
#多模态视觉-语言大模型的架构演进
本文回顾了多模态LLM (视觉-语言模型) 近一年来的模型架构演进,对其中有代表性的工作进行了精炼总结,截止2024.04,持续更新ing... 欢迎大家多多点赞、收藏、讨论
首先,推荐一篇启发我很多的综述和对应的项目地址(本文的封面图也来自该综述)
A Survey on Multimodal Large Language Models
arxiv.org/abs/2306.13549
Awesome-Multimodal-Large-Language-Models
github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
这篇综述一张图总结了多模态LLM的典型架构:

BLIP
【2022.01发布】https://arxiv.org/abs/2201.12086
统一视觉-语言理解和生成,使用captioner+filter高效利用互联网有噪数据
模型架构:
- Image/text encoder: ITC loss对齐视觉和语言表征,基于ALBEF提出的momentum distillation
- Image-grounded text encoder: ITM loss建模视觉-语言交互,区分positive/negative图文对,使用hard negative mining挖掘更高相似度的负例优化模型
- Image-grounded text decoder: LM loss实现基于图像的文本解码,将双向self-attention替换为causal self-attention
BLIP的bootstrapping训练过程:
BLIP-2
【2023.01发布】https://arxiv.org/abs/2301.12597
使用相对轻量的Q-Former连接视觉-语言模态,通过两阶段训练:第1阶段基于冻住的视觉编码器,第2阶段基于冻住的LLM
第1阶段:同样优化ITC/ITM/LM loss,使用不同的self-attention mask,query和text端共享self-attention参数,使得可学习的query embedding提取与text语义最相关的视觉表征;使用BERT-base初始化,32个768维的query作为信息瓶颈
- ITC:计算每个query与text的相似度,取最大的;使用batch内negatives,不再使用momentum queue
- ITM:对每个query与text的分类logits取平均,使用hard negatives mining挖掘难负例
- LM:text token和frozen image encoder不能直接交互,要求query能提取有益的视觉特征
第2阶段:可基于decoder-only/encoder-decoder LLM进行适配,FC层对齐维度
LLaVA
【2023.04发布】https://arxiv.org/abs/2304.08485
- 使用仅文本模态的GPT-4生成视觉-语言指令遵循数据,用于微调多模态LLM
- 使用图片的dense captions和bounding boxes作为prompt,可以生成对话、细节描述、复杂推理等指令
- CLIP ViT-L/14 + Vicuna,使用简单的线性层进行映射
- 更复杂的:Flamingo中gated cross-attention,BLIP-2中的Q-former
- LLaVA模型的两阶段训练
- stage1. 预训练特征对齐:冻住vision encoder和LLM,只训练projection,学习一个兼容的visual tokenizer
- stage2. 端到端微调:冻住vision encoder,在单轮/多轮对话数据上微调projection和LLM
MiniGPT-4
【2023.04发布】https://arxiv.org/abs/2304.10592
stage1. 预训练:使用image-text pair微调linear projection layer,vision encoder和LLM保持冻住
stage2. 指令微调:指令格式为:###Human:###Assistant:
InstructBLIP
【2023.05发布】https://arxiv.org/abs/2305.06500
stage1. 预训练:BLIP-2(使用image-text pairs进行两阶段训练)
stage2. 指令微调:只微调instruction-aware Q-former,冻住vision encoder和LLM
支持FlanT5(encoder-decoder)和Vicuna(decoder-only)
Qwen-VL
【2023.08发布】https://arxiv.org/abs/2308.12966
支持中英双语、多图像输入
Qwen-7B + OpenCLIP ViT-bigG,输入图像直接resize到视觉编码器输入
位置感知的VL adapter:使用基于Q-former的单层的cross-attention,将图像特征维度压缩到256,在query-key pairs中引入2D绝对位置编码增强位置信息
图像输入:256-dim图像特征
bounding box输入输出:(X_topleft, Y_topleft), (X_bottomright, Y_bottomright),…标记box所指内容
三阶段训练:
stage1. 预训练:基于大规模、弱标注、网络爬取的图像-文本对,输入分辨率224x224,冻住LLM,训练ViT和Q-former,主要目的是模态对齐
stage2. 多任务预训练:基于7种下游视觉-语言理解任务的高质量、细粒度标注数据训练,输入分辨率448x448,图像/文本数据交错,训练整个模型
stage3. 指令微调:提升指令遵循和多轮对话能力,冻住ViT,训练LLM和Q-former
Qwen-VL-Plus和Qwen-VL-Max提升了视觉推理能力、图像细节的识别/提取/分析能力(尤其是文本导向的任务)、支持高分辨率和极端纵横比的输入图像;在部分中文场景超过了GPT-4V和Gemini
InternLM-XComposer
【2023.09发布】https://arxiv.org/abs/2309.15112
交错图文构成:自动在输出文本中插入合适的图片
EVA-CLIP ViT + InternLM-7B + Q-former (将图像特征压缩到64个embedding)
两阶段训练:
stage1. 预训练:冻住ViT,训练LLM和Q-former
stage2. 监督微调:包括多任务训练和指令微调,冻住ViT和LLM,训练Q-former,对LLM进行LoRA微调,增强指令遵循和图文混排能力
Fuyu-8B
【2023.10发布】https://huggingface.co/adept/fuyu-8b
模型架构和训练过程简单,易于scaling;支持任意图像分辨率;推理速度快
decoder-only的transformer,没有专门的图像编码器;image patch直接线性映射到transformer第一层
LLaVA-1.5
【2023.10发布】https://arxiv.org/abs/2310.03744
仍使用MLP作为模态连接,突出了训练的数据高效性
CogVLM
【2023.11发布】https://arxiv.org/abs/2311.03079
深度视觉-语言模态融合,而不影响LLM原有的语言能力:冻住LLM和ViT,在attention和FFN层训练一份视觉专家模块
CogAgent
【2023.12发布】https://arxiv.org/abs/2312.08914
针对GUI场景的多模态理解和导引,使用高分辨率-低分辨率双编码器,支持1120x1120的屏幕输入
高分辨率分支使用更轻量的ViT,基于cross-attention将高分辨率图像特征与LLM每层进行融合
VILA
【2023.12发布】https://arxiv.org/abs/2312.07533
探索了视觉-语言模型训练的设计选择:
- 预训练阶段冻住LLM虽然能取得较好的zero-shot性能,但上下文学习能力依赖对LLM的微调
- 图文交错的预训练数据是有益的,只用图文数据对效果不够好
- 将纯文本的指令微调数据加入SFT阶段有助于缓解纯文本任务的能力退化,同时也能够增强视觉-语言任务的准确性
LLaVA-Next
【2024.01发布】https://llava-vl.github.io/blog/2024-01-30-llava-next/
相对于LLaVA-1.5,保持了极简的设计和数据高效性:
- 提高了输入图像的分辨率 (4x),支持3种纵横比:672x672, 336x1344, 1344x336
- 更好的视觉推理和OCR能力:更好的指令微调数据配比
- 更好的多场景视觉对话:更好的世界知识和逻辑推理
- 更高效的部署和推理:SGLang
动态高分辨率:视觉编码器支持336x336的图像输入,对于672x672的图像,按照{2,2}的grid split成4个图像patch过encoder,downsample到336x336也过encoder,特征拼接作为visual tokens输入到LLM中
收集高质量用户数据,包括真实场景中反映用户更广泛意图的指令数据,利用GPT-4V进行数据构造
多模态文档/图表数据,增强文档OCR和图表理解能力
InternLM-XComposer2
【2024.01发布】https://arxiv.org/abs/2401.16420
提出了新的模态对齐方法partial LoRA:只在image token上添加LoRA参数,保证预训练语言知识的完整性,这样一个更轻量的视觉编码器同样有效
OpenAI CLIP ViT-L/14 + InternLM2-7B + partial LoRA (rank=256)
两阶段训练:
stage1. 预训练:冻住LLM,微调ViT和partial LoRA模块,包括通用语义对齐(理解图像基本内容)、世界知识对齐(进行复杂的知识推理)、视觉能力增强(OCR、物体定位、图表理解)
stage2. 监督微调:微调整个模型,包括多任务训练、自由形式图文排布
InternLM-XComposer2-4KHD
2024.04发布了4KHD版本:https://arxiv.org/abs/2404.06512
支持动态分辨率(336px → 4K (3840x1600)):改进了patch division范式,保持训练图像原有的纵横比,自动变化patch数目,基于336x336的ViT配置layout
动态图像划分:将输入图像resize and pad到336的整数倍宽高
结合图像的global和local视角:global视角由输入直接resize到336x336,使用sep token分隔两种视角的token
图像2D结构的换行符:可学习的\n token分隔图像token行
Mini-Gemini
【2024.03发布】https://arxiv.org/abs/2403.18814
使用双视觉编码器提取低分辨率embedding作为query,高分辨率特征区域作为key/value,两者之间做cross-attention,输出挖掘的tokens作为prompt前缀,输入到LLM做推理,外接图像解码器生成图像(SDXL)
#DepictQA
图像质量感知多模态语言模型
基于多模态语言模型 (MLLM) 的图像质量感知方法,借助MLLM,对图像质量进行类似于人类的、基于语言的描述。
项目主页:https://depictqa.github.io
DepictQA-v1 (ECCV2024) :https://arxiv.org/abs/2312.08962
DepictQA-v2 (arXiv, preprint) :https://arxiv.org/abs/2405.18842
代码 (包括训练推理与数据集构造代码):https://github.com/XPixelGroup/DepictQA
数据集:https://huggingface.co/datasets/zhiyuanyou/DataDepictQA
为什么会做这个项目?
图像质量感知是一个宏大而复杂的课题。比如:
- 图像是细节越多越好吗?
并不是。很多人都会喜欢湛蓝纯净的天空。因此,在飘了一些淡淡的云彩的天空中加入blur,使得天空的颜色更加均匀,人看起来反而更好看。
- 失真一定会带来低质量吗?
并不是。如下图所示,右图是在左图的基础上添加噪声得到的。但是在这种情况下,噪声可以使手部皮肤看起来更加真实,而左图则显得过度平坦化。在这种情况下,噪声使图像更加真实。

