
XML 是一种标记语言(Markup Language),就像html一样。只不过没有预先定义的便签,也就是可以随便定义便签,且浏览器也不会去解析。 用于存储信息(少量数据或软件配置信息),并且这种存储是独立于软件和硬件的。现已被广泛应用于互联网和各种程序之中。就是一个规范、标准,大家遵守这个规范去存储信息,可以增加软件通用性,增加便利,所以我们也要使用。这就如同统一度量衡一个意思,顺应全球化发展。而这也是和html不同的地方:html被用来显示数据,它专注于怎么显示,而xml专注于存储什么数据。 JAVA解析XML 编程接口 作为程序员,最关注的就是如何编程操作xml。对此,w3c提供了DOM编程接口(只有接口,没有实现类;这也算面向接口编程。),另一个是由xml开源社区提供的sax接口。这两个接口如今都在javaSE中。
XML
是什么:
是一种标记语言(Markup Language),就像html一样。只不过没有预先定义的<tag>便签,也就是可以随便定义<tag>便签,且浏览器也不会去解析。
为什么要用:
用于存储信息(少量数据或软件配置信息),并且这种存储是独立于软件和硬件的。现已被广泛应用于互联网和各种程序之中。就是一个规范、标准,大家遵守这个规范去存储信息,可以增加软件通用性,增加便利,所以我们也要使用。这就如同统一度量衡一个意思,顺应全球化发展。而这也是和html不同的地方:html被用来显示数据,它专注于怎么显示,而xml专注于存储什么数据。
怎么用:
1,他没有预定义标签,所以可以自定义标签,想定义什么便签就定义什么,一对标签之中放的是数据。其次,他是一个严格的树形结构:一个根节点,多个子节点。每个子节点又可作为根节点。如下所示:
<root>
<child>
<subchild>data</subchild>
</child>
<child>
<subchild>data</subchild>
</child>
</root>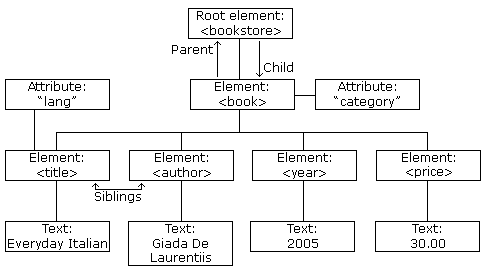
2、没有预定义便签一方面是好事,另一方面增加了不确定性。所以就出现了DTD,Schema标准(所以说最NB的还是设计标准的!),用来描述xml文档的结构,给标签设定了一个规范,如同预定义标签一样。例如:有哪些节点、父节点下子节点的顺序、节点中的数据类型等。(详细的语法参见w3schools)
JAVA解析XML
编程接口
作为程序员,最关注的就是如何编程操作xml。对此,w3c提供了DOM编程接口(只有接口,没有实现类;这也算面向接口编程。),另一个是由xml开源社区提供的sax接口。这两个接口如今都在javaSE中。
- org.w3c.dom
- org.w3c.dom.bootstrap
- org.w3c.dom.events
- org.w3c.dom.ls
- Interfaces
- DOMImplementationLS
- LSInput
- LSLoadEvent
- LSOutput
- LSParser
- LSParserFilter
- LSProgressEvent
- LSResourceResolver
- LSSerializer
- LSSerializerFilter
- Exceptions
- LSException
- org.xml.sax
- org.xml.sax.ext
- org.xml.sax.helpers
这两个接口解析方式大不相同:
DOM:解析xml文件,并构建了一个完整的节点树在内存中。相当于用树的数据结构保存了xml,对内存消耗比较大,但方便增删改查。
SAX:一行一行的扫描xml文件,并不记录。每扫到一个特定的标签,例如:标签开始符号,字符,标签结束符号。就会调用特定的事件处理程序(这应该是应用了观察者设计模式:扫描器是subject,处理程序是observer。)所以这样处理,速度快,内存消耗小。但他是一次且顺序的扫描,这样就不适合做随机的增删改查。
开发包(框架)
JAXP:Java API for XML Processing,在javax.xml包及此子包中实现了这些接口。
DOM:通过工厂方法获取文档树,再操作其中元素。
Document parse = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse("catalog.xml");
//获取tag
NodeList tag= parse.getElementsByTagName("OPTIONS");
Node item = tag.item(1);
System.out.println(item.getTextContent());SAX:通过工厂方法获取文档解析器,实现事件处理接口,在解析即可。
// 通过工厂获得解析器
SAXParser saxParser = SAXParserFactory.newInstance().newSAXParser();
// 得到读取器
XMLReader reader = saxParser.getXMLReader();
// 设置内容处理器
BeanListHander handler = new BeanListHander();
reader.setContentHandler(handler);
// 读取
reader.parse("exam.xml");DOM4J:开源框架,集成了DOM和SAX,且支持XPath(一种语言,可以像正则表达式一样快速搜索XML中的节点,详细:Zvon tutorial),功能强大,性能优异。
dom4j is an easy to use, open source library for working with XML, XPath and XSLT on the Java platform using the Java Collections Framework and with full support for DOM, SAX and JAXP.
dom4j is an Open Source XML framework for Java. dom4j allows you to read, write, navigate, create and modify XML documents. dom4j integrates with DOM and SAX and is seamlessly integrated with full XPath support.
Quick Start Guide!


















