
文章目录
- 序列化就是将python中的字典转换为一种特殊的字符串(json)
- 那么反序列化就是,将json字符串转换为python字典
- 想输出真正的中文需要指定ensure_ascii=False,,还可以使用排序sort_keys,缩进:indent
- 1.json.dumps()用于将dict类型的数据转成str
- 2. 、json.dump()用于将dict类型的数据转成str,并写入到json文件中。
- 3. json.loads()用于将str类型的数据转成dict。
- 4. json.load()用于从json文件中读取数据。
- pickle库
- 可以使用 demjson库,此库的强大,
- jmespath ,此工具内置,可直接使用
序列化就是将python中的字典转换为一种特殊的字符串(json)
那么反序列化就是,将json字符串转换为python字典
想输出真正的中文需要指定ensure_ascii=False,还可以使用排序sort_keys,缩进:indent
print(json.dumps({'a':'str', 'c': True, 'e': 10, 'b': 11.1, 'd': None, 'f': [1, 2, 3], 'g':(4, 5, 6)}, sort_keys=True, indent=4))json.dumps('中国',ensure_ascii=False)
>>> import json
>>> sstr = json.dumps("你好")
>>> print(sstr)
"\u4f60\u597d"
>>> ustr = json.dumps("你好", ensure_ascii=False)
>>> print(ustr)
"你好"1.json.dumps()用于将dict类型的数据转成str
import json
name_emb = {'a':'1111','b':'2222','c':'3333','d':'4444'}
jsObj = json.dumps(name_emb)
print(name_emb)
print(jsObj)
print(type(name_emb))
print(type(jsObj))
------------------------------------------------------------------------
{'a': '1111', 'c': '3333', 'b': '2222', 'd': '4444'}
{"a": "1111", "c": "3333", "b": "2222", "d": "4444"}
<type 'dict'>
<type 'str'>2. 、json.dump()用于将dict类型的数据转成str,并写入到json文件中。
import json
name_emb = {'a':'1111','b':'2222','c':'3333','d':'4444'}
emb_filename = ('/home/cqh/faceData/emb_json.json')
# solution 1
jsObj = json.dumps(name_emb)
with open(emb_filename, "w") as f:
f.write(jsObj)
f.close()
# solution 2
json.dump(name_emb, open(emb_filename, "w"))3. json.loads()用于将str类型的数据转成dict。
import json
name_emb = {'a':'1111','b':'2222','c':'3333','d':'4444'}
jsDumps = json.dumps(name_emb)
jsLoads = json.loads(jsDumps)
print(name_emb)
print(jsDumps)
print(jsLoads) #'a'变成了u'a'是因为发生了类型转换,str会转换成unicode
print(type(name_emb))
print(type(jsDumps))
print(type(jsLoads))
-----------------------------
{'a': '1111', 'c': '3333', 'b': '2222', 'd': '4444'}
{"a": "1111", "c": "3333", "b": "2222", "d": "4444"}
{u'a': u'1111', u'c': u'3333', u'b': u'2222', u'd': u'4444'}
<type 'dict'>
<type 'str'>
<type 'dict'>4. json.load()用于从json文件中读取数据。
import json
emb_filename = ('/home/cqh/faceData/emb_json.json')
jsObj = json.load(open(emb_filename))
print(jsObj)
print(type(jsObj))
for key in jsObj.keys():
print('key: %s value: %s' % (key,jsObj.get(key)))直接上代码
import json
# 序列化反序列化
# 将字典对象转换为json
# 序列化 将 Python对象转换成 json字符串
dic = {
'is_login': True,
'username': '枫枫',
}
print(json.dumps(dic)) # {"is_login": true, "username": "\u67ab\u67ab"}
# 反序列化 将 json 字符串转换成 python 对象
json_str = '{"is_login": true, "username": "\u67ab\u67ab"}'
print(json.loads(json_str)) # {'is_login': True, 'username': '枫枫'}
# 序列化
a = "枫枫"
print(json.dumps(a,ensure_ascii=False)) # "\u67ab\u67ab"
# 反序列化
s = '"\u67ab\u67ab"'
print(json.loads(s)) # 枫枫pickle库
dumps对象序列化为bytes对象
dump对象序列化到文件对象,就是存入到文件。
loads从bytes对象反序列化。
load对象反序列化,从文件读取数据.
pickle的接口跟json是一样的,序列化用dumps(x), dump(x, f),反序列化使用loads(s), load(f)。但是,pickle可以序列化任意复杂的对象,比如自定义的类、函数都是可以用它来序列化的。比如下面这个例子就是序列化b并反序列化一个函数:
obj = 123, "abcdedf", ["ac", 123], {"key": "value", "key1": "value1"}
obj1 = pickle.dumps(obj)
print type(obj1)# 输出:<type 'str'>
obj2 = pickle.loads(obj1)
print type(obj2)# 输出:<type 'tuple'>可以使用 demjson库,此库的强大,
安装方法:
pip install demjson两个最常用的直接用法
demjson.decode(string,encoding='utf-8') #把json字符串变json对象
demjson.encode(obj, encoding='utf-8') #把对象转换成json字符串json的字典也必须是加上双引号,要不然用json.loads报错,但是用这个 米有任何问题
# 这里 status是没有加""号的,用普通的转换会报错,这时用这个库就完美
string = '''{string = '''{status: "error",
"messages": ["Could not find resource or operation 'BZK1.MapServer' on the system."],
"code": 404}'''
# print(type(string))
# print(json.loads(string))# 将字符串转换成dict
resp_body = demjson.decode(string)
print(resp_body): "error",
"messages": ["Could not find resource or operation 'BZK1.MapServer' on the system."],
"code": 404}'''
# print(type(string))
# print(json.loads(string))# 将字符串转换成dict
resp_body = demjson.decode(string)
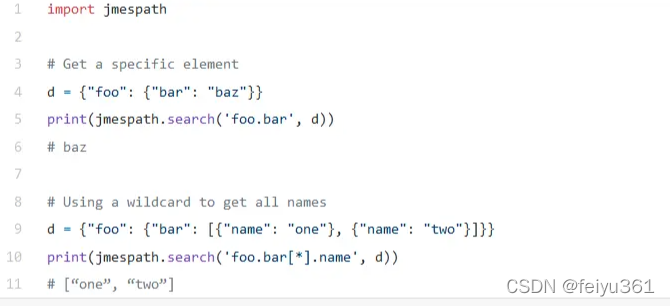
print(resp_body)jmespath ,此工具内置,可直接使用
import jmespath
dic_1 = {"a": "foo", "b": "bar", "c": "baz"}
path = jmespath.search("a", dic_1)
print(path)
```
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