图片来源:https://medium.com/photo-dojo/dont-fear-the-grain-263a37a64b87
很容易发现,图像质量感知与图像的局部内容是强相关的,甚至是与个人的喜好强相关的。
那么,如何刻画如此复杂的质量感知呢?
现有的图像质量评价 (IQA) 方法使用score来描述图像质量,可以直接用于对比不同模型的性能,被广泛地作为metric或者loss使用,促进了图像生成、修复等领域的发展。但是,score这种描述形式是图像质量感知的一个综合的方面,其表达能力的上限是不足的,无法刻画复杂的局部性和内容相关性。
在大语言模型 (LLM) 和多模态语言模型 (MLLM) 出现后,我们希望语言成为描述图像质量感知这个复杂问题的工具,这也是这一系列工作的初衷。
TL;DR
- DepictQA是基于多模态语言模型 (MLLM) 的图像质量感知方法。我们希望借助MLLM,对图像质量进行类似于人类的、基于语言的描述。
- DepictQA-v1。为了验证MLLM感知图像质量的可行性,我们 (1) 构造了full-reference下的任务框架,(2) 构建了一个包括 大量的、简短的、模版化的构造数据 + 少部分的、详细的、人工标注的数据 组成的数据集,(3) 训练了一个MLLM,验证了MLLM感知图像质量的可行性。
- DepictQA-v2。在可行性验证之后,我们希望拓展模型的适用范围,进行了 (1) 任务框架的拓展 (任务类型从3种到8种),(2) 数据集的scaling up (detail数据从5K到56K),实现了 (3) 在自然图像上具有一定的泛化性。

图1:DepictQA-v1作者与机构。

图2:DepictQA-v2作者与机构。
Motivation: Score-based质量感知方法的局限性
现有的图像质量感知方法主要是score-based方法。这些方法输出一个score来描述图像质量,可以用于对比不同模型的性能,被广泛地作为metric或者loss使用,促进了图像生成、修复等领域的发展。
虽然取得了如此巨大的成功,我们认为score的描述形式限制了更深层次的质量感知。
- 首先,图像质量包括了很多的因素,这些因素无法通过一个简单的score有效表达,例如图3中的噪声、色彩失真和伪影等。
- 其次,score无法模拟人类的感知过程。例如,在图3(b)中,人类一般首先识别图像的失真(即图像A中的噪声、图像B中的色彩失真和伪影),然后权衡这些失真对内容表达的影响(图像B中的色彩失真和伪影比图像A中的噪声更严重),最后得出结论 (图像A比图像B更好) 。但是,简单地对比score来判断好坏无法反应出人类复杂的感知过程。
最近,以ChatGPT为代表的大语言模型 (LLM) 将深度学习带入了大模型时代,随之出现的多模态大语言模型 (MLLM) 可以使用语言对图像的内容进行详细的描述。因此,我们希望探究基于MLLM、使用语言对于图像质量进行描述的方法。

图3:DepictQA-v1与score-based方法的比较。Score-based方法仅输出score,缺乏推理过程。DepictQA-v1识别图像的失真,权衡不同失真对纹理的影响,得出与人类判断更一致的结果。

图4:DepictQA-v2的定性结果。DepictQA-v2能够准确识别失真类型,分析失真类型对于图像内容的影响,得出质量评估或者质量对比的结论。
DepictQA-v1
任务定义
我们建立了一个包括三个任务的任务框架。
- 质量描述。模型应该能够感知图像失真。如图5(a),给出参考图像和一张失真图像,模型需要描述失真图像中的失真和纹理损伤,并判断失真图像的整体质量。
- 质量对比。模型应该能直接对比两张图像的好坏。如图5(b),给出参考图像和两张不同的失真图像,模型需要确定哪一张失真图像的质量更好。
- 对比归因。模型应该能对两张图像的好坏进行判断并归因。如图5(c),模型需要描述两张失真图像的失真和纹理损伤,并推理权衡利弊,对比图像质量的好坏。该任务是质量描述和质量对比的综合。

图5:DepictQA-v1任务定义与数据收集。
数据收集
- 人工标注选项 + GPT-4语言化
在DepictQA-v1收集数据时,GPT-4V等强多模态模型还没有出现。我们设计了人工标注选项 + GPT-4语言化的数据策略。如图5所示,我们设计了由选择题构成的问卷,标注员标注问卷后,GPT-4将问卷的标注结果组合成语言,由此构造图像文本对。
大量的、简短的、模板化回答 + 少部分的、详细的回答
人工标注数据是详细的,但是费时费力获取难度大。因此,我们将已有的包含score的数据集转化为文本,构造大量的、简短的、模版化的数据。比如,图像A的score比图像B高,可以转化为"Image A maintains a better quality than Image B"。将模版化数据 + 详细数据混合训练,对于对比精度和归因准确性都有一定提升。
模型训练
如图6所示,我们采用了LLaVA框架,包括image encoder、image projector、LLM三部分。
- 区分多张图像
LLaVA的输入是单张图像,而我们涉及到多张图像。如何让模型区别多张图像是十分重要的。我们测试了4种区分多种图像的方法,并根据结果选择了textual hint + tag hint的方法。

图6:DepictQA-v1模型架构。
- 加入high-level数据作为正则化
质量相关的描述语言是单一的,包括的独立词汇量偏少。仅仅用这些数据训练,模型存在过拟合、说套话、重复说话的问题。因此,我们在训练过程中加入了LAMM引入的COCO详细描述数据作为正则化。
实验结果
- 在双图对比、多图对比 (双图对比的拓展) 上,超越了经典的score-based方法。

- 在质量描述和对比归因上,通用MLLMs不具有质量感知能力,而DepictQA-v1体现出了一定的质量感知能力。

DepictQA-v2任务定义
DepictQA-v1主要关注了full-reference设置下的3种任务。在DepictQA-v2中,我们对任务定义进行了拓展,从3种任务扩展到8种任务,提出了一个多任务的框架。如图7所示,拓展后的任务框架包括了单图评估和双图对比两大类任务,每类任务都包括了brief和detail两个子任务,支持full-reference和non-reference设置。

图7:DepictQA-v2任务定义。
数据收集
- 更全面的自然图像。我们选择了KADIS-700K作为高质量图像的来源,一共包括了140K的高质量图像。
- 更全面的失真类型。我们构建了一个全面的失真库,包括了35种失真类型,每种类型包括了5个等级。
- 更大尺度的数据量。我们将detail数据从DepictQA-v1的5K扩增到了56K,相应地,brief的数据也扩增到了440K。
- 更合理的数据生成。在构造DepictQA-v2的数据集时,GPT-4V等强多模态模型已经出现。Co-Instruct直接采用了GPT-4V构造数据。虽然GPT-4V具有强大的内容识别、逻辑推理能力,但是其失真识别、质量对比能力都是不足的。因此,如图8所示,我们提出ground-truth-informed生成方法,将失真识别和质量对比的结果直接加入GPT-4V的prompt中,提升了生成数据的质量。

图8:DepictQA-v2数据收集。
模型训练
我们采用了DepictQA-v1的模型架构。
- 图像分辨率的适应。由于图像的分辨率以及比例也是质量的重要部分,我们提出对于clip image encoder的位置编码进行差值,而保留图像的原始分辨率和比例。
- 置信度的计算。MLLM的response缺乏一个良好的置信度。我们提取了response中的key tokens,计算了key tokens的预测概率作为置信度。
实验结果
- 在失真识别上,超越了通用MLLMs、以及已有的MLLM-based质量感知模型。

- 在直接对比上,超越了score-based方法、通用MLLMs、以及已有的MLLM-based质量感知模型。

- 在评估归因和对比归因上,超越了通用MLLMs、以及已有的MLLM-based质量感知模型。

- 在web下载的真实图像上也体现出较好的泛化性。

图9:DepictQA-v2在真实图像上的质量感知结果。
- 模型预测的置信度与模型性能的一致程度非常高。

图10:置信度与模型性能的一致程度非常高。
不足与未来的工作
在这两篇工作中,我们展示了使用MLLMs描述图像质量的可能性。但是,MLLM-based图像质量感知模型的落地应用仍有很长的路要走。
- 数据的数量和覆盖范围不足,限制了模型的泛化性能。尽管DepictQA-v2已经进行了数据集的scaling up,但是对于非自然图像,其泛化性能依然不足。
- MLLM-based方法的应用不像score-based方法那么自然。Score可以被直接对比选择更优的模型,但语言不能被直接对比。Score也可以被用作loss优化模型,但语言目前还不具有这种特性。因此,质量感知的语言能否被输入生成模型或者修复模型用于质量提升,还需要进一步的探索。
#InternVL2
最好的开源多模态基础模型
最近忙完了WAIC,有空写个帖子,宣传下InternVL2,最好的开源多模态基础模型,以及介绍下背后的几篇论文:

第一篇:
OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
世界上最大的图文交错数据集,支持我们模型的训练
第二篇:
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
首创多模态信息压缩学习,首次支持互联网尺度图文交错数据端到端预训练算法
第三篇:
VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
https://arxiv.org/abs/2406.08394
VisionLLM v2通用任务解码器(强化模型专项能力):首创向量链接技术,连接多模态大模型和各领域专用模型,通专结合,拓展多模态大模型的基础能力
#Multimodal-Unlearnable-Examples
多模态不可学习样本:保护数据免受多模态对比学习的威胁
在本文中,作者探索了多模态数据保护,特别关注图像-文本对,并生成了多模态不可学习样本来防止被多模态对比学习利用。
导读
多模态对比学习(如CLIP)通过从互联网上抓取的数百万个图像-字幕对中学习,在零样本分类方面取得了显著进展。然而,这种依赖带来了隐私风险,因为黑客可能会未经授权地利用图像-文本数据进行模型训练,其中可能包括个人和隐私敏感信息。最近的工作提出通过向训练图像添加难以察觉的扰动来生成不可学习样本(Unlearnable Examples),可以建立带有保护的捷径。然而,这些方法是为单模态分类任务设计的,在多模态对比学习中仍未得到充分探索。本文首通过评估现有方法在图像-标题对上的性能来探索这一背景,由于在该场景中缺乏标签,之前的无法有效地推广到多模态数据,并且在建立捷径方面的效果有限。在本文中提出了多步误差最小化(MEM),这是一种用于生成多模态不可学习样本的新颖优化过程。它扩展了误差最小化(EM)框架,以优化图像噪声和额外的文本触发器,从而扩大了优化空间,并有效地误导模型学习噪声特征和文本触发器之间的捷径。具体来说,采用投影梯度下降来解决噪声最小化问题,并使用HotFlip方法来近似梯度和替换单词,以找到最佳的文本触发器。大量实验证明了方法的有效性,保护后的检索结果几乎是随机猜测的一半,并且它在不同模型之间具有高度的可转移性。本篇工作的论文和代码均已开源。

【论文链接】https://arxiv.org/abs/2407.16307
【代码链接】https://github.com/thinwayliu/Multimodal-Unlearnable-Examples
研究背景
近年来,随着多模态学习的兴起,研究者们对结合文本、图像和音频等多种数据类型的模型产生了浓厚的兴趣。其中,多模态对比学习成为了这一领域的重要方法,如CLIP和ALIGN等模型利用对比损失训练,以增强图像和文本的相关性,进而减少人工标注的需求,并展示了在图像分类、生成等任务中的潜力。然而,这些模型的训练依赖于大量的多模态数据,这些数据常常来自公开的数据集,如CC12M、YFCC100M和LAION5B,但这些数据集可能仍然不足,且可能包含大量敏感的个人信息,引发了对隐私泄露的担忧。
我们考虑了一个专注于生成多模态不可学习样本以应对与多模态对比学习相关的隐私风险的场景。在这种场景下,我们专注于图像-文本对作为代表性的多模态数据集。假设用户经常在社交媒体平台(如Facebook)上分享带有文本的个人照片,包括一些私人身份信息,如面孔、姓名、电话号码和地址。目前,黑客试图从互联网上收集大量此类图像-文本对,并利用多模态对比学习技术训练或微调大模型,如图1的左半部分所示。这些模型无意中捕获了用户的私人信息和面部特征,导致潜在的隐私泄露。保护者旨在通过对多模态数据进行不可学习的方法来防止这些敏感数据被未经授权利用。这些方法使在这种多模态不可学习样本上训练的模型无法访问用户的隐私特征,同时不妨碍用户在发布图像和文本后的社交互动,如图1的右半部分所示。

图 1:Facebook上的帖子无意中会泄露了个人信息(如图左),但利用多模态不可学习样本可以保护数据可以防止未经授权的模型访问私人特征(如图右)。
动机
最近的研究致力于通过不可学习样本(Unlearnable Examples)来防止图像分类中的数据未经授权使用。这些方法通过对数据施加细微扰动来阻碍模型学习图像特征,也被称为可用性攻击(availability attacks)或无差别的中毒攻击(indiscriminate poisoning attacks)。它主要分为无代理模型攻击和基于代理模型的攻击,其中无代理模型攻击通过在像素级别生成噪声,而基于代理模型的攻击则通过代理模型生成特征级别的噪声。然而,所有用于分类的无代理模型方法在多模态场景下都无法生成图像噪声,因为这些方法旨在为与某个特定类别相关的图像找到一系列特定的噪声模式,而图像-文本对数据中没有标签。因此,只有基于代理模型的方法可以应用,我们扩展了两种典型的方法来生成不可学习的多模态示例(EM和UAP)。
The Error-minimizing Noise(EM)方法:

Untargeted Adversarial Perturbation.(UAP)方法:

尽管EM和UAP可以应用于图像-字幕对,但它们未能实现高效的保护,尤其是UAP。我们探讨了这些方法从图像分类到多模态对比学习有效性下降的原因。在图像分类中,EM和UAP优化具有相同标签的图像,使其在特征空间中收敛,导致模型容易捕获这些附加噪声并学习与标签的相关性,如图2(a)所示。但在多模态对比学习中,为了有效地应用EM和UAP方法,优化的图像噪声的方向必须与文本的特征相关,导致图像特征变得要么接近要么远离这些特征。然而,不同对的文本特征可能在图像–文本数据集中广泛分散。如图2(b)和(c)所示,与分类不同,模型更难捕捉字幕和EM和UAP生成的噪声之间的相关性。在图2(c)中,UAP的学习决策空间更加复杂,因此其保护效果不佳。

图 2:不同方法在传统分类和多模态对比学习中的比较。𝐼表示图像,𝑇是配对的标题。蓝色区域是在不可学习样本上训练的模型的预期决策边界。
方法

图 3:多步误差最小化方法(MEM)的框架
由于图像-文本对的分散,基于代理模型的方法仍然无法实现有效的保护。一个直观的增强策略是同时优化图像和文本,以获得更大的优化空间,促进它们在特征空间中不同对的收敛。因此,图像和文本集的优化特征表示呈现出相似的分布,便于模型学习它们的捷径,如图2(d)所示。为此,我们以EM方法为基本框架,并提出在字幕前添加额外的短文本触发器来最小化对比损失,遵循对文本任务的对抗攻击的设置。我们的方法可以被概念化为一个三层迭代优化问题,类似于EM的多步过程。具体来说,我们依次优化噪声δ和文本触发器t,以减少优化图像I + δ和优化文本T ⊕ t之间的对比损失,其中⊕表示可以在不同位置插入干净文本T的触发器。为了简单起见,我们在本文中选择在文本的开头添加文本触发器。因此,我们的多步误差最小化(MEM)方法可以表述为:

通过参考EM中的方法依次迭代优化上述问题。使用投影梯度下降(PGD)来解决式中的噪声最小化问题。值得注意的是,为了减轻噪声对干净字幕的过拟合,我们通过在批处理中打乱干净字幕并添加正确匹配的文本触发器来增强它们。因此,当面对语义错误的字幕时,这种生成的噪声可以更多地关注文本触发器而不是部分字幕。因此,我们可以根据以下迭代公式获得最优的δ:

对于文本触发器最小化问题,首先通过在所有输入的前面重复单词“the”或“a”来初始化触发序列。此外,基于HotFlip优化文本触发器,通过梯度近似替换标记的效果。通过更新每个触发标记的嵌入,以最小化当前标记嵌入周围的CLIP损失的一阶泰勒近似:

最后,我们可以在候选标记的集合中使用束搜索来搜索每个最优文本触发器。我们考虑来自上式的前k个候选者,并在触发器的每个位置从前到后搜索,并使用当前批处理上的损失对每个束进行评分。我们遵循Wallace等人的方法,并使用小的束大小进行高效计算。在图3中,我们可以看到使用我们的MEM生成多模态不可学习样本的框架。
实验效果
有效保护性

表 1:在不同数据集上几种方法生成的不可学习样本的有效性比较。
表1展示了它们在不同数据集上的检索结果。显然,UAP几乎无法为多模态数据提供任何保护,而EM则表现出一定程度的保护。然而,我们的MEM始终为多模态数据提供强大的保护,将检索性能降低到几乎是随机猜测的一半。特别是MEM - 5,由于其文本触发器更长,与MEM - 3相比,在降低黑客模型性能方面取得了更大的效果。图4展示了由不同方法生成的不可学习样本训练的训练损失下降曲线和在干净测试集上的检索Medr。从(a)中可以观察到,尽管EM使损失比正常训练下降得更快,但我们的方法MEM-3和MEM-5在第一个epoch时损失更小,这表明模型可以快速学习到捷径。从(b)中我们发现,所有模型的Medr都比随机猜测时降低,但在不可学习样本上训练的模型停止学习得最快,达到了最差的检索结果,并且随着epoch的增加不会进一步学习得更好。以上观察结果与表1中的结果一致。

图 4:训练损失和测试指标Medr的曲线变化记
跨模型迁移性

表 2:在不同模型架构上,基于ResNet50模型的MEM-3方法生成的不可学习样本的可转移性。
我们假设数据保护是一个完全黑盒的设置,其中保护者不知道黑客模型的架构。因此,我们评估了在ResNet50代理模型上生成的MEM在不同黑客模型上的性能,包括ResNet101和ViT。结果如表2所示。我们发现这些样本可以成功地在不同模型之间转移,并能降低CLIP模型的性能
可视化分析

