
文章目录
按照学习计划,本周是学习Informer机制
网上资料还是比较多了,最近看下来,还是书箱资料比较易懂,有带入感,blog笔记只做个个人理解+记录。
书籍资料 5.3 Informer 机制
在Kubernetes系统中,组件之间通过HTTP协议进行通信,在不依赖任何中间件的情况下需要保证消息的实时性、可靠性、顺序性等。那么Kubernetes是如何做到的呢?答案就是Informer机制。Kubernetes的其他组件都是通过client-go的Informer机制与Kubernetes API Server进行通信的。
5.3.1 Informer机制架构设计
本节介绍Informer机制架构设计,Informer运行原理如图5-5所示。
在Informer架构设计中,有多个核心组件,分别介绍如下。
- 1.ReflectorReflector用于监控(Watch)指定的Kubernetes资源,当监控的资源发生变化时,触发相应的变更事件,例如Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,并将其资源对象存放到本地缓存DeltaFIFO中。
- 2.DeltaFIFODeltaFIFO可以分开理解,FIFO是一个先进先出的队列,它拥有队列操作的基本方法,例如Add、Update、Delete、List、Pop、Close等,而Delta是一个资源对象存储,它可以保存资源对象的操作类型,例如Added(添加)操作类型、Updated(更新)操作类型、Deleted(删除)操作类型、Sync(同步)操作类型等。
- 3.IndexerIndexer是client-go用来存储资源对象并自带索引功能的本地存储,Reflector从DeltaFIFO中将消费出来的资源对象存储至Indexer。Indexer与Etcd集群中的数据完全保持一致。client-go可以很方便地从本地存储中读取相应的资源对象数据,而无须每次从远程Etcd集群中读取,以减轻Kubernetes API Server和Etcd集群的压力。
直接阅读Informer机制代码会比较晦涩,通过Informers Example代码示例来理解Informer,印象会更深刻。Informers Example代码示例如下
package main
import (
"log"
"time"
v1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
config, err := clientcmd.BuildConfigFromFlags("", "/root/.kube/config")
if err != nil {
panic(err)
}
// 首先通过kubernetes.NewForConfig创建clientset对象,Informer需要通过ClientSet与Kubernetes API Server进行交互
clientSet, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
//创建stopCh对象,该对象用于在程序进程退出之前通知Informer提前退出,因为Informer是一个持久运行的goroutine
