的数据库表,只要数据库用户被分配了合适的数据库权限。
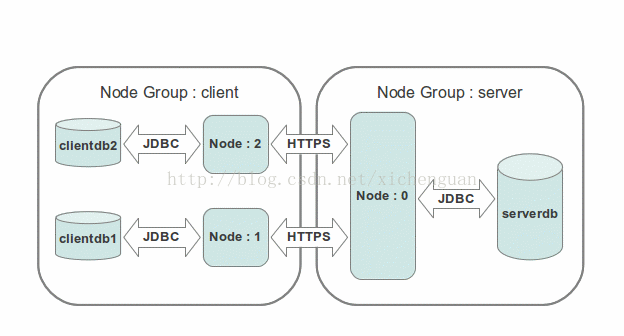
一个SymmetricDS节点被分配一个external id和一个节点group id。External id是用户指定的标示符,SymmetricDS使用这个标示符来标识一个特定的节点,数据被派往的节点。节点的group id用来标识节点所在的组或者层。它定义了一个节点整个网络中所有的节点中所处的位置。例如,一个节点的组可能被命名为‘corporate’,代表一个企业或者公司的数据库;另一个节点的组可能被命名为“local_office”,代表一个地区不同的机构的数据库。一个“local_office”的external id可能是一个机构的编码或者其他有标示性的字母组成的字符串。一个节点通过它的node id在一个网络中被唯一的区分开,这个node id是根据external id自动生成的。如果本地机构代码1有两个数据库和两个SymmetricDS节点,它们可能有一个值为“1”的external id和值为“1-1”和“1-2”的node id。
SymmetricDS可以以多种方式部署。最常见的选择是在作为一个独立的进程,以服务的形式运行于服务器中。当以这种方式被部署的时候,SymmetricDS可以作为一个客户端或者一个多租户的服务端,也可以依赖SymmetricDS数据库在整个数据库网络中的位置而定。尽管它可以与数据库服务器运行在同一个服务器上,但是不需要必须这么做。SymmetricDS可以被部署到一个应用服务器中,像Apache Tomcat,JBoss Application Server,IBM WebSphere中,作为一个web应用。
SymmetricDS被设计成一个对技术人员来说,简单,易用的工具。它可以被认为是一个web应用,只是用其他的SymmetricDS引擎作为客户端代替浏览器的角色。它拥有web应用的所有特性,可以使用调试web应用的原理来调试SymmetricDS。
1.2.2. Change Data Capture
数据库触发器开启SymmetricDS捕获数据变化功能,SymmetricDS会根据用户的配置自动安装触发器。数据库触发器记录的数据变化都在DATA表(DATA表是SymmetricDS中的系统表)。数据库被设计为非侵入性的,尽可能的轻量级。在SymmetricDS触发器被安装之后,外部应用执行的所有的DML statement产生的数据变化都会被捕捉。注意,用户的应用不需要添加额外的库,也不需要任何的更改;SymmetricDS不需要必须在线才能捕捉数据。
SymmetricDS配置的不同数据库实例间的数据库表需要有相同的结构。整个网络中的节点的配置通常在网络中的一个中心节点管理,也就是registration server节点。Registration Server节点几乎总是与树形拓扑网络结构中的root节点是同一个。当配置一个“叶”节点,需要配置的一个启动参数是registration server节点的URL。如果“叶”节点还没注册到root节点,它联系registration server然后请求加入到网络中。一旦请求被接受,“叶”节点就下载所需的配置。在一个节点被注册之后,SymmetricDS也可以在开始同步之前提供一个数据初始负载操作。
SymmetricDS将在启动时安装或者更新它的数据库触发器;当预定的同步触发器任务运行的时候,SymmetricDS会定期地再次安装新的触发器和更新原有的触发器(默认情况下,是在每天午夜)。当决定一个触发器是否需要被重新建立的时候,同步触发器任务会检测数据库结构或者触发器配置的变化。可选择地,同步触发器任务可以被关闭,DBA可以自己生成和运行数据库触发器DDL脚本。
在变化的数据被数据库触发器插入到SymmetricDS的DATA系统表之后,这些数据被Router Job分批然后分配到某个SymmetricDS节点。路由数据指的是在SymmetricDS网络中选择一个数据应该发送的节点。默认情况下,一个节点的数据根据节点组标识被路由。可选地,数据和目标节点的特性也可以在路由过程中使用。一个数据的batch是一组数据的变化。这一组数据一起被传送和加载到目标节点,作为一个数据库事务提交。Batch信息记录在SymmetricDS的OUTGOING_BATCH系统表中。Batch是节点特定的,每个节点只有自己处理过的Batch的记录。DATA和OUTGOING_BATCH通过DATA_EVENT联系。Batch的发送状态记录在OUTGOING_BATCH中。在数据被发送到远程节点之后,batch的状态被改为“OK”。
1.2.3. Change Data Delivery