图 5:注意力图可视化:比较四种模型在干净数据和不同方法的不可学习样本上的情况。
图5展示了在干净数据和不同方法生成的不可学习样本上训练的模型的注意力热图。对于图像,我们使用Grad-CAM来可视化模型的注意力,而对于文本,我们使用Integrated Gradients来可视化注意力。颜色越浅表示模型的注意力越高。值得注意的是,对于图5(1),(2)和(3)中的模型都关注中心区域,这与字幕相关。然而,图5(4)中由MEM - 3生成的样本训练的模型由于只学习了噪声特征,无法准确识别干净图像。同样在文本中,前三者中的模型都关注关键词“glass”,而后者中的模型将注意力放在前三个单词上,这可能是因为MEM-3总是优化噪声和前三个文本触发器来创建捷径。这些可视化结果表明,EM和UAP在保护多模态数据方面效果不佳,而MEM具有明显的有效性。

图 6:干净样本和MEM-3优化的不可学习样本在干净模型和中毒模型下的t-SNE可视化。
我们在图6中可视化了正常模型下干净样本的特征分布以及MEM3在中毒模型上优化的不可学习样本的特征分布。我们用三角形表示图像特征,用圆圈表示文本特征,相同颜色表示数据集中五个相同但经过变换的图像及其对应的不同描述。从(a)中我们可以观察到,在干净模型下,相同的图像和文本在内部聚集在一起,并且相应的图像-文本对彼此接近。然而,在(b)中,相同的图像和文本出现了分歧,只有成对的图像和文本彼此接近。这表明我们的方法有效地促进了模型学习噪声和文本触发器之间的捷径。
案例探讨: 人脸隐私保护
我们进行了一个案例研究,将我们的MEM噪声应用于一个现实世界的场景:保护社交媒体平台上的个人人脸图像和相关信息,如姓名。我们使用PubFig数据库进行了实验,这是一个大型的现实世界人脸数据集,包含从互联网上收集的200个个体的58,797张图像。对于检索评估,我们随机选择每个名人的一张照片作为测试集,并使用所有剩余的图像进行训练。为了进行真实的微调,我们更改了他们的名字,并提供了一组与该名字相关的文本模板用于字幕生成。随后,我们使用MEM生成不可学习的样本,并使用不同的黑客模型进行评估。结果如表3所示。MEM可以防止这些微调模型学习人脸和姓名特征之间的相关性,从而阻碍在测试集上的准确人员检索。

表 3:在不同预训练模型上,ResNet50微调生成的不可学习样本的保护效果。
结语
在本文中,我们探索了多模态数据保护,特别关注图像-文本对,我们生成了多模态不可学习样本来防止被多模态对比学习利用。我们将先前的分类方法扩展到这个背景下,揭示了由于模态增加和数据分散而存在的局限性。鉴于这些发现,我们引入了一种名为多步误差最小化(MEM)的新颖生成方法,它基于EM框架。MEM有效地在噪声和文本触发器之间建立了捷径,并展示了在不同黑客模型之间的可转移性。此外,我们使用各种可视化工具验证了我们方法的有效性。我们的工作开辟了一个新的方向,预计将适用于其他模态对,如音频-文本和音频-图像对。
#Janus
DeepSeek新作Janus:解耦视觉编码,引领多模态理解与生成统一新范式
- 论文: https://arxiv.org/pdf/2410.13848
- 项目主页:https://github.com/deepseek-ai/Janus
- 模型下载:https://huggingface.co/deepseek-ai/Janus-1.3B
- 在线 Demo:https://huggingface.co/spaces/deepseek-ai/Janus-1.3B
1.
我们提出了 Janus,一种基于自回归的多模态理解与生成统一模型。Janus 的核心思想是对理解和生成任务的视觉编码进行解耦,在提升了模型的灵活性的同时,有效缓解了使用单一视觉编码导致的冲突和性能瓶颈。实验表明,Janus 超越了此前的统一模型的效果,并取得了和纯理解 / 纯生成模型比肩或更好的性能。我们通过详细严格的对比实验证实了解耦的好处,并分析了理解生成统一训练相较于分开训练带来的影响。
在罗马神话中,Janus (雅努斯) 是象征着矛盾和过渡的双面守护神。我们将模型命名为 Janus,形象地表示我们的模型可以像 Janus 一样,用不同的眼睛看向视觉数据,分别编码特征,然后用同一个身体 (Transformer) 去处理这些输入信号。此外,得益于解耦的设计,Janus 极易扩展,研究者们可以将理解和生成领域最新的编码技术直接应用在 Janus 之上。我们希望我们提出的框架能和雅努斯一样,象征着多模态统一模型的旧范式到新范式的过渡。

2. 背景和动机
2.1 相关工作
多模态理解大模型和视觉生成模型都取得了飞速的发展。最近,也有一些工作尝试将这两者进行统一,构造更强大的通用模型。将理解和生成进行统一具有重大意义。从模型部署角度来说,统一之后能避免分开部署多个模型,减少了模型的冗余性。且社区对 LLM 的推理做了很细致的优化,如果能统一到一个 LLM 中,会很方便;从结果来说,理解和生成统一可以提高视觉生成的指令跟随能力,甚至解锁一些涌现能力,例如多语言视觉生成,或随着 LLM 的 scale up 获得更强的能力。
有一些先驱工作 (EMU, Seed) 尝试将预训练好的 Diffusion Model 接在多模态理解模型后面。这些方法中,多模态理解模型输出 Diffusion Model 的条件,然后依赖 Diffusion Model 做图像生成。但是,这样的设计中,LLM 本身并不具备直接出图的能力,出图的性能也往往被外接的 Diffusion Model 所限制。后来的一些工作 (Chameleon, Vila-U, Show-O 等) 则提出直接让 LLM 处理多模态理解和生成任务,真正做到了统一。但是,这些方法通常将视觉编码器也进行了合并,即:用一个视觉编码器同时负责理解与生成任务。
2.2 目前方法存在的问题
由于多模态理解和生成任务所需的信息不完全一致,视觉编码器的合并可能导致一些问题。(1) 多模态理解任务通常需要的是对图像或视频等视觉输入的高层语义理解,因此需要视觉编码器能够从低级像素信息逐渐转换为具有更高层语义的信息。(2) 对视觉生成任务来说,视觉编码器需要传递细粒度的视觉信息,通常需要保留更多的细节信息,例如纹理、颜色等。将这两个任务的视觉编码压缩到同一个表征空间中,会带来一些冲突和妥协。由于专门为多模态理解设计的编码器很多并不能直接来做视觉生成,现有的方案在挑选编码器时,往往优先考虑图像生成任务 (如 使用 VQ Tokenizer 作为编码器),导致目前的统一模型生成能力还不错,但是多模态理解能力和当前最先进的方法差异较大。
3. 方法
3.1 模型结构

为了解决单一视觉编码器带来的性能瓶颈,我们提出了对视觉编码进行解耦。具体来说,我们使用两个独立的视觉编码器分别负责多模态理解和生成任务,然后用一个统一的 Transformer 结构去处理不同的输入信息。
为了简化整个模型,我们在选取视觉编码器的时候没有进行复杂的设计。对多模态理解任务来说,我们使用 SigLIP-Large-Patch16-384 去编码特征。对视觉生成任务来说,我们使用 LlamaGen 中训练的标准 VQ Tokenizer 去编码。编码后的信息会分别经过一个 adaptor,然后送入 LLM 中。整个模型是使用 Next-Token-Prediction 的方式进行训练的,采用 causal attention mask,和 LLM 的训练方式一致。
3.2 训练流程

Janus 的训练分为三个阶段。(每一阶段使用的数据详情请参考 paper。整体上会控制 多模态理解 + 纯文本理解:视觉生成 = 1:1)
- 在第一阶段,我们使用 Image Caption 数据和 ImageNet 文生图数据,对 understanding adaptor, generation adaptor, image head 这三个随机初始化的模块进行训练,起到 warm up 的效果。
- 在第二阶段,我们额外打开 LLM 和 text head,然后使用大量纯文本、图生文和文生图的数据进行联合预训练。对于文生图数据,我们会让 ImageNet 这部分数据出现在其他场景的文生图数据之前,先学习像素依赖关系,然后学习场景生成 (参照 Pixart 中的设定)。
- 在第三阶段,我们额外打开 understanding encoder,使用指令跟随数据进行训练。
3.3 推理流程
我们使用 Next-Token-Prediction 的方式进行推理,所以可以使用针对 LLM 进行的优化,例如 KV Cache, vLLM 等加速推理。对视觉生成任务,遵循之前的方法,我们还额外使用了 classifier-free guidance (cfg) 机制,即每个 token 的 logit 由以下公式得出:

