
本文介绍了十三个常见的Linux性能监测工具,可以检测系统负载、硬件系统信息、进程状态、内存使用情况等一系列参数。针对每个工具,文章介绍了该工具的功能、使用方法以及输出样式,参考起来十分方便。
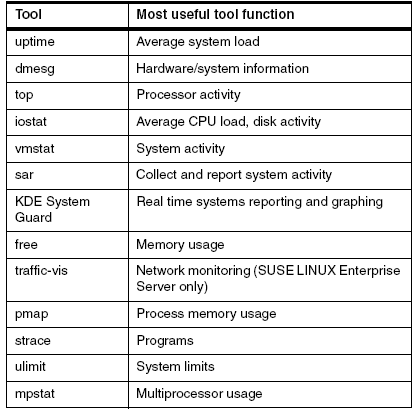
表-Linux性能监测工具
1、uptime
uptime命令用于查看服务器运行了多长时间以及有多少个用户登录,快速获知服务器的负荷情况。
uptime的输出包含一项内容是load average,显示了最近1-,5-,15分钟的负荷情况。它的值代表等待CPU处理的进程数,如果CPU没有时间处理这些进程,load average值会升高;反之则会降低。
load average的最佳值是1,说明每个进程都可以马上处理并且没有CPU cycles被丢失。对于单CPU的机器,1或者2是可以接受的值;对于多路CPU的机器,load average值可能在8到10之间。
也可以使用uptime命令来判断网络性能。例如,某个网络应用性能很低,通过运行uptime查看服务器的负荷是否很高,如果不是,那么问题应该是网络方面造成的。
# uptime
15:31:18 up 5:47, 3 users, load average: 0.16, 0.19, 0.13
2、dmesg
dmesg命令主要用来显示内核信息。使用dmesg可以有效诊断机器硬件故障或者添加硬件出现的问题。
另外,使用dmesg可以确定您的服务器安装了那些硬件。每次系统重启,系统都会检查所有硬件并将信息记录下来。执行/bin/dmesg命令可以查看该记录。
3、top
top命令显示处理器的活动状况。缺省情况下,显示占用CPU最多的任务,并且每隔5秒钟做一次刷新。
3.1 Process priority and nice levels
Process priority的数值决定了CPU处理进程的顺序。LIUNX内核会根据需要调整该数值的大小。nicevalue局限于priority。priority的值不能低于nice value(nicevalue值越低,优先级越高)。您不可以直接修改Process priority的值,但是可以通过调整nicelevel值来间接地改变Process priority值,然而这一方法并不是所有时候都可用。如果某个进程运行异常的慢,可以通过降低nicelevel为该进程分配更多的CPU。
Linux 支持的 nice levels 由19 (优先级低)到-20 (优先级高),缺省值为0。
执行/bin/ps命令可以查看到当前进程的情况。
4、iostat
iostat由Red Hat Enterprise Linux AS发布。同时iostat也是Sysstat的一部分,可以下载到,网址是http://perso.wanadoo.fr/sebastien.godard/
执行iostat命令可以从系统启动之后的CPU平均时间,类似于uptime。除此之外,iostat还对创建一个服务器磁盘子系统的活动报告。该报告包含两部分:CPU使用情况和磁盘使用情况。
下边是iostat的输出样式
# iostat ALL -1
avg-cpu: %user %nice %system %iowait %steal %idle
14.29 0.00 4.84 0.00 0.00 80.87
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
ram0 0.00 0.00 0.00 0 0
ram1 0.00 0.00 0.00 0 0
ram2 0.00 0.00 0.00 0 0
ram3 0.00 0.00 0.00 0 0
ram4 0.00 0.00 0.00 0 0
ram5 0.00 0.00 0.00 0 0
ram6 0.00 0.00 0.00 0 0
ram7 0.00 0.00 0.00 0 0
ram8 0.00 0.00 0.00 0 0
ram9 0.00 0.00 0.00 0 0
ram10 0.00 0.00 0.00 0 0
ram11 0.00 0.00 0.00 0 0
ram12 0.00 0.00 0.00 0 0
ram13 0.00 0.00 0.00 0 0
ram14 0.00 0.00 0.00 0 0
ram15 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
loop1 0.00 0.00 0.00 0 0
loop2 0.00 0.00 0.00 0 0
loop3 0.00 0.00 0.00 0 0
loop4 0.00 0.00 0.00 0 0
loop5 0.00 0.00 0.00 0 0
loop6 0.00 0.00 0.00 0 0
loop7 0.00 0.00 0.00 0 0
sda 4.00 0.00 64.00 0 64
CPU占用情况包括四块内容
%user:显示user level (applications)时,CPU的占用情况。
%nice:显示user level在nice priority时,CPU的占用情况。
%sys:显示system level (kernel)时,CPU的占用情况。
%idle: 显示CPU空闲时间所占比例。
磁盘使用报告分成以下几个部分:
Device: 块设备的名字
tps: 该设备每秒I/O传输的次数。多个I/O请求可以组合为一个,每个I/O请求传输的字节数不同,因此可以将多个I/O请求合并为一个。
Blk_read/s, Blk_wrtn/s: 表示从该设备每秒读写的数据块数量。块的大小可以不同,如1024, 2048 或 4048字节,这取决于partition的大小。
例如,执行下列命令获得设备/dev/sda1 的数据块大小:
dumpe2fs -h /dev/sda1 |grep -F "Block size"
输出结果如下
dumpe2fs 1.34 (25-Jul-2003)
Block size: 1024
Blk_read, Blk_wrtn: 指示自从系统启动之后数据块读/写的合计数。
5、vmstat
vmstat提供了processes, memory, paging, block I/O, traps和CPU的活动状况.