数据通过HTTP或者HTTPS发送到远程节点。数据可以通过这两种方式中的一种发送,发送的方式依赖于配置的节点的组之间的传输链路的类型。一个节点组可以被配置成推送变化到某个节点组中的其他节点,也可以配置成从某个节点组中的其他节点拉取数据。推送数据的操作是通过在数据源节点初始化一个Push Job实现。如果有多个等待被发送的Batch,推送节点将通过使用同一个HTTP HEAD请求来保持同一个到各个目标节点的连接。如果预留的请求被接受,数据源节点将从batch中提取所有的数据。数据以CSV格式被提取高内存缓冲区中,直到缓冲区大小达到配置的阀值,数据通过HTTP PUT被发送到目标节点。下一个Batch接着被提取和发送。这将一直重复直到给每一个channel发送的batch达到最大值,或者没有batch可以发送为止。因为所有的batch通过一个HTTP PUT请求发送,目标节点也将返回一个batch的状态的列表。
拉取请求在目标节点通过Pull Job初始化。一个拉取请求使用HTTP GET提交方式。在Push过程中执行的提取过程也会在Pull过程中执行。
在数据被提取,发送之后,数据加载到目标节点。与提取过程相似,随着数据不断被接收,数据加载器将以CSV格式缓存数据到内存缓冲区中,直到达到阀值。如果达到阀值,数据被刷写到一个文件中然后继续接收数据。一个batch中所有的数据都是本地可用的,一个数据库连接从连接池中取出,然后在源数据库中发生的事情会在目标数据库再次重演。
1.2.4. Data Channels
数据总是以在特定channel中记录的顺序被发送到远程节点。一个channel是用户定义的一组互相依赖的表。捕获的属于一个组的表的数据总是一起被同步。每一个触发器必须被分配一个channel id作为trigger定义的一部分。Channel id记录在SymmetricDS的SYM_DATA和SYM_OUTGOING_BATCH系统表中。如果一个batch加载失败,将不会再有数据发送到这个channel直到这个失败被处理。但是,其他channel上的数据将不受影响,继续同步。
如果远程节点离线,数据仍然在源数据库端被记录,直到远程节点重新上线。可选地,可以设置一个超时时间,超过此时间,下线的节点将从网络中删除。SymmetricDS捕获的数据所在的表的数据将在被发送后或者配置的保留时间到期后从SymmetricDS存放捕获的数据的系统表中被删除。将要发送到一个关闭的节点的没有被发送的数据变化也将被清除。
SymmetricDS在数据完整性错误的时候的默认的处理方式是尝试修复这些数据。如果一个插入statement执行,但是表中已经存在这样的一行数据,SymmetricDS将会回退插入操作然后尝试更新已经存在的行。同样地,如果一个在源数据库节点上成功执行的更新操作在目标节点上执行的时候,没有找到要更新的行,SymmetricDS将会回退更新操作,然后将这行数据插入到数据库中。如果在目标节点执行删除操作,但是没有找到要删除的行,这种情况将会被简单的记录。这些处理方式可以通过调整配置来进行冲突监测和处理。
SymmetricDS使用标准的web技术设计,所以它可以被扩展成不同数据库类型的多个客户端。它可以同步数据到与部署的数据库和网络基础设施支持的客户端一样多的客户端节点;也可以从这么多数量的客户端拉取数据以同步数据。当一个两层的数据库和网络基础设施不够用的时候,一个SymmetricDS网络可以被设计成使用N层以产生更高的扩展性。到这我们已经介绍了SymmetricDS是什么,如何完成用标准的方式在多个数据库间同步数据的工作。
1.3. Features
SymmetricDS拥有很多数据同步时你可能需要或者想要的特性。这些特性的大部分是根据SymmetricDS在生产环境中的使用反馈增加的。
1.3.1.Two-Way Table Synchronization
事实上,数据的同步通常只需要往一个方向同步。例如,一个分销商店发送它的商品交易信息到中央数据库,中央数据库发送存货信息和价格到商店。其他的数据可能需要在双向同步。例如,分销商店发送中央数据库一个存货清单文档,然后中央数据库更新文档中的数据,然后发送回商店。SymmetricDS支持表的双向同步,同时通过仅记录同步之外的数据变化避免了陷入更新循环。
1.3.2. Data Channels
SymmetricDS支持数据通道的概念。数据同步被定义在表(整个表或者表的一部分数据)的层面,每一个被管理的数据库表都被分配到一个channel上,channel会帮助控制数据流。一个channel是一个种类的数据,一个channel的数据可以不依赖于其他的channel中的数据被同步。例如,在一个分销例子中,一个促销事件可能更新很多的商品信息,但是用户可能正在等待存货清单文档的更新。如果按照顺序处理,商品更新将延迟存货清单的更新,尽管数据是没有联系的。通过将item表分配到item channel,inventory表分配到inventory channel,这两个表的数据变化被分开来处理,因此inventory可以不管大量的商品数据的情况下操作数据。
Channel 将在Section3.3“Channel”中被详细讨论。
1.3.3. Change Notification
