
1.HDFS常用操作
HDFS文件操作有2种方式:命令行方式和API方式
我们以Hadoop自带的wordcout实例来演示HDFS分布式文件系统的命令行方式常用操作。
[liuqingjie@master ~]$ mkdir input
[liuqingjie@master ~]$ cd input/
[liuqingjie@master input]$ echo "hello world" >test1.txt
[liuqingjie@master input]$ echo "hello hadoop" >test2.txt
[liuqingjie@master input]$ cd ../hadoop-0.20.2
//将输入文件复制到分布式系统里(in)
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -put ../input in
//查看分布式系统里的文件
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./in/*
-rw-r--r-- 2 liuqingjie supergroup 12 2015-05-09 04:18 /user/liuqingjie/in/test1.txt
-rw-r--r-- 2 liuqingjie supergroup 13 2015-05-09 04:18 /user/liuqingjie/in/test2.txt
注意,/user/liuqingjie/in/ 并不是linux里面实际存在的目录,而是分布式系统里的虚拟根目录
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount in out
15/05/09 04:25:23 INFO input.FileInputFormat: Total input paths to process : 2
15/05/09 04:25:23 INFO mapred.JobClient: Running job: job_201505090340_0001
15/05/09 04:25:24 INFO mapred.JobClient: map 0% reduce 0%
15/05/09 04:25:35 INFO mapred.JobClient: map 50% reduce 0%
15/05/09 04:25:36 INFO mapred.JobClient: map 100% reduce 0%
15/05/09 04:25:47 INFO mapred.JobClient: map 100% reduce 100%
15/05/09 04:25:49 INFO mapred.JobClient: Job complete: job_201505090340_0001
15/05/09 04:25:49 INFO mapred.JobClient: Counters: 17
15/05/09 04:25:49 INFO mapred.JobClient: Job Counters
15/05/09 04:25:49 INFO mapred.JobClient: Launched reduce tasks=1
15/05/09 04:25:49 INFO mapred.JobClient: Launched map tasks=2
15/05/09 04:25:49 INFO mapred.JobClient: Data-local map tasks=2
15/05/09 04:25:49 INFO mapred.JobClient: FileSystemCounters
15/05/09 04:25:49 INFO mapred.JobClient: FILE_BYTES_READ=55
15/05/09 04:25:49 INFO mapred.JobClient: HDFS_BYTES_READ=25
15/05/09 04:25:49 INFO mapred.JobClient: FILE_BYTES_WRITTEN=180
15/05/09 04:25:49 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25
15/05/09 04:25:49 INFO mapred.JobClient: Map-Reduce Framework
15/05/09 04:25:49 INFO mapred.JobClient: Reduce input groups=3
15/05/09 04:25:49 INFO mapred.JobClient: Combine output records=4
15/05/09 04:25:49 INFO mapred.JobClient: Map input records=2
15/05/09 04:25:49 INFO mapred.JobClient: Reduce shuffle bytes=61
15/05/09 04:25:49 INFO mapred.JobClient: Reduce output records=3
15/05/09 04:25:49 INFO mapred.JobClient: Spilled Records=8
15/05/09 04:25:49 INFO mapred.JobClient: Map output bytes=41
15/05/09 04:25:49 INFO mapred.JobClient: Combine input records=4
15/05/09 04:25:49 INFO mapred.JobClient: Map output records=4
15/05/09 04:25:49 INFO mapred.JobClient: Reduce input records=4
//查看测试结果
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:18 /user/liuqingjie/in
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out/_logs
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -cat ./out/*
hadoop1
hello2
world1
//将HDFS的文件复制到本地
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -get ./out ./xyz
[liuqingjie@master hadoop-0.20.2]$ ll
drwxrwxr-x. 3 liuqingjie liuqingjie 4096 May 9 05:37 xyz
//删除HDFS下的文档
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 2 items
drwxr-xr-x - liuqingjie supergroup 0 2015-05-09 04:25 /user/liuqingjie/out/_logs