下边是vmstat的输出样式
vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 225436 325116 773332 0 0 37 40 172 373 9 4 86 1 0
0 0 0 220600 325116 777060 0 0 0 32 5202 11515 17 7 76 0 0
1 0 0 220228 325116 776952 0 0 0 108 4892 11146 16 5 78 0 0
1 0 0 219296 325116 776888 0 0 0 32 4906 11163 17 5 78 0 0各输出列的含义:
Process
– r: 等待runtime的进程数
– b: 在不可打断的休眠状态下的进程数
Memory
– swpd: 虚拟内存使用量(KB)
– free: 闲置内存使用量(KB)
– buff: 被当做buffer使用的内存量(KB)
Swap
– si: swap到磁盘的内存量(KBps)
– so: 从磁盘swap出去的内存量(KBps)
IO
– bi: Blocks sent to a block device (blocks/s).
– bo: Blocks received from a block device (blocks/s).
System
– in: The number of interrupts per second, including the clock.
– cs: The number of context switches per second.
CPU (these are percentages of total CPU time)
- us: Time spent running non-kernel code (user time, including nice time).
– sy: Time spent running kernel code (system time).
– id: Time spent idle. Prior to Linux 2.5.41, this included IO-wait time.
– wa: Time spent waiting for IO. Prior to Linux 2.5.41, this appeared as zero.
6 sar
sar是Red Hat Enterprise Linux AS发行的一个工具,同时也是Sysstat工具集的命令之一,可以从以下网址下载:http://perso.wanadoo.fr/sebastien.godard/
sar用于收集、报告或者保存系统活动信息。
sar由三个应用组成:sar显示数据、sar1和sar2用于收集和保存数据。
使用sar1和sar2,系统能够配置成自动抓取信息和日志,以备分析使用。
可以配置在/etc/crontab中定时抓取数据。------未实现
同样的,你也可以在命令行方式下使用sar运行实时报告。如图所示:
从收集的信息中,可以得到详细的CPU使用情况(%user, %nice, %system, %idle)、内存页面调度、网络I/O、进程活动、块设备活动、以及interrupts/second
#sar -u 3 10
Linux 2.6.32-220.el6.x86_64 (localhost.localdomain) 2012年09月17日 _x86_64_ (4 CPU)
15时43分36秒 CPU %user %nice %system %iowait %steal %idle
15时43分39秒 all 15.78 0.00 5.50 0.89 0.00 77.83
15时43分42秒 all 15.84 0.00 5.58 0.81 0.00 77.77
15时43分45秒 all 18.86 0.00 5.04 0.41 0.00 75.69
7 KDE System Guard
8 free
/bin/free命令显示所有空闲的和使用的内存数量,包括swap。同时也包含内核使用的缓存。
# free
total used free shared buffers cached
Mem: 3719516 3517456 202060 0 326596 773868
-/+ buffers/cache: 2416992 1302524
Swap: 4194296 0 4194296total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
9 Traffic-vis
10 pmap
pmap可以报告某个或多个进程的内存使用情况。使用pmap判断主机中哪个进程因占用过多内存导致内存瓶颈。图14-9显示了SUSE LINUX
Enterprise Server下pmap命令执行结果
pmap -x <pid>
pmap <pid>
pmap -x 4576
4576: ./qq
Address Kbytes RSS Dirty Mode Mapping
0000000000110000 900 268 0 r-x-- libstdc++.so.6.0.13
00000000001f1000 16 16 16 r---- libstdc++.so.6.0.13
00000000001f5000 8 8 8 rw--- libstdc++.so.6.0.13
......
00000000001f7000 24 8 8 rw--- [ anon ]
00000000f779c000 72 64 0 r---- gtk20.mo
00000000f77ae000 4 4 4 rw--- [ anon ]
00000000ffe05000 84 36 36 rw--- [ stack ]
---------------- ------ ------ ------
total kB 100160 18164 8956
11 strace
strace截取和记录系统进程调用,以及进程收到的信号。是一个非常有效的检测、指导和调试工具。系统管理员可以通过该命令容易地解决程序问题。
使用该命令需要指明进程的ID(PID),例如:
strace -p <pid>
12 ulimit
ulimit内置在bash shell中,用来提供对shell和进程可用资源的控制
使用选项-a列出可以设置的所有参数:
ulimit -a
# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 28905
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 10000
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
13 mpstat
mpstat是Sysstat工具集的一部分,下载地址是http://perso.wanadoo.fr/sebastien.godard/
mpstat用于报告多路CPU主机的每颗CPU活动情况,以及整个主机的CPU情况。
例如,下边的命令可以隔2秒报告一次处理器的活动情况,执行3次
# mpstat 2 3
Linux 2.6.32-220.el6.x86_64 (localhost.localdomain) 2012年09月17日 _x86_64_ (4 CPU)
15时57分54秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
15时57分56秒 all 3.58 0.00 4.77 0.00 0.00 0.36 0.00 2.74 88.56
15时57分58秒 all 3.73 0.00 4.45 1.32 0.00 0.36 0.00 2.76 87.38
15时58分00秒 all 4.07 0.00 4.67 0.00 0.00 0.36 0.00 2.87 88.04
平均时间: all 3.79 0.00 4.63 0.44 0.00 0.36 0.00 2.79 87.99

















