
# aiXcoder-7B
7B超越百亿级,北大开源aiXcoder-7B最强代码大模型,企业部署最佳选择,对代码大模型而言,比能做编程题更重要的,是看是能不能适用于企业级项目开发,是看在实际软件开发场景中用得顺不顺手、成本高不高、能否精准契合业务需求,后者才是开发者关心的硬实力。
当下,大语言模型集成至编程领域、完成代码生成与补全任务成为重要趋势。业界已经出现了一批引人瞩目的代码大模型,比如 OpenAI 的 CodeX、谷歌 DeepMind 的 AlphaCode、HuggingFace 的 StarCoder,帮助程序员更迅捷、更准确、更高质量地完成编码任务,大幅提升效率。
有这样一支研发团队,在 10 年前便开始了将深度学习用于软件开发的探索,并在代码理解和代码生成领域双双全球领先。他们就是来自北京大学软件工程研究所的 aiXcoder 团队(简称 aiXcoder 团队),此次为开发者带来了新的高效编码利器。
4 月 9 日,该团队开源了全自研 aiXcoder 7B 代码大模型,不仅在代码生成和补全任务中大幅领先同量级甚至超越 15B、34B 参数量级的代码大模型;还凭借其在个性化训练、私有化部署、定制化开发方面的独有优势,成为最适合企业应用、最能满足个性化开发需求的代码大模型。
aiXcoder 7B 的全部模型参数和推理代码均已开源,可以通过 GitHub、Hugging Face、Gitee 和 GitLink 等平台访问。
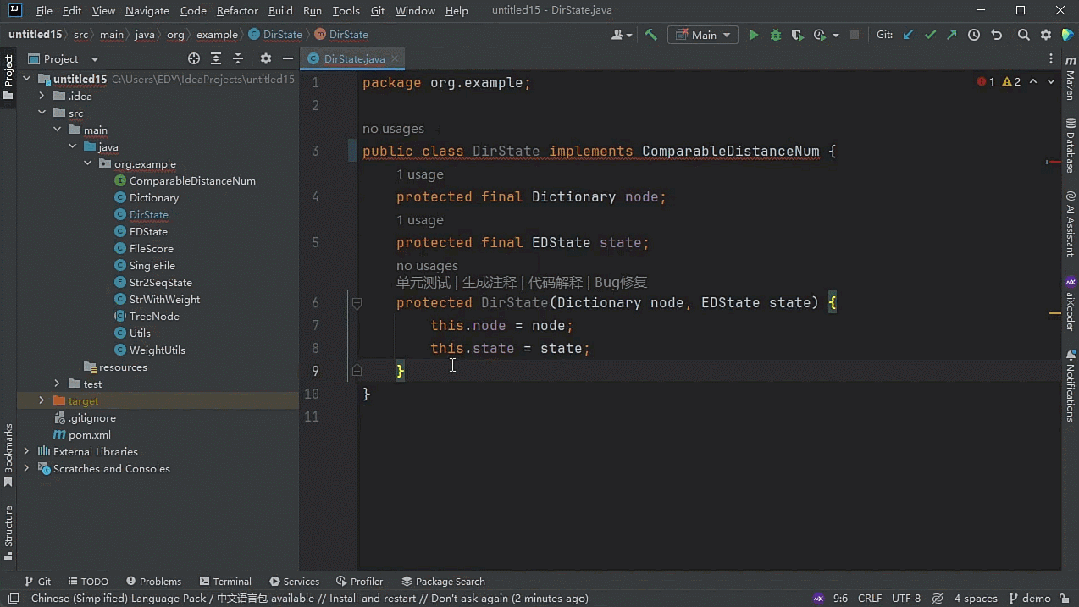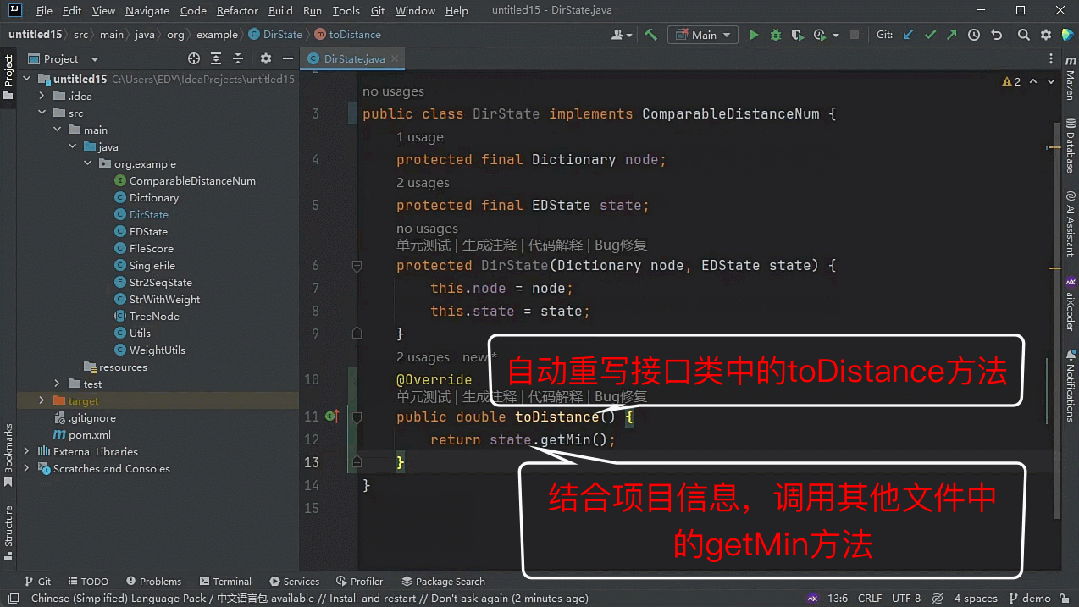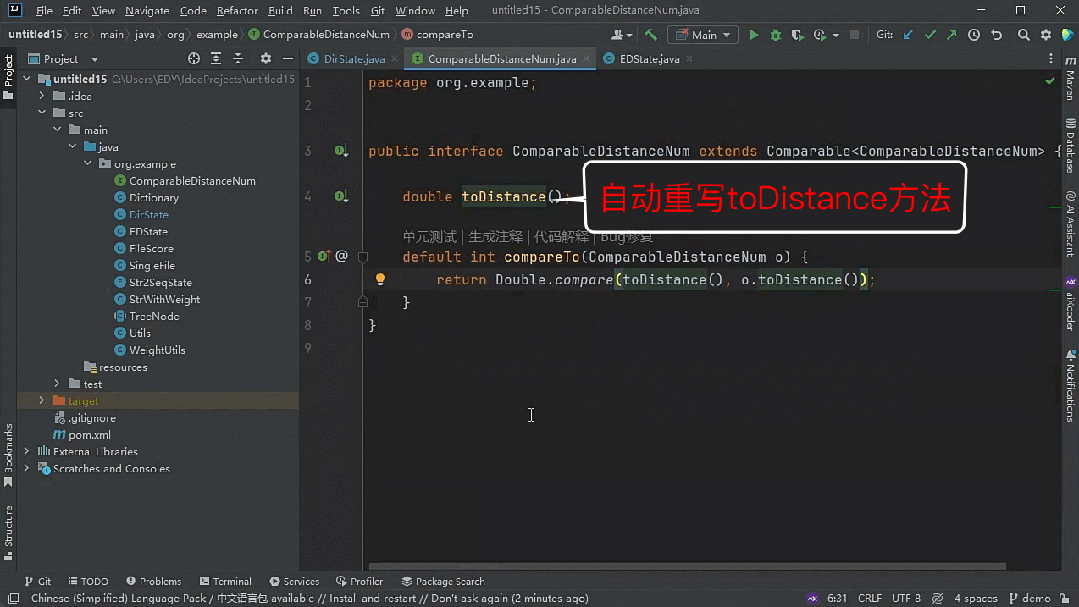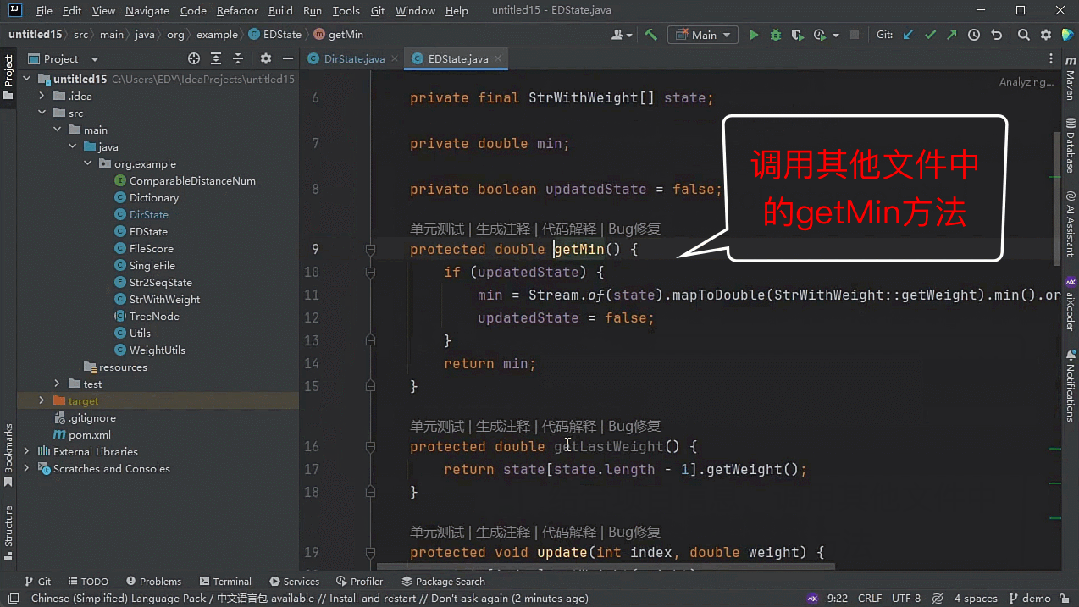
「耳听为虚眼见为实」,一切还是要用真实的测评数据和实际的任务效果说话。
越级体验
能其他代码大模型所不能
一个代码大模型究竟好不好用, 当然要在对程序员最有帮助、用的最多的代码生成与补全任务中来验证。
先看代码生成比较结果,在 OpenAI HumanEval(由 164 道 Python 编程问题组成)、谷歌 MBPP(由 974 个 Python 编程问题组成)和 HuggingFace MultiPL-E(包含了 18 种编程语言)等代码生成效果评估测试集上,aiXcoder 7B 版的准确率远超当前主流代码大模型,成为十亿乃至百亿级参数中最强。

除了在 HumanEval 这样偏向非真实开发场景的测试集上取得准确率新 SOTA,aiXcoder 7B 在代码补全等真实开发场景中的表现更是可圈可点,比如写好上文让代码大模型补下文或者跨文件引用已经定义好的方法、函数、类等。
同样用数据说话,在考虑上下文的单行补全测评集 SantaCoder 上,aiXcoder 7B Base 版在与 StarCoder 2、CodeLlama 7B/13B、DeepSeekCoder 7B 等主流同量级开源模型的较量中取得最佳效果,成为最适合实际编程场景的代码补全基础模型。具体如下表所示:

aiXcoder 7B Base 版的补全效果最好,不单单是准确率更高,还在实际运行中表现出了其他代码大模型没有或者逊于自己的能力。实现这些的背后是一系列针对代码特性的创新训练方法,正是它们使得 aiXcoder 7B Base 版脱颖而出。
首先,aiXcoder 7B Base 版在预训练时提供了 32k 的上下文长度,这在现有 7B 参数量级代码大模型中为最大,其他多为 16k。不仅如此,通过插值的方法可以直接在推理时将上下文长度扩展到 256k,并在理论上有能力扩展至更长。
在同量级模型中拥有最大预训练上下文长度,并可弹性扩展,成为提升 aiXcoder 7B Base 版代码补全效果的重要基础。
其次,aiXcoder 7B Base 版在代码补全过程中「知道」用户什么时候需要生成代码,并在代码内容已经完整不需要再生成时自动停止。这成为该模型比较独特的功能,其他很多代码大模型无法做到这一点。
aiXcoder 团队表示,该功能在技术上的实现离不开结构化 Span 技术。在模型训练中,通过结构化 Span 技术来构建训练数据和相关任务,让模型学习到用户应该在什么时候生成代码或者补全的内容在语法和语义结构上是否完整。
这也就意味着 aiXcoder 7B Base 版能自动「知道」自己推理到了什么位置,而其他模型想要终止的话,需要人为设定终止条件。自动推理则少了这种麻烦,有助于提升工作效率。
此外,在 aiXcoder 扩展基准测试集(aiXcoder Bench)上,aiXcoder 7B Base 版表现出了相较于其他代码大模型的又一大亮点,即倾向于使用较短代码来完成用户指定的任务。
详细结果如下表所示,在针对 Java、C++、JavaScript 和 Python 编程语言的代码补全测评时,aiXcoder 7B Base 不仅效果最好,四处红框圈出的生成答案长度明显短于其他竞品模型,并且非常接近甚至有时比标准答案(Ref)还要短。

aiXcoder 团队指出,这一后验发现仍离不开结构化 Span 技术。他们在整个训练过程中特别注重代码结构,而结构化 Span 按照代码结构对代码进行拆分,这更有益于体现代码的语义,最终促成了模型「短」答案的同时效果又占优。
除了在以上单文件上下文代码补全任务中的卓越表现,aiXcoder 7B Base 版在跨多文件补全场景中的表现同样更胜一筹,不仅针对多文件的编程效果提升最优,还在下表 CrossCodeEval 测评集上有了一个重要发现。
据 aiXcoder 团队介绍,该模型在只通过光标上文搜索到的结果作为 prompt(只看当前编写的上文),同时其他模型拿 GroundTruth(把包含答案的文件给到这些模型)搜索到的结果作为 prompt,在这种条件下,前者的效果依然要强于后者。
如何做到的呢?对于其他模型来说,即使有更多的上下文信息,它们也搞不清楚哪些是最核心、最关键的。而 aiXcoder 7B Base 版能从上下文档中拣出对当前编写代码最有效、最核心的上下文细节,所以才有好的效果。
这里感知到哪些信息最有效最为关键,通过对上下文进一步信息处理,结合文件相关内容的聚类、代码 Calling Graph 来构建多文件之间的相互注意力关系,进而获取到对当前补全或生成任务最关键的信息。

