
正则表达式分为扩展正则表达式和基本正则表达式,它寻于一个管理员来说是非常重要的。因为管理员很多时候用到主样的表达方式 来快速的查找、替换、操作等;所以对正则表达式的掌握程度也反应了一个管理员的工作效率和质量。
下面我就总结一个我的理解:
在说正则表达式之前我样先说几个文件名通配的特殊字符,因为它极易使我们混淆正则表达式的的一些特殊字符:
文件名通配的特殊字符:
glob:就是我们在匹配文件名时能使用某种特殊的字符来通配具有某种特征的 一类文件。
*:任意长度的任意字符
?:任意单个字符
[]:指定范围内的任意单个字符
[a-z]:任意单个小写字母
[A-Z]:任意单个大写字母
[0-9]:任意数字
[:digit:]:表示所有的数字
[:lower:]:所有的小写字母
[:upper:]:所有的大写字母
[:alnum:]:所有字母加数字
[:space:]:所有的空白字符
[:alpha:]:所有的字母
[:punct:]:所有的标点符号
示例如下图:
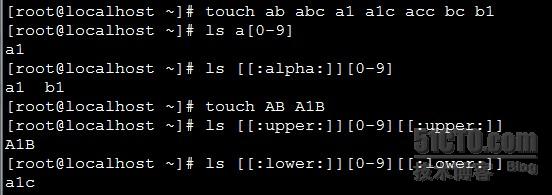
使用glob匹配的仅是文件名,而不能通本到文件中的,内容。
下面就来讲述正则表达式:
下则表达式分为基本正则表达式和扩展正则表达式:
基本正则表达式grep的使用:
grep的模式我们可以用单引号和双引号引起来,不过在模式中如果有变量的话就只能用双引号了。另外grep仅支持基本正则表达式
元字符常用的有如下:
我们在一个a.txt的文件中写入了

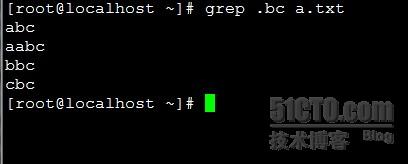
.:匹配任意单个字符 ;只要b前面有一个字符无论是什么字符无论有几个,那么就可以匹配;如下图:
[]:指定范围内的任意单个字符
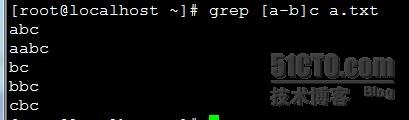
[^]: 非的意思,比如我们前面的大写[:upper:] 我们如果要表示非大写那么 就要用[^[:upper:]]. 例如 我们筛选不是以a-b开关的行。则如下:

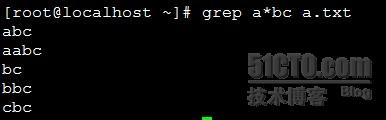
*: 表示匹配其前面的字符任意次
 a
a
X\{m,n\}: 表示匹配前面的字符X至少m次,至多n次 ,'\'表示转意符。
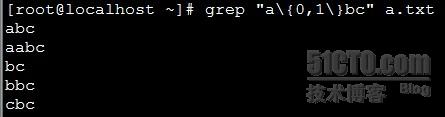
X\{m,\}
X\{0,n\}
?: 匹配其前的字符0次或1次
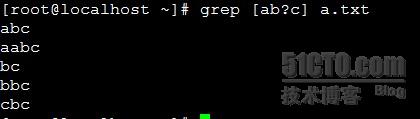
锚定符:
^:锚定行首,下面台筛选出以a开头的行则:

$:锚定行尾
^$:表示空白行“”
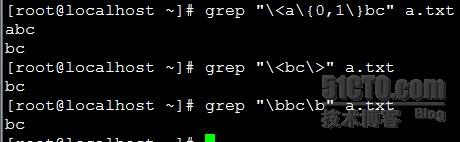
\<:锚定词首 -- 也可以用\b
\>:锚定词尾 -- 也可以用\b
\(\):分组 然后用\1,\2……来引用前面的分组;\1表示引用前面第一个组括 号内的内容,\2是引用 第二个括号内的内容,以此类推:
如下我们建立如下文件:
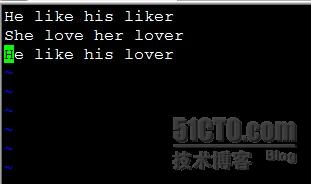
我们做如下操作为例:

下面主要列举重要的筛选工具 grep的一些选项:
-v:对结果取反
-i:忽略字母大小写
-o:仅显示匹配到的字符串
-E:支持扩展正则表达式。
-A n:表示显示匹配到的行的下n行
-B n: 显示匹配到的行的上n行
-C n: 显示匹配到的行的上下n行。
扩展正则表达式的使用 grep -E 或 egrep:
\(\):--> ()
\{\}:--> {}
+:次数匹配,匹配其前的字符至少1次
|:或者 a|b, 用法如: (c|C)at:可以匹配到:Cat,cat


