stopCh := make(chan struct{})
defer close(stopCh)
/*informers.NewSharedInformerFactory函数实例化了SharedInformer对象,
它接收两个参数:第1个参数clientset是用于与Kubernetes API Server交互的客户端,
第2个参数time.Minute用于设置多久进行一次resync(重新同步),
resync会周期性地执行List操作,将所有的资源存放在Informer Store中,如果该参数为0,则禁用resync功能。
*/
sharedInformers := informers.NewSharedInformerFactory(clientSet, time.Minute)
/*
通过sharedInformers.Core().V1().Pods().Informer可以得到具体Pod资源的informer对象。
通过informer.AddEventHandler函数可以为Pod资源添加资源事件回调方法,支持3种资源事件回调方法,
分别介绍如下。
● AddFunc:当创建Pod资源对象时触发的事件回调方法。
● UpdateFunc:当更新Pod资源对象时触发的事件回调方法。
● DeleteFunc:当删除Pod资源对象时触发的事件回调方法。
*/
informer := sharedInformers.Core().V1().Pods().Informer()
// 为Pod资源添加资源事件回调方法,支持AddFunc、UpdateFunc及DeleteFunc
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
/*
在正常的情况下,Kubernetes的其他组件在使用Informer机制时触发资源事件回调方法,
将资源对象推送到WorkQueue或其他队列中,在Informers Example代码示例中,
我们直接输出触发的资源事件。
*/
mObj := obj.(v1.Object)
log.Printf("New Pod Added to Store: %s", mObj.GetName())
},
UpdateFunc: func(oldObj, newObj interface{}) {
oObj := oldObj.(v1.Object)
nObj := newObj.(v1.Object)
log.Printf("%s Pod Updated to %s", oObj.GetName(), nObj.GetName())
},
DeleteFunc: func(obj interface{}) {
mObj := obj.(v1.Object)
log.Printf("Pod Deleted from Store: %s", mObj.GetName())
},
})
//最后通过informer.Run函数运行当前的Informer,内部为Pod资源类型创建Informer。
informer.Run(stopCh)
}
1.资源Informer