所有这些创新性训练方法很大程度上决定了 aiXcoder 7B Base 版能够在众多代码大模型的比拼中胜出。此外, 1.2T 的高质量训练数据同样功不可没,这一量级不仅在同类型模型中最大,还是独有 token 数据。
其中 600G 优先放入的高质量数据对模型效果起了重要作用,其他数据主要来自 GitHub,以及 Stack Overflow、Gitee 等,自然语言部分还包括了一部分 CSDN 数据,并且全部数据进行了过滤处理。
Talk is cheap, Show me the code
显然,aiXcoder 7B Base 版在测评数据上赢了其他代码大模型,但究竟能不能高效地帮助开发者完成编码任务?还是要看实战效果。
先看生成能力,对于前端开发,aiXcoder 7B Base 版可以通过注释快速地生成对应网页:
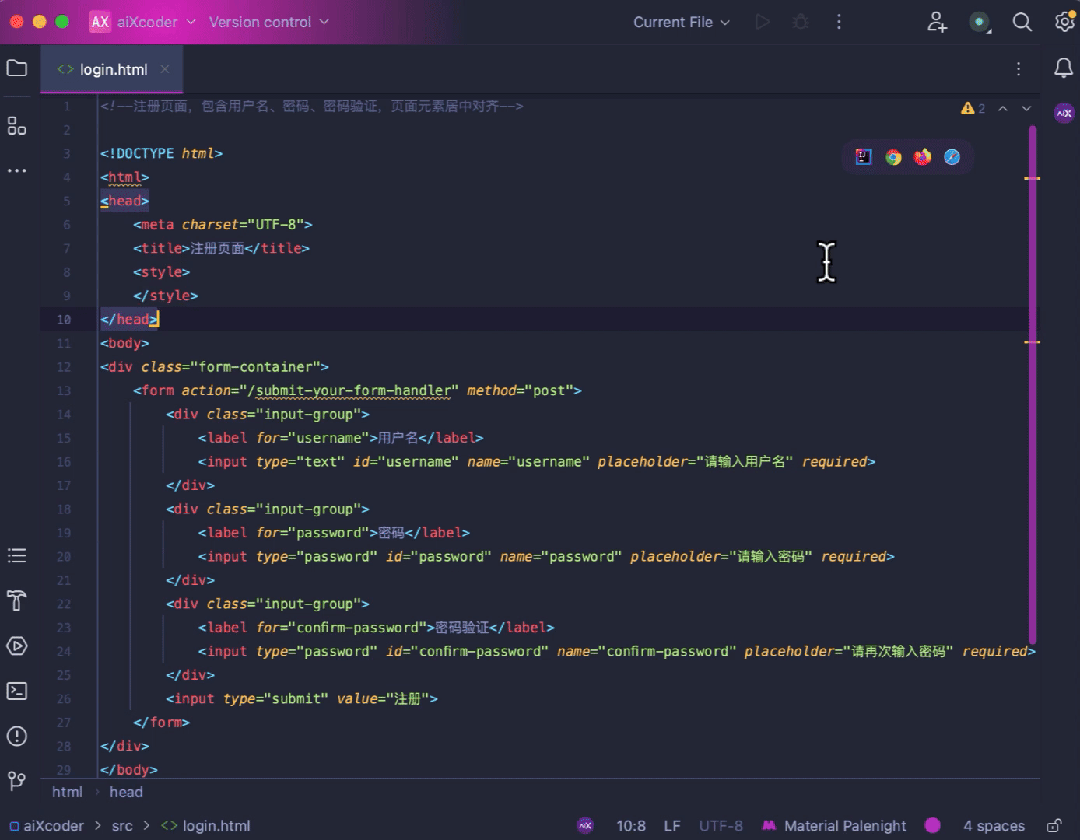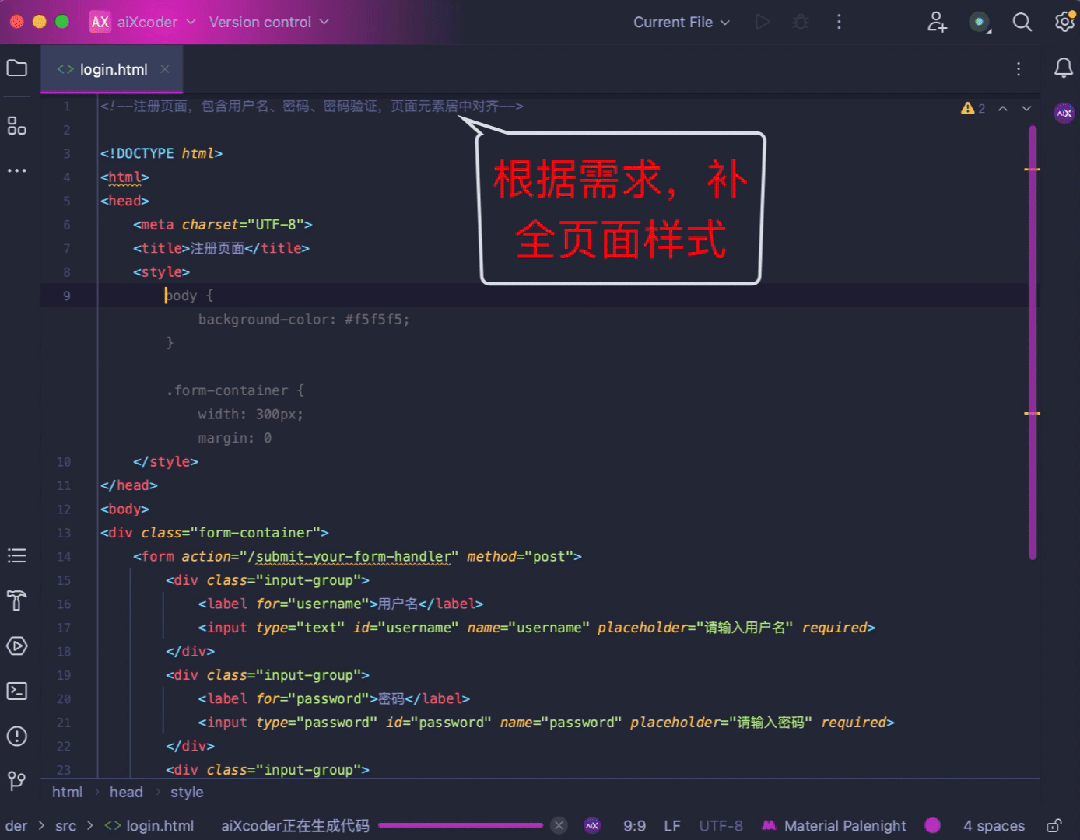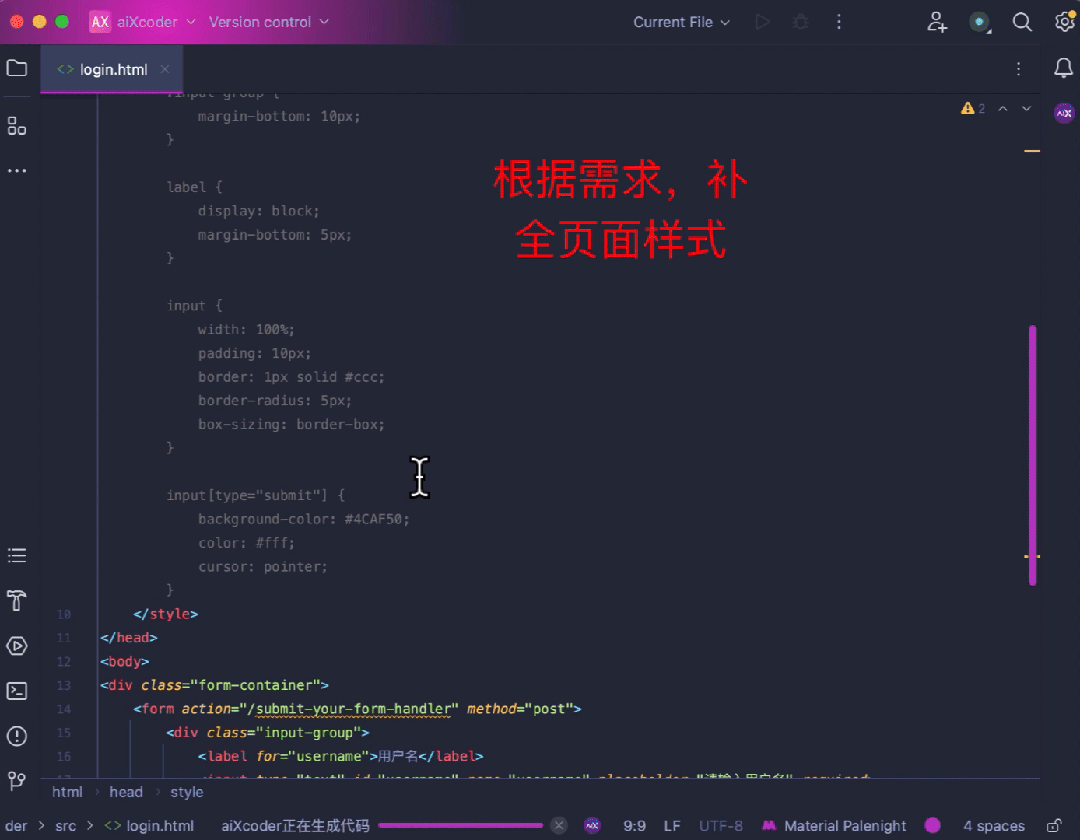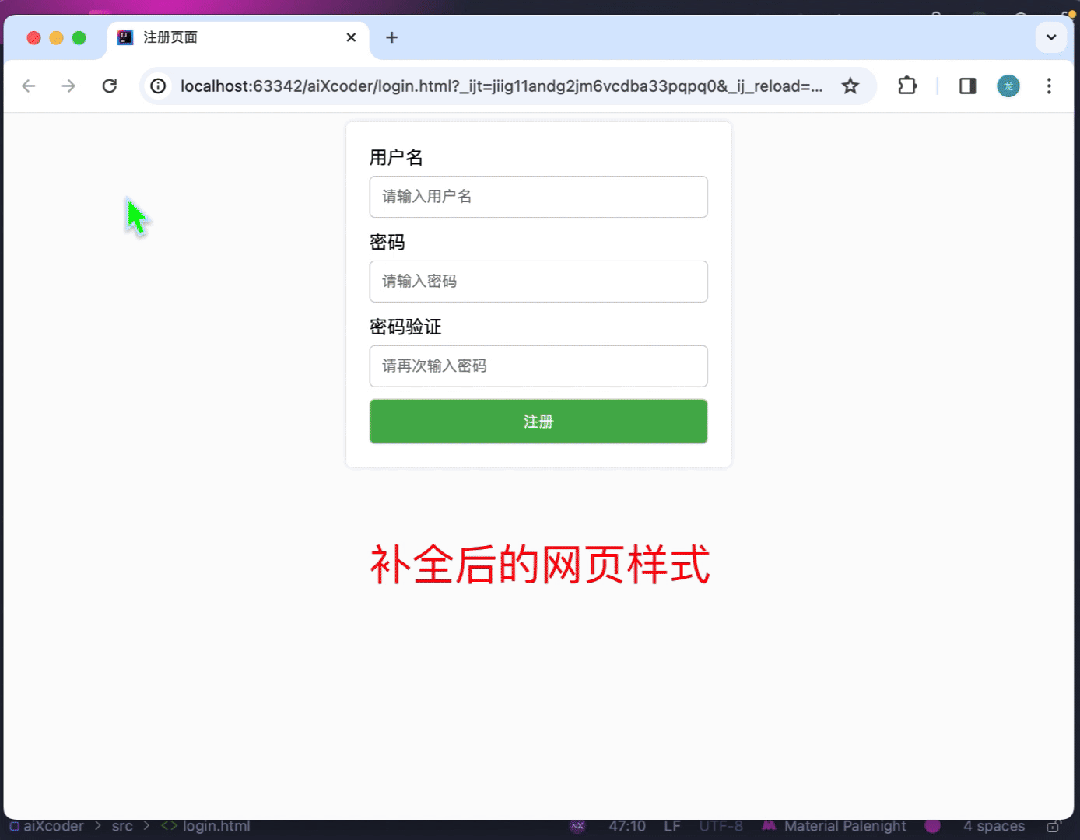
还可以处理高难度算法题,比如经典的分糖果问题,通过贪心的策略,以左右两次遍历的方式得到最少糖果数。
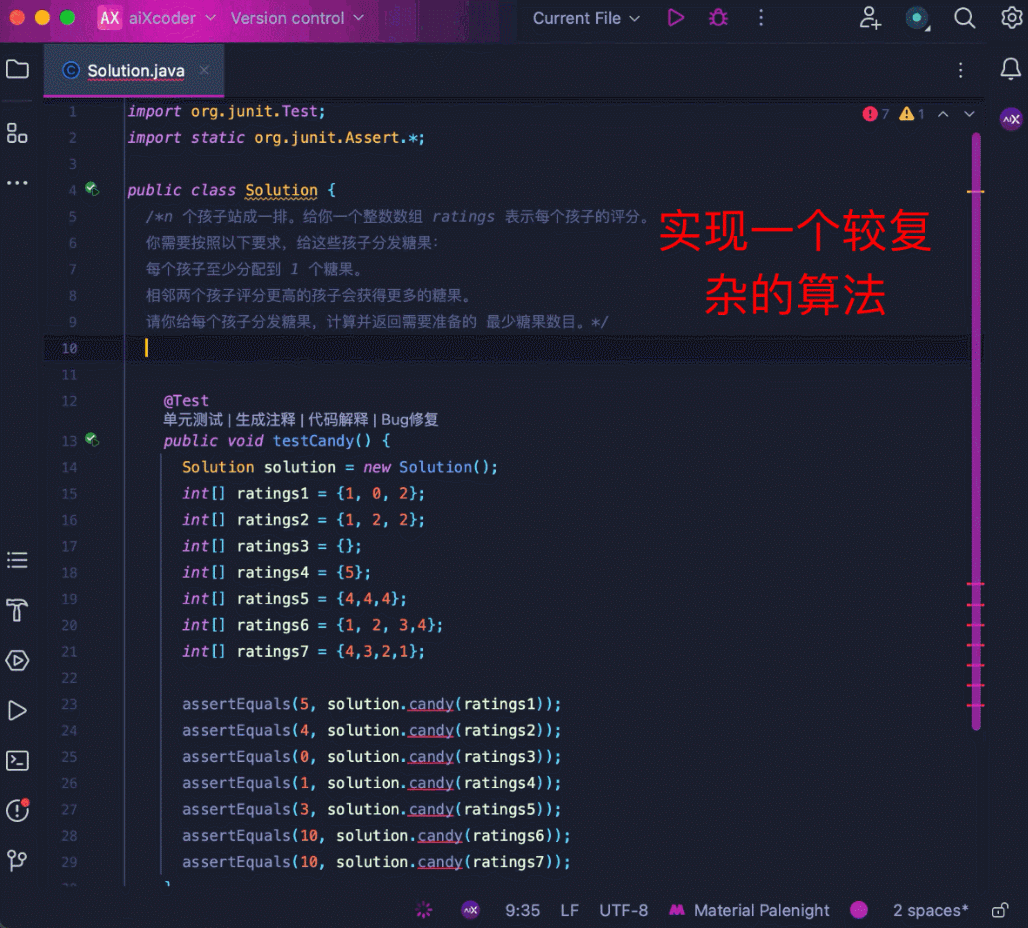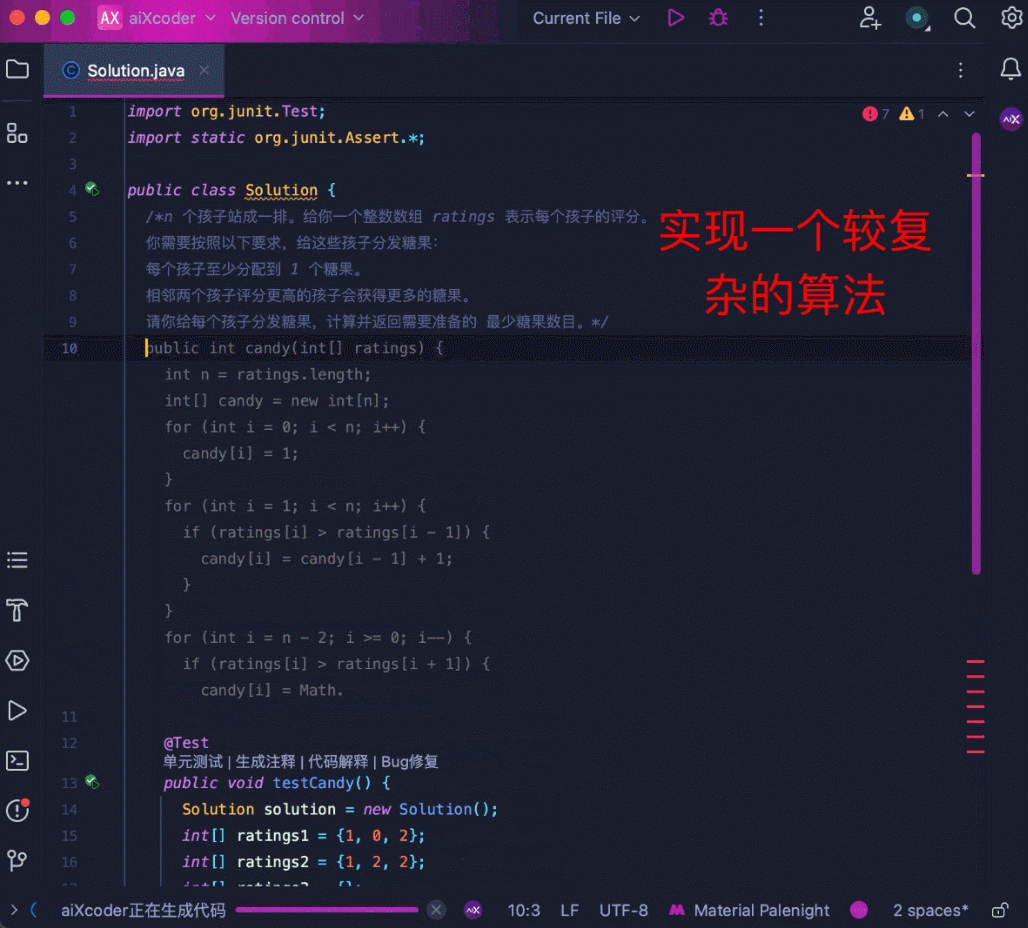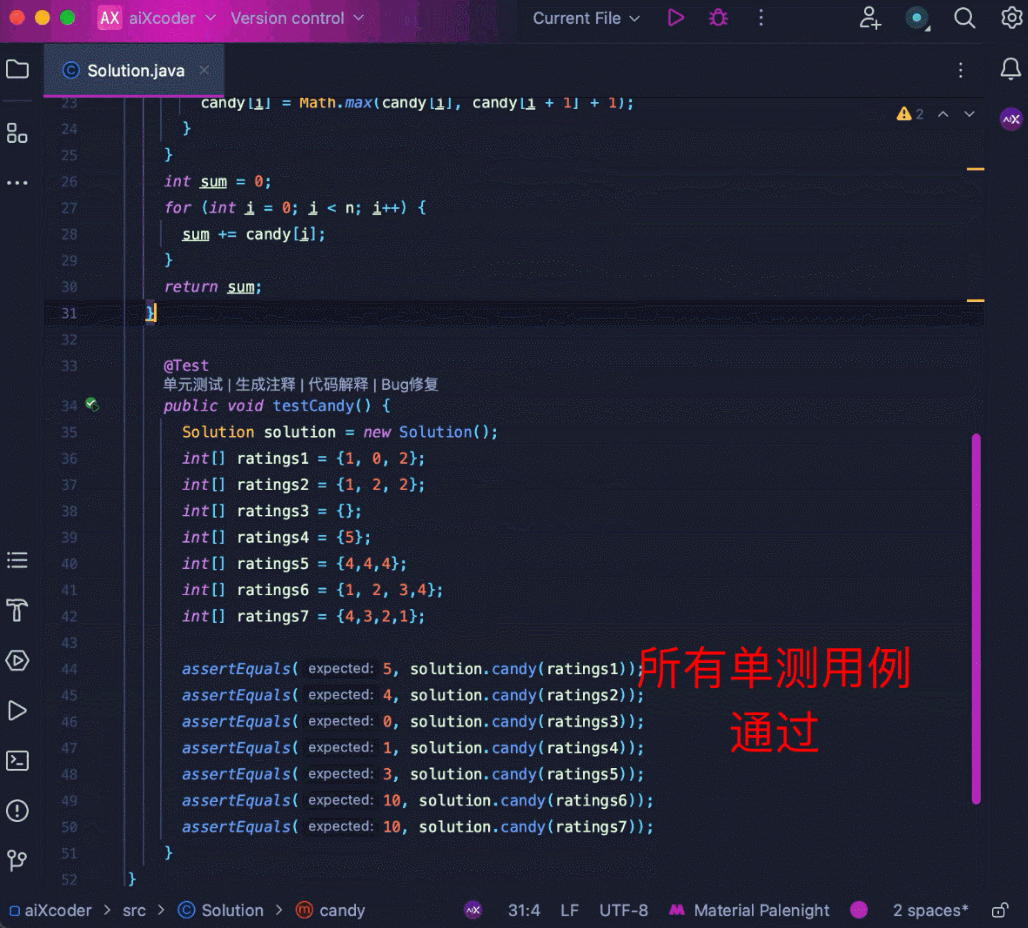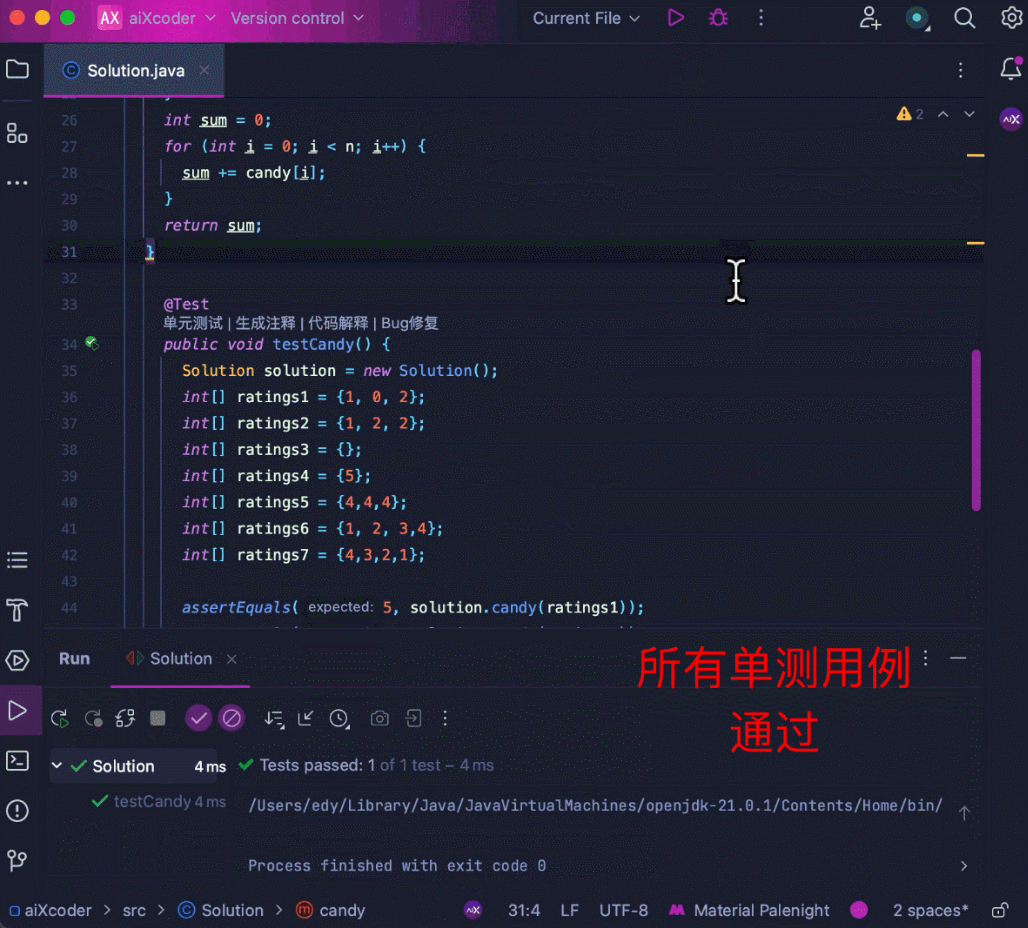
再来看 aiXcoder 7B Base 版更得心应手的代码补全场景,比如长上下文补全。这里用多个工具函数拼成 1500 多行的代码,要求模型在文件末端进行注释补全,模型识别到了文件顶部的相关函数,并成功地结合函数信息补全了相关方法:
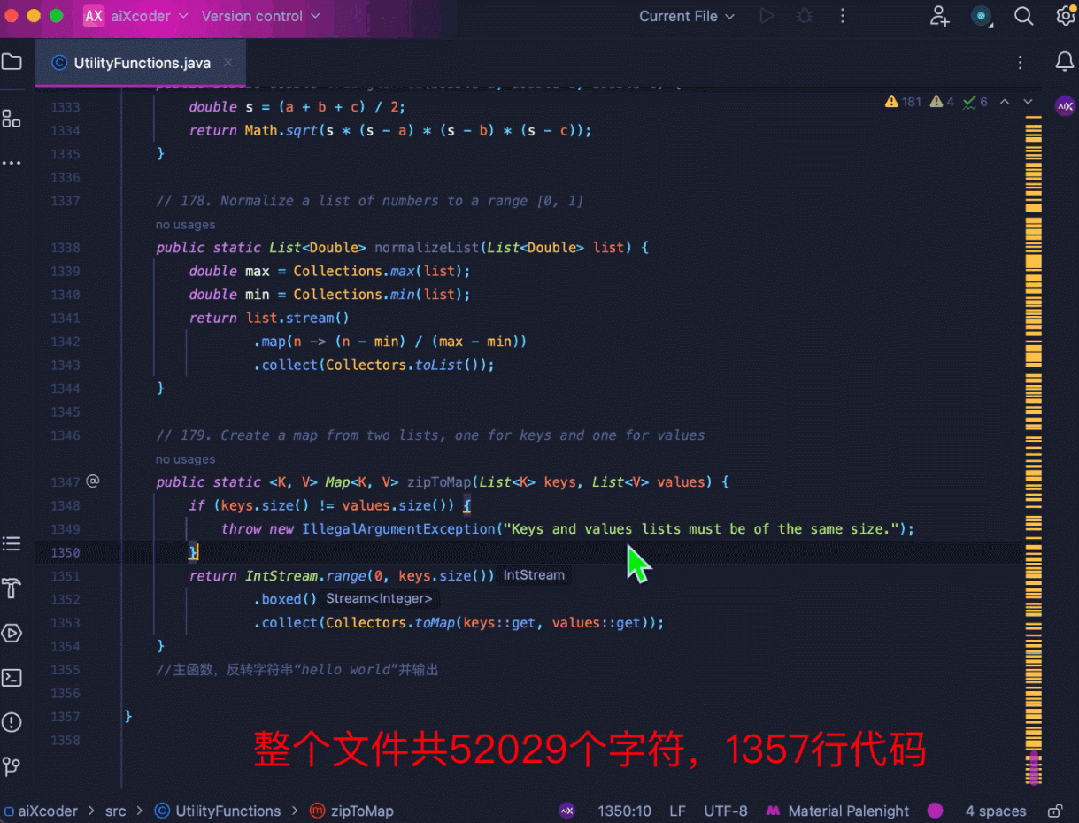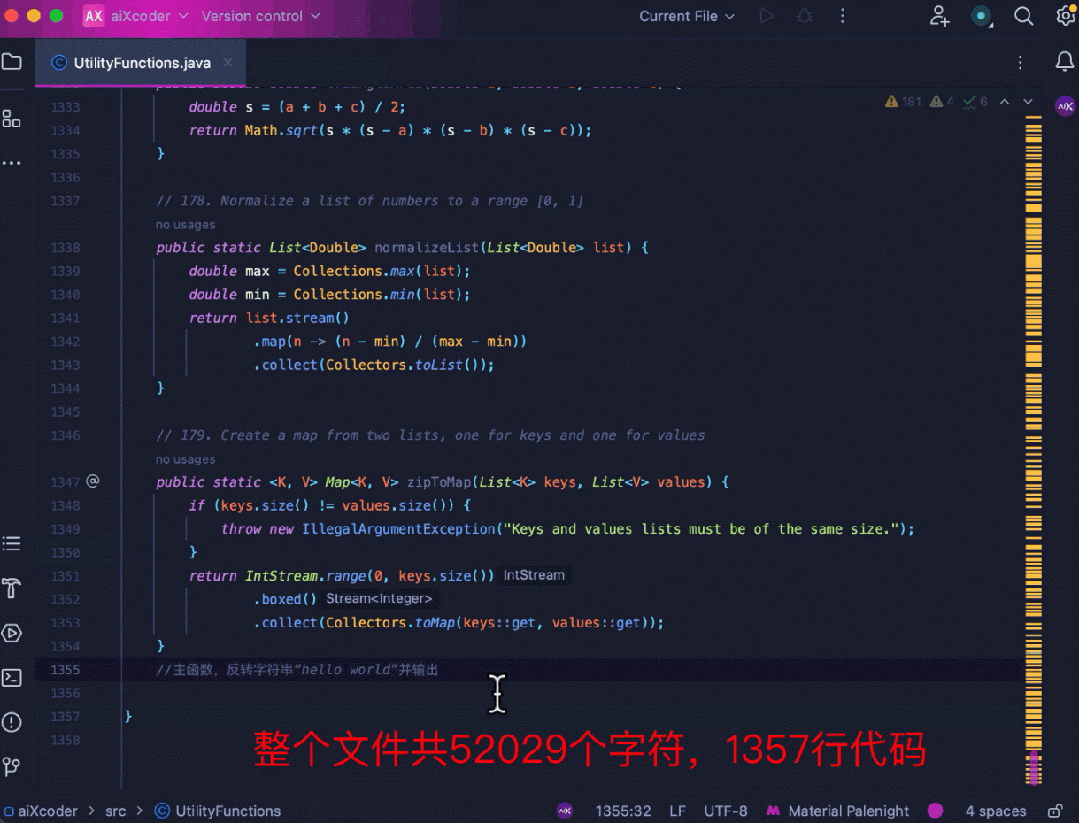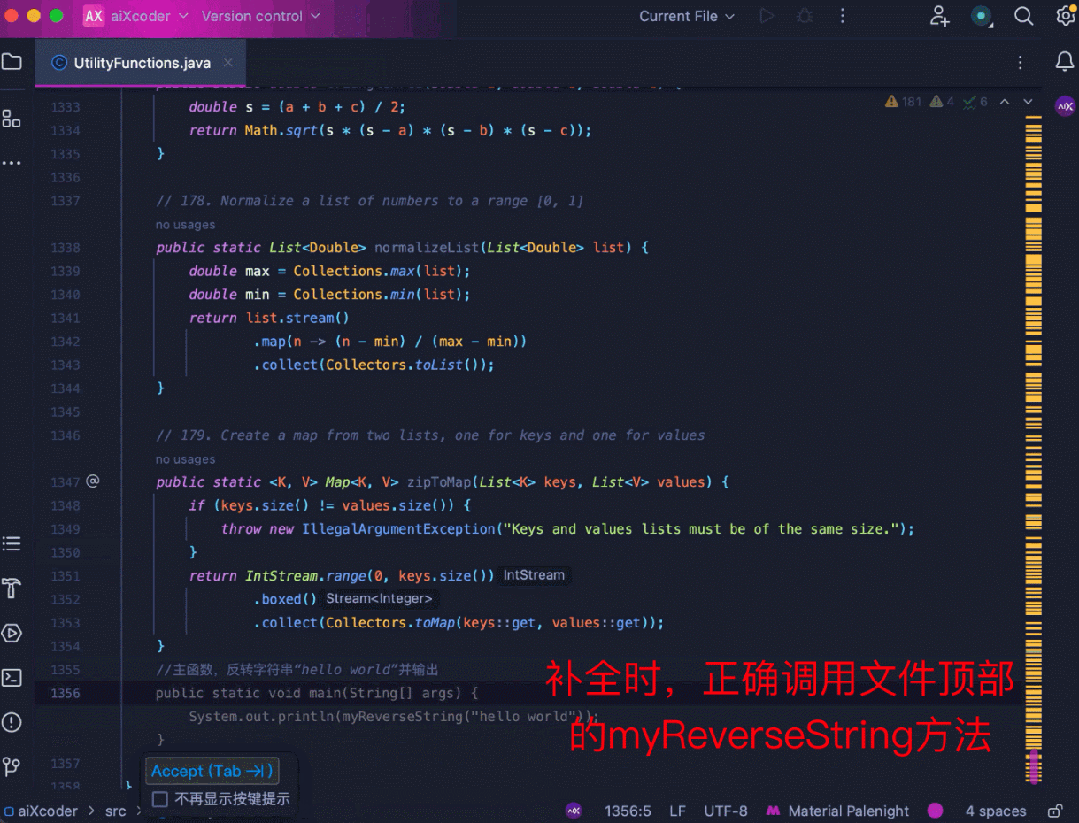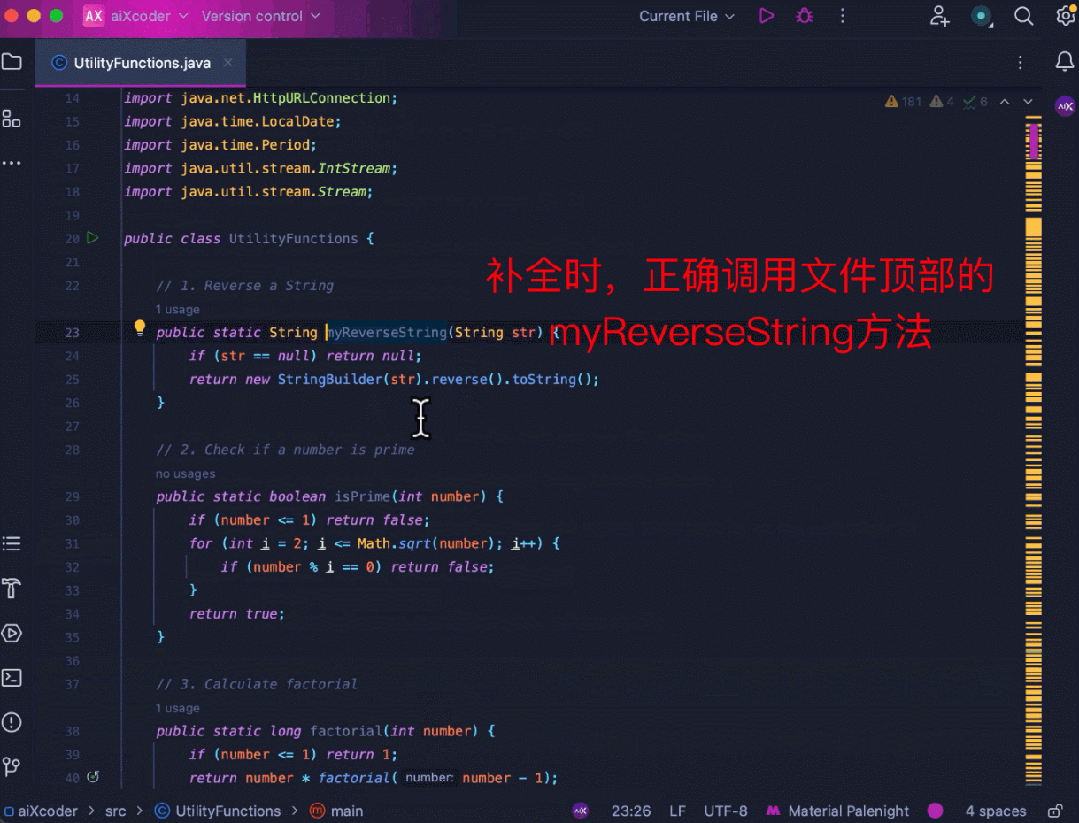
还有以下跨文件补全任务,在树结构上应用动态规划来实现编辑距离搜索。模型补全的代码识别到了编辑距离的计算与另一个文件中滚动数组内部取最小值的计算之间的关系,并给出了正确的预测结果:
当然还可以智能化匹配输出长度。当用户调整自己的采纳内容时,模型能够根据当前的采纳情况自动调整补全长度:
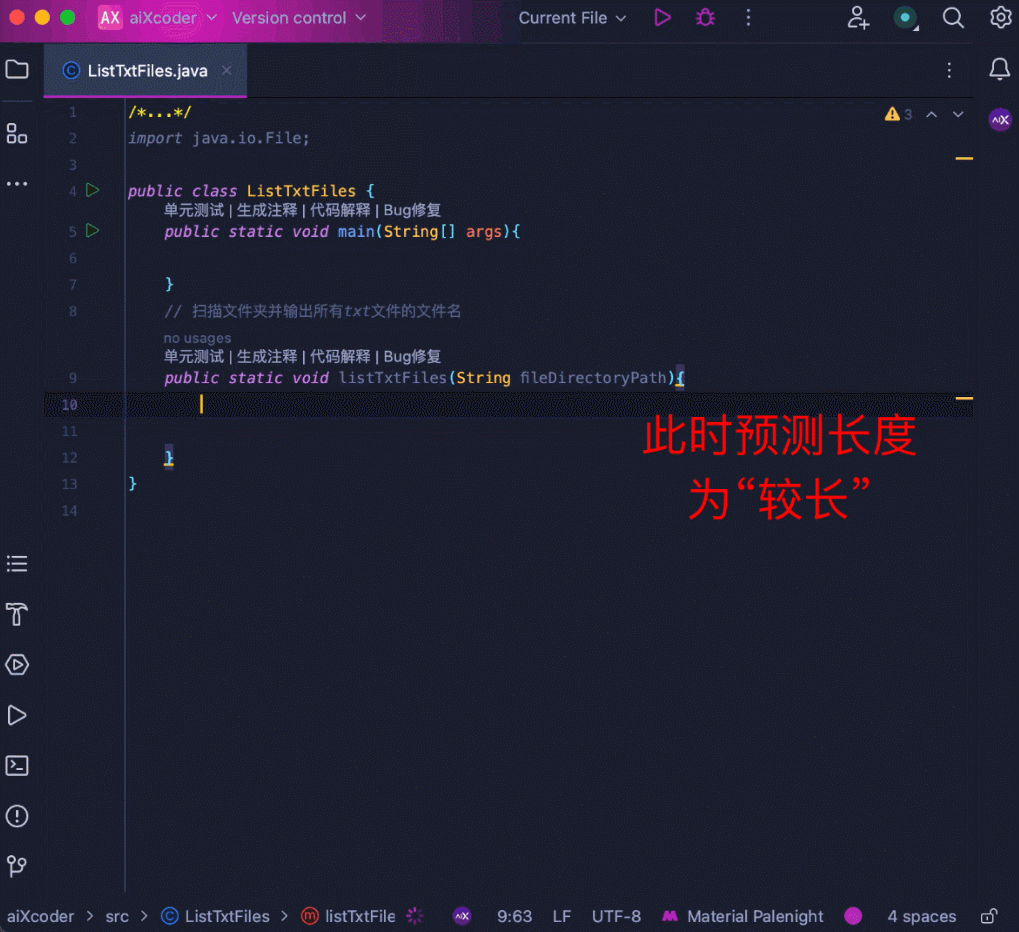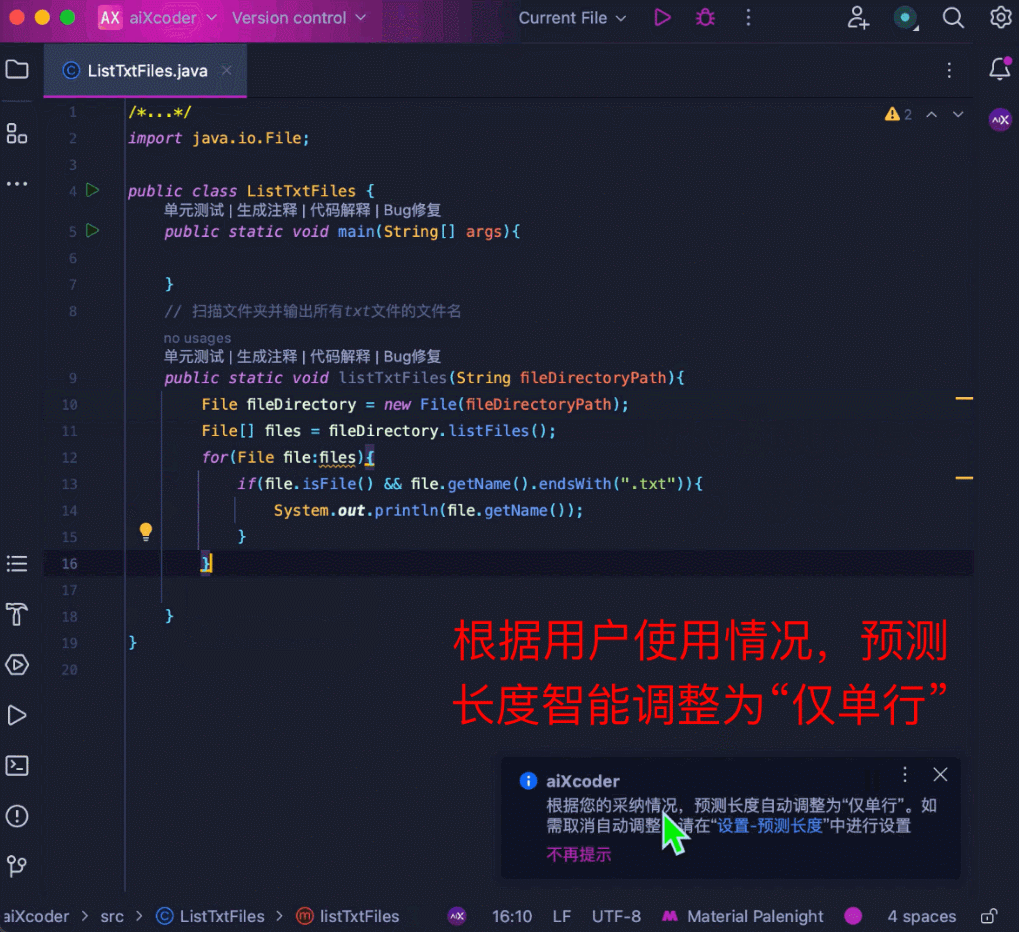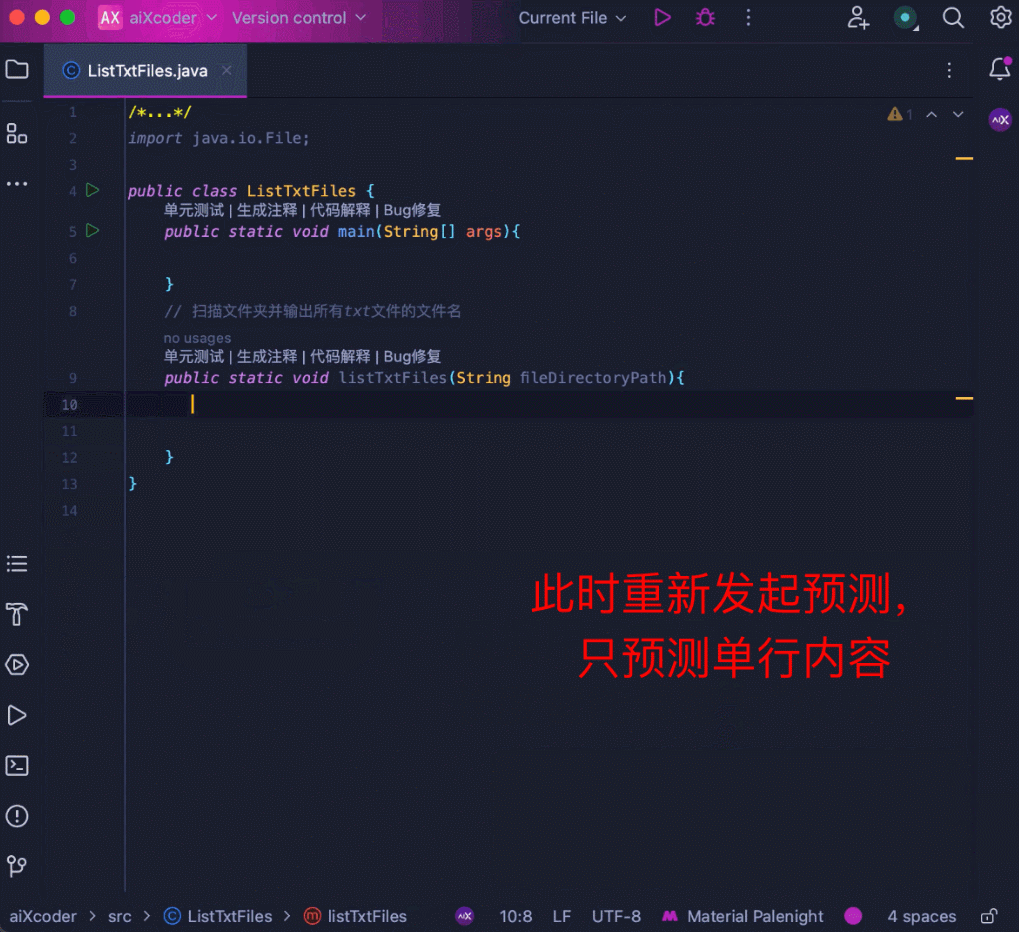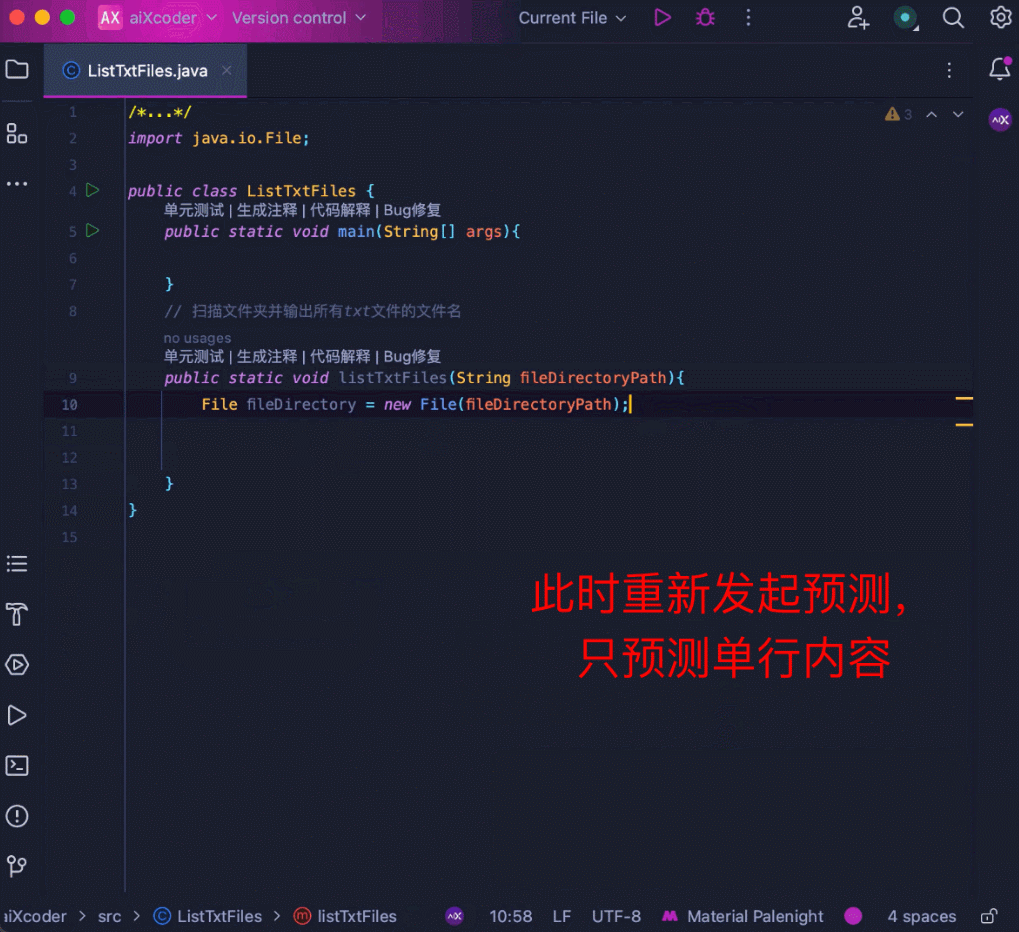
一句话,有了 aiXcoder 7B Base 版代码大模型,无论是代码生成还是补全,程序员多了一个效率提升利器,节省时间,事半功倍。
拼效果,更拼应用
用核心竞争力成为企业首选
我们已经看到,aiXcoder 7B Base 版在代码补全这样的真实开发场景中充分展现了自身的硬实力。不过,对于企业客户来说,代码大模型只是效果好并不能完全打动他们。只有全方位满足自身需求,企业客户才会毫不犹豫地下手。
aiXcoder 7B Base 版正是奔着企业需要、解决他们的个性化需求来的。打造最适合企业应用的代码大模型,成为了 aiXcoder 7B Base 版的首要目标和有别于其他模型的又一核心优势。
当然,想要成为企业应用的最佳选择并不容易,必须围绕着企业业务场景、需求、所能承担的成本等实际情况做深文章。aiXcoder 模型不仅这样做了,而且做到了极致。
简而言之,为了实现企业级个性化的应用落地,aiXcoder 模型在私有化部署、个性化训练和定制化开发三个方面齐发力,打造出了相较于其他代码大模型的核心优势。
首先来看私有化部署。对于企业而言,代码大模型在本地服务器的私有化部署和运行,首要考虑的是自身算力是否可以支撑。在这点上,aiXcoder 模型对企业 GPU 资源要求少,应用成本投入低,让部署模型门槛大大降低。