在一条数据变化记录到数据库中之后,对此变化感兴趣的SymmetricDS节点被唤醒。Change Notification被配置为既可以执行数据push也可以执行数据pull。当几个节点将它们的数据变化对准到一个中央节点的时候,用push的方式代替等待中央节点从每个源数据库pull的方式是高效的。如果网络配置了防火墙来保护一个节点,pull配置可能使该节点可以接收到数据变化,而push方式将会被阻塞。Change Notification的频率是可配置的,默认是一分钟一次。
1.3.4 HTTP(S) Transport
默认情况下,SymmetricDS以REST风格使用基于web的HTTP或者HTTPS请求的方式。这是一种轻量级并且易管理的方式。提供了一系列的filter来强制认证和限制同时同步的数据流的数量。ITransportManager接口允许实现其他的数据传输方式。
1.3.5. Data Filtering and Rerouting
使用SymmetricDS,数据可以再记录,提取和加载的时候被过滤。
1. 数据路由是通过往SymmetricDS系统表ROUTER中插入一个给定类型的router来完成的。Router负责确定捕获到的变化应该被发往的目的节点。自定义的router可以通过实现一个IDataRouter接口来提供。
2. 除了同步,随着同步数据加载到目标数据库,SymmetricDS也可以完成很复杂的数据转换。数据转换可以被用来合并源数据,产生多个源数据的副本到多个目标数据库表,在目标数据库设置默认值,等等。转换的类型可以被扩展,可以创建自定义的转换。
3. 因为数据变化被加载到目标数据库中,数据可以被一个简单的shell加载过滤器过滤,也可以被一个IDatabaseWriterFilter的实现类过滤。你可以改变一个列中的数据,然后路由改变后的数据到任何地方,触发器初始化负载或者其他可能的情况。一个可能的用法是可以路由信用卡数据到一个安全的数据库然后在中央存放销售信息的数据库中空出来。过滤器也可以防止数据全部到达目标节点,然后在目标节点加载数据时使用数据的默认值,这样非常高效。
1.3.6. Transaction Awareness
很多的数据库提供全局唯一的事务标识,跟作为一个事务一起提交的多个行相关联。SymmetricDS随同变化的数据一起,也存储事务的标识,因此SymmetricDS可以精确地回滚一个事务。这意味着,目标数据库维护与源数据库中相同的事务完整性。支持事务标识符的数据库在附录中有记录。
1.3.7. Remote Management
管理功能通过JMX暴露出来,可以通过Java JConsole工具或者通过一个应用程序服务器访问。功能包括打开注册,重新加载数据,清除旧的数据和查看batch信息。很多的配置信息和运行时属性也可以被查看。
SymmetricDS也提供了发送SQL事件的功能,跟用来发送数据的同步机制一样。数据payload可以使任意的SQL statement。事件的处理和响应也跟其他类型的事件一样。
1.3.8. File Synchronization
不少的SymmetricDS用户已经发现他们不仅需要同步数据库表到远端,他们也有一系列的文件应该被同步。从version 3.5开始,SymmetricDS开始支持文件同步了。
请查看Section3.5 “File Trigger / File Synchronization”获取更多的信息。
1.4 Why Database Triggers?
在关系型数据库中,有几种方法可以捕获到变化的数据,以用来复制、同步和整合。
1. Lazy data capture从源数据库系统中使用条件(比如一个时间戳列)SQL语句查询变化的数据。
2. Trigger-based data capture 安装一个数据库触发器来捕获变化的数据。
3. Log-based data capture从数据库的恢复日志中读取数据的变化。
上边的山中方式都有优势,也都有劣势,都在SymmetricDS的开发计划中。目前,SymmetricDS支持基于触发器的数据捕获和不公平的懒惰数据捕获。首先实现这两种技术有很多的原因,最重要的是SymmetricDS要解决的大多数的用例都能使用基于触发器的方式解决,在某种程度上,条件复制的方式(第一种方式)使更多的使用企业标准技术的数据库平台被支持。这个事实使SymmetricDS的开发者宝贵的时间和经理被放到设计一个易于安装、配置和管理的产品,而不是花费时间在逆向数据库日志文件上。
基于触发器的数据捕获方式引入了一个可以衡量数据库操作开销。开销会随着处理器的能力和配置给数据库平台的资源还有应用使用数据库的方式变化。随着不断改进的硬件和数据库技术,基于触发器的数据捕获对需要高数据吞吐量或者需要扩展的应用来说将变得更加灵活。
基于触发器的数据捕获比基于日志的解决方案更容易实现和受支持。它使用众所周知的数据库概念,对于软件,数据库开发者和数据库管理员来说更易理解。它通常被应用开发团队或者数据库管理员安装,配置和管理,本身不需要部署到数据库服务器上。


