每一个Kubernetes资源上都实现了Informer机制。每一个Informer上都会实现Informer和Lister方法,例如PodInformer,代码示例如下: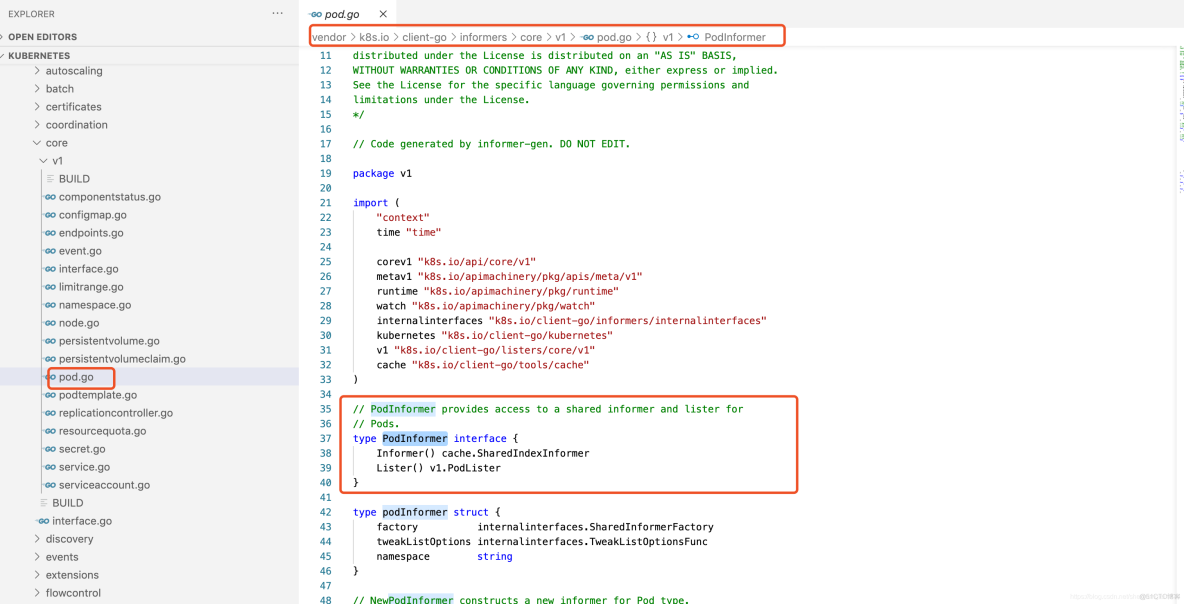
调用不同资源的Informer,代码示例如下:
podInformer := sharedInformers.Core().V1().POds().Informer()
nodeInformer := sharedInformers.Node().V1beta1().RuntimeClasses().Informer()
定义不同资源的Informer,允许监控不同资源的资源事件,例如,监听Node资源对象,当Kubernetes集群中有新的节点(Node)加入时,client-go能够及时收到资源对象的变更信息。
2.Shared Informer共享机制
Informer也被称为Shared Informer,它是可以共享使用的。在用client-go编写代码程序时,若同一资源的Informer被实例化了多次,每个Informer使用一个Reflector,那么会运行过多相同的ListAndWatch,太多重复的序列化和反序列化操作会导致Kubernetes API Server负载过重。Shared Informer可以使同一类资源Informer共享一个Reflector,这样可以节约很多资源。通过map数据结构实现共享的Informer机制。SharedInformer定义了一个map数据结构,用于存放所有Informer的字段,代码示例如下: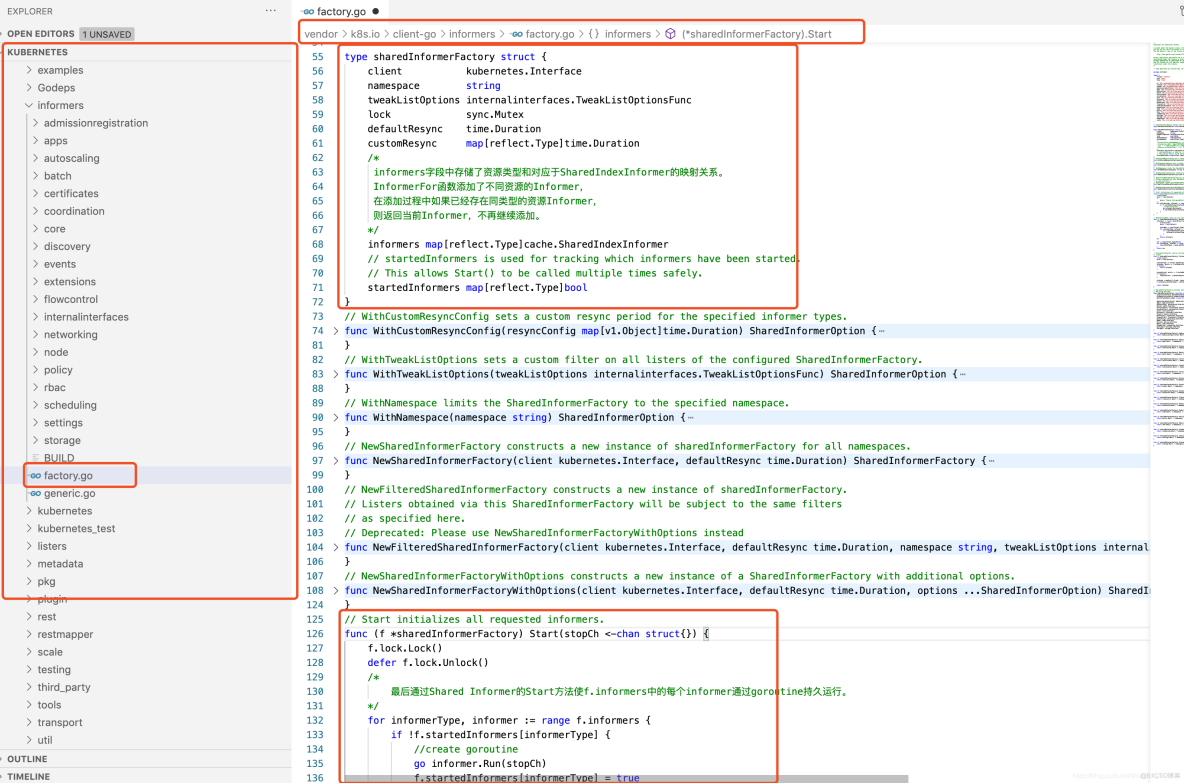
5.3.2 Reflector
Informer可以对Kubernetes API Server的资源执行监控(Watch)操作,资源类型可以是Kubernetes内置资源,也可以是CRD自定义资源,其中最核心的功能是Reflector。Reflector用于监控指定资源的Kubernetes资源,当监控的资源发生变化时,触发相应的变更事件,例如Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,并将其资源对象存放到本地缓存DeltaFIFO中。通过NewReflector实例化Reflector对象,实例化过程中须传入ListerWatcher数据接口对象,它拥有List和Watch方法,用于获取及监控资源列表。只要实现了List和Watch方法的对象都可以称为ListerWatcher。Reflector对象通过Run函数启动监控并处理监控事件。而在Reflector源码实现中,其中最主要的是ListAndWatch函数,它负责获取资源列表(List)和监控(Watch)指定的Kubernetes API Server资源。ListAndWatch函数实现可分为两部分:第1部分获取资源列表数据,第2部分监控资源对象。
1.获取资源列表数据
ListAndWatch List在程序第一次运行时获取该资源下所有的对象数据并将其存储至DeltaFIFO中。以Informers Example代码示例为例,在其中,我们获取的是所有Pod的资源数据。ListAndWatchList流程图如图5-6所示。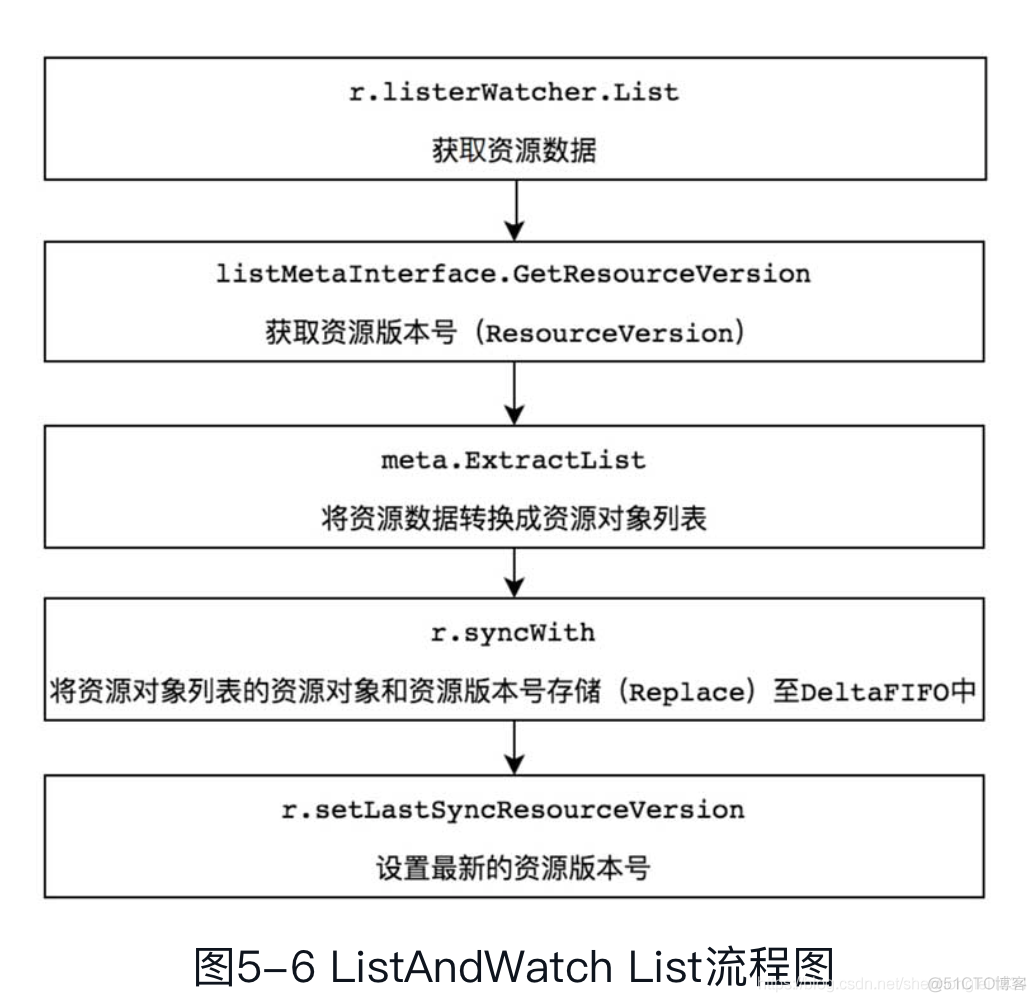
