
2 测试环境
Eclipse-version : Juno Service Release 1,hadoop-version hadoop-1.0.4,hbase -version hbase-0.92.0, jdk-version: 1.6.0_31
1 在ubuntu 12.04的版本中已经安装了ssh-client,这里还需要进行ssh-server的安装。安装如下图:

图-ssh-server安装
2 使用主节点上的ssh-keygen生成rsa密钥对,务必避免输入密码,否则每次节点启动的时候都会提示输入密码。生成方式如下(一路回车即可):

图-keygen生成
3 对生成的密钥进行授权:

图-授权
注:在生成密钥对时需要注意用户,如果是普通用户则在生成keygen的时候不需要加sudo ex:ssh-keygen -t rsa -P “”。如果为管理员账户则需要加入sudo来执行 ex: sudo ssh-keygen -t rsa -P “”
1. 将下载的hadoop压缩文件进行解压,我解压的目录是在 “下载” 目录。
2. 对解压的hadoop进行配置,打开conf/目录。编辑hadoop-env.sh文件
对里面的java_home进行设置。

图- java_home设置
3.对core_site.xml文件进行配置,以下分别对主机节点的地址和存储文件的路径进行配置,文件路径默认情况是存在/tmp/目录下的。

图- core-site.xml配置
4. 对mapred-site.xml进行配置,以下是对job的主机端口的配置

图 - mapred-site.xml设置
5.在启动主机之前学要对hdfs系统进行格式化。Bin/hadoop namenode -format 格式化之后会在你配置文件给定的目录中生成一个hdfs的工作目录。

图-hdfs工作目录生成
6.启动hdfs。这里的datanode jobtracker都在同一主机上运行。启动时需要注意不是直接运行bin/start-all.sh文件。而是按以下顺序来运行。引文在单个注意上运行时datanode namenode jobtracker tasktracker 等都是在同一主机上运行。但是在运行时候有一定的依赖关系。所以需要按顺序启动。执行情况如下图:

图-启动流程 查看启动情况
到现在为止,hadoop已经成功启动,所有节点都并运行在本机上。如果需要查看namenode的状况可以访问 www.localhost:50070。查看map/reduce的状况访问 www.localhost:50030。信息如下:

图-namenode信息

图-map/reduce信息
1.版本在上面已经提到,这里直接将下载的压缩文件解压到自定义目录。我是解压的“下载”目录
2.对解压的文件进行配置。打开con/目录。编辑hbase-env.sh,进行java_home的配置。

图-hbase java_home配置
3.编辑hbase-site.xml文件。定义hbase和zookeeper(可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等)的文件存储目录。以及zookeeper的主机节点

图-hbase hbase-site.xml
4.启动hbase,并进入建表模式。

图-base启动
1.新建立java工程
2.将hbase解压文件下的conf/目录中的hbase-site.xml拷贝到eclipse的src根目录下。
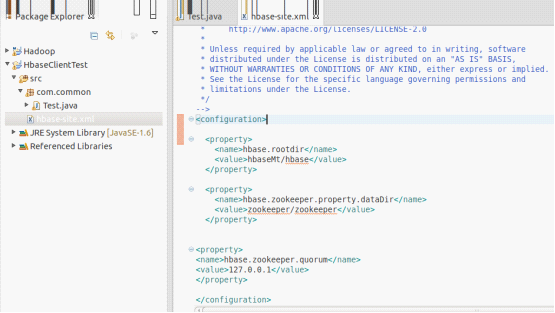
图- eclipse配置文件
3.进入eclipse点击添加额外的jar包选项。将hbase根目录下的两个jar包和lib/文件夹下的jar包全部引入。
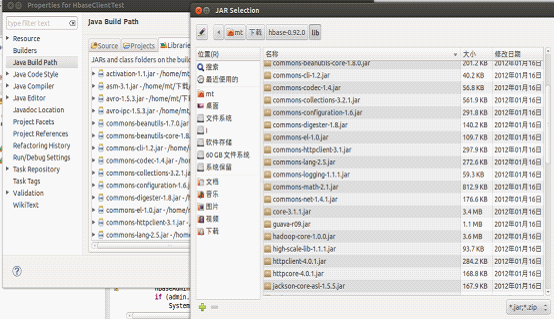
图-添加jar包到工程中
4.编写测试类进行测试。测试结果如下图:

图-运行结果


