其中, 是无条件生成得到的 logit,s 是 cfg 权重,默认为 5。相应的,为了让 cfg 能顺利进行,我们在训练时会随机将 10% 的文生图数据置换为无条件生图。
3.4 可能的扩展
Janus 的设计非常灵活,易于扩展。
- 多模态理解方面,(1) 可以使用比 SigLIP 更强的 encoder,例如 EVA-CLIP 或 InternViT 6B,而不用担心这些 encoder 是否能来做生成。(2) 可以引入当前多模态理解领域先进的动态分辨率技术 (将图像切成多个子块,提供更好的细粒度理解能力) 和 pixel shuffle 压缩技术。
- 视觉生成方面,(1) 可以将当前的 VQ Tokenizer 替换成更好的 tokenizer,例如 MoVQGan 以及最近刚出的 HART (一种结合连续和离散的优点的 tokenizer)。(2) 可以为图像生成部分设计其他优化目标,如 diffusion loss。也可以将图像生成部分的 attention mask 改成双向的,这也被证实了比单向 mask 有更好的生成效果。
- 对更多模态的支持。Janus 的核心思想是解耦,对不同的输入使用不同的编码方式,然后用统一的 transformer 进行处理。这一方案的可行性,意味着 Janus 有可能接入更多的模态,如视频、3D 点云、EEG 信号等。这使得 Janus 有可能成为下一代多模态通用模型的有力候选。
4. 实验
4.1 实现细节
我们使用 DeepSeek-LLM (1.3B, pretrain 模型,未经过指令微调) 作为 LLM 的初始化。在理解和生成任务中,图像分辨率均为 384 * 384。我们用 DeepSeek 自研的 HAI-LLM 框架进行开发,整个训练流程需要在 16 台 8 Nvidia A100 (40GB) GPU 机器上跑 7 天时间。具体细节请参考论文。
4.2 和 state-of-the-arts 的比较
- 多模态理解 (Table 2)。Janus-1.3B 超越了之前同规模的统一模型。在一些 benchmark (POPE, MMBench, SEED Bench, MM-Vet) 上,Janus-1.3B 甚至超越了 LLaVA-v1.5-7B 的结果。这证实了视觉编码解耦对多模态理解性能带来了显著的提升。
- 视觉生成 (Table 3 和 Table 4)。Janus-1.3B 在图像质量评价 (MSCOCO-30K 和 MJHQ-30K) 和图像生成指令跟随能力 benchmark GenEval 上都取得了很不错的结果,超越了之前同规模的统一模型,和一些专用图像生成模型,如 SDXL。



4.3 消融实验
我们设计了严格的消融实验,一方面对 Janus 的视觉编码解耦这一观点进行验证,另一方面,研究联合训练对单任务训练的性能影响。

Baseline 介绍
我们首先按照 Chameleon 的设计,使用一个 VQ Tokenizer 去同时为理解和生成任务编码 (Exp-A)。这个 VQ Tokenizer 和 Janus 中视觉生成部分的编码器是同一个。考虑到这个编码器语义很弱,所以我们额外构造了一个更强的 baseline, Semantic Tokenizer (Exp-B)。
简单来说,这个 Semantic Tokenzier 基于原先的 VQ Tokenizer 构造,额外加了一个 semantic decoder,预测 SigLIP 产生的语义特征,具体细节请见论文的补充材料。通过这样的方式,一方面可以通过 semantic decoder,产生语义更强的图像特征;另一方面,可以使得 Semantic Tokenizer 编码出的图像 ID 具有更好的语义,局部连续性更强。请注意:为了方法的简单性。Semantic Tokenizer 仅在对比实验中使用,而没有在 Janus 中用。如果用了,Janus 应该会在视觉生成方面表现更好。
视觉编码解耦的影响
(1) 比较 Exp-A 和 Exp-D,我们发现 Exp-A 的图像生成效果还不错,COCO-FID 有 8.72,和 Janus (8.53) 类似。但是 Exp-A 的多模态理解性能明显拉胯。
(2) 当换上语义更强的 tokenizer (Exp-B),我们发现多模态理解能力有了明显的提升,但和 Janus 相比还有一定距离。视觉生成方面,Exp-B (7.11) 比 Janus (8.53) 更好。我们猜测原因可能有两点。首先,Semantic Tokenizer 编码出的图像 ID 语义更强,作为 LLM 的预测目标更合理。其次,Semantic Tokenizer 的参数量显著高于 VQ Tokenizer。这也说明了 Janus 在视觉生成方面巨大的提升空间。
(3) 那么,使用同一个 Encoder,对理解的影响到底有多大呢?通过比较 Exp-B 和 Exp-C,我们发现仅使用 Semantic Tokenizer 做多模态理解,明显高于 Exp-B 中的结果。举例来说,MMBench 从 52.7 提高到 62.1。这说明使用单一视觉编码器确实在理解和生成任务上导致了冲突,牺牲了多模态理解的性能。
(4) 最后,我们探讨一下联合训练对单一任务的影响,见 Exp-D, Exp-E, Exp-F。这里为了公平,我们对迭代步数做了严格的控制。例如,让联合训练的模型和纯理解模型见过的多模态理解数据一样多。(其实这样对联合模型不太公平,因为联合模型的数据里,多模态理解的数据浓度相对更低)。最后发现联合训练可以在基本保持多模态理解的能力下,有效地加入视觉生成能力。
4.4 可视化
文生图可视化
如 Figure 4 所示,我们的模型相比于 SDXL, LlamaGen 有着更好的指令跟随能力,能对用户的 prompt 做出更精准的反馈。

涌现能力:多语言文生图
如 Figure 8 所示,我们还意外地发现,及时训练数据中只有英文文生图数据,但最后的模型涌现出了多语言文生图能力,如中文、法语、日语、甚至使用 emoji 🐶 都可以。我们认为这里的涌现能力来自于 LLM 预训练模型。