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -rmr ./out/_logs
Deleted hdfs://master:9000/user/liuqingjie/out/_logs
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfs -ls ./out
Found 1 items
-rw-r--r-- 2 liuqingjie supergroup 25 2015-05-09 04:25 /user/liuqingjie/out/part-r-00000
//查看HDFS基本统计信息
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -report
Configured Capacity: 38516342784 (35.87 GB)
Present Capacity: 29941987116 (27.89 GB)
DFS Remaining: 29941833728 (27.89 GB)
DFS Used: 153388 (149.79 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.132.132:50010
Decommission Status : Normal
Configured Capacity: 19770150912 (18.41 GB)
DFS Used: 76694 (74.9 KB)
Non DFS Used: 4366947434 (4.07 GB)
DFS Remaining: 15403126784(14.35 GB)
DFS Used%: 0%
DFS Remaining%: 77.91%
Last contact: Sat May 09 05:42:42 PDT 2015
Name: 192.168.132.131:50010
Decommission Status : Normal
Configured Capacity: 18746191872 (17.46 GB)
DFS Used: 76694 (74.9 KB)
Non DFS Used: 4207408234 (3.92 GB)
DFS Remaining: 14538706944(13.54 GB)
DFS Used%: 0%
DFS Remaining%: 77.56%
Last contact: Sat May 09 05:42:41 PDT 2015
//进入和退出安全模式
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -safemode enter
Safe mode is ON
[liuqingjie@master hadoop-0.20.2]$ bin/hadoop dfsadmin -safemode leave
Safe mode is OFF
2.HDFS设计原理
(1)HDSF设计基础与目标
硬件错误是常态。因此需要冗余
流式数据访问。即数据批量读取而非随机读写,Hadoop擅长做的是数据分析而不是事务处理
大规模数据集
简单一致性模型。为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写入,关闭,就再也不能修改
程序采用“数据就近”原则分配节点执行
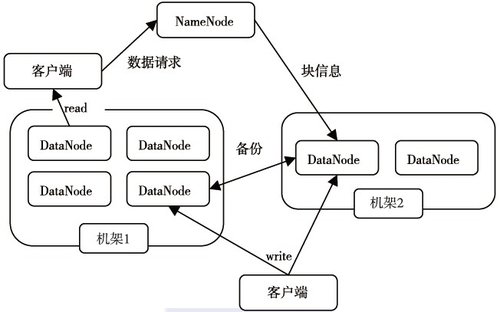
(2)HDFS体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。下图给出了HDFS的体系结构。
NameNode
管理文件系统的命名空间
记录每个文件数据块在各个Datanode上的位置和副本信息
协调客户端对文件的访问
记录命名空间内的改动或空间本身属性的改动
Namenode使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命
名空间,包括文件映射,文件属性等
DataNode
负责所在物理节点的存储管理
一次写入,多次读取(不修改)
文件由数据块组成,典型的块大小是64MB
数据块尽量散布道各个节点
数据读取流程
客户端要访问HDFS中的一个文件,首先从namenode获得组成这个文件的数据块位置列表,根据列表知道存储数据块的datanode,访问datanode获取数据。Namenode并不参与数据实际传输。
(3)HDSF的可靠性理念
a.冗余副本策略
*可以在hdfs-site.xml中设置复制因子指定副本数量
*所有数据块都有副本
*Datanode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列
表(blockreport)汇报给namenode
b.机架策略
*集群一般放在不同机架上,机架间带宽要比机架内带宽要小
HDFS的“机架感知”
*一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时
丢失数据,也可以提高带宽利用率
c.心跳机制
*Namenode周期性从datanode接收心跳信号和块报告
*Namenode根据块报告验证元数据
*没有按时发送心跳的datanode会被标记为宕机,不会再给它任何I/O请求
*如果datanode失效造成副本数量下降,并且低于预先设置的阈值,namenode会检测
出这些数据块,并在合适的时机进行重新复制
*引发重新复制的原因还包括数据副本本身损坏、磁盘错误,复制因子被增大等
d.安全模式
*Namenode启动时会先经过一个“安全模式”阶段
*安全模式阶段不会产生数据写
*在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为 是“安全”的
*在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
*当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数
e.校验和
*在文件创立时,每个数据块都产生校验和
*校验和会作为单独一个隐藏文件保存在命名空间下
*客户端获取数据时可以检查校验和是否相同,从而发现数据块是否损坏
*如果正在读取的数据块损坏,则可以继续读取其它副本
f.回收站
*删除文件时,其实是放入回收站/trash
*回收站里的文件可以快速恢复
*可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值,就被彻底删除,
并且释放占用的数据块
g.元数据保护
*映像文件刚和事务日志是Namenode的核心数据。可以配置为拥有多个副本
*副本会降低Namenode的处理速度,但增加安全性
*Namenode依然是单点,如果发生故障要手工切换
h.快照机制
*支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态
*Hadoop目前还不支持快照,已经列入开发计划




