- (1)r.listerWatcher.List用于获取资源下的所有对象的数据,例如,获取所有Pod的资源数据。获取资源数据是由options的ResourceVersion(资源版本号)参数控制的,如果ResourceVersion为0,则表示获取所有Pod的资源数据;如果ResourceVersion非0,则表示根据资源版本号继续获取,功能有些类似于文件传输过程中的“断点续传”,当传输过程中遇到网络故障导致中断,下次再连接时,会根据资源版本号继续传输未完成的部分。可以使本地缓存中的数据与Etcd集群中的数据保持一致。
- (2)listMetaInterface.GetResourceVersion用于获取资源版本号,ResourceVersion (资源版本号)非常重要,Kubernetes中所有的资源都拥有该字段,它标识当前资源对象的版本号。每次修改当前资源对象时,Kubernetes API Server都会更改ResourceVersion,使得client-go执行Watch操作时可以根据ResourceVersion来确定当前资源对象是否发生变化。更多关于ResourceVersion资源版本号的内容,请参考6.5.2节“ResourceVersion资源版本号”。
- (3)meta.ExtractList用于将资源数据转换成资源对象列表,将runtime.Object对象转换成[]runtime.Object对象。因为r.listerWatcher.List获取的是资源下的所有对象的数据,例如所有的Pod资源数据,所以它是一个资源列表。
- (4) r.syncWith用于将资源对象列表中的资源对象和资源版本号存储至DeltaFIFO中,并会替换已存在的对象。
- (5)r.setLastSyncResourceVersion用于设置最新的资源版本号。
ListAndWatch List代码示例如下: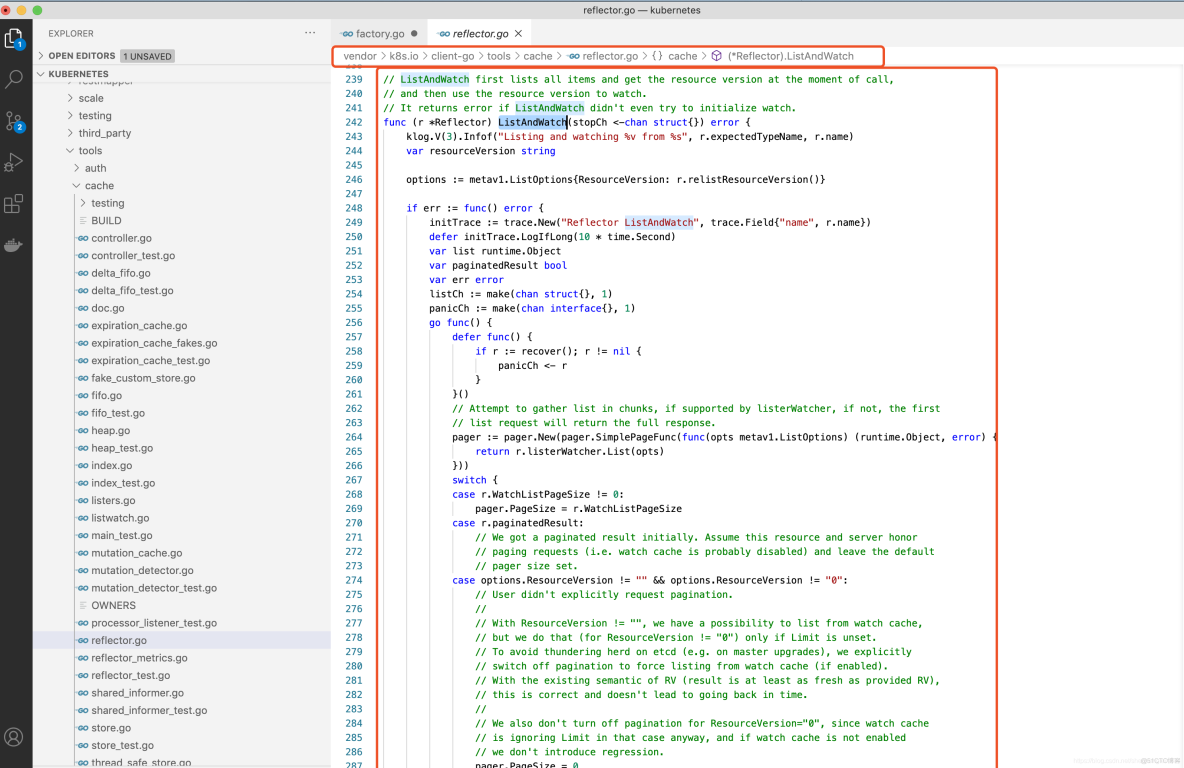
r.listerWatcher.List函数实际调用了Pod Informer下的ListFunc函数,它通过ClientSet客户端与Kubernetes API Server交互并获取Pod资源列表数据,代码示例如下: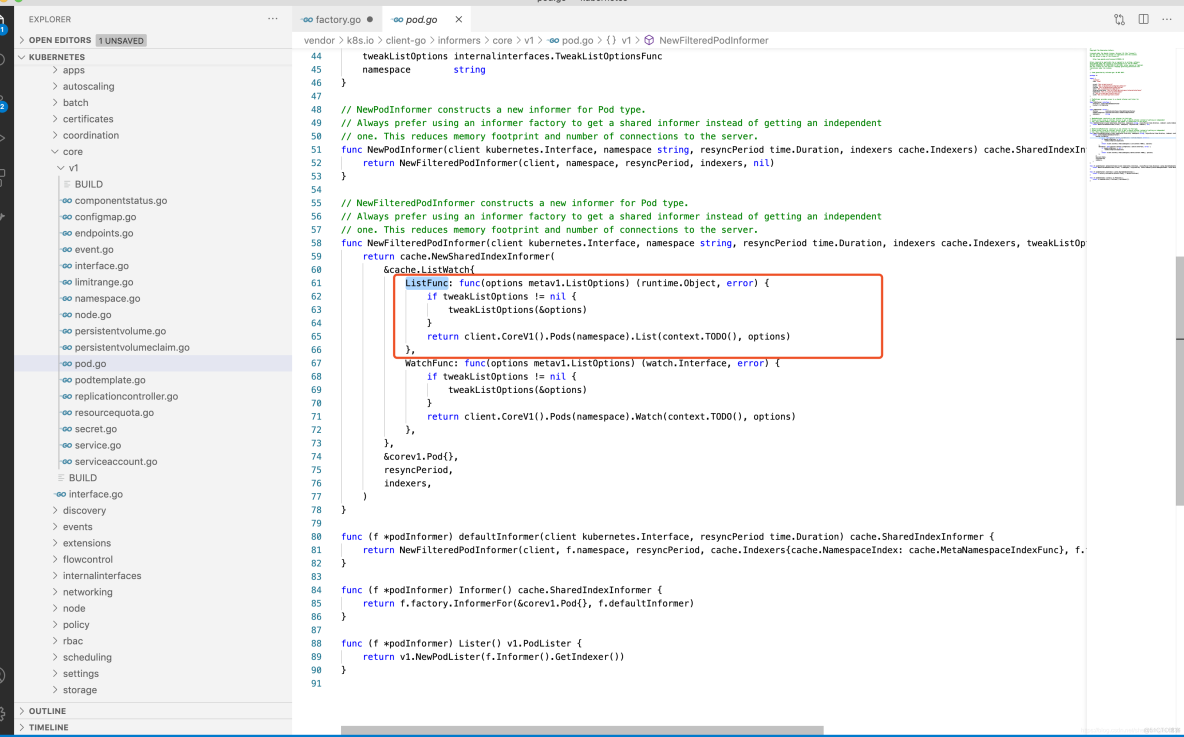
2.监控资源对象
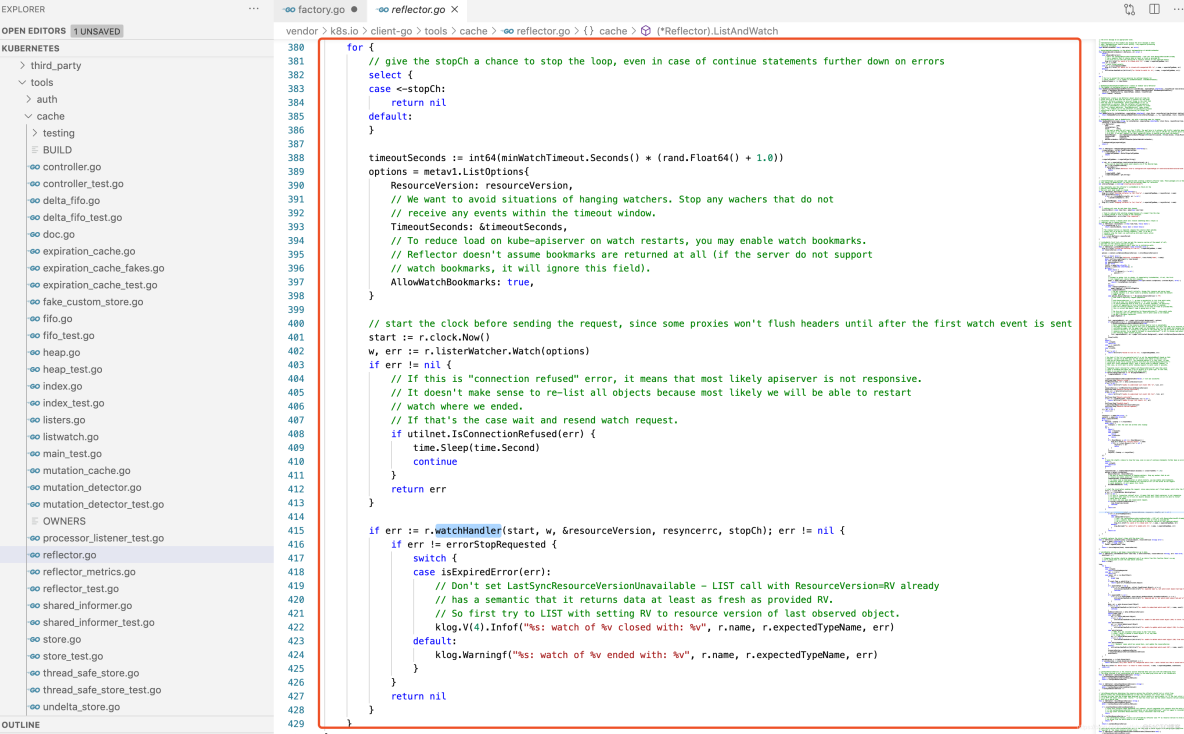
Watch(监控)操作通过HTTP协议与KubernetesAPI Server建立长连接,接收Kubernetes APIServer发来的资源变更事件。Watch操作的实现机制使用HTTP协议的分块传输编码(ChunkedTransfer Encoding)。当client-go调用Kubernetes API Server时,Kubernetes APIServer在Response的HTTP Header中设置Transfer-Encoding的值为chunked,表示采用分块传输编码,客户端收到该信息后,便与服务端进行连接,并等待下一个数据块(即资源的事件信息)。更多关于分块传输编码的内容请参考维基百科(参见链接[3])。ListAndWatch Watch代码示例如下:[同上]