多模态理解可视化
请见以下两张图,相比于以前的大一统模型,我们的模型更聪明,能读懂 meme 图像。同时还能处理 latex 公式转换、图转代码等任务。


5. 总结
Janus 是一个基于自回归的统一多模态理解与生成框架,具有简单性、高效性和高度灵活性。通过解耦视觉编码,我们突破了当前多模态统一模型中的性能瓶颈,拉进了大一统模型和专用模型在专项任务上的性能差距,解锁了多模态统一模型的新范式。
#Multimodal Pathway
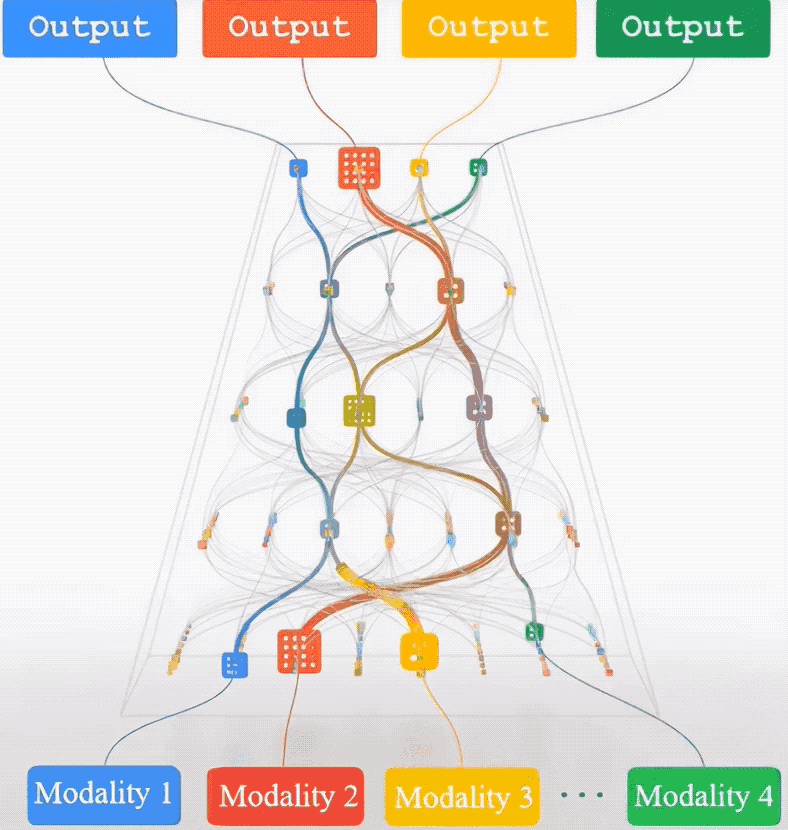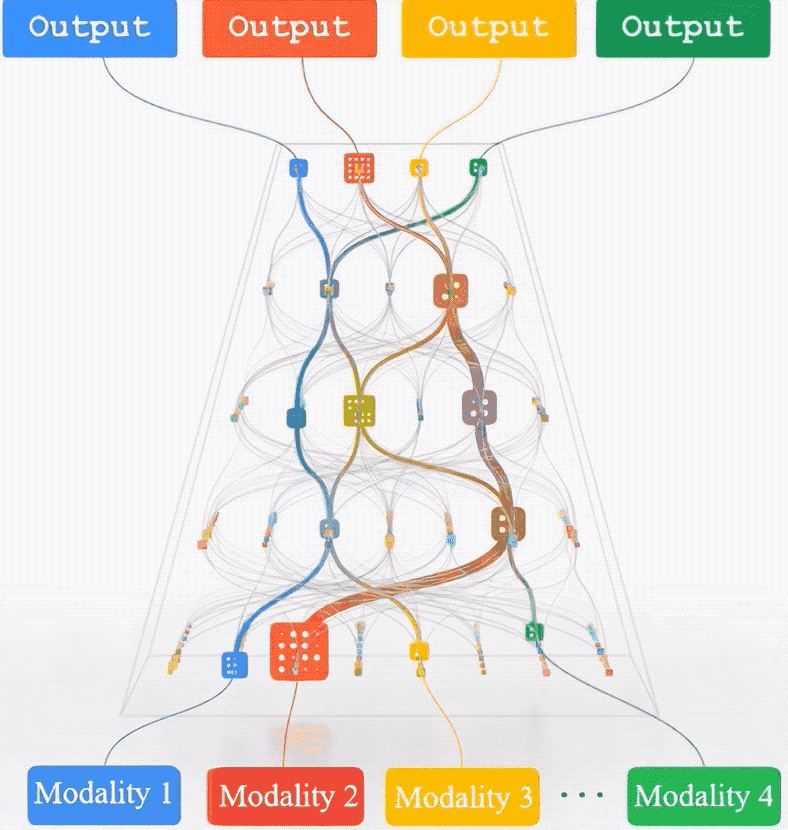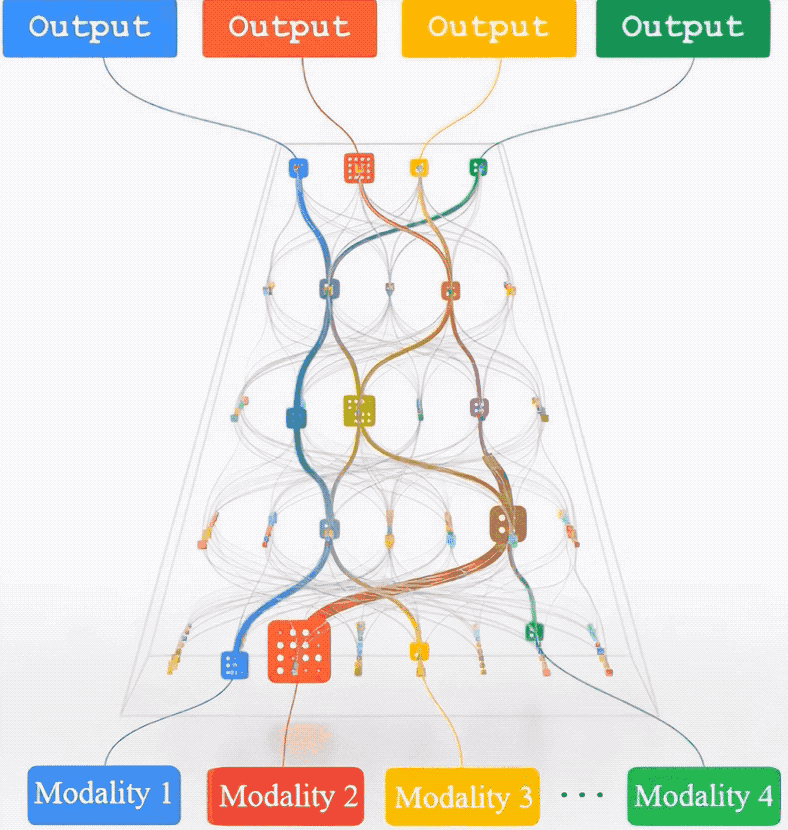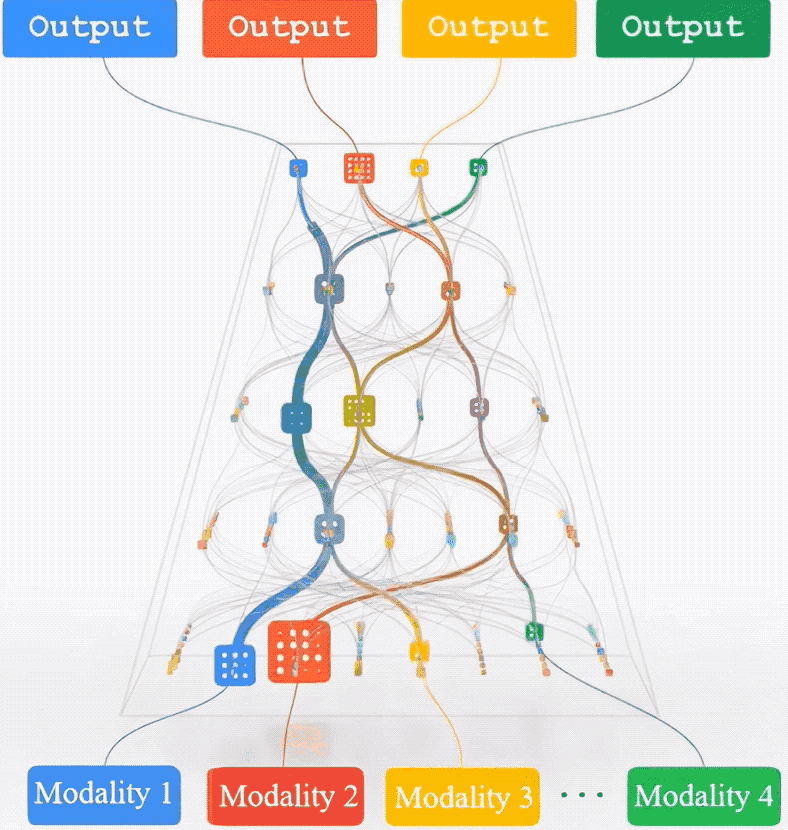
与任务无直接关联的多模态数据也能提升Transformer模型性能。
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。
比如训练一个图像分类模型,除了标注好类别的图像数据集,增加视频、音频、点云等模态数据,也能显著提升模型在图像分类上的性能。
这样一来,在AI训练阶段就可以减少与特定任务直接相关的标注数据需求,可以节省大量成本,或在数据有限的任务上提供新解决思路。

这个神奇的发现来自港中文MMLab和腾讯AI Lab的合作研究,相关论文已被CVPR 2024接收,引起广泛关注。
论文地址:https://arxiv.org/abs/2401.14405
项目网页:https://ailab-cvc.github.io/M2PT/
开源代码:https://github.com/AILab-CVC/M2PT
讲解视频:https://www.bilibili.com/video/BV1Sm41127eW/
从无关数据中学习有用知识
具体来说,团队提出了一种称为多模态通路(Multimodal Pathway)的新框架。
该框架允许Transformer模型在处理特定模态的数据时,同时利用其他模态中的无关数据进行训练,从而在不增加额外推理成本的前提下显著提升模型性能。

多模态通路的核心技术是跨模态重参数化 (Cross-Modal Re-parameterization)*。
这一技术的创新之处在于,它通过结构上的智能重组,使得模型能够在保持原有计算成本的同时,增加从其他模态学习的能力。
对于已经被广泛运用到多模态特征提取的Vision Transformer,团队关心的是这些神经网络中的主要线性层。

具体来说,这一技术在模型的每一个线性层中引入了辅助模态的权重,这些权重通过可学习的参数进行调节,从而在不增加推理时间的情况下,实现模态间的知识迁移。

如图所示,比如有不同模态的两个线性层FC和FC’, 那么跨模态结构重参数化就是要通过构建一个运算完全等价的线性层来承载两个模态的运算,在这里直接将来自不同模态的两部分权重 (W和W’) 做线性组合 (W+λW’) 来平衡两个模态的权重对于目标模态的贡献。
实验结果:跨模态增益挖掘Transformer潜力
在论文中,研究团队详细介绍了他们的实验设计和结果。
在图像识别、点云处理、视频理解和音频分析等多个任务上应用了多模态通路技术,观察到多模态通路 能够在12种不同的模态相互帮助的关系中实现一致的性能提升。

例如,在ImageNet图像识别任务中,结合了点云数据的多模态通路Transformer模型,比传统的Transformer模型在识别准确率上提高了0.7%。
与MAE预训练方法的各种改进相比,该方法无需高昂的计算成本来预训练1600 Epoch,而是直接在下游任务中微调,就能显著地提升模型性能。这充分展示了多模态学习在处理大规模复杂数据集时的强大潜力。
研究人员还发现,跨模态知识迁移的效果不仅与模型参数规模有关,还可能与层次表示(Hierarchical Representation)能力密切相关。也就是越擅长学习层次化的抽象表示的模型,迁移效果就越好。
更值得注意的是,该方法有效地证明了即使毫不相关的多模态数据之间,仍能存在着明显的多模态增益效果,这充分说明我们现在对多模态学习的理解与认知还有很大的提升空间。
总的来说,这项研究不仅能够启发多模态学习在学术领域的发展,也为工业界提供了新的思路。通过利用现有的海量数据资源,即使这些数据与当前任务不直接相关,也能够为AI模型的训练带来积极的影响。
这种方法为数据资源有限或难以标注的领域提供了新的解决方案,特别是在自动驾驶、医疗影像分析、自然语言处理等技术要求极高的领域,多模态通路技术的应用前景广阔。
此外,这一研究还揭示了AI跨模态学习的新机制,推动了学界对于不同数据模态间交互和协同处理的深入理解。研究团队表示,未来他们将探索将多模态通路技术应用于卷积神经网络(CNN)和其他跨架构的AI系统,以进一步挖掘这一技术的潜力。
#OCR-Omni
OCR-Omni来了,字节&华师提出统一的多模态文字理解与生成大模型
本篇分享 NeurIPS 2024 论文Harmonizing Visual Text Comprehension and Generation,字节&华师提出统一的多模态文字理解与生成大模型。
论文链接: https://arxiv.org/abs/2407.16364
代码开源: https://github.com/bytedance/TextHarmony
研究背景与挑战
在人工智能领域,赋予机器类人的图像文字感知、理解、编辑和生成能力一直是研究热点。目前,视觉文字领域的大模型研究主要聚焦于单模态生成任务。尽管这些模型在某些任务上实现了统一,但在 OCR 领域的多数任务上仍难以达成全面整合。
例如,Monkey 等视觉语言模型(VLM)擅长文字检测、识别和视觉问答(VQA)等文本模态生成任务,却无法胜任文字图像的生成、抹除和编辑等图像模态生成任务。反之,以 AnyText 为代表的基于扩散模型的图像生成模型则专注于图像创建。因此,OCR 领域亟需一个能够统一多模态生成的大模型。

