
在以前的文章中,我们讨论过Transformer并不适合时间序列预测任务。为了解决这个问题Google创建了Hybrid Transformer-LSTM模型,该模型可以实现SOTA导致时间序列预测任务。
但是我实际测试效果并不好,直到2022年3月Google研究团队和瑞士AI实验室IDSIA提出了一种新的架构,称为Block Recurrent Transformer [2]。
从名字中就能看到,这是一个新型的Transformer模型,它利用了lstm的递归机制,在长期序列的建模任务中实现了显著改进。
在介绍它之前,让我们简要讨论与LSTMS相比,Transformer的优势和缺点。这将帮助你了解这个新架构的工作原理。
Transformer vs LSTM
Transformer 最显著的优点总结如下
并行性
LSTM实现了顺序处理:输入(比如说句子)逐字处理。
Transformer 使用非顺序处理:句子是作为一个整体处理的,而不是一个字一个字地处理。
图1和图2更好地说明了这种比较。
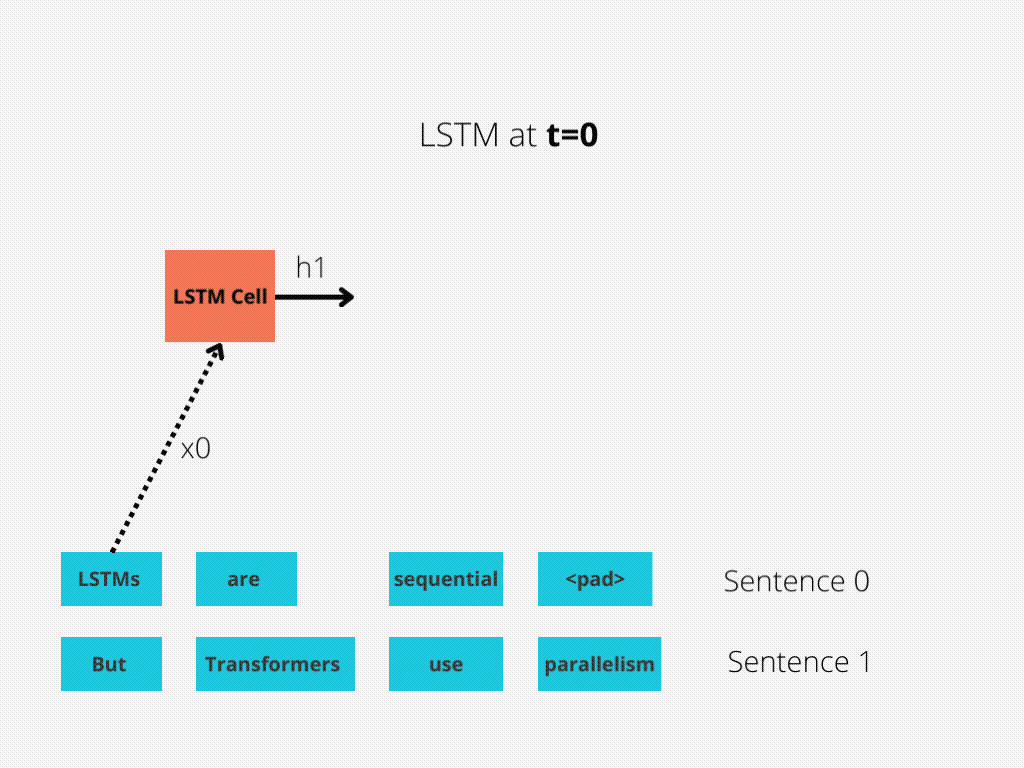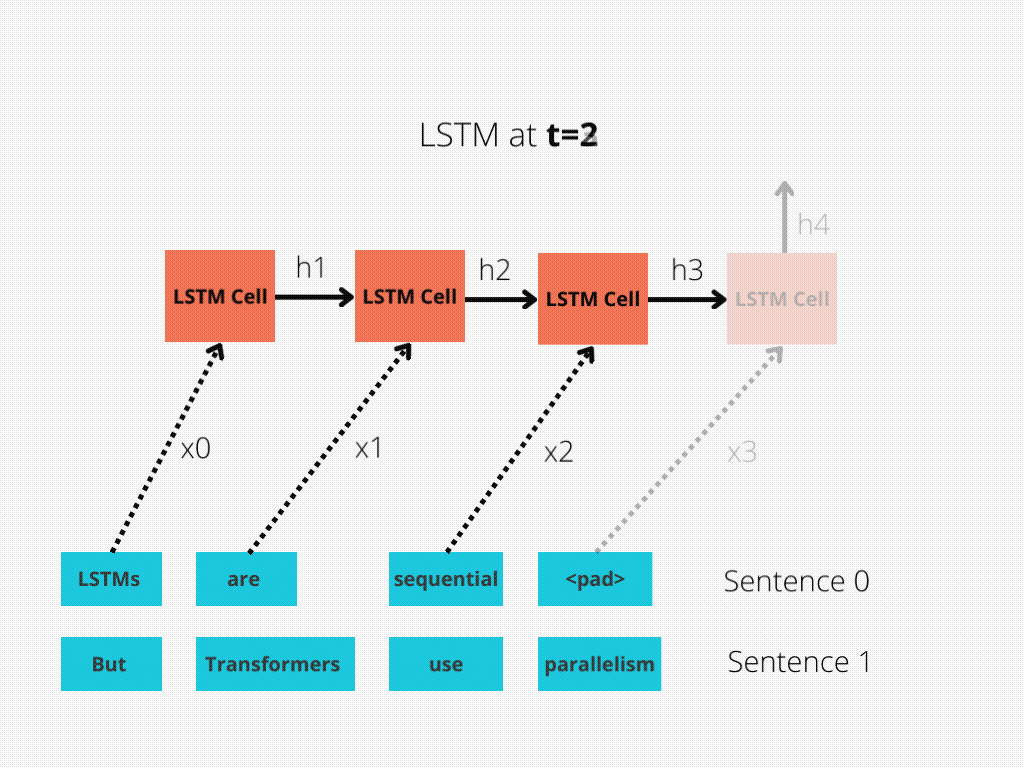