此外,不同企业拥有的软硬件各异,既会有国产芯片,也会有国外如英伟达显卡。基于此,aiXcoder 模型进行针对性硬件适配以及进一步模型训练和推理优化,比如在信息处理层面采用高速缓存技术,充分满足多样化部署要求。
其次也是 aiXcoder 模型着重强调的个性化训练。我们知道,企业的实际情况不能一概而论,而 aiXcoder 模型做到了见招拆招,提供了「一揽子」的个性化模型训练解决方案。
一方面构建企业专属数据集和测评集,其中数据集构建基于企业代码特征和员工编码习惯,专门对代码及相关文档进行数据预处理;测评集构建则以真实开发场景为准绳,模拟并评估模型在实际应用中的预期效果。
另一方面,将企业代码这一内因与企业算力资源这一外因相结合,充分考虑到不同企业计算资源、代码量的多寡,为他们提供灵活的个性化训练及优化方案,最大化提升专属代码大模型的前期训练效果和后续应用效果。
第三是定制化开发。aiXcoder 模型瞄准不同行业和企业的实际情况,结合企业个性化需求来为他们提供灵活的定制化服务。凭借丰富和成熟的定制开发经验,让基于企业代码和计算资源打造的模型高度契合实际需求,让业务效率的提升看得见摸得着。目前,客户已经遍布银行、证券、保险、军工、运营商、能源、交通等多个行业。
可以看到,相较于其他代码大模型,aiXcoder 能同时为企业提供个性化训练的产品和服务,这在业内是唯一一个。
aiXcoder 开源链接:
https://github.com/aixcoder-plugin/aiXcoder-7B
https://gitee.com/aixcoder-model/aixcoder-7b
https://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
https://wisemodel.cn/codes/aiXcoder/aiXcoder-7b
# Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
Llama架构比不上GPT2?神奇token提升10倍记忆?
一个 7B 规模的语言模型 LLM 能存储多少人类知识?如何量化这一数值?训练时间、模型架构的不同将如何影响这一数值?浮点数压缩 quantization、混合专家模型 MoE、以及数据质量的差异 (百科知识 vs 网络垃圾) 又将对 LLM 的知识容量产生何种影响?
近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。
作者首先指出,通过开源模型在基准数据集 (benchmark) 上的表现来衡量 LLM 的 scaling law 是不现实的。例如,LlaMA-70B 在知识数据集上的表现比 LlaMA-7B 好 30%,这并不能说明模型扩大 10 倍仅仅能在容量上提高 30%。如果使用网络数据训练模型,我们也将很难估计其中包含的知识总量。
再举个例子,我们比较 Mistral 和 Llama 模型的好坏之时,到底是他们的模型架构不同导致的区别,还是他们训练数据的制备不同导致的?
综合以上考量,作者采用了他们《语言模型物理学》系列论文的核心思路,即制造人工合成数据,通过控制数据中知识的数量和类型,来严格调控数据中的知识比特数 (bits)。同时,作者使用不同大小和架构的 LLM 在人工合成数据上进行训练,并给出数学定理,来精确计算训练好的模型从数据中学到了多少比特的知识。
- 论文地址:https://arxiv.org/pdf/2404.05405.pdf
- 论文标题:Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
对于这项研究,有人表示这个方向似乎是合理的。我们可以使用非常科学的方式对scaling law 进行分析。
也有人认为,这项研究将 scaling law 提升到了不同的层次。当然,对于从业者来说是一篇必读论文。
研究概览
作者研究了三种类型的合成数据:bioS、bioR、bioD。bioS 是使用英语模板编写的人物传记,bioR 是由 LlaMA2 模型协助撰写的人物传记(22GB 总量),bioD 则是一种虚拟但可以进一步控制细节的知识数据(譬如可以控制知识的长度、词汇量等等细节)。作者重点研究了基于 GPT2、LlaMA、Mistral 的语言模型架构,其中 GPT2 采用了更新的 Rotary Position Embedding (RoPE) 技术。