r.listerWatcher.Watch函数实际调用了PodInformer下的WatchFunc函数,它通过ClientSet客户端与Kubernetes API Server建立长连接,监控指定资源的变更事件,代码示例如下: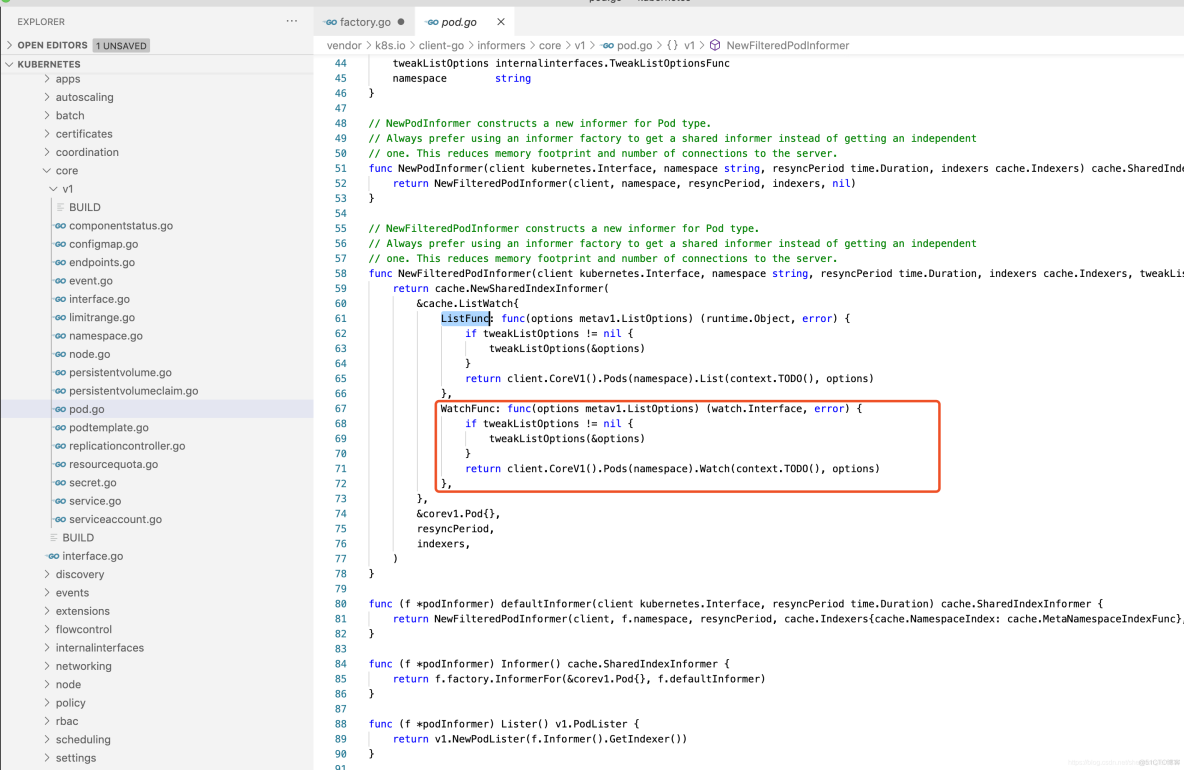
r.watchHandler用于处理资源的变更事件。当触发Added(资源添加)事件、Updated (资源更新)事件、Deleted(资源删除)事件时,将对应的资源对象更新到本地缓存DeltaFIFO中并更新ResourceVersion资源版本号。r.watchHandler代码示例如下: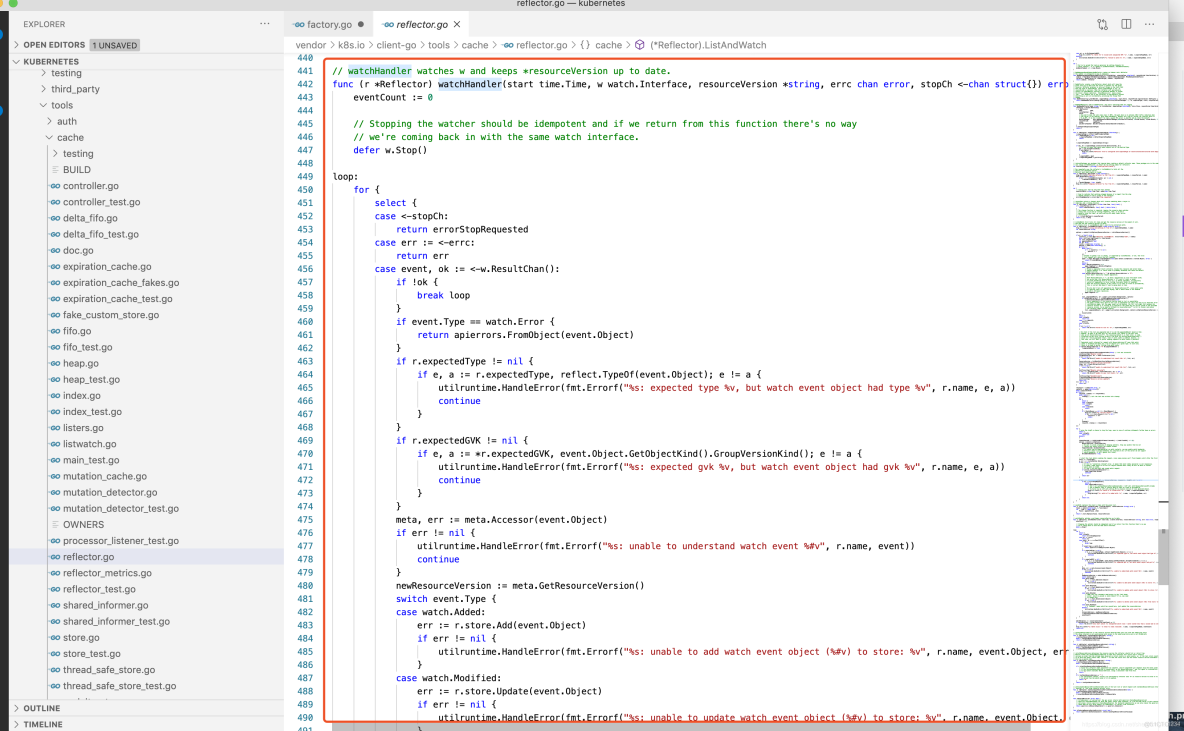
5.3.3 DeltaFIFO
DeltaFIFO可以分开理解,FIFO是一个先进先出的队列,它拥有队列操作的基本方法,例如Add、Update、Delete、List、Pop、Close等,而Delta是一个资源对象存储,它可以保存资源对象的操作类型,例如Added(添加)操作类型、Updated(更新)操作类型、Deleted(删除)操作类型、Sync(同步)操作类型等。DeltaFIFO结构代码示例如下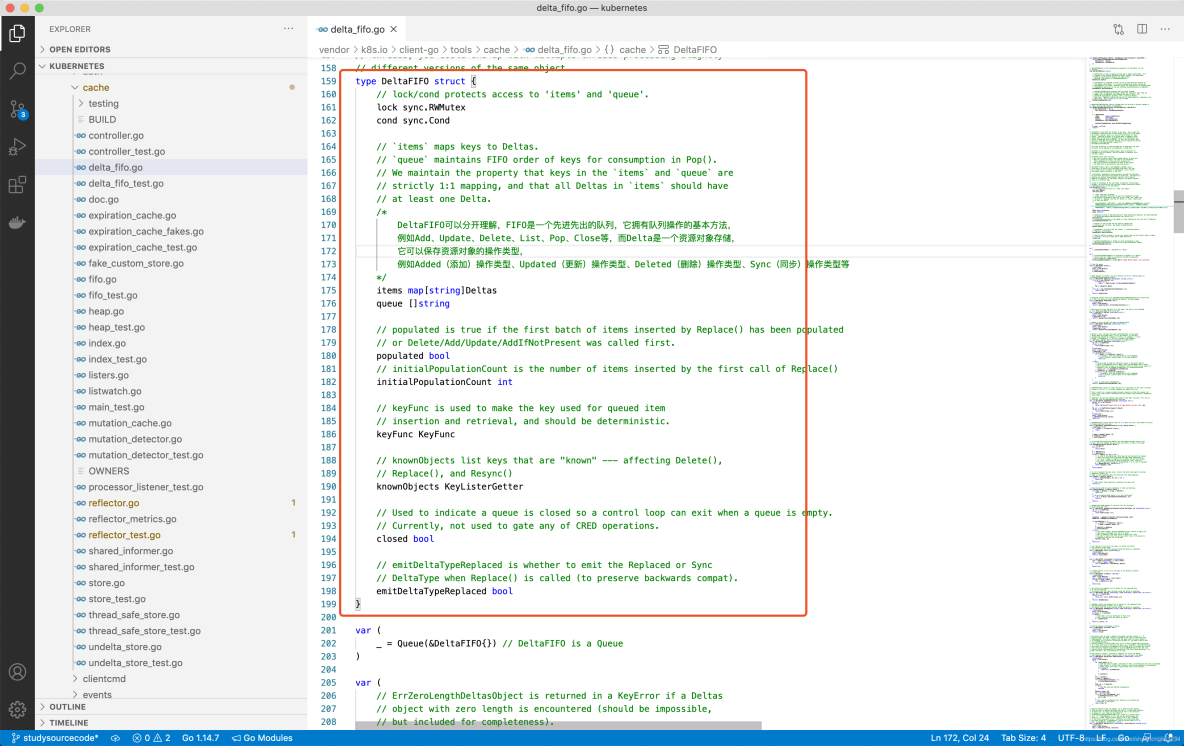
DeltaFIFO与其他队列最大的不同之处是,它会保留所有关于资源对象(obj)的操作类型,队列中会存在拥有不同操作类型的同一个资源对象,消费者在处理该资源对象时能够了解该资源对象所发生的事情。queue字段存储资源对象的key,该key通过KeyOf函数计算得到。items字段通过map数据结构的方式存储,value存储的是对象的Deltas数组。DeltaFIFO存储结构如图5-7所
DeltaFIFO本质上是一个先进先出的队列,有数据的生产者和消费者,其中生产者是Reflector调用的Add方法,消费者是Controller调用的Pop方法。下面分析DeltaFIFO的核心功能:生产者方法、消费者方法及Resync机制。
1.生产者方法
DeltaFIFO队列中的资源对象在Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件中都调用了queueActionLocked函数,它是DeltaFIFO实现的关键,代码示例如下: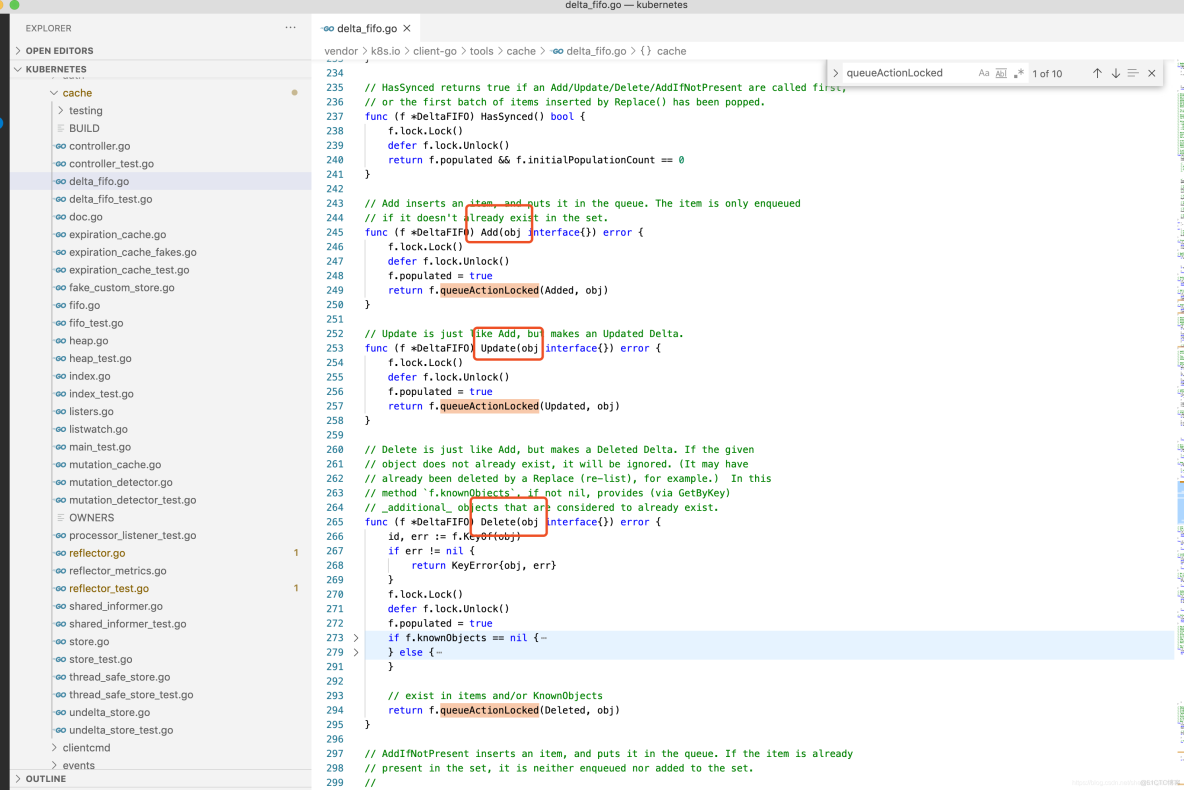
// queueActionLocked appends to the delta list for the object.
// Caller must lock first.
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
newDeltas := append(f.items[id], Delta{actionType, obj})
