
连接浏览器
上一篇说到了Puppeteer本质是使用了Chrome Devtools协议控制浏览器,本篇就说说连接方式。
常规Hook浏览器
此方式其实就是需要一个浏览器可执行文件(不同平台需要下载对应平台文件),Puppeteer有两种方式,一种是安装Puppeteer包时下载的文件,另一种是自己下载文件通过环境变量指向文件路径就可以了(上篇文章有详细介绍),下面的演示为了视频我使用headless: false开启了FullHead模式。
在vscode里面使用export可查看环境变量

以上是我习惯的环境变量设置(使用launch参数executablePath也可达到同样效果,个人觉得环境变量更灵活),下面一段脚本来看看效果。
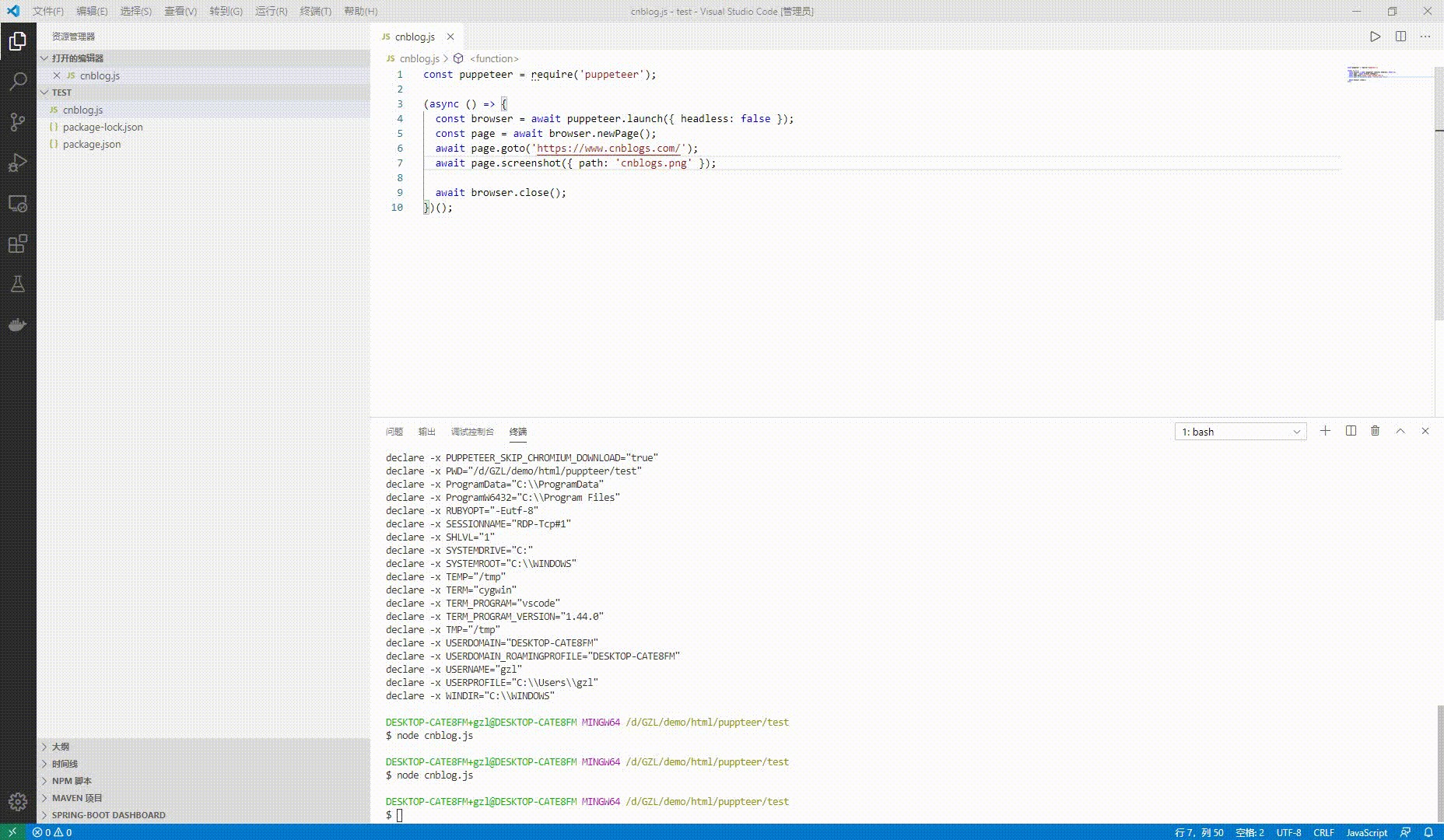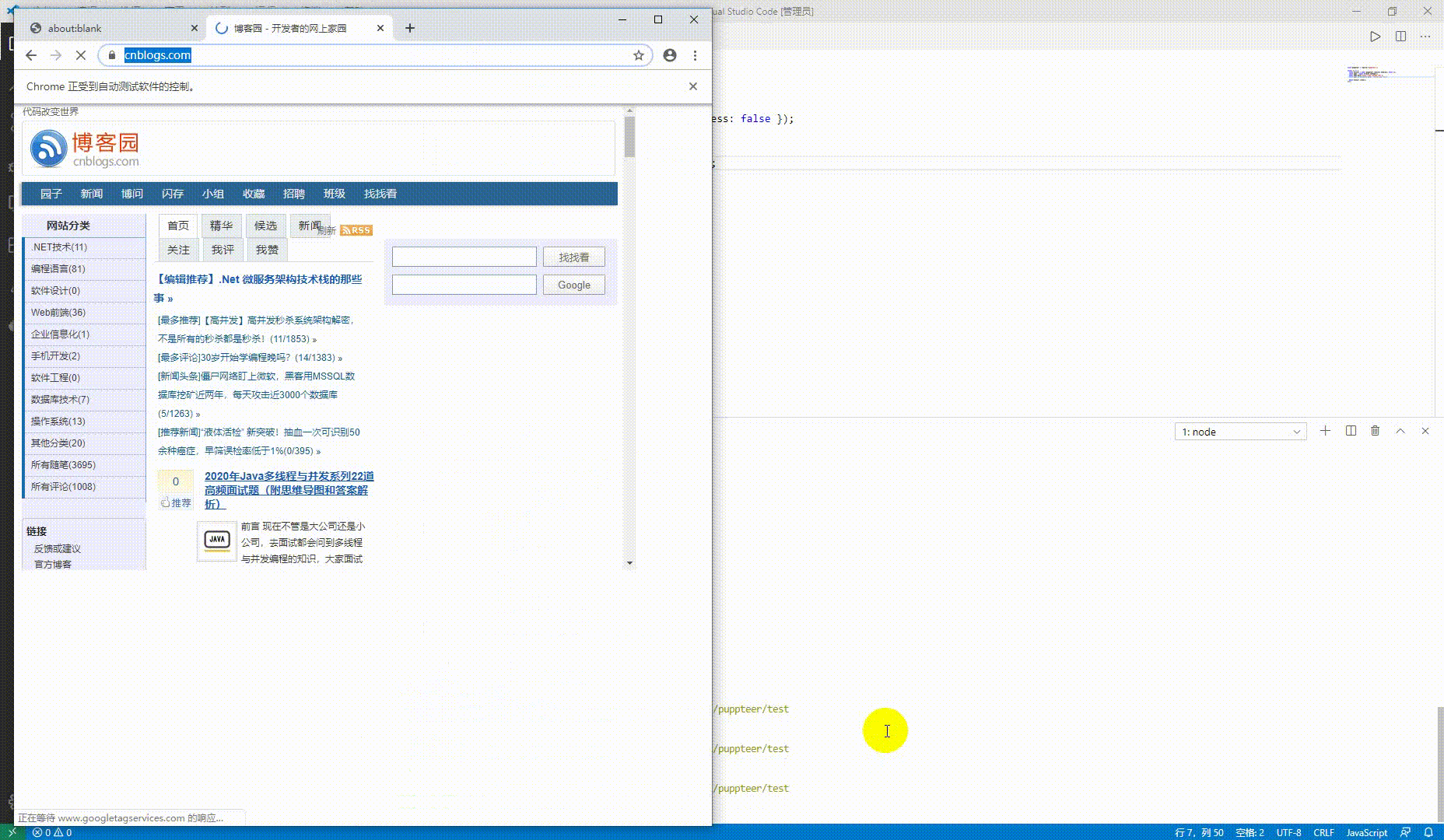