左图为训练时间充足,右图为训练时间不足的 scaling laws
上图 1 简要概述了作者提出的前 5 条定律,其中左 / 右分别对应了「训练时间充足」和 「训练时间不足」两种情况,分别对应了常见知识(如中国首都是北京)和较少出现的知识(如清华物理系成立于 1926 年)。
如果训练时间充足,作者发现,不论使用何种模型架构,GPT2 或 LlaMA/Mistral,模型的存储效率均可以达到 2bit/param—— 即平均每个模型参数可以存储 2 比特的信息。这与模型的深度无关,仅与模型大小有关。换言之,一个 7B 大小的模型,如果训练充足,可以存储 14B 比特的知识,这超过了维基百科和所有英文教科书中人类知识的总和!
更令人惊讶的是,尽管传统理论认为 transformer 模型中的知识主要存储在 MLP 层,但作者的研究反驳了这一观点,他们发现即便移除了所有 MLP 层,模型仍能达到 2bit/param 的存储效率。

图 2:训练时间不足情况下的 scaling laws
然而,当我们观察训练时间不足的情况时,模型间的差异就显现出来了。如上图 2 所示,在这种情况下,GPT2 模型能比 LlaMA/Mistral 存储超过 30% 的知识,这意味着几年前的模型在某些方面超越了今天的模型。为什么会这样?作者通过在 LlaMA 模型上进行架构调整,将模型与 GPT2 的每个差异进行增减,最终发现是 GatedMLP 导致了这 30% 的损失。
强调一下,GatedMLP 并不会导致模型的「最终」存储率变化 —— 因为图 1 告诉我们如果训练充足它们就不会有差。但是,GatedMLP 会导致训练不稳定,因此对同样的知识,需要更长的训练时间;换句话说,对于较少出现在训练集里的知识,模型的存储效率就会下降。

图 3:quantization 和 MoE 对模型 scaling laws 的影响
作者的定律 8 和定律 9 分别研究了 quantization 和 MoE 对模型 scaling law 的影响,结论如上图 3 所示。其中一个结果是,将训练好的模型从 float32/16 压缩到 int8,竟然对知识的存储毫无影响,即便对已经达到 2bit/param 存储极限的模型也是如此。
这意味着,LLM 可以达到「信息论极限」的 1/4—— 因为 int8 参数只有 8 比特,但平均每个参数可以存储 2 比特的知识。作者指出,这是一个普遍法则(universal law),和知识的表现形式无关。
最引人注目的结果来自于作者的定律 10-12(见图 4)。如果我们的 (预) 训练数据中,有 1/8 来自高质量知识库(如百度百科),7/8 来自低质量数据(如 common crawl 或论坛对话,甚至是完全随机的垃圾数据)。
那么,低质量数据是否会影响 LLM 对高质量知识的吸收呢?结果令人惊讶,即使对高质量数据的训练时间保持一致,低质量数据的「存在本身」,可能会让模型对高质量知识的存储量下降 20 倍!即便将高质量数据的训练时间延长 3 倍,知识储量仍会降低 3 倍。这就像是将金子丢进沙子里,高质量数据被严重浪费了。
有什么办法修复呢?作者提出了一个简单但极其有效的策略,只需给所有的 (预) 训练数据加上自己的网站域名 token 即可。例如,将 Wiki 百科数据统统加上 wikipedia.org。模型不需要任何先验知识来识别哪些网站上的知识是「金子」,而可以在预训练过程中,自动发现高质量知识的网站,并自动为这些高质量数据腾出存储空间。
作者提出了一个简单的实验来验证:如果高质量数据都加上一个特殊 token(任何特殊 token 都行,模型不需要提前知道是哪个 token),那么模型的知识存储量可以立即回升 10 倍,是不是很神奇?所以说对预训练数据增加域名 token,是一个极其重要的数据制备操作。

图 4:预训练数据「知识质量不齐」情形下的 scaling laws,模型缺陷以及如何修复
结语
作者认为,通过合成数据,计算模型在训练过程中获得的知识总量的方法,可以为「评估模型架构、训练方法和数据制备」提供了一套系统且精确的打分体系。这和传统的 benchmark 比较完全不同,并且更可靠。他们希望这能帮助未来 LLM 的设计者做出更明智的决策。
# 多模态大语言模型综述 ~重大升级
本综述主要围绕 MLLM 的基础形式、拓展延伸以及相关研究课题进行展开,具体包括:MLLM 的基础构成与相关概念、MLLM 的拓展延伸、MLLM 的相关研究课题。
去年 6 月底,我们在 arXiv 上发布了业内首篇多模态大语言模型领域的综述《A Survey on Multimodal Large Language Models》,系统性梳理了多模态大语言模型的进展和发展方向,目前论文引用 120+ ,开源 GitHub 项目获得 8.3K Stars。自论文发布以来,我们收到了很多读者非常宝贵的意见,感谢大家的支持!
- 论文链接:https://arxiv.org/pdf/2306.13549.pdf
- 项目链接(每日更新最新论文):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
去年以来,我们见证了以 GPT-4V 为代表的多模态大语言模型(Multimodal Large Language Model,MLLM)的飞速发展。为此我们对综述进行了重大升级,帮助大家全面了解该领域的发展现状以及潜在的发展方向。

MLLM 发展脉络图
MLLM 脱胎于近年来广受关注的大语言模型(Large Language Model , LLM),在其原有的强大泛化和推理能力基础上,进一步引入了多模态信息处理能力。相比于以往的多模态方法,例如以 CLIP 为代表的判别式,或以 OFA 为代表的生成式,新兴的 MLLM 展现出一些典型的特质:(1)模型大。MLLM 通常具有数十亿的参数量,更多的参数量带来更多的潜力;(2)新的训练范式。为了激活巨大参数量的潜力,MLLM 采用了多模态预训练、多模态指令微调等新的训练范式,与之匹配的是相应的数据集构造方式和评测方法等。在这两种特质的加持下,MLLM 涌现出一些以往多模态模型所不具备的能力,例如给定图片进行 OCRFree 的数学推理、给定图片进行故事创作和理解表情包的深层含义等。
本综述主要围绕 MLLM 的基础形式、拓展延伸以及相关研究课题进行展开,具体包括:
- MLLM 的基础构成与相关概念,包括架构、训练策略、数据和评测;
- MLLM 的拓展延伸,包括输入输出粒度、模态、语言和场景的支持;
- MLLM 的相关研究课题,包括多模态幻觉、多模态上下文学习(Multimodal In-Context Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)、LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)。
架构
对于多模态输入-文本输出的典型 MLLM,其架构一般包括编码器、连接器以及 LLM。如要支持更多模态的输出(如图片、音频、视频),一般需要额外接入生成器,如下图所示:

MLLM 架构图
其中,模态编码器负责将原始的信息(如图片)编码成特征,连接器则进一步将特征处理成LLM 易于理解的形式,即视觉 Token。LLM 则作为“大脑”综合这些信息进行理解和推理,生成回答。目前,三者的参数量并不等同,以 Qwen-VL[1]为例,LLM 作为“大脑”参数量为 7.7B,约占总参数量的 80.2%,视觉编码器次之(1.9B,约占 19.7%),而连接器参数量仅有 0.08B。
对于视觉编码器而言,增大输入图片的分辨率是提升性能的有效方法。一种方式是直接提升分辨率,这种情况下需要放开视觉编码器进行训练以适应更高的分辨率,如 Qwen-VL[1]等。另一种方式是将大分辨率图片切分成多个子图,每个子图以低分辨率送入视觉编码器中,这样可以间接提升输入的分辨率,如 Monkey[2]等工作。
对于预训练的 LLM,常用的包括 LLaMA[3]系列、Qwen[4]系列和 InternLM[5]系列等,前者主要支持英文,而后两者中英双语支持得更好。就性能影响而言,加大 LLM 的参数量可以带来显著的性能增益,如 LLaVA-NeXT[6]等工作在 7B/13B/34B 的 LLM 上进行实验,发现提升LLM 大小可以带来各 benchmark 上的显著提升,在 34B 的模型上更涌现出 zero-shot 的中文能力。除了直接增大 LLM 参数量,近期火热的 MoE 架构则提供了更高效实现的可能性,即通过稀疏计算的方式,在不增大实际计算参数量的前提下提高总的模型参数量。
相对前两者来说,连接器的重要性略低。例如,MM1[7]通过实验发现,连接器的类型不如视觉 token 数量(决定之后 LLM 可用的视觉信息)及图片的分辨率(决定视觉编码器的输入信息量)重要。
数据与训练
MLLM 的训练大致可以划分为预训练阶段、指令微调阶段和对齐微调阶段。预训练阶段主要通过大量配对数据将图片信息对齐到 LLM 的表征空间,即让 LLM 读懂视觉 Token。指令微调阶段则通过多样化的各种类型的任务数据提升模型在下游任务上的性能,以及模型理解和服从指令的能力。对齐微调阶段一般使用强化学习技术使模型对齐人类价值观或某些特定需求(如更少幻觉)。
早期工作在第一阶段主要使用粗粒度的图文对数据,如 LAION-5B,这些数据主要来源于互联网上的图片及其附带的文字说明,因此具有规模大(数 10 亿规模)但噪声多、文本短的特点,容易影响对齐的效果。后来的工作则探索使用更干净、文本内容更丰富的数据做对齐。如 ShareGPT4V[8]使用 GPT-4V 生成的详细描述来做更细粒度的对齐,在一定程度上缓解了对齐不充分的问题,获得了更好的性能。但由于 GPT-4V 是收费的,这种类型的数据规模通常较小(数百万规模)。此外,由于数据规模受限,其包含的世界知识也是有限的,比如是否能够识别出图像中的建筑为广州塔。此类世界知识通常储备于大规模的粗粒度图文对中。
第二阶段的微调数据一方面可以来源于各种任务的数据,如 VQA 数据、OCR 数据等,也可以来源于 GPT-4V 生成的数据,如问答对。虽然后者一般能够生成更复杂、更多样化的指令数据,但这种方式也显著地增加了成本。值得一提的是,第二阶段的训练中一般还会混合部分纯文本的对话数据,这类数据可以视为正则化的手段,保留 LLM 原有的能力与内嵌知识。
第三阶段的数据主要是针对于回答的偏好数据。这类数据通常由人工标注收集,因而成本较高。近期出现一些工作使用自动化的方法对来自不同模型的回复进行偏好排序,如 Silkie[9]通过调用 GPT-4V 来收集偏好数据。
其他技术方向
除了提升模型的基础能力(如支持的输入/输出形式、性能指标)外,还有一些有意思的问题以及待探索的方向。本综述中主要介绍了多模态幻觉、多模态上下文学习(Multimodal InContext Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)和 LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)等。
多模态幻觉的研究主要关注模型生成的回答与图片内容不符的问题。视觉和文本本质上是异构的信息,完全对齐两者本身就具有相当大的挑战。增大图像分辨率和提升训练数据质量是降低多模态幻觉的两种最直观的方式,此外我们仍然需要在原理上探索多模态幻觉的成因和解法。例如,当前的视觉信息的 Token 化方法、多模态对齐的范式、多模态数据和 LLM 存储知识的冲突等对多模态幻觉的影响仍需深入研究。
多模态上下文学习技术为少样本学习方法,旨在使用少量的问答样例提示模型,提升模型的few-shot 性能。提升性能的关键在于让模型有效地关注上下文,并将内在的问题模式泛化到新的问题上。以 Flamingo[10]为代表的工作通过在图文交错的数据上训练来提升模型关注上下文的能力。目前对于多模态上下文学习的研究还比较初步,有待进一步探索。
多模态思维链的基本思想是通过将复杂的问题分解为较简单的子问题,然后分别解决并汇总。相较于纯文本的推理,多模态的推理涉及更多的信息来源和更复杂的逻辑关系,因此要复杂得多。当前该方面的工作也比较少。
LLM 辅助的视觉推理方法探索如何利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。相比于通过端到端训练获得单一模型,这类方法一般关注如何通过免训练的方式扩展和加强 LLM 的能力,从而构建一个综合性的系统。
挑战和未来方向
针对 MLLM 的研究现状,我们进行了深入思考,将挑战与可能的未来发展方向总结如下:
- 现有 MLLM 处理多模态长上下文的能力有限,导致模型在长视频理解、图文交错内容理解等任务中面临巨大挑战。以 Gemini 1.5 Pro 为代表的 MLLM 正在掀起长视频理解的浪潮,而多模态图文交错阅读理解(即长文档中既有图像也有文本)则相对空白,很可能会成为接下来的研究热点。
- MLLM 服从复杂指令的能力不足。例如,GPT-4V 可以理解复杂的指令来生成问答对甚至包含推理信息,但其他模型这方面的能力则明显不足,仍有较大的提升空间。
- MLLM 的上下文学习和思维链研究依然处于初步阶段,相关的能力也较弱,亟需相关底层机制以及能力提升的研究探索。
- 开发基于 MLLM 的智能体是一个研究热点。要实现这类应用,需要全面提升模型的感知、推理和规划能力。
- 安全问题。MLLM 容易受设计的恶意攻击影响,生成有偏的或不良的回答。该方面的相关研究也仍然欠缺。
- 目前 MLLM 在训练时通常都会解冻 LLM,虽然在训练过程中也会加入部分单模态的文本训练数据,但大规模的多模态和单模态数据共同训练时究竟对彼此互有增益还是互相损害仍然缺乏系统深入的研究。
# MobileLLM
Meta 推出 MobileLLM 系列,一款适用于移动设备上的「小」模型。
一个新的模型家族:MobileLLM,SOTA 性能,在一系列 zero-shot 任务中,比之前的 SOTA 125M/350M 模型高出 2.7%/4.3%。
「在移动设备上运行 LLM?可能需要 Meta 的一些技巧。」刚刚,图灵奖得主 Yann LeCun 在个人社交平台表示。
他所宣传的这项研究来自 Meta 最新论文《 MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases 》,在众多作者中也有我们熟悉的来自 Meta FAIR 田渊栋。
田渊栋表示:「我们的 MobileLLM 预训练模型(125M/350M),性能达到 SoTA,特别是在聊天 / API 调用方面表现出色。此外,本工作中的一个有趣研究是跨 Transformer 层的权重共享,这样不仅节省了参数,还减少了推理过程中的延迟。」
论文地址:https://arxiv.org/pdf/2402.14905.pdf
现阶段大语言模型(LLM)已经渗透到人类生活的各个方面,尤其是以 ChatGPT 等为代表的模型,这类研究主要在云环境中运行。
然而领先的模型如 ChatGPT4 的参数量已经超过了 1 万亿。我们设想这样一个场景,这个场景广泛依赖 LLM,不仅用于前端的会话界面,也用于后端操作,如推荐系统,覆盖人类约 5% 的时间。在这一假设场景中,假如以 GPT-4 每秒处理 50 个 token 的速率来计算,则需要部署大约一亿个 H100 GPU,每个 GPU 的计算能力为 60 TFLOPs/s。这种计算规模,还不包括通信和数据传输的开销,就已经与 160 个 Meta 规模的公司相当。随之而来的能源消耗和二氧化碳排放将带来巨大的环境挑战。
本文着眼于大语言模型的延时和开发云成本不断增长的问题,希望探索轻量化且高质量的大语言模型,这里着重强调的是参数量小于 1B 的模型,这种配置也是移动部署中实用的选择。
与强调大模型数据质量和参数量的很多工作普遍强调的点不同,本文的研究着力于模型架构对 1B 参数量级别的 LLM 的重要性。本文提出的模型称为 MobileLLM,它的架构是 Deep and thin 的,且结合了词嵌入的共享和分组查询注意机制,比之前的 125M/350M 最先进的模型获得了显著的 2.7%/4.3% 的准确率提升。
本文最终得到的是一个新的模型家族:MobileLLM,SOTA 性能,在一系列 zero-shot 任务中,比之前的 SOTA 125M/350M 模型高出 2.7%/4.3%。
此外,本文还提出了一种直接的 Block 级别的权重共享方法,不增加模型大小,且延迟开销小幅增加。用这种方法训练的模型 MobileLLM-LS,精度比 MobileLLM 125M/350M 进一步提高了 0.7%/0.8%。此外,MobileLLM 模型家族的性能也有显著的改进,而且在 API 调用任务中的精度也与 LLAMA-v2 7B 很接近,这就证明了小模型对于端侧设备的能力。

图1:MobileLLM 精度与其他模型对比
具体结论
1) 网络架构:
- 与 Scaling Law[1]相反,本文证明了深度比宽度对于小的 LLM 更加重要。一个 deep-and-thin 的模型结构擅长捕捉抽象概念,从而获得更好的最终性能。
- 重新思考了 OPT[2]中提出的 Embedding sharing 方法,并将 Grouped Query Attention[3]实现在小的 LLM 中。
2) 推理策略:
- 本文提出 Block-wise 的权重共享,用于内存移动成为延时瓶颈的情形。两个相邻 Block 之间的权重共享避免了移动权重这样的费时操作,只需要计算同一个 block 两次就可以,这样一来就可以降低延迟的开销。
MobileLLM:优化 1B 参数之下的语言模型
论文名称:MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
论文地址:http://arxiv.org/pdf/2402.14905.pdf
缩小语言模型的规模势在必行
大语言模型 (LLM) 已经渗透到人类生活的各个方面,不仅影响人们交流和工作的方式,还影响日常娱乐体验。领先的 LLM 产品,如 ChatGPT 和 Perplexity AI,主要在云环境中运行。ChatGPT4 等领先模型超过1万亿个参数,那么我们可以设想这样的一个未来的场景:人类在前端对话界面以及后端推荐系统中广泛地依赖于 LLM,它们甚至占据了人们每天时间的约 5%。在这个假设的场景中,以 50 tokens/s 的处理速度使用 GPT-4 需要部署大约 100 万个 算力为 60 TFLOPs/s 的 H100 GPU。这样的计算规模,不包括通信和数据传输开销,就已经与足足160 个 Meta 相当了。随之而来的能源消耗和二氧化碳排放将带来惊人的环境挑战。
因此,最好的解决方案是缩小 LLM 的规模。
此外,在当前的移动技术领域,由于主内存(DRAM)容量的限制,将像 LLaMAv2 7B 这样的 LLM 与 8 位权重整合起来代价过高。移动设备中普遍的内存层结构如图 2 所示。随着 DRAM 容量从 iPhone 15 的 6GB 到 Google Pixel 8 Pro 的 12GB 不等,一个移动应用不应超过 DRAM 的 10%,因为 DRAM 需要与操作系统和其他应用程序共享。这一要求促进了部署小于十亿参数 LLM 更进一步的研究。
而且,对可移植性和计算成本的考虑也推动了在智能手机和移动设备上部署 LLM 的必要性。在现代的移动设备技术中,由于 DRAM 容量的限制,将 LLaMA V2 7B[4]等具有8位权重的 LLM 集成到移动设备中是非常昂贵的。下图2展示了移动设备中流行的内存层次结构。iPhone 15 的 DRAM 容量约 6GB,而 Google Pixel 8 Pro 的约为 12GB。而且,原则是移动应用程序所占的空间不应超过 DRAM 的 10%[5],因为 DRAM 还要放操作系统和其他应用程序。而且 LLM 的能耗也是一个很大的问题:7B 参数的 LLM 的能耗为 0.7 J/token。一个充满电的 iPhone 手机大约有 50kJ 的能量,可以以 10 tokens/s 的速度在对话中使用这个模型 2h,每次生产 64 个 tokens 就会耗掉 0.2% 的电池电量。
这些问题其实都可以归结为我们需要更加紧凑的 LLM 模型来在手机设备上面运行。比如一个参数量为 350M 的 8-bit 模型,仅消耗 0.035 J/token,那么 iPhone 就可以支持其使用一整天。而且,解码速度可以显着增强:比如一个 125M 的模型的解码速度可以达到 50 tokens/s。而最先进的 iPhone App MLC Chat 使用的是 LLaMA 7B 模型,解码速度仅为 3∼6 tokens/s。鉴于这些考虑,本文的动机是设计参数低于 1B 的 LLM 模型。

图2:流行的移动设备中的内存层次结构。尽管有足够的 Flash 存储,但是执行高速应用程序主要依赖于 DRAM,通常限制为 6-12GB 大小
基于上述考量,来自 Meta 的研究者专注于设计参数少于十亿的高质量 LLM,这是在移动端部署 LLM 比较好的解决方案。
与强调数据和参数数量在决定模型质量方面的关键作用的普遍观点相反,Meta 强调了模型架构对少于十亿(sub-billion)规模 LLM 的重要性。
基于深而窄的架构,加上嵌入共享和分组查询注意力机制,Meta 建立了一个强大的基线网络,称为 MobileLLM,与之前的 125M/350M 最先进模型相比,其准确率显著提高了 2.7%/4.3% 。这也说明了与缩放定律(scaling law)相反,该研究证明对于小型 LLM 来说深度比宽度更重要,一个深而窄的模型结构在捕获抽象概念方面更为出色。
此外,Meta 还提出了一种及时逐块权重共享( immediate block-wise weight sharing)方法,该方法不会增加模型大小,所得模型表示为 MobileLLM-LS,其准确率比 MobileLLM 125M/350M 进一步提高了 0.7%/0.8%。此外,在下游任务中,例如 Chat 和 API 调用,MobileLLM 模型家族显著优于同等规模的模型。在 API 调用任务中,与规模较大的 LLaMA-v2 7B 相比,MobileLLM 甚至实现了相媲美的分数。
看到这项研究后,网友纷纷表示「我们应该向 Meta 致敬,很高兴看到这个领域的活跃玩家。该机构通过使用低于 10 亿参数的模型,并且 350M 8 位模型的能源消耗仅为 0.035 J/token ,要是部署在 iPhone 上的话,可以支持用户一整天的会话使用。」优化 1B 参数之下的语言模型的路线图
下面开始介绍从参数量为 1B 以下的 Baseline 的 LLM 到最终模型的整个过程,如图3所示。作者尝试了 125M 和 300M 这两种尺寸的模型,对于一些模型大小是主要限制条件的设备而言,如何高效分配模型的参数非常关键。本文探索的结论可以概括为:
- 采用 SwiGLU FFN。
- 采用 Deep-and-thin 的架构。
- 采用 OPT[2]中提出的 Embedding sharing 方法。
- 采用 Grouped Query Attention[3]。
- 提出 Block 级别的权重共享策略,进一步提高了精度,而且不会产生任何额外的内存开销。
探索实验在 32 A100 GPU 上面进行,训练长度是 120k iterations,文本是 0.25T tokens。评测方法是在零样本常识推理任务上评估,还有问答和阅读理解任务。
改进十亿以下参数规模的 LLM 设计
研究者介绍了从十亿以下参数规模的基线模型到新的 SOTA 模型的演进之路(如下图 3 所示)。他们分别研究了 125M 和 350M 参数规模的模型,并在这两个规模下展示了一致的改进。对于模型尺寸成为主要制约因素的设备用例而言,如何有效地分配有限的权重参数变得比以往更加重要。
研究者首先通过测试四种有益于十亿以下规模 LLM 的模型设计方法,提出了一个名为MobileLLM 的强大基线模型。这四种模型设计方法包括 1)采用 SwiGLU FFN,2)强制使用深和薄的架构,3)重新审视嵌入共享方法,4)利用分组查询注意力。
接下来,研究者开发了一种直接的逐块层共享方法,基于该方法可以进一步提高准确度,而不产生任何额外的内存开销,并在内存有限的 LM 解码过程中产生很小的延迟开销。他们将具有层共享的模型表示为 MobileLLM-LS。

图3:探索实验结果。前景和背景分别代表 125M 和 300M 的模型的 Zero-Shot 的常识推理任务的结果
前馈网络选择
作者首先把原始的 FFN (FC →ReLU → FC) 替换为了 SwiGLU,这使得 125M 模型 Zero-Shot 推理任务的平均性能从 42.6 提高到 43.9。因此,作者以后都使用 SwiGLU 进行实验。
架构宽度和深度
一个普遍存在的认知是 Transformer 模型的性能主要由参数数量、训练数据集的大小和训练迭代次数决定。这个认知假设架构设计对变压器模型的性能的影响是可以忽略不计的。但本文的研究结果表明,这对于较小的模型可能不成立。本文的实验结果,尤其是对于容量有限的小模型,表明深度对于提高模型的性能非常重要。
本文的研究涉及 19 个模型的训练,包括 9 个具有 ∼125M 参数的模型和 10 个具有 ∼350M 参数的模型。每个模型都的设计大小相似,但在深度和宽度方面有所不同。作者在 8 个 Zero-Shot 的尝试推理任务以及问答和阅读理解的基准上进行了实验。实验的结果如下图4所示。更深的模型在大多数 Zero-Shot 的推理任务中都表现出了更加卓越的性能,这些任务包括 ARC-easy、ARC-challenge、PIQA、HellaSwag、OBQA、Winogrande 等。

图4:在相似的模型大小下,更深更薄的模型通常在各种任务中都优于更广泛和更浅的模型,例如零样本常识推理、问答和阅读理解
而且,这种趋势在 TQA 和 RACE 数据集上更为明显,如下图5所示。对于大小为 125M 的 Transformer 模型,具有 30 甚至 42 层的模型比具有 12 层的模型表现得更好。

图5:在相似的模型大小下,更深更薄的模型通常在各种任务中都优于更广泛和更浅的模型,例如零样本常识推理、问答和阅读理解
嵌入层共享
对于一个 1B 规模的语言模型而言,嵌入层 (Embedding Layer) 构成了参数量的很大一部分。对于一个嵌入维度为 512,词汇表大小为 32K 的模型而言,输入和输出的嵌入层各包含 16 万个参数,它们占据了 125M 参数模型规模的 20% 以上。相比之下,在更大的语言模型中,这个比例要低得多:输入和输出的嵌入层仅占 LLaMA-7B 模型中参数量总数的 3.7%,在 LLaMA-70B 模型中仅占 0.7%。
作者在小语言模型设计的工作中,重新回顾了嵌入层共享这一概念:
- LLM 模型的输入嵌入层 (Input Embedding) 的作用是:把一个 token 的 id 映射为一个向量,其维度是:(vocab_size, embedding_dim)。
- LLM 模型的输出嵌入层 (Output Embedding) 的作用是:把一个向量反映射为 token 的 id,以转化成具体的词汇表的 logit 预测结果,其维度是:(vocab_size, embedding_dim)。
通过输入嵌入和输出嵌入层的权重共享,就可以得到更加高效和紧凑的模型架构。
作者在一个 30 层的大小为 125M 的模型上面进行了实验,结果如图6所示。可以看到输入和输出嵌入层的权重共享将参数量减少了 16M,占总参数量的 11.8%,而平均精度仅仅下降了 0.2。这个极小的精度下降我们可以通过额外加一些层来弥补。与原始的 135M 的模型相比,把层数增加至 24 可以带来约 0.4 的精度增益。在 350M 量级的模型里面仍然可以观察到类似的结果。这些发现也进一步表明,在给定有限的模型存储预算的前提下,可以通过权重共享来最大化权重的利用效率以提升模型性能。

图6:使用 512 嵌入维度的 30 层模型进行输入输出嵌入共享的消融实验结果,任务是 Zero-Shot 的常识推理任务
Heads 的数量


图7:Heads 数量和 kv-heads 数量的消融实验结果
这一步得到的模型称之为 MobileLLM。
作者探索了 125M 和 300M 两种大小的 Transformer 模型的最优 Head 数量,实验结果如图7所示。可以看到使用 16 个 query heads 获得的结果是最好的。而且,把 kv-heads 的数量从 16 个减少到 4 个不影响 125M 模型的性能,且只会使得 300M 模型的性能轻微下降 0.2,但却能够带来 10% 的参数量削减。通过使用 Grouped Query Attention,同时适当增加模型宽度以维持参数量,使得 125M 大小模型的精度进一步提升了 0.4。
训练设置
研究者在 32 个 A100 GPU 上进行实验,其中每个 GPU 的批大小为 32。他们在 0.25T 的 tokens 上执行了 120k 次迭代的探索性实验。下文中表 3 和表 4 报告了在 1T 的 tokens 上执行 480k 次迭代训练的 top 模型。
层共享
关于层深度与宽度影响的研究结果表明,更深的层有利于小型 transformer 模型。这促使本文研究层共享作为增加隐藏层数量而不增加存储成本的策略。这种方法在模型大小成为主要制约因素的场景中尤其有用。
令人惊讶的是,实验结果表明,通过简单地复制 transformer 块就可以提高准确度而无需任何架构修改或扩大模型尺寸。研究者进一步探究三种不同的权重共享策略,具体如下图 6 所示。

下表 2 结果表明,重复层共享策略在立即块重复、全面重复(repeat all-over)和反向共享策略中产生了最佳性能。

不过,考虑到硬件内存的层级结构(如图 2),用于计算的 SRAM 通常限制在了 20M 左右。该容量通常仅够容纳单个 transformer 块。因此,将共享权重放入缓存中并立即计算两次则无需在 SRAM 和 DRAM 之间传输权重,提高了自回归推理的整体执行速度。
研究者在模型设计中选择了直接的分块共享策略,并将提出的带有层共享的模型表示为 MobileLLM-LS。
实验结果
该研究进行实验比较了模型在零样本(zero-shot)常识推理任务、问答和阅读理解任务上的性能。
零样本常识推理任务的实验结果如下表 3 所示:


在问答和阅读理解任务上,该研究采用 TQA 问答基准和 RACE 阅读理解基准来评估预训练模型,实验结果如下表 4 所示:

为了验证将模型用于设备上应用程序的有效性,该研究评估了模型在两个关键任务上的性能:聊天和 API 调用。
针对聊天任务,该研究在两个基准上进行了评估实验:AlpacaEval(单轮聊天基准)和 MT-Bench(多轮聊天基准),实验结果如下表 5 所示:

在 API 调用方面,如下表 6 所示,MobileLLM-350M 表现出与 LLaMA-v2 7B 相当的 EM_intent 和 EM_structure,其中 EM_intent 越高,表明模型对用户计划调用 API 的预测就越准确,而 EM_structure 反映了预测 API 函数内内容的熟练程度。

该研究进一步在 MobileLLM 和 MobileLLM-LS 模型上针对每个 token 进行最小 / 最大训练后量化 (PTQ) 实验,模型大小分别为 125M 和 350M,在 0.25T token 上进行训练,实验结果如下图 7 所示:

# Contrastive Preference Learning (CPL)
我们知道,ChatGPT 的成功离不开 RLHF 这个「秘密武器」。不过 RLHF 并不是完美无缺的,存在难以处理的优化难题。本文中,斯坦福大学等研究机构的团队探索用「对比偏好学习」替换掉「强化学习」,在速度和性能上都有不俗的表现。需强化学习即可从人类反馈中学习
在模型与人类意图对齐方面,根据人类反馈的强化学习(RLHF)已经成为一大流行范式。通常来说,RLHF 算法的工作过程分为两个阶段:一、使用人类偏好学习一个奖励函数;二、通过使用强化学习优化所学习的奖励来对齐模型。
RLHF 范式假定人类偏好的分布遵照奖励,但近期有研究认为情况并非如此,人类偏好其实遵循用户最优策略下的后悔值(regret)。因此,根据反馈学习奖励函数不仅基于一个有漏洞的对于人类偏好的假设,而且还会导致出现难以处理的优化难题 —— 这些难题来自强化学习阶段的策略梯度或 bootstrapping。
由于存在这些优化难题,当今的 RLHF 方法都会将自身限定在基于上下文的 bandit 设置中(比如在大型语言模型中)或会限制自己的观察维度(比如基于状态的机器人技术)。
为了克服这些难题,斯坦福等多所大学的一个研究团队提出了一系列新算法,可使用基于后悔的人类偏好模型来优化采用人类反馈时的行为,而没有采用社区广泛接受的仅考虑奖励总和的部分回报模型。不同于部分回报模型,基于后悔的模型可直接提供有关最优策略的信息。
这样一种机制带来了一个幸运的结果:完全不需要强化学习了!
这样一来,就能在具有高维状态和动作空间的通用型 MDP 框架中来解决 RLHF 问题了。
研究者提出,他们这项研究成果的核心见解是:将基于后悔的偏好框架与最大熵(MaxEnt)原理结合起来,可得到优势函数与策略之间的双射。通过将对优势的优化换成对策略的优化,可以推导出一个纯监督学习的目标,其最优值为专家奖励下的最优策略。该团队将这种方法命名为对比偏好学习(Contrastive Preference Learning/CPL),因为其类似于人们广为接受的对比学习目标。
- 论文地址:https://arxiv.org/pdf/2310.13639.pdf
- 代码地址:https://github.com/jhejna/cpl
相比于之前的方法,CPL 有三大关键优势。
一、CPL 能像监督学习一样扩展,因为它只使用监督式目标来匹配最优优势,而无需使用任何策略梯度或动态规划。
二、CPL 是完全离策略的方法,因此其可有效使用任何离线的次优数据源。
三、CPL 可应用于任意马尔可夫决策过程(MDP),使其可以从序列数据上的偏好查询中学习。
该团队表示,之前的 RLHF 方法都无法同时满足以上三点。为了表明 CPL 方法符合以上三点描述,研究者进行了实验,结果表明该方法确实能有效应对带有次优和高维离策略数据的序列决策问题。
值得注意的是,他们在实验中发现:在 MetaWorld 基准上,CPL 竟能有效地使用与对话模型一样的 RLHF 微调流程来学习在时间上扩展的操作策略。
具体来说,他们使用监督学习方法,在高维图像观察上对策略进行预训练,然后使用偏好来对其进行微调。无需动态规划或策略梯度,CPL 就能达到与基于先验式强化学习的方法一样的性能表现。与此同时,CPL 方法要快 1.6 倍,参数效率也提高了四倍。当使用更密集的偏好数据时,CPL 的性能表现在 6 项任务的 5 项上超越了强化学习。
对比偏好学习
这种方法的核心思想很简单:研究者发现,当使用最大熵强化学习框架时,后悔偏好模型中使用的优势函数可被轻松替换成策略的对数概率。但是,这种简单的替换能带来巨大的好处。如果使用策略的对数概率,就不需要学习优势函数或应付与类强化学习算法相关的优化难题了。
研究者表示,这不仅能造就对齐更紧密的后悔偏好模型,还能完全依靠监督学习来学习人类反馈。
下面首先将推导 CPL 目标,并表明对于带有无界数据的专家用户奖励函数 r_E,该方法可以收敛到最优策略。然后将说明 CPL 与其它监督学习方法的联系。最后,研究者将说明如何在实践中使用 CPL。他们表示,这些算法属于一个用于解决序列决策问题的新方法类别,这类方法非常高效,因为它能直接从基于后悔的偏好中学习出策略,而无需强化学习。

从最优优势到最优策略
在使用后悔偏好模型时,偏好数据集 D_pref 包含有关最优优势函数 A^∗ (s, a) 的信息。我们可以直观地认为,该函数度量的是一个给定动作 a 比最优策略在状态 s 时生成的动作的糟糕程度。
因此根据定义,最大化最优优势的动作就是最优动作,并且从偏好学习最优优势函数应该让人能直观地提取出最优策略。
具体而言,该团队证明了以下定理:

直接学习策略的好处。以这种方式直接学习 π 有诸多实践和理论上的好处。其中最明显的可能是:直接学习策略的话,就无需学习其它任何函数了,比如奖励函数或价值函数。这使得 CPL 比之前的方法简单很多。
与对比学习的联系。CPL 方法直接使用一个对比目标来进行策略学习。研究者表示,鉴于对比学习目标已经在大型数据集和神经网络方面取得了有目共睹的成功,因此他们预计 CPL 能比使用传统强化学习算法的强化学习方法进行更好的扩展。
实践方面需要考虑的问题
对比偏好学习框架提供了一个通用的损失函数,可用于从基于优势的偏好中学习策略,基于此可以派生出许多算法。下面将基于一个实践效果很好的特定 CPL 框架实例介绍实践方面需要考虑的问题。
使用有限离线数据的 CPL。尽管 CPL 可通过无界偏好数据收敛到最优策略,但实际上我们通常关心的是学习有限离线数据集。在这种设置下,外推到数据集支持之外太远的策略表现很差,因为它们采取的动作会导致出现分布之外的状态。
正则化。在有限设置中,我们希望选择能最小化 CPL 损失函数的策略,同时为该数据集中的动作赋予更高的可能性。为了做到这一点,研究者使用一个保守的正则化器得到了以下损失函数:当策略在 D_pref 中的动作上有更高的可能性时,就分配更低的损失,从而保证其在分布内。

预训练。该团队发现,如果使用行为克隆(BC)方法对策略 π_θ 进行预训练,往往能得到更优的结果。因此,在通过 CPL 损失使用偏好来进行微调之前,该团队使用了标准的最大似然行为克隆目标来训练策略,即:

实验及结果
这一节将解答以下有关 CPL 的问题:一、CPL 能否有效地根据基于后悔的偏好来微调策略?二、CPL 能否扩展用于高维控制问题和更大的网络?三、CPL 的哪些组件对于获得高性能很重要?
偏好数据。使用次优的离策略 rollout 数据和偏好,研究者评估了 CPL 为一般性 MDP 学习策略的能力。
基准方法。实验中考虑了三种基准方法:监督式微调(SFT)、偏好隐式 Q 学习(P-IQL)、% BC(通过对 rollout 的 top X% 进行行为克隆来训练策略)。
CPL 表现如何?
使用基于状态的观察数据时,CPL 表现如何?对于基于状态的实验结果,主要可见表 1 的第 1 和 3 行。
当使用更稀疏的比较数据时(第 3 行),CPL 在 6 个环境中的 5 个上都优于之前的方法,并且相比于 P-IQL 的优势大都很明显,尤其是 Button Press、Bin Picking 和 Sweep Into 环境。当应用于具有更密集比较的数据集时,CPL 比 P-IQL 的优势还要更大(第 1 行),并且在所有环境上都很显著。

CPL 如何扩展用于高维观察数据?为了测试 CPL 的监督目标能否扩展用于高维连续控制问题,该团队将 MetaWorld 数据集渲染成了 64 × 64 的图像。
表 1 的第 2 和 4 行给出了基于图像的实验结果。他们得到了有趣的发现:对 SFT 来说,性能表现略有提升,但 P-IQL 的提升却很明显。当学习更密集的偏好数据时(第 2 行),CPL 仍旧在 6 个环境中的 4 个上优于 P-IQL,在 Sweep Into 上两者相当。当学习更稀疏的比较数据时(第 4 行),CPL 和 P-IQL 在大多数任务上都表现相当。
考虑到 CPL 有明显更低的复杂性,这样的结果就更惊人了!P-IQL 必须学习一个奖励函数、一个 Q 函数、一个价值函数和一个策略。CPL 则都不需要,它只需学习一个策略,这能极大减少训练时间和参数数量。
正如下表 2 所示,在图像任务上,CPL 的运行速度比 P-IQL 快 1.62 倍,并且参数数量还不到 P-IQL 的四分之一。随着网络越来越大,使用 CPL 所带来的性能增益只会有增无减。

哪些组件有助于 CPL 的性能表现?
从实验结果可以看到,当使用有更密集比较的数据集时,CPL 和基准方法之间的差距会更大。这与之前在对比学习方面的研究成果一致。
为了研究这种效果,研究者基于一个包含 5000 个片段的固定大小的数据集,通过增加每个片段采样的比较数量,对 CPL 的性能进行了评估。下图 2 给出了在基于状态的观察数据的开抽屉(Drawer Open)任务上的结果。
整体上看,当每片段采样的比较数量增加时,CPL 都能从中受益,仅有 Plate Slide 任务例外。

最后,该团队也对 CPL 的超参数(温度值 α 和偏差正则化器 λ)进行了消融研究;该研究也基于开抽屉任务,结果见图 2 右侧。尽管 CPL 使用这些值的表现已经很好了,但实验发现通过适当调整超参数(尤其是 λ),其表现还能更好。
# RLHF~
LLM成功不可或缺的基石:RLHF及其替代技术,关于训练大模型常用的 RLHF 技术,这篇文章帮你逐步解读了其工作过程,还总结了一些其他替代方法。
在讨论 LLM 时,我们总是会涉及一个名为「使用人类反馈的强化学习(RLHF)」的过程。RLHF 是现代 LLM 训练流程中不可或缺的一部分,因为它可以将人类偏好整合到优化图景中,从而提升模型的有用性和安全性。
在这篇文章中,机器学习和 AI 研究者 Sebastian Raschka 将逐步解读 RLHF 的工作过程,以帮助读者理解其核心思想和重要性。这篇文章也会比较 ChatGPT 和 Llama 2 执行 RLHF 的方式。
文章最后还将简单介绍一些最近出现的可替代 RLHF 的技术。
本文的目录如下:
- 使用人类反馈的强化学习(RLHF)
- Llama 2 中的 RLHF
- RLHF 的替代技术
典型的 LLM 训练流程
ChatGPT 或 Llama 2 等基于 transformer 的现代 LLM 的训练流程一般分为三大步骤:
- 预训练;
- 监督式微调;
- 对齐。
在最初的预训练阶段,模型会从海量的无标签文本数据集中吸收知识。后续的监督式微调阶段会对这些模型进行微调,使之能更好地遵守特定指令。最后的对齐阶段则是对 LLM 进行打磨,使之在响应用户 prompt 时能给出更有用且更安全的结果。
请注意,这个训练流程基于 OpenAI 的 InstructGPT 论文《Training language models to follow instructions with human feedback》,该论文详述了 GPT-3 的训练过程。人们普遍认为 ChatGPT 的训练也使用了此种方法。后面我们还会比较一下该方法与 Meta 最新的 Llama 2 所采用的方法。
首先从最初的预训练步骤开始吧,如下图所示。

LLM 的预训练步骤
预训练通常需要使用一个超大型的文本语料库,其中包含数十亿乃至数万亿 token。预训练阶段的训练任务很简单直接,就是根据前文预测下一个词。
值得强调的一点是,这种类型的预训练让我们可以利用大型的无标注数据集。只要我们能够在不侵犯版权或无视创作者偏好的情况下使用数据,我们就可以使用大型数据集,而无需人来手动标记。事实上,在这个预训练步骤中,其「标签」就是文本中的后一个词,而这本身就已经是数据集的一部分了(因此,这种预训练方法通常被称为自监督学习)。
接下来的步骤是监督式微调,其过程如下图所示。

根据指令数据对预训练后的模型进行微调
监督式微调阶段涉及到另一轮对下一 token 的预测。但是,不同于之前的预训练阶段,模型现在处理的是成对的「指令 - 输出」,如上图所示。在这里,指令是指提供给模型的输入(根据任务的不同,指令中有时候会带有可选的输入文本)。输出则是模型给出的接近我们期望的响应。
这里给出一个具体示例,对于下面这一对「指令 - 输出」:
指令:"Write a limerick about a pelican."
输出:"There once was a pelican so fine..."
模型将指令文本(Write a limerick about a pelican)作为输入,执行下一 token 预测获得输出文本(There once was a pelican so fine...)。
尽管预测下一 token 这个训练目标是相似的,但监督式微调使用的数据集通常比预训练所用的小得多。这是因为它需要的是指令 - 输出对,而不只是原始文本。为了构建这样一个数据集,必需有一个人类(或另一个高质量 LLM)来根据给定指令写出所需输出 —— 创建这样一个数据集非常费力。
在这个监督式微调阶段之后,还有另一个微调阶段,该阶段通常被称为「对齐」步骤,其主要目标是将 LLM 与人类偏好对齐。这就是 RLHF 的用武之地。

对齐,右侧图表来自 InstructGPT 论文
下一节将深入介绍基于 RLHF 的对齐步骤。但是,如果你想对比一下其与预训练的基础模型和步骤 2 的监督式微调,可以看看来自 InstructGPT 论文的上图。
上图比较了经过监督式微调后的以及使用其它方法的 GPT-3 模型(1750 亿参数)。图中最下方是基础 GPT-3 模型。
可以看到,如果采用 prompt 工程设计方法,即多次查询并选取其中的最佳响应(GPT-3 + prompting),则能获得比基础模型更好的表现,这符合我们的预期。
而如果将监督式微调用于 GPT-3 基础模型,则还能取得甚至更优的表现(GPT-3 + supervised finetuning)。
但是,这里表现最佳的还是使用了监督式微调及 RLHF 的 GPT-3 模型(GPT-3 + supervised finetuning + RLHF)—— 即图中最上面的两条线。(注意,这里之所以有两条线,是因为研究者实验了两种不同的采样方法。)
下面将更详细地介绍 RLHF 步骤。
使用人类反馈的强化学习(RLHF)
前一节讨论了 ChatGPT 和 Llama-2-chat 等现代 LLM 背后的三步式训练流程。这一节将更为详细地描述微调阶段,并重点关注 RLHF 部分。
RLHF 工作流程是通过一种监督式的方式来对预训练模型进行微调(前一节的第 2 步),然后再通过近端策略优化(PPO)来对齐它(前一节的第 3 步)。
为了简单起见,我们可将 RLHF 工作流程再分为三步:
- RLHF 第 1 步:对预训练模型进行监督式微调;
- RLHF 第 2 步:创建一个奖励模型;
- RLHF 第 3 步:通过近端策略优化进行微调。
如下所示,RLHF 第 1 步是监督式微调步骤,目的是创建用于进一步 RLHF 微调的基础模型。

RLHF 第 1 步,图片来自 InstructGPT 论文
在 RLHF 第 1 步,我们创建或采样 prompt(比如从一个数据库中采样),然后让人类编写质量优良的响应。然后使用这个数据集通过一种监督式方式来微调预训练模型。
要注意,RLHF 第 1 步类似于前一节的第 2 步,即「典型的 LLM 训练流程」。这里再次列出它,因为这是 RLHF 不可或缺的一部分。
然后在 RLHF 第 2 步,使用经过监督式微调的模型创建一个奖励模型,如下所示。

RLHF 第 2 步,图片来自 InstructGPT 论文
如上图所示,用上一步中创建的已微调 LLM 为每个 prompt 生成 4-9 个响应。然后再让人基于自己的偏好对这些响应进行排名。尽管这个排名过程非常耗时,但相比于创建用于监督式微调的数据集,其劳动力密集程度可能要低一些。这是因为对响应进行排名多半比编写响应更简单。
然后基于使用这些排名构建的数据集,我们可以设计一个奖励模型,其输出的是用于 RLHF 第 3 步后续优化阶段的奖励分数。这个奖励模型通常源自之前的监督式微调步骤创建的 LLM。下面将奖励模型简称为 RM,将经过监督式微调后的 LLM 简称为 SFT。为了将 RLHF 第 1 步的模型变成奖励模型,需要将其输出层(下一 token 分类层)替换成一个回归层,其具有单个输出节点。
RLHF 工作流程的第 3 步是使用这个奖励模型(RM)来微调之前监督式微调的模型(SFT),如下图所示。

RLHF 第 3 步,图片来自 InstructGPT 论文
在 RLHF 第 3 步,这也是最后一步,需要根据 RLHF 第 2 步创建的 RM 的奖励分数,使用近端策略优化(PPO)来更新 SFT 模型。
有关 PPO 的更多细节超出了本文的范围,但感兴趣的读者可以在 InstructGPT 论文之前的这四篇论文中找到相关数学细节:
(1) 《Asynchronous Methods for Deep Reinforcement Learning》引入了策略梯度方法来替代基于深度学习的强化学习中的 Q 学习。
(2) 《Proximal Policy Optimization Algorithms》提出了一种基于修改版近端策略的强化学习流程,其数据效率和可扩展性均优于上面的基础版策略优化算法。
(3) 《Fine-Tuning Language Models from Human Preferences》阐释了 PPO 的概念以及对预训练语言模型的奖励学习,包括 KL 正则化,以防止策略偏离自然语言太远。
(4) 《Learning to Summarize from Human Feedback》引入了现在常用的 RLHF 三步流程,后来的 InstructGPT 论文也使用了该流程。
Llama 2 中的 RLHF
上一节介绍了 OpenAI 的 InstructGPT 论文中描述的 RLHF 流程。人们也普遍相信 ChatGPT 的开发中也使用了该流程。但它与 Meta AI 最新的 Llama 2 模型相比如何呢?
Meta AI 在创造 Llama-2-chat 模型时也使用了 RLHF。尽管如此,这两种方法之间还是有些差异,如下图所示。