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
if _, exists := f.items[id]; !exists {
f.queue = append(f.queue, id)
}
f.items[id] = newDeltas
f.cond.Broadcast()
} else {
// This never happens, because dedupDeltas never returns an empty list
// when given a non-empty list (as it is here).
// But if somehow it ever does return an empty list, then
// We need to remove this from our map (extra items in the queue are
// ignored if they are not in the map).
delete(f.items, id)
}
return nil
}
queueActionLocked代码执行流程如下。
- (1)通过f.KeyOf函数计算出资源对象的key。
- (2)如果操作类型为Sync,则标识该数据来源于Indexer(本地存储)。如果Indexer中的资源对象已经被删除,则直接返回。
- (3)将actionType和资源对象构造成Delta,添加到items中,并通过dedupDeltas函数进行去重操作。
- (4)更新构造后的Delta并通过cond.Broadcast通知所有消费者解除阻塞。
2.消费者方法
Pop方法作为消费者方法使用,从DeltaFIFO的头部取出最早进入队列中的资源对象数据。Pop方法须传入process函数,用于接收并处理对象的回调方法,代码示例如下: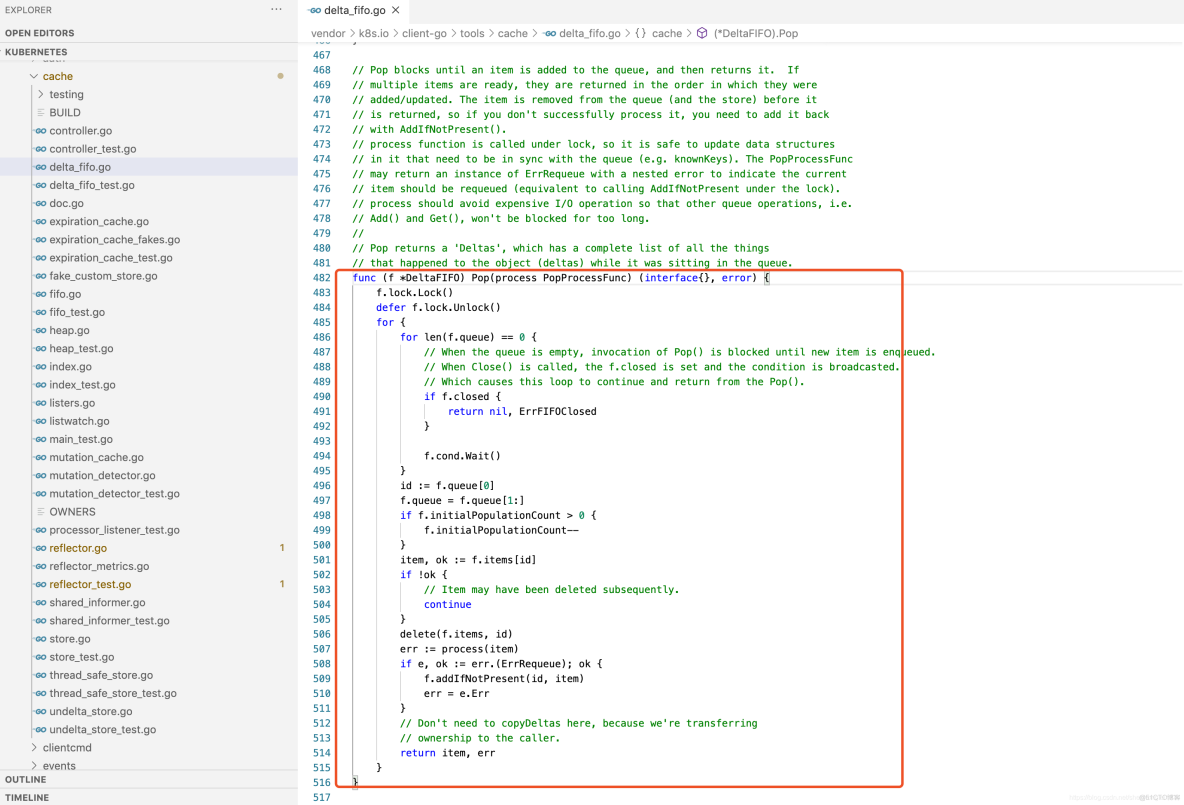
当队列中没有数据时,通过f.cond.wait阻塞等待数据,只有收到cond.Broadcast时才说明有数据被添加,解除当前阻塞状态。如果队列中不为空,取出f.queue的头部数据,将该对象传入process回调函数,由上层消费者进行处理。如果process回调函数处理出错,则将该对象重新存入队列。Controller的processLoop方法负责从DeltaFIFO队列中取出数据传递给process回调函数。process回调函数代码示例如下:
3.Resync机制
Resync机制会将Indexer本地存储中的资源对象同步到DeltaFIFO中,并将这些资源对象设置为Sync的操作类型。Resync函数在Reflector中定时执行,它的执行周期由NewReflector函数传入的resyncPeriod参数设定。Resync→syncKeyLocked代码示例如下:
5.3.4 Indexer