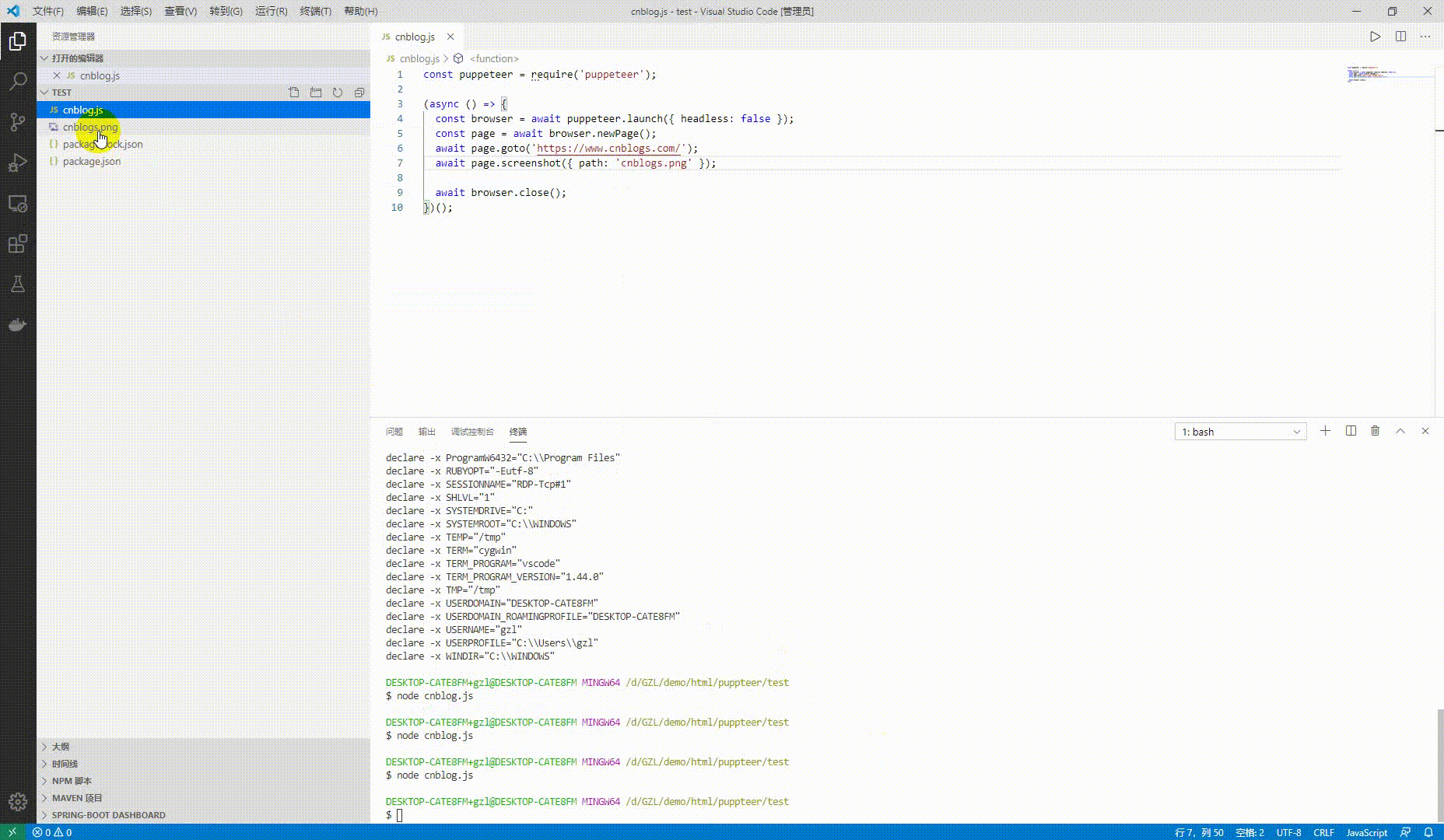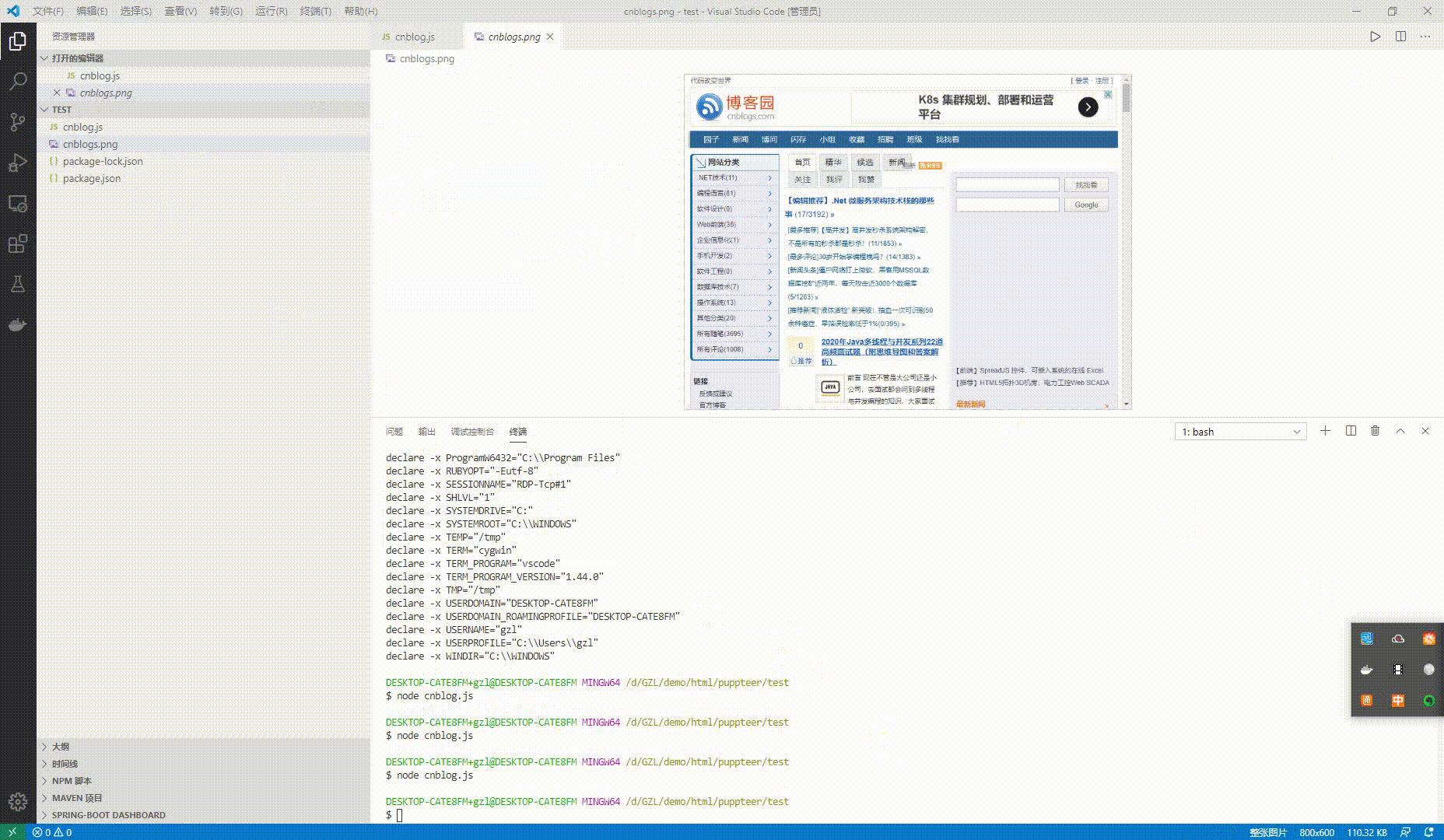
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('');
await page.screenshot({ path: 'cnblogs.png' });