两种 RLHF 的差异,图片改编自 Llama-2 论文
总结起来,Llama-2-chat 遵循与 InstructGPT 的 RLHF 第 1 步相同的基于指令数据的监督式微调步骤。然而,在 RLHF 第 2 步,Llama-2-chat 是创建两个奖励模型,而不是一个。此外,Llama-2-chat 模型会经历多个演进阶段,奖励模型也会根据 Llama-2-chat 中涌现的错误而获得更新。它还有一个额外的拒绝采样步骤。
边际损失
还有另一个区别未在上图中给出,其涉及到生成奖励模型时对模型响应排序的方式。在之前讨论的 InstructGPT 所用的标准 RLHF PPO 中,研究者会根据自己创建的「k 选 2」比较方法来收集排名 4-9 的输出响应。
举个例子,如果一位人类标注者要对 4 个响应(A-D)进行排名,比如 A < C < D < B,这会有「4 选 2」=6 次比较。
- A < C
- A < D
- A < B
- C < D
- C < B
- D < B
类似地,Llama 2 的数据集基于对响应的二元比较,例如 A < B。然而,每位人类标记者在每轮标记时仅会比较 2 个响应(而不是 4-9 个响应)。
此外,Llama 2 方法的另一个不同之处是在每次二元排名时会收集一个「边际」标签(范围从「优势显著」到「优势可忽略」),这可以通过一个附加的边际参数被用于二元排名损失(可选)以计算两个响应之间的差距。
在训练奖励模型方面,InstructGPT 使用的是以下基于交叉熵的排名损失:

其中:
- r_θ(x,y) 是对于 prompt x 和生成的响应 y 的标量分数输出;
- θ 是模型权重;
- σ 是 logistic sigmoid 函数,作用是把层输出转换为 0 到 1 之间的分数;
- y_c 是人类标注者选择的偏好响应;
- y_r 是人类标注者选择的被拒响应。
举个例子,通过 m (r) 返回一个更高的边际量会让偏好响应和被拒响应的奖励之差更小,这会让损失更大,又进一步导致梯度更大,最终导致模型在策略梯度更新过程中发生变化。
两个奖励模型
如前所述,Llama 2 中有两个奖励模型,而不是一个。一个奖励模型基于有用性,另一个则是基于安全性。而用于模型优化的最终奖励函数是这两个分数的一种线性组合。

Llama 2 的排名方法和奖励模型创建,改编自 InstructGPT 论文的图片
拒绝采样
此外,Llama 2 的作者还采用了一种可以迭代式产生多个 RLHF 模型(从 RLHF-V1 到 RLHF-V5)的训练流程。他们没有仅仅依赖于之前讨论的使用 PPO 方法的 RLHF,而是使用了两种用于 RLHF 微调的算法:PPO 和拒绝采样(rejection sampling。
在拒绝采样中,会先抽取 K 个输出,然后在优化步骤选取其中奖励最高那个用于梯度更新,如下图所示。

Llama 2 的拒绝采样步骤,即创建多个响应然后选取其中奖励最高的那个,改编自 InstructGPT 论文的图片
拒绝采样的作用是在每次迭代中选取奖励分数高的样本。由此造成的结果是,模型可以使用奖励更高的样本进行微调,相比之下,PPO 每次只能基于一个样本进行更新。
在经过监督式微调的最初阶段后,再专门使用拒绝采样训练模型,之后再将拒绝采样和 PPO 组合起来。
研究者绘出了随 RLHF 各阶段的模型性能变化情况,可以看到经过 RLHF 微调的模型在安全性和有用性方面都有提升。

RLHF 确实有效,改编自 Llama 2 论文的图片
请注意,研究者在最后一步中使用了 PPO,之前则是用拒绝采样更新过的模型。对比图中 RLHF-v5 (with PPO) 和 RLHF-v5 (no PPO) 的位置可以看到,如果在拒绝采样之后的最后阶段使用 PPO,模型的表现会更好一些。
RLHF 的替代技术
现在我们已经讨论并定义了 RLHF 过程,这个过程相当复杂,人们可能会问这么麻烦是否值得。前文中来自 InstructGPT 和 Llama 2 论文的图表(下面再次给出)证明 RLHF 值得这样麻烦。

但是,有很多研究关注的重点是开发更高效的替代技术。其中最有趣的方法总结如下。
论文 1:《Constitutional AI: Harmlessness from AI Feedback》
论文地址:https://arxiv.org/abs/2212.08073
在这篇 Constitutional AI 论文中,作者提出了一种自训练机制,其基于人类提供的规则列表。类似于之前提到的 InstructGPT 论文,这里提出的方法也使用了一种强化学习。

来自 Constitutional AI 论文
上图中的「red teaming(红队)」这一术语指的是一种源于冷战军事演习的测试方法,原本是指扮演苏联角色的演习队伍,用于测试美国的战略和防御能力。
在 AI 研究的网络安全语境中,红队现在描述的是这样一个过程:外部或内部的专家模仿潜在的对手,通过模仿真实世界攻击者的战术、技术和工作流程来挑战、测试并最终提升给定的相关系统。
论文 2:《The Wisdom of Hindsight Makes Language Models Better Instruction Followers》
论文地址:https://arxiv.org/abs/2302.05206
这篇论文用于 LLM 微调的监督式方法实际上可以发挥出很好的效果。这里,研究者提出了一种基于重新标注的监督式微调方法,其在 12 个 BigBench 任务上的表现优于 RLHF。
这种新提出的 HIR(Hindsight Instruction Labeling)是如何工作的?简单来说,HIR 方法包含两个步骤:采样和训练。在采样步骤,prompt 和指令被输入到 LLM 中以收集响应。然后基于对齐分数,在训练阶段适当的地方对指令进行重新标注。然后,使用经过重新标注的指令和原始 prompt 对 LLM 进行微调。使用这种重新标注方法,研究者可以有效地将失败案例(LLM 的输出与原始指令不匹配的情况)转变成对监督学习有用的训练数据。

来自上述论文的方法及实验结果比较
注意这项研究不能直接与 InstructGPT 中的 RLHF 工作进行比较,因为它似乎使用启发式方法(「但是,由于大多数人类反馈数据都难以收集,所以我们采用了一个脚本化的反馈函数……」)不过 HIR 的事后高见方法的结果依然非常引人注目。
论文 3:《Direct Preference Optimization:Your Language Model is Secretly a Reward Model》
论文地址:https://arxiv.org/abs/2305.18290
直接偏好优化(DPO)是一种「使用 PPO 的 RLHF」的替代技术,作者在论文中表明在 RLHF 用于拟合奖励模型的交叉熵损失也可用于直接微调 LLM。根据他们的基准测试,使用 DPO 的效率更高,而且在响应质量方面也通常优于 RLHF/PPO。

来自对应论文的 DPO 及其效果展示
论文 4:《Reinforced Self-Training (ReST) for Language Modeling》
论文地址:https://arxiv.org/abs/2308.08998
ReST 也是 RLHF 的一种替代方法,其能用于对齐 LLM 与人类偏好。ReST 使用一种采样方法来创建一个改进版数据集,然后在质量越来越高的子集上不断迭代训练,从而实现对奖励函数的微调。据作者描述,ReST 的效率高于标准的在线 RLHF 方法(比如使用 PPO 的 RLHF),因为其能以离线方式生成训练数据集,但他们并未全面地比较这种方法与 InstructGPT 和 Llama 2 等中使用的标准 RLHF PPO 方法。

ReST 方法图示
论文 5:《RLAIF:Scaling Reinforcement Learning from Human Feedback with AI Feedback》
论文地址:https://arxiv.org/abs/2309.00267
近期的根据人工智能反馈的强化学习(RLAIF)研究表明,在 RLHF 中用于训练奖励模型的评分并不一定非要由人类提供,也可以使用 LLM(这里是 PaLM 2)生成。在人类评估者看来,用传统 RLHF 方法和 RLAIF 方法训练的模型得到的结果都差不多
另一个有趣的发现是:RLHF 和 RLAIF 模型都显著优于单纯使用监督式指令微调训练的模型。

RLHF 和 RLAIF 方法以及它们的胜率比较
这项研究的结果非常有用而且很有意思,因为这基本上意味着我们可以让 RLHF 训练更加高效并且成本更低。但是,在有关信息内容的安全性和可信性(人类偏好研究只能部分地体现)的定性研究中,这些 RLAIF 模型究竟表现如何还有待观察。
结语
这些替代技术是否值得投入应用实践?这个问题还有待解答,因为目前 Llama 2 和未使用 RLHF 训练的 Code Llama 系列模型都还没有真正的竞争者。
# Collinear-Constrained-Attention
随着大语言模型的快速发展,其长度外推能力(length extrapolating)正日益受到研究者的关注。尽管这在 Transformer 诞生之初,被视为天然具备的能力,但随着相关研究的深入,现实远非如此。传统的 Transformer 架构在训练长度之外无一例外表现出糟糕的推理性能。
研究人员逐渐意识到这一缺陷可能与位置编码(position encoding)有关,由此展开了绝对位置编码到相对位置编码的过渡,并产生了一系列相关的优化工作,其中较为代表性的,例如:旋转位置编码(RoPE)(Su et al., 2021)、Alibi (Press et al., 2021)、Xpos (Sun et al., 2022) 等,以及近期 meta 研发的位置插值(PI)(Chen et al., 2023),reddit 网友给出的 NTK-aware Scaled RoPE (bloc97, 2023),都在试图让模型真正具备理想中的外推能力。破解自注意力推理缺陷的奥秘,蚂蚁自研新一代Transformer或实现无损外推
然而,当研究人员全力将目光放在位置编码这一众矢之的上时,却忽视了 Transformer 中另一个重量级角色 --self-attention 本身。蚂蚁人工智能团队最新研究表明,这一被忽视的角色,极有可能成为扭转局势的关键。Transformer 糟糕的外推性能,除了位置编码外,self-attention 本身仍有诸多未解之谜。
基于此发现,蚂蚁人工智能团队自研了新一代注意力机制,在实现长度外推的同时,模型在具体任务上的表现同样出色。
- 论文地址:https://arxiv.org/abs/2309.08646
- Github仓库:https://github.com/codefuse-ai/Collinear-Constrained-Attention
- ModelScope:https://modelscope.cn/models/codefuse-ai/Collinear-Constrained-Attention/summary
- HuggingFace:敬请期待
背景知识
在深入探讨之前,我们快速回顾一些核心的背景知识。
长度外推 (Length Extrapolating)
长度外推是指大语言模型在处理比其训练数据中更长的文本时的能力。在训练大型语言模型时,通常有一个最大的序列长度,超过这个长度的文本需要被截断或分割。但在实际应用中,用户可能会给模型提供比训练时更长的文本作为输入,如果模型欠缺长度外推能力或者外推能力不佳,这将导致模型产生无法预期的输出,进而影响模型实际应用效果。
自注意力 (Self-Attention)
(Vaswani et al., 2017) 于 2017 年提出的 multi-head self-attention,作为如今大语言模型的内核,对于推动人工智能领域的发展起到了举足轻重的作用。这里以下图 1 给出形象化的描述,这项工作本身已经被广泛认可,这里不再进行赘述。初次接触大语言模型,对这项工作不甚了解的读者可以前往原论文获取更多细节 (Vaswani et al., 2017)。

图1. 多头注意力机制示意图,引自(Vaswani, et al., 2017)。
位置编码 (Position encoding)
由于 self-attention 机制本身并不直接处理序列中的位置信息,因此引入位置编码成为必要。由于传统的 Transformer 中的位置编码方式由于其外推能力不佳,如今已经很少使用,本文不再深入探讨传统的 Transformer 中的编码方法,对于需要了解更多相关知识的读者,可以前往原论文查阅详情 (Vaswani et al., 2017)。在这里,我们将重点介绍目前非常流行的旋转位置编码(RoPE)(Su et al., 2021),值得一提的是,Meta 的 LLaMa 系列模型 (Touvron et al., 2023a) 均采用了此种编码方式。
RoPE 从建模美学的角度来说,是一种十分优雅的结构,通过将位置信息融入 query 和 key 的旋转之中,来实现相对位置的表达。

图2. 旋转位置编码结构,引自(Su et al., 2021)。
位置插值 (Position Interpolation)
尽管 RoPE 相比绝对位置编码的外推性能要优秀不少,但仍然无法达到日新月异的应用需求。为此研究人员相继提出了各种改进措施,以 PI (Chen et al., 2023) 和 NTK-aware Scaled RoPE (bloc97, 2023) 为典型代表。但要想取得理想效果,位置插值仍然离不开微调,实验表明,即使是宣称无需微调便可外推的 NTK-aware Scaled RoPE,在传统 attention 架构下,至多只能达到 4~8 倍的外推长度,且很难保障良好的语言建模性能和长程依赖能力。

图3. 位置插值示意图,引自(Chen et al., 2023)。
CoCA
过去的研究主要集中在位置编码上,所有相关研究工作均默认 self-attention 机制已经被完美实现。然而,蚂蚁人工智能团队近期发现了一个久被忽视的关键:要从根本上解决 Transformer 模型的外推性能问题,self-attention 机制同样需要重新考量。

图4. CoCA 模型架构,引自(Zhu et al., 2023)。
RoPE 与 self-attention 的异常行为
在 Transformer 模型中,self-attention 的核心思想是计算 query(q)和 key(k)之间的关系。注意力机制使用这些关系来决定模型应该 “关注” 输入序列中的哪些部分。



图6.因果模型中的序被破坏,引自(Zhu et al., 2023)。
共线约束注意力(CoCA)
基于以上 RoPE 与 self-attention 的异常行为分析,要从根本上解决这个问题,仅从位置编码入手很显然是药不对症,根本的解决方法是让 self-attention 中的 query 和 key 初始夹角为 0,这是论文中共线约束(Collinear Constrained Attention)的由来。
详细的推导和公式,这里不进行一一展开,读者可以阅读原文进行深入理解。
需要特别指出的是,论文给出的理论解释中,表明:
- 稳定的远程衰减特性:CoCA 相对于 RoPE 显示出了更为稳定的远程衰减特性。
- 显存瓶颈与解决方案:CoCA 有引入显存瓶颈的风险,但论文给出了十分高效的解决方案,使得 CoCA 的计算和空间复杂度几乎与最初版本的 self-attention 无异,这是十分重要的特性,使得 CoCA 的实用性十分优异。
- 无缝集成:CoCA 可以与当前已知的插值手段(论文中实验了 NTK-aware Scaled RoPE)无缝集成,且在无需微调的情况下取得了远超原始 attention 结构的性能,这意味着使用 CoCA 训练的模型,天然就拥有近乎无限的外推能力,这是大语言模型梦寐以求的特性。
实验结论
论文比较了 CoCA 与 RoPE (Su et al., 2021)、 ALibi (Press et al., 2021) 在外推性能上的差异,取得了令人振奋的结果。相应模型记为:
- Origin:原始 attention 结构,位置编码方式为 RoPE
- ALibi:原始 attention 结构,位置编码方式为 ALibi
- CoCA:论文模型结构,位置编码方式为 RoPE
详细的实验背景,可以查阅原文。
长文本建模能力
论文评估了 CoCA 和 Origin、ALibi 模型的长文本语言建模能力。该评估使用了 100 个文档,每个文档至少拥有 8,192 个 token,这些文档随机采样于 PG-19 数据集 (Rae et al., 2019)。所有 3 个模型的训练长度均为 512,模型大小为 350M。
图 7 说明了一个值得注意的趋势:当推理长度超出其训练长度,Origin 模型的困惑度迅速偏离(>1000)。相比之下,CoCA 模型能够维持低困惑度,即使是在其训练长度的 16 倍时,困惑度没有出现发散趋势。
NTK-aware Scaled RoPE (bloc97, 2023) 作为一种无需微调的外推方法,论文中允许在实验中应用该方法,但即使在 Origin 模型上应用了动态 NTK 方法,其困惑度仍然远高于 CoCA。
ALibi 在困惑度上的表现最好,而 CoCA 在应用动态 NTK 方法后,可以取得与 ALibi 相近的结果。

图7.滑动窗口困惑度测试结果,引自(Zhu et al., 2023)。
捕捉长程依赖
困惑度是衡量语言模型预测下一个 token 的熟练程度的指标。然而,它并不能完全代表一个理想的模型。因为虽然局部注意力在困惑度上表现出色,但它在捕获长程依赖性方面往往表现不佳。
为了深入评估这一问题,论文采用 (Mohtashami & Jaggi, 2023) 提出的密钥检索综合评估任务评估了 CoCA 和 Origin、ALibi 模型。在此任务中,有一个隐藏在长文档中的随机密钥需要被识别和检索。
如图 8 所示,像 ALibi 这一类具有一定局部假设的模型,尽管在困惑度任务上表现良好,但在捕捉长程依赖时具备无法弥补的劣势,在外推 1 倍长度时,准确率就开始迅速下降,最终下跌至 10% 以下。相比之下,即使测试序列长度扩展到原始训练长度的 16 倍,CoCA 也始终表现出很高的准确性,在 16 倍外推长度时仍然超过 60%。比 Origin 模型整体高出 20%,而比 ALibi 整体高出 50% 以上。

图8.随机密钥识别检索性能曲线,引自(Zhu et al., 2023)。
超参数稳定性
由于在实验中应用了动态 NTK 方法,论文针对 Origin 和 CoCA 模型在动态 NTK 方法下的 scaling factor 超参数稳定性进行了深入探讨。
如图 9 所示,Origin 模型在不同 scaling factor 下存在剧烈波动(200~800),而 CoCA 模型则处于相对稳定的区间(60~70)。更进一步,从 Table 4 中的明细数据可以看出,CoCA 模型最差的困惑度表现仍然比 Origin 模型最好的困惑度表现要好 50% 以上。
在 Passkey 实验中,Origin 和 CoCA 模型表现出了与困惑度实验中类似的特性,CoCA 模型在不同的 scaling factor 均有较高的准确率,而 Origin 模型在 scaling factor=8 时,准确率下跌至了 20% 以下。更进一步,从 Table 5 的明细数据可以看出,Origin 模型即使在表现最好的 scaling factor=2 时,仍然与 CoCA 模型有 5%~10% 的准确率差距。
同时,Origin 模型在 scaling factor=2 时困惑度表现却是糟糕的,这从侧面反映了原始的 attention 结构在长度外推时很难同时保证困惑度和捕捉长程依赖两方面的性能,而 CoCA 做到了这一点。

图9. Origin model 和 CoCA 在不同 scaling factor 的困惑度,引自(Zhu et al., 2023)

图10. Origin 模型和 CoCA 在不同 scaling factor 的通行密钥准确性,引自(Zhu et al., 2023)

长度外推中的注意力得分
如同 PI (Chen et al., 2023) 论文所探究的一样,大语言模型在长度外推中的失败与注意力得分的异常值(通常是非常大的值)直接相关。论文进一步探讨了这一现象,这一现象也从侧面说明了为什么 CoCA 模型在长度外推中的表现要优于传统 attention 结构。
实验使用了 PG-19 数据集 (Rae et al., 2019) 中的一个随机片段,长度为 1951 个 token,大约是模型训练长度的 4 倍。
如图 11 所示,其中 (a1) 是 Origin 和 CoCA 模型在不使用动态 NTK 方法时的各层注意力得分,(b1) 是使用动态 NTK 方法后的得分,low layers 表示模型的第 6、12、18 层,last layer 表示第 24 层,(a2) 是 (a1) 在最后 500 个 token 的放大版本,(b2) 同理。
- 从 (a1) 和 (b1) 可以发现,Origin 模型的注意力得分存在少量异常值,数值比 CoCA 模型注意力得分大 10~20 倍。
- 由于这些异常值影响了观察效果,(a2) 局部放大了最后 500 个 token,可以看到 Origin 模型的 last layer 注意力得分几乎为 0,这说明 Origin 模型在长度外推时,发生了关注邻近 token 的失效。
- 从 (b2) 可以看出,当应用动态 NTK 方法后,Origin 模型在邻近 token 处的注意力得分变得异常大,这一异常现象与前文论证的 RoPE 与 self-attention 的异常行为息息相关,Origin 模型在邻近 token 处可能存在着严重的过拟合。