关键问题多模态生成的内在矛盾
研究人员发现,多模态生成大模型面临视觉与语言模态之间的固有不一致性,这往往导致模型性能显著下滑。如图所示,在文本生成任务上,多模态生成模型相比单模态生成模型效果降低5%,在图像生成上降低了8%。为应对这一挑战,近期的一些研究采用了特定模态的监督微调,从而分别优化文字生成和图片生成的模型权重。然而,这种方法与统一视觉理解与生成的初衷相悖。
为解决这一难题,字节跳动与华东师范大学的联合研究团队提出了创新性的多模态生成模型 ——TextHarmony。该模型不仅精通视觉文本的感知、理解和生成,还在单一模型架构中实现了视觉与语言模态生成的和谐统一。
TextHarmony: 突破性贡献
TextHarmony 的核心优势在于其成功整合了视觉文本的理解和生成能力。传统研究中,这两类任务通常由独立模型处理。TextHarmony 通过融合这两大类生成模型,实现了视觉文字理解和生成的同步进行,从而统筹了 OCR 领域的多数任务。
研究表明,视觉理解和生成之间存在显著差异,直接整合可能导致严重的模态不一致问题。具体而言,多模态生成模型在文本生成(视觉感知、理解)和图像生成方面,相较于专门的单模态模型,性能出现明显退化。

数据显示,多模态生成模型在文本生成任务上较单模态模型效果降低 5%,图像生成任务上最高降低 8%。而 TextHarmony 成功缓解了这一问题,其在两类任务上的表现均接近单模态专家模型水平。
技术创新
TextHarmony 采用了 ViT、MLLM 和 Diffusion Model 的组合架构:
- ViT 负责图像到视觉 token 序列的转换。
- MLLM 处理视觉 token 和文本 token 的交叉序列,输出两类 token:
- 文本 token 经文本解码器转化为文本输出。
- 视觉 token 与文本 token 结合,作为 Diffusion Model 的条件指引,生成目标图像。
这种结构实现了多模态内容的全面理解与生成。
Slide-LoRA:解决方案
为克服训练过程中的模态不一致问题,研究者提出了 Slide-LoRA 技术。该方法通过动态整合模态特定和模态无关的 LoRA(Low-Rank Adaptation)专家,在单一模型中实现了图像和文本生成空间的部分解耦。
Slide-LoRA 包含一个动态门控网络和三个低秩分解模块:
- 模态特定 LoRA 专家聚焦于特定模态(视觉或语言)的生成任务。
- 模态无关 LoRA 专家处理跨模态的通用特征。
- 动态门控网络根据输入特征,灵活调度不同专家的参与度。

DetailedTextCaps-100K: 高质量数据集
为提升视觉文本生成性能,研究团队开发了 DetailedTextCaps-100K 数据集。该集利用闭源 MLLM(Gemini Pro)生成详尽的图像描述,为模型提供了更丰富、更聚焦于视觉和文本元素的训练资源。

训练策略
TextHarmony 采用两阶段训练方法:
- 首阶段利用 MARIO-LAION 和 DocStruct4M 等图文对预训练对齐模块和图像解码器,构建基础的文本生成与图像生成能力。
- 次阶段运用视觉文本的生成、编辑、理解、感知四类数据进行统一微调。此阶段开放 ViT、对齐模块、图像解码器和 Slide-LoRA 的参数更新,以获得统一的多模态理解与生成能力。
实验评估
研究者对 TextHarmony 在视觉文本场景下进行了全面评估,涵盖理解、感知、生成与编辑四个维度:
视觉文本理解:TextHarmony 显著优于多模态生成模型,性能接近 Monkey 等专业文字理解模型。

视觉文本感知:在OCR定位任务上,TextHarmony超过了TGDoc、DocOwl1.5等知名模型。

视觉文本编辑与生成:TextHarmony 大幅领先于现有多模态生成模型,且与 TextDiffuser2 等专业模型相当。

文字生成效果对比

文字编辑效果对比

文字图像感知与理解可视化

总结与展望
TextHarmony 作为 OCR 领域的多功能多模态生成模型,成功统一了视觉文本理解和生成任务。通过创新的 Slide-LoRA 技术,它有效解决了多模态生成中的模态不一致问题,在单一模型中实现了视觉与语言模态的和谐统一。TextHarmony 在视觉文字感知、理解、生成和编辑方面展现出卓越性能,为复杂的视觉文本交互任务开辟了新的可能性。
这项研究不仅推动了 OCR 技术的进步,也为人工智能在理解和创造方面的发展提供了重要参考。未来,TextHarmony 有望在自动文档处理、智能内容创作、教育辅助等多个领域发挥重要作用,进一步推动人工智能的应用。
#VLoRA
一种参数空间对齐的多模态大模型范式
本文提出了一种参数空间对齐的多模态大模型范式,该范式将输入图像特征转换成LoRA权重并合并到LLM中,使LLM感知图像视觉信息。该范式避免了在LLM的输入序列中引入视觉标记,在训练和推理上都非常高效。
主页:https://feipengma6.github.io/vlora/
论文:https://arxiv.org/pdf/2405.20339
代码:github.com/FeipengMa6/VLoRA
- 输入空间对齐范式1.1 介绍
在进入正题之前,我们先简单回顾一下当前主流的MLLM范式。
以最具代表性的LLaVA[1]为例,

Figure 1. LLaVA的结构框图
对于输入的图像,通过视觉编码器(Vision Encoder)和 映射模块(Projection)提取特征,得到一个由视觉标记(Visual Tokens)组成的视觉序列,然后将视觉序列和文本在序列维度上拼接,一同输入到LLM中进行训练。在训练过程中,视觉序列是在对齐LLM的输入空间以让LLM能够理解视觉信息,我们称这种范式为输入空间对齐范式。
输入空间对齐范式有2个特点:
1. 视觉信息序列化,和文本信息具有相同的表现形式 图像经过视觉编码器之后会变成视觉标记,然后通过映射模块映射到和文本标记(Text Tokens)相同的特征维度,最后形成了和文本信息相同的表现形式,即序列。
2. MLLM中视觉和文本的模态交互通过注意力机制进行 视觉信息序列化之后,会将视觉序列与文本序列在序列维度上拼接,然后同时输入给LLM。在前向传播的过程中,视觉与文本通过注意力机制产生模态交互。
目前主流MLLM遵从输入空间对齐范式,比如Qwen2-VL[2],DeepSeek-VL[3],和InternVL2[4],如Figure 2所示。

Figure 2. 输入空间对齐范式:Qwen2-VL, DeepSeek-VL 和 InternVL2
1.2 问题
输入空间对齐范式使用CLIP可以很容易将视觉特征对齐到LLM输入空间,因为CLIP的视觉特征预先和文本对齐过,本身具备丰富的语义信息,但是在训练和推理时计算效率低。
在输入序列达到一定长度的情况下,LLM的计算量集中在注意力机制部分,当输入序列长度为 n 时,计算复杂度为,也就是说LLM的计算量随着输入序列长度而平方增长。LLaVA-v1.5的视觉编码器为ViT-L-14,对于单张图像,产生的视觉标记的数量为576。而考虑到高分辨率图像输入,一些工作会将图像切分成多个子图,分别转换成视觉标记,最后产生非常长的视觉序列。比如,Sphinx-2k[5]的视觉序列长度为2890,InternLM-Xcomposer2-4KHD的视觉序列长度甚至可以达到8737。然而,视觉序列长度的增长会导致MLLM的计算量急剧增加。特别是在预训练阶段,MLLM通常在网络爬取的图像文本对上进行预训练,文本长度通常比较短,比如LAION-2B的文本平均长度为10.95,视觉token的数量是文本的20~50倍,这意味着视觉标记引入了绝大部分的计算量,影响了训练效率。
2. 参数空间对齐范式
为了解决上面的问题,我们提出了参数空间对齐范式,将视觉信息表征为模型权重合并到LLM中,从而在不引入额外计算量的情况下使LLM能够感知视觉信息。

Figure 3. 参数空间对齐范式
参数空间对齐范式的核心是将视觉信息表征为模型权重,并融合到LLM的参数中。整体流程如Figure 3 所示。
LLM中Self-attention包含 和 ,共4个权重矩阵,Feed-forward Network包含 和 共2个权重矩阵。这里我们用 来表示LLM的权重矩阵, 为隐藏层维度。
对于输入图像 , 先使用视觉编码器 来提取图像视觉特征, 得到 是 visual token的数量, 是视觉特征的维度。
然后,我们设计了感知权重生成模块 来将视觉特征转化为感知权重 ,这里值得注意的是, 为了尽可能保持LLM本身的语言能力, 是一个低秩矩阵, 同时, 这也有利于减少生成感知权重的计算开销。
得到感知权重 后, 我们可以直接将其融合到LLM的权重中, 。
通过将从视觉特征转化来的权重整合到LLM的权重中,LLM自然就具备了视觉感知能力。在合并权重后,不会给LLM带来额外的计算开销。对于LLM中每个解码层中的任意类型权重(q, k, v, o, m),我们都可以生成相应的感知权重并将其整合到对应权重中。
3. 感知权重生成模块