await browser.close();
})();
使用已经存在的浏览器
首先开启浏览器远程调试,配置端口

在浏览器的快捷方式加上 --remote-debugging-port=9222 即可,详细配置
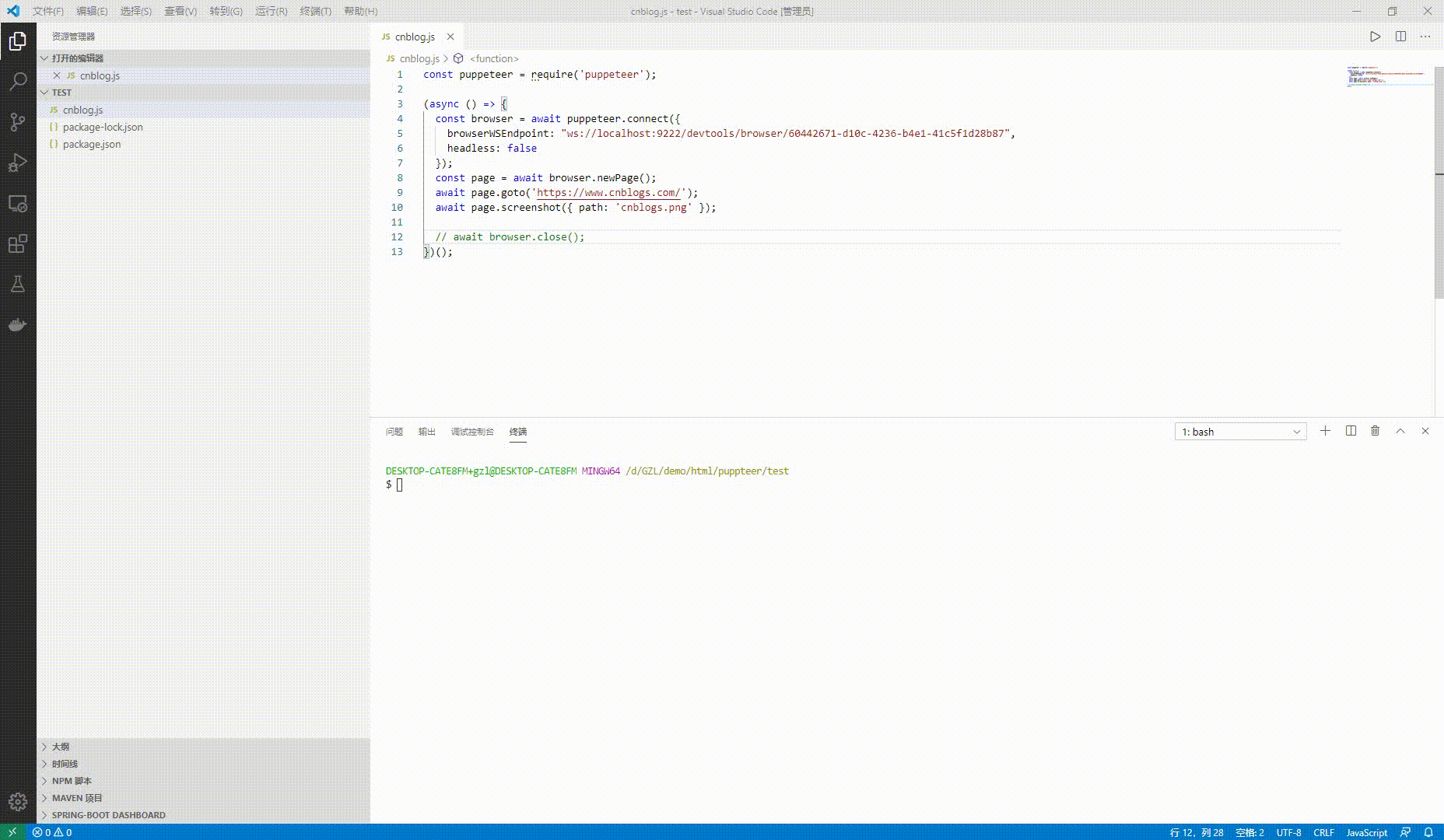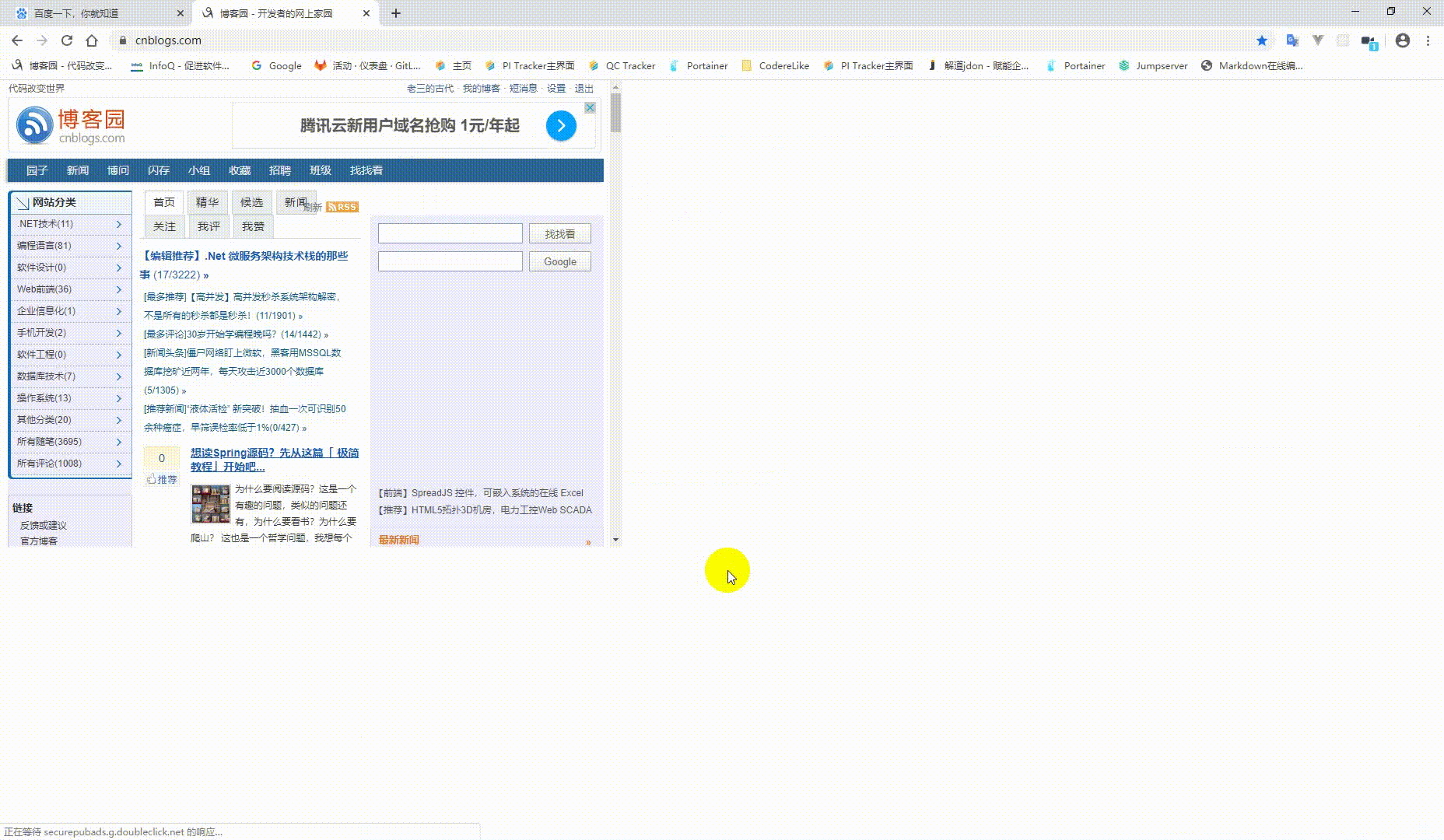