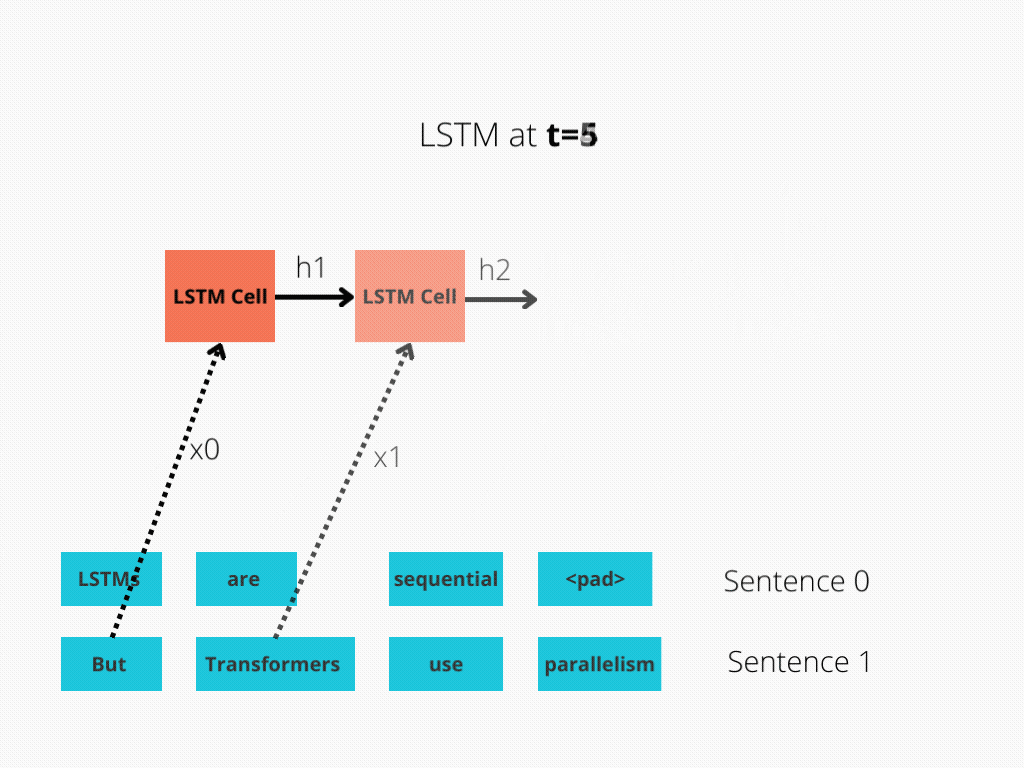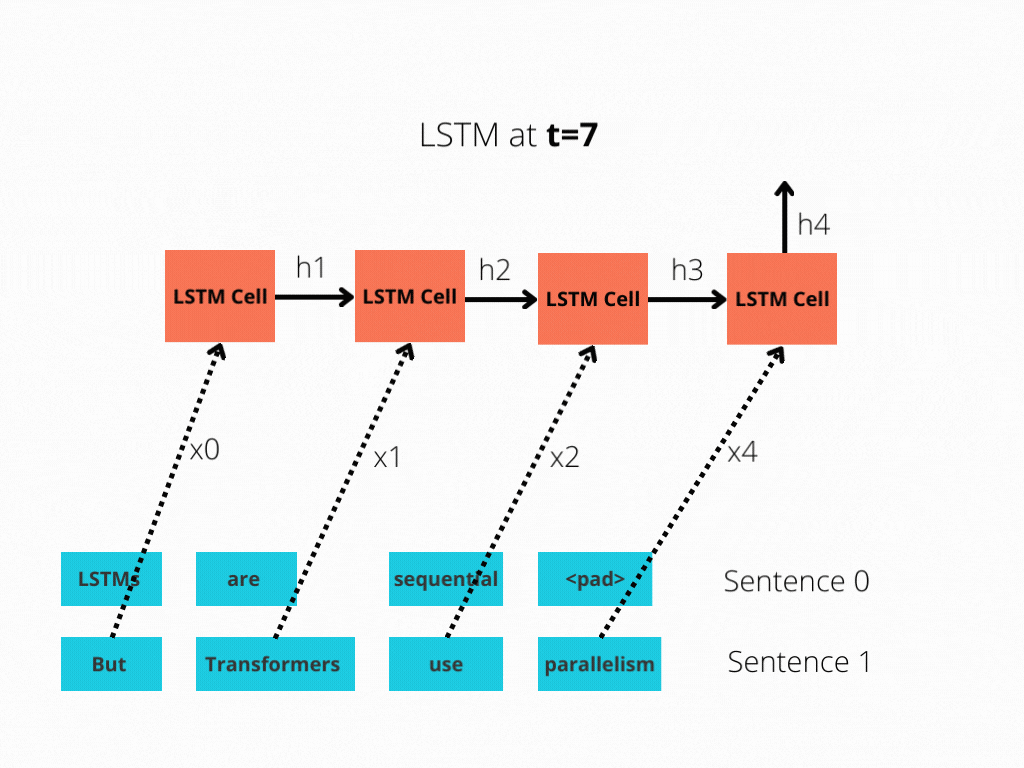
图1:序列长度为4的LSTM单元。
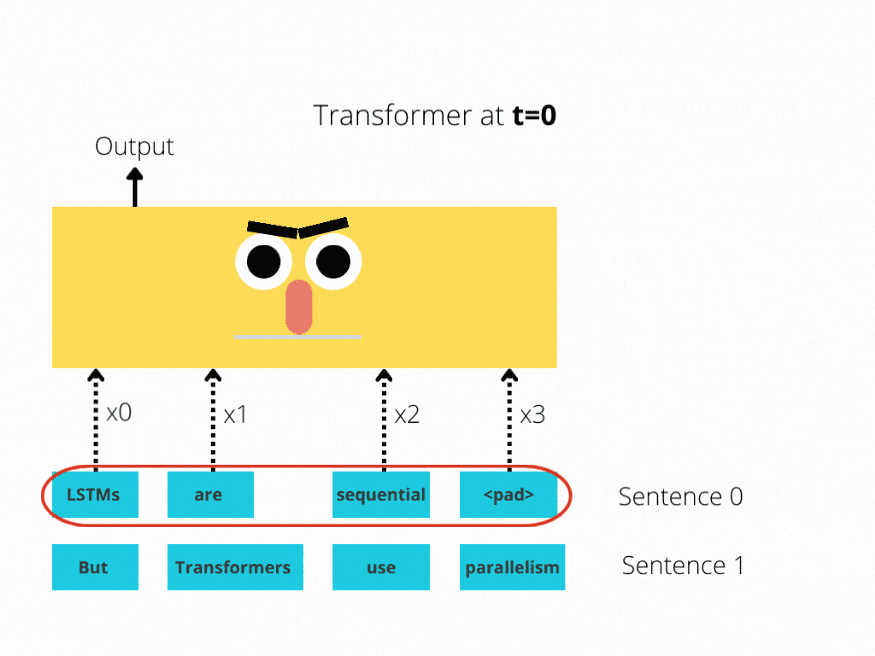