图11. 外推中的注意力得分,引自(Zhu et al., 2023)
Human Eval
在论文之外,我们使用相同的数据(120B token),相同的模型规模(1.3B),相同训练配置,基于 CoCA 和 Origin 模型进一步评测了 human eval 上的表现,与 Origin 模型对比如下:
- 跟 Origin 模型比起来,两者水平相当,CoCA 并没有因为外推能力而导致模型表达能力产生损失。
- Origin 模型在 python、java 的表现比其他语言好很多,在 go 上表现较差,CoCA 的表现相对平衡,这与训练语料中 go 的语料较少有关,说明 CoCA 可能有潜在的小样本学习能力。

总结
在这项工作中,蚂蚁人工智能团队发现了 RoPE 和注意力矩阵之间的某种异常行为,该异常导致注意力机制与位置编码的相互作用产生紊乱,特别是在包含关键信息的最近位置的 token。
为了从根本上解决这个问题,论文引入了一种新的自注意力框架,称为共线约束注意力(CoCA)。论文提供的数学证据展示了该方法的优越特性,例如更强的远程衰减形式,以及实际应用的计算和空间效率。
实验结果证实,CoCA 在长文本语言建模和长程依赖捕获方面都具有出色的性能。此外,CoCA 能够与现有的外推、插值技术以及其他为传统 Transformer 模型设计的优化方法无缝集成。这种适应性表明 CoCA 有潜力演变成 Transformer 模型的增强版本。
# Penetrative AI
大语言模型是否是世界模型?
大语言模型除了在数字世界完成如写作或翻译等任务,它们能否理解并处理物理世界中的信息并进而完成更广泛的任务呢?
最近来自香港科技大学(HKUST)、南洋理工大学(NTU)与加利福尼亚大学洛杉矶分校(UCLA)的研究者们提供了新的思路:他们发现大语言模型如 ChatGPT 可以理解传感器信号进而完成物理世界中的任务。该项目初步成果发表于 ACM HotMobile 2024。
- 论文标题:Penetrative AI: Making LLMs Comprehend the Physical World
- 论文地址:https://arxiv.org/abs/2310.09605
- 项目网站:https://dapowan.github.io/wands_penetrative-ai/
在讨论大型语言模型(LLMs)与物理世界互动的议题时,大家或许更熟悉的是将其应用于图像或音频数据处理,例如视觉语言模型(VLMs)。但在真实物理世界中,除了这些人类依赖的感知数据外,还存在诸多其他重要的物理量,如温度、气压、加速度、电压及电磁波信号强度等等。
因此,该研究团队从一个更广的视野出发,探索了大型语言模型理解这些物理量的可能性。他们发现了大语言模型新的能力 —— 处理物理信号进而理解世界,并基于此提出了渗透式人工智能(Penetrative AI)的概念。
研究者们首先尝试让 ChatGPT 来处理手机传感器(加速计、卫星和 WiFi)信号来感知用户在现实世界的活动与位置语义,流程与部分实验结果如下图所示:

研究团队在多种真实场景中采集手机传感器信号,并让 ChatGPT-4 分析采集的数据(图中绿色部分)。研究发现 ChatGPT 能够准确地识别用户的行为和所处环境。
在第一项实验中,模型通过分析特定 WiFi 名称(SSID),如「WiFi.HK via EPCC」和「3DG Jewellery」,成功推理用户很有可能在香港某商场。
接下来,研究团队进一步挑战让 ChatGPT 处理心电图(ECG)数据来推算心率。每次心跳都会在 ECG 数据上形成明显的波峰,即所谓的 R-peak。
在这一任务中,ChatGPT 的目标是识别出所有的 R-peak 峰值,以此来计算心率。不同于之前的任务,传感器数据在此任务中完全以纯数字序列的形式提供给模型,如下图所示:

初步实验发现,大语言模型如 ChatGPT 无法有效地直接处理长数字序列信号。面对此挑战,研究者在 Prompt 中为大语言模型设计了一个基于自然语言的「算法」以引导其分析数字信号。
与传统算法不同,该「算法」包含许多模糊逻辑(如「overall」和「lower」等词汇),且无需设定任何阈值。
实验结果显示,ChatGPT-4 能有效利用「算法」在绝大多数情况下准确识别出ECG信号中所有R-peaks,其精度甚至能超越相同实验设置下的传统信号处理算法。
渗透式人工智能
开启 AI 和物理世界交互新篇章
定义
研究团队于是提出了一个创新性的概念,渗透式人工智能(Penetrative AI):利用大语言模型内嵌的世界知识来理解和处理广泛部署的物联网(IoT)传感器或控制器信号,来为物理信息系统(Cyber–Physical System,CPS)完成感知与决策任务。

该研究总结了渗透式人工智概念下感知事物的简易流程。在这一新范式下,大语言模型的输入和输出都对应真实的物理信号或状态。例如,让语言模型处理温度计捕获的温度信号,并生成与物理状态相对应的描述性文本 ——「水沸腾了」。随着任务复杂度的增加,向模型中注入专家知识(Expert Knowledge)可以增强其处理复杂数据的能力。
核心特点

与传统范式相比,渗透式人工智能的独特之处在于利用大语言模型中的通用知识。传统方法依赖于专家对物理世界的观察和规则制定,或通过大数据集训练的机器学习模型。而渗透式智能则基于大语言模型中的通识,通过与额外观察或专家模型的协作,为物理信息系统提供更全面的知识支持。
这种新的智能范式利用大量文本数据衍生的通识,不仅能增强系统的泛化能力,而且也能降低对领域知识的依赖。得益于大型语言模型的特性,开发者主要通过编辑文本进行操作,这相比传统的编程方式,可降低开发的难度和成本。该范式也可以利用文本这一通用表征,将不同传感器信号文本化再整合,呈现新的多模态融合方式。
深度探索

研究团队从信号处理的角度出发,深入探讨了大语言模型在处理不同类型信号时的能力,分为文本层次渗透和数字层次渗透两大层次,如上图所示:
- 文本层次渗透(Textualized-level Penetration):大语言模型主要处理文本形式的信号,例如文本化的温度信号,或第一个示例应用中大模型分析的 WiFi 名称。
- 数字层次渗透(Digitized-level Penetration):大语言模型主要处理数字形式的信号,例如温度数字信号,或第二个示例应用中大模型分析的 ECG 数字信号。
前文两个示例应用均展示了大型语言模型如 ChatGPT 在两个层次的潜能。相较于文本层次的渗透,大语言模型在数字层次渗透中可以处理更细致的信号信息,但也对其解析信号能力提出了更高要求,任务难度也随之增大。
小结
该研究提出了「渗透式人工智能」(Penetrative AI)的概念,透过两个具体的应用实例,展示了大型语言模型(LLM)如何利用其丰富的知识库,在不同信号层面上理解和处理物理信号,从而实现对现实世界的深度感知和有效干预的潜能。此研究也说明大语言模型如 ChatGPT-4 可能已经发展出世界模型,对物理世界有深入的理解。
渗透式智能不仅扩展了大型语言模型的应用领域,而且为 AI 在医疗、环境监测、家庭自动化等多个领域的应用提供了新的智能化解决方案。
如想进一步了解渗透式人工智能的定义、潜力、所面临的挑战和机遇,以及应用实例设计细节,欢迎阅读原论文。
# Octopus-v2
在大模型落地应用的过程中,端侧 AI 是非常重要的一个方向。
近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。
20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。
不少网友感叹:设备端 AI 智能体的时代到来了!
- 论文:Octopus v2: On-device language model for super agent
- 论文地址:https://arxiv.org/abs/2404.01744
- 模型主页:https://huggingface.co/NexaAIDev/Octopus-v2
模型概述
Octopus-V2-2B 是一个拥有 20 亿参数的开源语言模型,专为 Android API 量身定制,旨在在 Android 设备上无缝运行,并将实用性扩展到从 Android 系统管理到多个设备的编排等各种应用程序。

通常,检索增强生成 (RAG) 方法需要对潜在函数参数进行详细描述(有时需要多达数万个输入 token)。基于此,Octopus-V2-2B 在训练和推理阶段引入了独特的函数 token 策略,不仅使其能够达到与 GPT-4 相当的性能水平,而且还显著提高了推理速度,超越了基于 RAG 的方法,这使得它对边缘计算设备特别有利。

Octopus-V2-2B 能够在各种复杂场景中生成单独的、嵌套的和并行的函数调用。
数据集
为了训练、验证和测试阶段采用高质量数据集,特别是实现高效训练,研究团队用三个关键阶段创建数据集:
- 生成相关的查询及其关联的函数调用参数;
- 由适当的函数组件生成不相关的查询;
- 通过 Google Gemini 实现二进制验证支持。

研究团队编写了 20 个 Android API 描述,用于训练模型。下面是一个 Android API 描述示例:
def get_trending_news (category=None, region='US', language='en', max_results=5):
"""
Fetches trending news articles based on category, region, and language.
Parameters:
- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.
- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.
- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.
- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.
Returns:
- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL.
"""模型开发与训练
该研究采用 Google Gemma-2B 模型作为框架中的预训练模型,并采用两种不同的训练方法:完整模型训练和 LoRA 模型训练。
在完整模型训练中,该研究使用 AdamW 优化器,学习率设置为 5e-5,warm-up 的 step 数设置为 10,采用线性学习率调度器。
LoRA 模型训练采用与完整模型训练相同的优化器和学习率配置,LoRA rank 设置为 16,并将 LoRA 应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。其中,LoRA alpha 参数设置为 32。
对于两种训练方法,epoch 数均设置为 3。
使用以下代码,就可以在单个 GPU 上运行 Octopus-V2-2B 模型。
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport time
def inference (input_text):
start_time = time.time ()
input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)
input_length = input_ids ["input_ids"].shape [1]
outputs = model.generate (
input_ids=input_ids ["input_ids"],
max_length=1024,
do_sample=False)
generated_sequence = outputs [:, input_length:].tolist ()
res = tokenizer.decode (generated_sequence [0])
end_time = time.time ()
return {"output": res, "latency": end_time - start_time}
model_id = "NexaAIDev/Octopus-v2"
tokenizer = AutoTokenizer.from_pretrained (model_id)
model = GemmaForCausalLM.from_pretrained (
model_id, torch_dtype=torch.bfloat16, device_map="auto"
)
input_text = "Take a selfie for me with front camera"
nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"
start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")评估
Octopus-V2-2B 在基准测试中表现出卓越的推理速度,在单个 A100 GPU 上比「Llama7B + RAG 解决方案」快 36 倍。此外,与依赖集群 A100/H100 GPU 的 GPT-4-turbo 相比,Octopus-V2-2B 速度提高了 168%。这种效率突破归功于 Octopus-V2-2B 的函数性 token 设计。

Octopus-V2-2B 不仅在速度上表现出色,在准确率上也表现出色,在函数调用准确率上超越「Llama7B + RAG 方案」31%。Octopus-V2-2B 实现了与 GPT-4 和 RAG + GPT-3.5 相当的函数调用准确率。

# 量子计算~现实冷酷,炒作太多
我们公司也有研究这个的~~ 我虽然也是军队密码的学校但对这个不感冒~~ 看到大佬的文章就拿来说说~~~
「量子计算,寒冬将至了?」距离技术成熟永远「还差五年」?
本周五,AI 先驱 Yann LeCun 的一番言论引发了人们的讨论。
这位 AI 领域的著名学者表示,量子计算正在进入一个艰难时刻。与此同时,很多科技领域专家认为,目前的量子计算技术进步很多趋向于炒作,距离实际应用仍然很遥远。
对此,很多人同样持有悲观态度。
让我们看看 IEEE 的这篇文章是怎么说的:
量子计算机革命可能比许多人想象的更遥远、更有限。
一直以来,量子计算机都被期许为一种能够解决广泛问题的强大工具,可应用的方向包括金融建模、优化物流和加速机器学习。量子计算公司往往会提出一些雄心勃勃的规划,称机器可能会在短短几年内对现实世界产生巨大影响。但如今,对该技术不切实际的期望遭到越来越多的抵制。
LeCun—— 量子比特,没那么神奇
图灵奖得主、Meta 人工智能研究负责人 Yann LeCun 最近给量子计算机的前景泼了一盆冷水。
在庆祝 Meta 基础人工智能研究团队成立 10 周年的媒体活动上,LeCun 表示量子计算这项技术是「一个令人着迷的科学话题」,但他不太相信「会真正制造出真正有用的量子计算机」。
虽然 LeCun 并不是量子计算领域的专家,但该领域的领军人物也发出了类似的警告。亚马逊网络服务量子硬件负责人 Oskar Painter 表示,目前该行业存在「大量炒作」,「很难从完全不切实际的情况中筛选出乐观的观点」。
有观点认为将信息传播到许多物理量子比特上,可以创建更强大的「逻辑量子比特」,但这可能需要每个逻辑量子比特多达 1000 个物理量子比特。一些人甚至认为量子纠错根本上就是不可能的。
总之,Oskar Painter 表示:以所需的规模和速度实现这些计划仍然是遥远的目标。他还指出:「考虑到实现能够在数千个量子比特上运行数十亿个门的容错量子计算机所面临的技术挑战,很难给出一个时间线,但我估计至少需要十年。」
微软 —— 量子计算,非常消耗算力
不仅仅是时间的问题。今年 5 月,微软量子计算领导者 Matthias Troyer 在《Communications of the ACM》上合著发表了一篇论文,表明量子计算机可以提供的有意义应用数量比人们想象的要有限。
「我们发现过去十年来人们提出的许多想法都行不通,并且我们发现原因非常简单」,Matthias Troyer 说道。
量子计算机主要的前景是能够比传统计算机更快地解决问题,但有关具体能快多少,人们的思考却各不相同。Troyer 表示,在两种应用中,量子算法似乎可以提供指数级的加速。一是对大数进行因式分解,这使得破解互联网所依赖的公钥加密成为可能。另一个是模拟量子系统,它可以在化学和材料科学中获得应用。
量子算法已经被提出来解决一系列其他问题,包括优化、药物设计和流体动力学。但研究中声称的计算加速并不总是成功 —— 有时相当于二次增益,这意味着量子算法解决问题所需的时间是其经典算法所用时间的平方根。Troyer 表示,这些增益很快就会因为量子计算所需的大量计算消耗所抵消。操作量子比特比开关晶体管要复杂得多,因此速度要慢几个数量级。
这意味着,对于较小的问题,经典计算机总是会更快,而量子计算机获得领先的点取决于经典算法的复杂性扩展的速度。
Troyer 和他的同事将单块英伟达 A100 GPU 与虚构的未来容错量子计算机进行了比较,该计算机具有一万个「逻辑量子比特」,并且 gate 时间比当今的设备快得多。
研究人员发现,具有二次加速的量子算法必须运行几个世纪,甚至几千年,才能在大到有用的问题上超越经典算法。
另一个重大障碍是数据带宽。量子比特缓慢的运行速度从根本上限制了量子计算机输入和输出经典数据的速度。Troyer 表示,即使在乐观的未来场景中,这也可能比传统计算机慢数千或数百万倍。这意味着在可预见的未来,像机器学习或搜索数据库这样的数据密集型应用程序几乎肯定是遥不可及的。
Troyer 表示,当前的结论是量子计算机只能以指数级速度真正解决小数据问题。「其余的都是美丽的理论,但并不实用,」他补充道。
Troyer 表示,这篇论文并没有对量子计算研究社区产生太大影响,但许多微软客户很高兴能够了解量子计算的实际应用。他说,他们已经看到许多公司缩小甚至关闭了量子计算团队,包括金融和生命科学领域的公司。
应用范围可能有限
本月早些时候,来自量子计算初创公司 QuEra 和哈佛大学的研究人员证明他们可以使用 280 个量子比特处理器生成 48 个逻辑量子比特,远远超过之前的实验所能达到的水平。
QuEra CMO Yuval Boger 强调该实验是实验室演示,但该结果已促使一些人重新评估容错量子计算的时间尺度。
但与此同时,他也注意到一些公司悄悄地将资源从量子计算转移出去的趋势。他认为这在一定程度上是由于大型语言模型出现以来人们对人工智能的兴趣日益浓厚所致。
即使在量子计算机看起来最有前途的领域,其应用范围也可能比最初希望的要窄。例如,近年来的研究论文表明,量子化学中只有有限数量的问题可能受益于量子加速。
德国制药巨头默克集团数字创新全球主管 Philipp Harbach 表示,同样重要的是要记住,许多公司已经拥有在经典硬件上运行的成熟且高效的量子化学工作流程。
他表示:「在公众看来,量子计算机似乎能够实现目前无法实现的目标,这是不准确的。首先,它将加速现有任务的速度,而不是引入完全颠覆性的新应用领域。所以我们正在评估这里的差异。」
Harbach 的团队大约六年来一直在研究量子计算与制药等工作的相关性。虽然 NISQ 设备可能用于解决某些高度专业化的问题,但他们得出的结论是,在实现容错之前,量子计算不会对工业产生重大影响。Harbach 表示,即便如此,这种影响的变革性实际上取决于公司正在开发的具体用例和产品。
量子计算机擅长为经典计算机难以解决的大规模问题提供准确的解决方案。这对于某些应用非常有用,例如设计新催化剂。但在默克的实践中,人们感兴趣的大多数化学问题都涉及快速筛选大量候选分子。
「量子化学中的大多数问题都不会呈指数级扩展,近似值就足够了,」Harbach 表示。「它们是易于解决的问题,你只需要通过增加系统规模来使它们更快。」
尽管如此,微软的 Troyer 表示,我们仍然有理由对量子计算感到乐观 —— 即使量子计算机只能解决化学和材料科学等领域的有限问题,其影响仍然可能改变游戏规则。「我们谈论的是石器时代、青铜时代、铁器时代和硅时代之间的代际区别,所以材料对人类有着巨大的影响,」他说道。
Troyer 认为,提出一些怀疑的目的不是为了减少人们对该领域的兴趣,而是为了确保研究人员专注于量子计算最有前途、最有可能产生影响的应用。
或许在 Yann LeCun 的推特下,有人的一条回应可以支持这样的说法。
谷歌市场负责人 Guillaume Roques 表示:如今大语言模型的基础 —— 神经网络的首次实现是由 Marvin Minsky 和 Dean Edmond(当时是哈佛大学的学生)于 1950 年提出的。
在 1957 年,Frank Rosenblatt 创建了感知器,这是一种以软件形式实现的单层神经网络,返回二进制结果(0 或 1)作为输出。不幸的是,多层网络直到几十年后才会出现,因为人工智能在研究方面经历了一个漫长的「冬天」,因为感知器受到了 Minsky 的批评,而且 James Lighthill 关于人工智能的非常悲观的报告把有关人工智能的很多研究多「埋葬」了几年。
因此,希望量子计算不会迎来冬天,这样我们就能看到它对我们一生的影响……
原文链接:
https://spectrum.ieee.org/quantum-computing-skeptics



