Indexer是client-go用来存储资源对象并自带索引功能的本地存储,Reflector从DeltaFIFO中将消费出来的资源对象存储至Indexer。Indexer中的数据与Etcd集群中的数据保持完全一致。client-go可以很方便地从本地存储中读取相应的资源对象数据,而无须每次都从远程Etcd集群中读取,这样可以减轻Kubernetes API Server和Etcd集群的压力。在介绍Indexer之前,先介绍一下ThreadSafeMap。ThreadSafeMap是实现并发安全的存储。作为存储,它拥有存储相关的增、删、改、查操作方法,例如Add、Update、Delete、List、Get、Replace、Resync等。Indexer在ThreadSafeMap的基础上进行了封装,它继承了与ThreadSafeMap相关的操作方法并实现了Indexer Func等功能,例如Index、IndexKeys、GetIndexers等方法,这些方法为ThreadSafeMap提供了索引功能。Indexer存储结构如图5-8所示。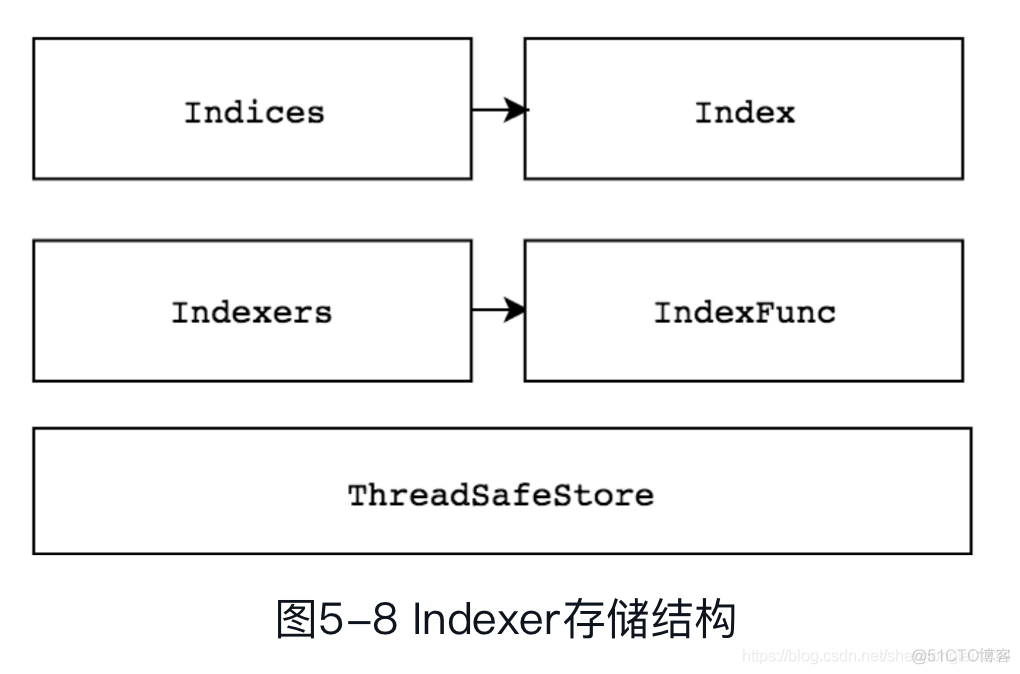
1.ThreadSafeMap并发安全存储
ThreadSafeMap是一个内存中的存储,其中的数据并不会写入本地磁盘中,每次的增、删、改、查操作都会加锁,以保证数据的一致性。ThreadSafeMap将资源对象数据存储于一个map数据结构中,ThreadSafeMap结构代码示例如下: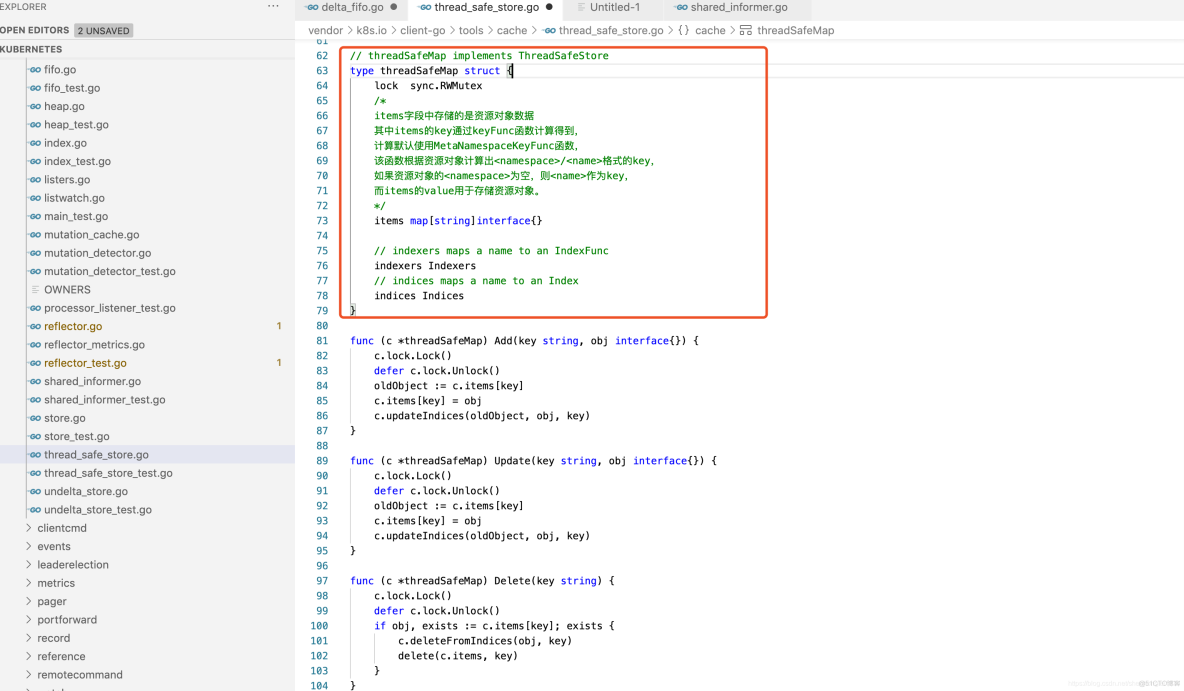
2. Indexer索引器
在每次增、删、改ThreadSafeMap数据时,都会通过updateIndices或deleteFromIndices函数变更Indexer。Indexer被设计为可以自定义索引函数,这符合Kubernetes高扩展性的特点。Indexer有4个非常重要的数据结构,分别是Indices、Index、Indexers及IndexFunc。直接阅读相关代码会比较晦涩,通过Indexer Example代码示例来理解Indexer,印象会更深刻。IndexerExample代码示例如下:
package main
import (
"fmt"
"strings"
"k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/tools/cache"
)
//索引器函数,查询出所有Pod资源下Annotations字段的key为users的Pod
func UserIndexFunc(obj interface{}) ([]string, error) {
pod := obj.(*v1.Pod)
userString := pod.Annotations["users"]
return strings.Split(userString, ","), nil
}
func main() {
/*
cache.NewIndexer函数实例化了Indexer对象,
该函数接收两个参数:第1个参数是KeyFunc,它用于计算资源对象的key,
计算默认使用cache.MetaNamespaceKeyFunc函数;第2个参数是cache.Indexers,
用于定义索引器,其中key为索引器的名称(即byUser),value为索引器。
通过index.Add函数添加3个Pod资源对象。