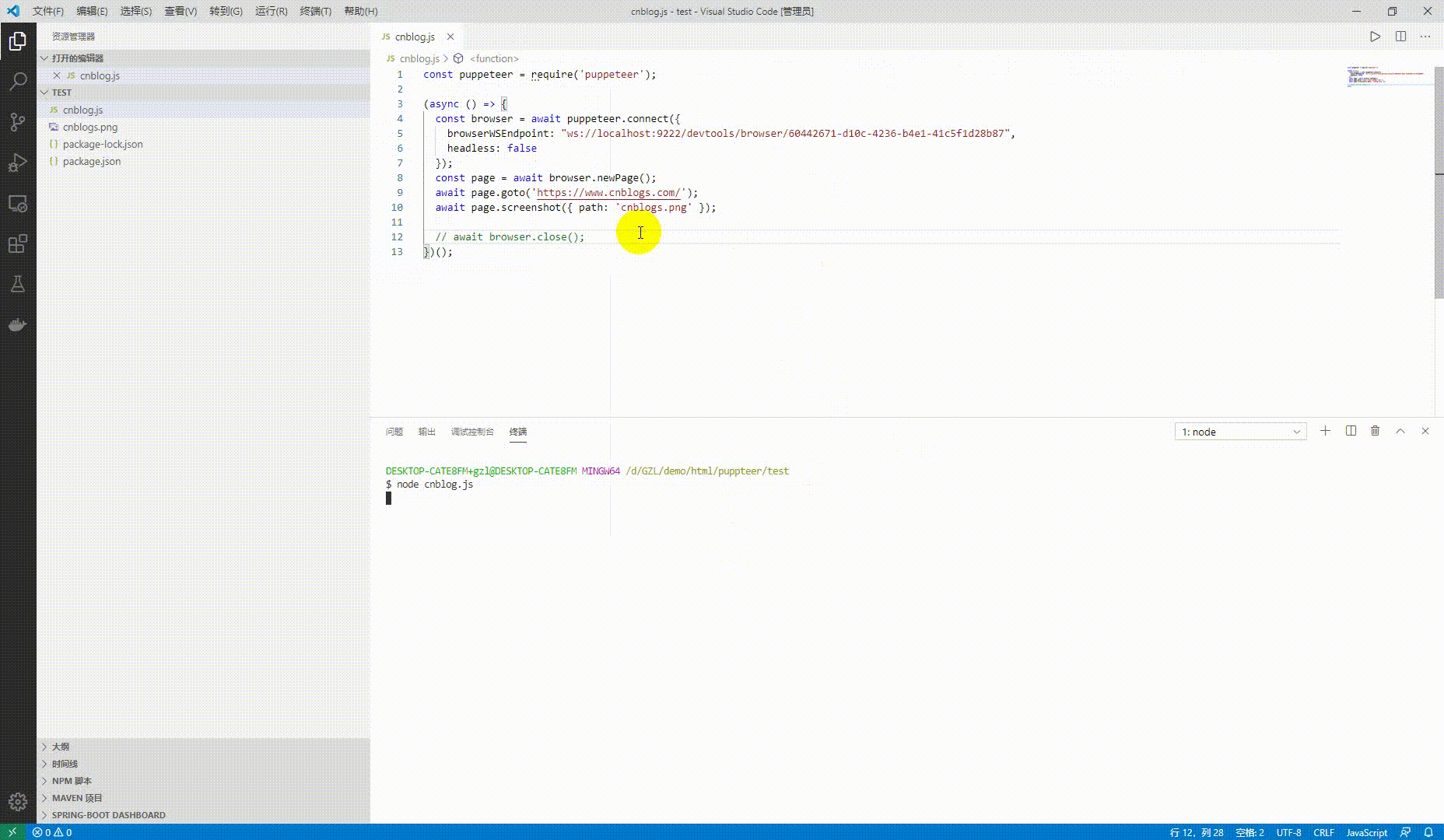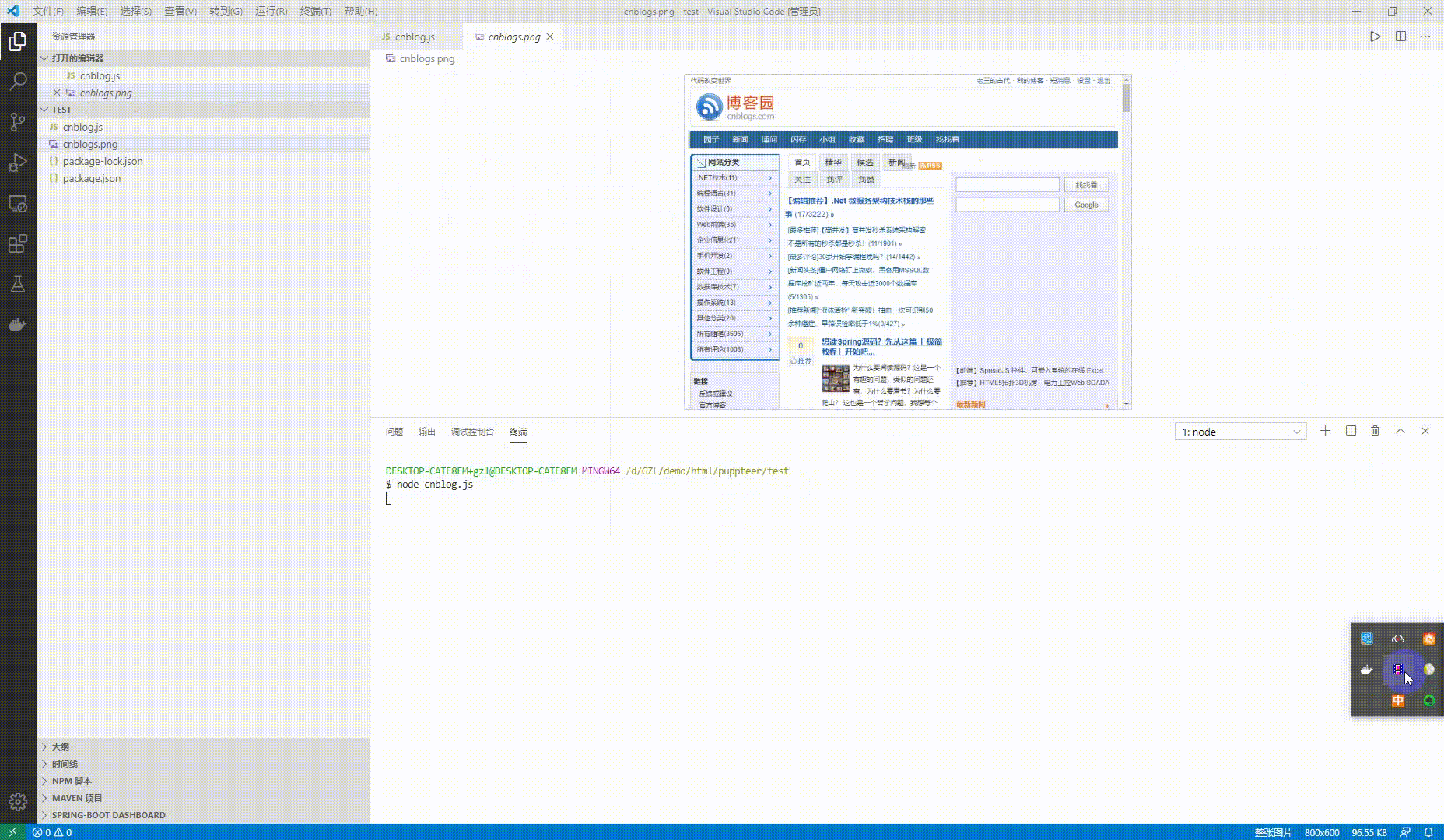
下面一段脚本来看看效果
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://localhost:9222/devtools/browser/60442671-d10c-4236-b4e1-41c5f1d28b87",
headless: false
});
const page = await browser.newPage();
await page.goto('');
await page.screenshot({ path: 'cnblogs.png' });
// await browser.close();
})();上面的代码可以看到browserWSEndpoint指定了一个地址,这个地址可以从下面获取

使用了Edge,嘿嘿🤭
上图看到了一些浏览器信息,主要是为了拿到browserWSEndpoint,切记这个地址是你打开的那个浏览器实例,也就是说每次打开后这个地址都会不同,测试的时候不要打开复制出来就关闭了,这样就找不到这个浏览器实例了,并且上面的信息在HeadLess与FullHead模式中式不太一样的。
现在已经能看到,Puppeteer的基本工作原理,下一篇将会介绍如何针对一个网站进行数据抓取,详细对puppeteer进行设置。目前Puppeteer的优势已经很明显了,那就是可以作到在服务端渲染(后面的文章会介绍如何在容器内运行,并且实现FullHead模式),当然selenium也能实现。皮皮虾😄
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