Figure 4. 感知权重生成模块
我们设计了感知权重生成模块来将视觉特征转化为感知权重,对于LLM中不同类型的权重,我们用不同的感知权重生成模块来生成对应的感知权重。以下是对单一类型的权重生成的介绍。
如Figure 4(a) 所示, 我们的感知权重生成模块是Decoder-only结构的, 有 层解码层, 每层由 self-attention 模块,cross-attention模块,和feed-forward network组成。首先,感知权重生成模块的self-attention模块的输入是 个感知查询标记(perceptual queries),感知查询标记的数量对应我们想要合并权重的LLM层数,即生成的感知权重的数量。然后,在cross-attention模块中,视觉特征与感知查询标记交互,最后通过feed-forward network,得到 个 ,其中 是感知权重模块的 隐藏层维度,并且该特征维度远小于LLM的隐藏层维度 (比如 ),有 。我们的目的是获得 个 ,而直接使用线性层将 的特征维度从 升维到 会引入极大的参数量,同时,这么一个高维矩阵直接合并到原始权重中可能会影响LLM本身的语言能力。因此,我们先采用一个共享的线性层 ,将 个 分别升维到 的维度 ,其中 ,重整形状为 ,称为视觉参数。接下来,对于 个视觉参数 ,我们采用 个不同的线性层 分别进行升维,得到感知权重 。
最后我们将感知权重合并到 LLM 权重中,有 ,考虑到 和 的低秩特性, 我们可以观测到上式和LoRA具有相同的形式, 如Figure 4(b)所示, 其中 相当于LoRA中的 相当于 , 因此, 我们的感知权重生成模块也可以视为 "LoRA权重生成器"。
4. 实验结果
我们采用和LLaVA-v1.5相同的设置,用Vicuna-7b-v1.5作为LLM,CLIP-ViT-L-14作为视觉编码器。我们对所有权重类型都生成LoRA权重,秩为64,并且每隔4层合并到LLM权重中。预训练数据我们从Capsfusion-120M中采样30M,微调数据我们采用和LLaVA-v1.5相同的数据。
4.1 和现有MLLM对比

Table 1. 主要实验结果
在Table 1中,我们在多个MLLM评测基准上进行了测试,包括MMBench,MME,ScienceQA,HallusionBench MMMU和CCBench。由于我们的VLoRA不需要在LLM推理过程中引入额外的视觉标记,计算量相比其他方法显著减少。在性能上,在MMBench,ScienceQA和HallusionBench上,可以达到和LLaVA-v1.5可比的结果,在CCBench上达到了28.6,超过了LLaVA-v1.5的27.5。在MME上VLoRA落后于LLaVA-v1.5,这可能是因为我们的感知权重生成器是随机初始化的,预训练不够充分。
4.2 在相同数据下和LLaVA-v1.5对比

Table 2. 消融实验
为了更公平的对比,我们在不同的设置下复现LLaVA-v1.5,包括使用Capsfusion-30M作为预训练数据,将Projector换成QFormer(和我们的权重生成模块相似的结构)。在Table 2中,第2行是将LLaVA-v1.5的预训练数据换成Capsfusion-30M的结果,可以看到,在使用了更多预训练数据的情况下,LLaVA-v1.5的性能并没有进一步提升,甚至在MME,HallusionBench,MMMU和CCBench上有所下降,说明了在相同的预训练数据下,VLoRA的性能是和LLaVA-v1.5可比的。第3行是使用QFormer结构作为LLaVA-v1.5的映射模块的结果,我们可以发现该设置下VLoRA 除了在ScienceQA和HallusionBench上略微低于LLaVA-v1.5,在其他评测榜单上都超过了LLaVA-v1.5。
5. 未来展望
VLoRA在参数空间对齐上做了尝试,初步验证了这种范式的有效性,目前还处于一个初级阶段,还有很多值得探索的地方,包括更合适的视觉编码器,更大规模的预训练,扩展到多图,视频场景,扩展到更多的模态等。
#MMCA
本文介绍了一种名为多模态条件适应(MMCA)的新方法,它通过动态更新视觉编码器的权重来改善视觉定位任务中的特征提取,该方法在四个代表性数据集上取得了显著的性能提升。论文还提出了灵活的多模态条件变换器和卷积模块,可以作为即插即用组件应用于其他视觉引导模型。
论文地址:https://arxiv.org/abs/2409.04999
论文代码:https://github.com/Mr-Bigworth/MMCA
创新点
- 提出了多模态条件适应(
MMCA)方法,该方法从一种新颖的权重更新视角改善了视觉引导模型中视觉编码器的特征提取过程。 - 将提出的
MMCA应用于主流的视觉引导框架,并提出了灵活的多模态条件变换器和卷积模块,这些模块可以作为即插即用组件轻松应用于其他视觉引导模型。 - 进行广泛的实验以验证该方法的有效性,在四个具有代表性的数据集上的结果显示出显著的改善,且成本较小。

视觉定位旨在将传统的物体检测推广到定位与自由形式文本描述相对应的图像区域,已成为多模态推理中的核心问题。现有的方法通过扩展通用物体检测框架来应对这一任务,使用独立的视觉和文本编码器分别提取视觉和文本特征,然后在多模态解码器中融合这些特征以进行最终预测。
视觉定位通常涉及在同一图像中定位具有不同文本描述的物体,导致现有的方法在这一任务上表现不佳。因为独立的视觉编码器对于相同的图像生成相同的视觉特征,从而限制了检测性能。最近的方法提出了各种语言引导的视觉编码器来解决这个问题,但它们大多仅依赖文本信息,并且需要复杂的设计。
受LoRA在适应不同下游任务的高效性的启发,论文引入了多模态条件适配(MMCA),使视觉编码器能够自适应更新权重,专注于与文本相关的区域。具体而言,首先整合来自不同模态的信息以获得多模态嵌入,然后利用一组从多模态嵌入生成的权重系数,来重组权重更新矩阵并将其应用于视觉定位模型的视觉编码器。
MMCA

MMCA遵循典型的端到端编码器-解码器范式:
- 给定一幅图像和一个语言表达作为输入将其输入到编码器部分,以生成相应的特征嵌入。
a. 在语言分支中, 语言主干将经过分词的语言表达作为输入, 并提取文本特征 ,其中 是语言标记的数量。
b. 在视觉分支中,CNN主干首先提取一个二维特征图,然后经过一系列变换器编码器层,生成一个展平的视觉特征序列
c. 多模态条件适应(MMCA)模块以层级方式应用于卷积层和变换器层的参数矩阵。该模块同时接受视觉和文本特征作为输入,并动态更新视觉编码器的权重,以实现基于语言的视觉特征提取。
- 将视觉和文本特征嵌入连接在一起,并在多模态解码器(视觉-语言变换器)的输入中添加一个可学习的标记 [
REG],该解码器将来自不同模态的输入标记嵌入对齐的语义空间,并通过自注意力层执行模态内和模态间的推理。 - 回归头使用 [ REG ] 标记的输出状态来直接预测被指对象的四维坐标 。与真实框 的训练损失可以表述为:

对于视觉引导任务,论文希望不同的指代表达能够控制视觉编码器的一组权重更新,从而引导编码器的注意力集中在与文本相关的区域。然而,直接生成这样的矩阵带来了两个缺点:(1)这需要一个大型参数生成器。(2)没有约束的生成器可能在训练中对表达式过拟合,而在测试期间却难以理解表达式。
受LoRA的启发,让网络学习一组权重更新的基矩阵并使用多模态信息重新组织更新矩阵。这使得参数生成器变得轻量,并确保网络的权重在同一空间内更新。
具体而言,先对权重更新矩阵进行分解,并将其重新表述为外积的和,通过并使用加权和来控制适应的子空间:

为了简化并且不引入其他归纳偏差,使用线性回归来生成这一组权重:

其中 是参数矩阵, 是特定层的多模态嵌入,它是由文本特征和从前一层输出的视觉特征生成的。
与迁移学习任务不同,这里并不打算微调一小部分参数以适应特定的下游任务,而是希望视觉编码器能够适应各种表达。因此,所有参数矩阵在训练阶段都是可学习的。
多模态嵌入
仅依赖文本信息来引导视觉编码器可能会在某些应用中限制灵活性,并且性能可能会受到文本信息质量的影响。为了缓解这些问题,采用门控机制来调节文本信息的输入。

给定文本特征 和展平的视觉特征 ,使用简单门控机制来融合视觉和文本嵌入:

最后,融合嵌入被用来生成系数,从而指导视觉编码器的权重更新。
适配视觉定位
基于视觉编码器(卷积层和Transformer层),进一步提出了多模态条件Transformer和多模态条件卷积,用于将MMCA应用于视觉定位中。
- 多模态条件
Transformer
视觉主干中的Transformer编码器层主要由两种类型的子层组成,即MHSA和FFN。通过应用多模态条件适应,MHSA和FFN的计算变为:

其中是查询、关键和MLP块的线性投影的条件权重更新。
- 多模态条件卷积
为了便于应用多模态条件适应, 将卷积权重更新展开为一个 2-D 矩阵并用两个矩阵 进行近似, 秩为 。于是, 卷积块的多模态条件适应可以通过两个连续的卷积层 和 来近似:

其中 和 分别是来自前一卷积层的视觉特征和从多模态嵌入生成的权重系数。在通道维度上计算系数与 输出的点积, 并将输出输入到 , 这相当于重新组织权重更新。
主要实验





