最后通过index.ByIndex函数查询byUser索引器下匹配ernie字段的Pod列表。
Indexer Example代码示例最终检索出名称为one和tre的Pod。
*/
index := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{"byUser": UserIndexFunc})
//创建三个pod资源对象
pod1 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "one", Annotations: map[string]string{"users": "ernie,bert"}}}
pod2 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "two", Annotations: map[string]string{"users": "bert,oscar"}}}
pod3 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "tre", Annotations: map[string]string{"users": "ernie,elmo"}}}
//添加Pod资源对象
index.Add(pod1)
index.Add(pod2)
index.Add(pod3)
//最后通过index.ByIndex函数查询byUser索引器下匹配ernie字段的Pod列表
erniePods, err := index.ByIndex("byUser", "ernie")
if err != nil {
panic(err)
}
for _, erniePod := range erniePods {
fmt.Println(erniePod.(*v1.Pod).Name)
}
}
//输出
one
tre
现在再来理解Indexer的4个重要的数据结构就非常容易了,它们分别是Indexers、IndexFunc、Indices、Index,数据结构如下: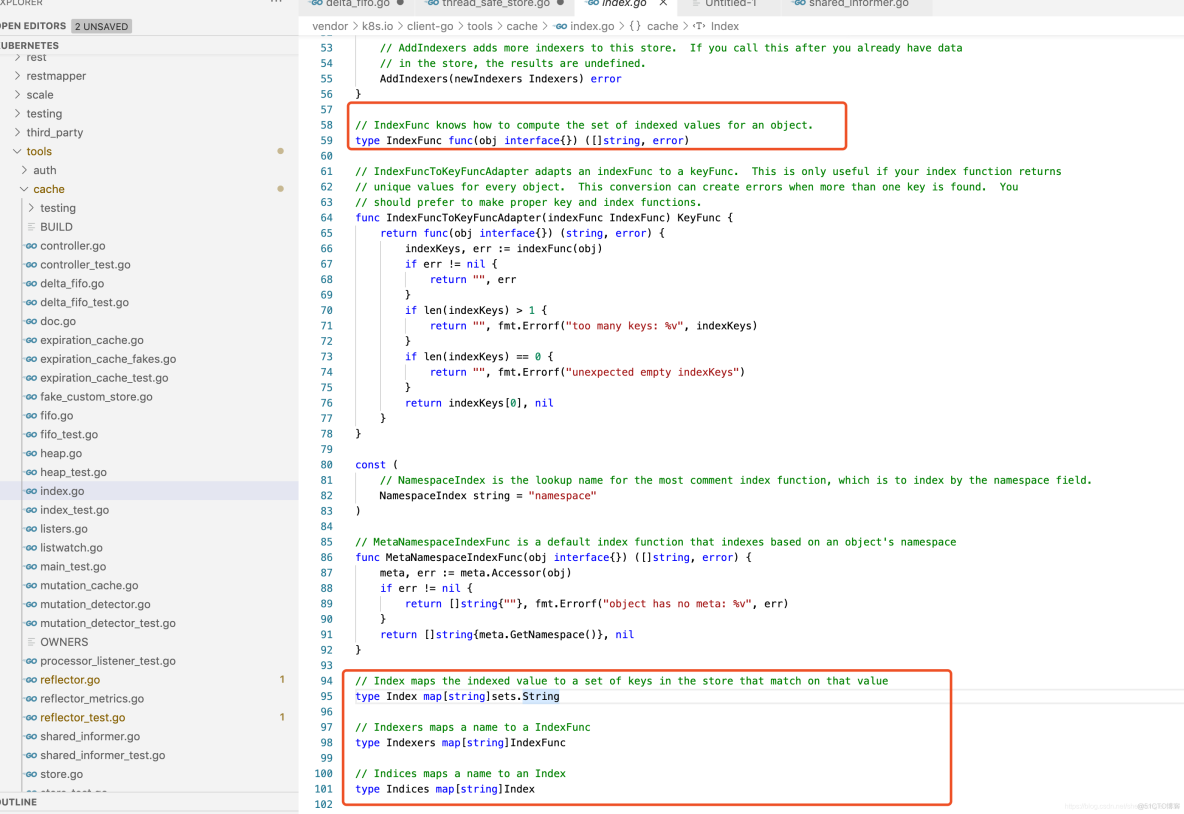
Indexer数据结构说明如下。
- Indexers:存储索引器,key为索引器名称,value为索引器的实现函数。
- IndexFunc:索引器函数,定义为接收一个资源对象,返回检索结果列表。
- Indices:存储缓存器,key为缓存器名称(在Indexer Example代码示例中,缓存器命名与索引器命名相对应),value为缓存数据。
- Index:存储缓存数据,其结构为K/V。
3. Indexer索引器核心实现
index.ByIndex函数通过执行索引器函数得到索引结果,代码示例如下: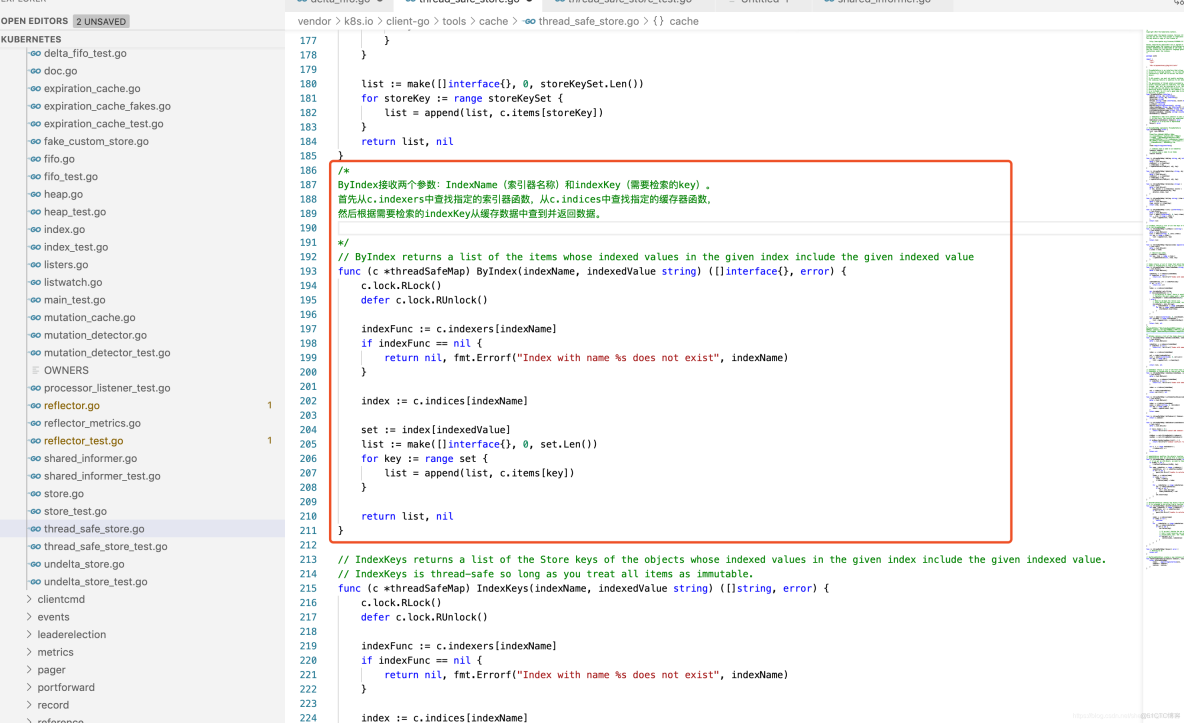
提示:Index中的缓存数据为Set集合数据结构,Set本质与Slice相同,但Set中不存在相同元素。由于Go语言标准库没有提供Set数据结构,Go语言中的map结构类型是不能存在相同key的,所以Kubernetes将map结构类型的key作为Set数据结构,实现Set去重特性。