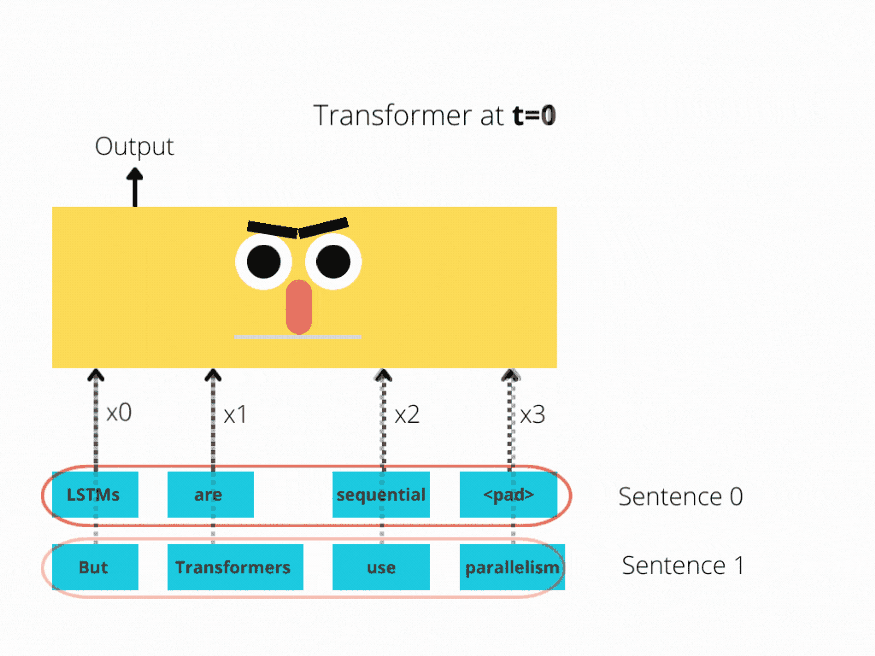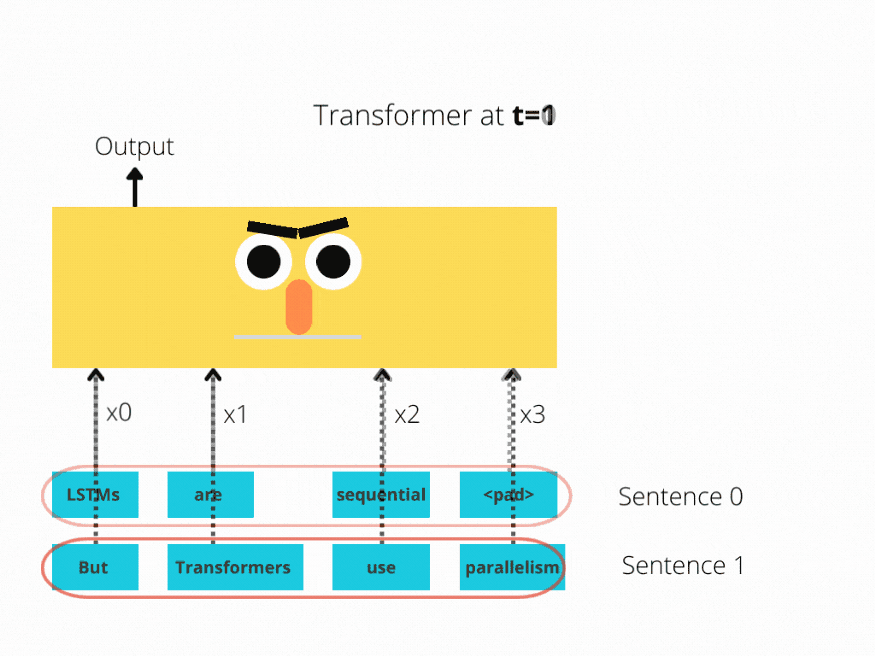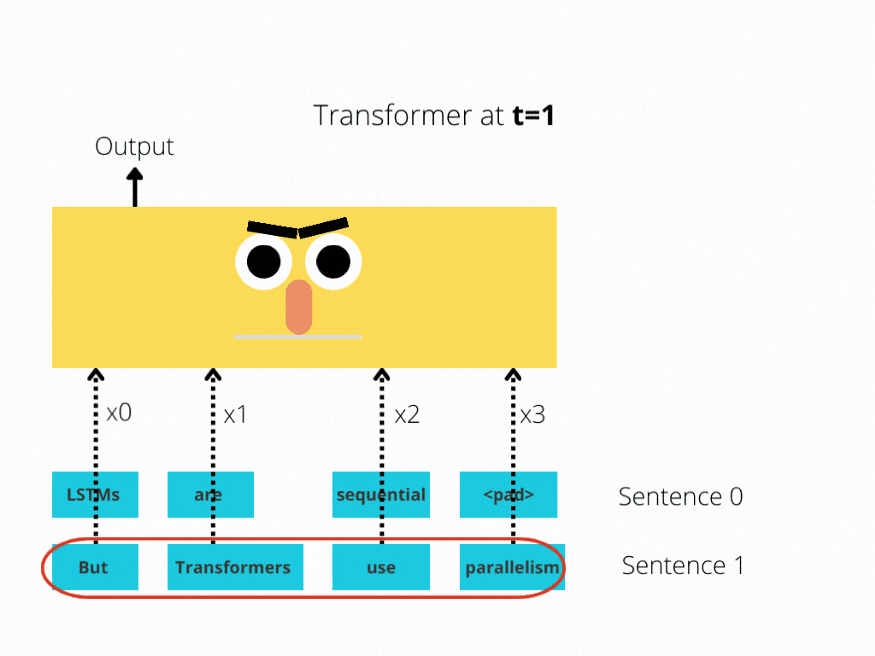
图2:Bert体系结构(简化)
LSTM需要8个时间步来处理句子,而BERT[3]只需要2个时间步!所以BERT能够更好地利用现代GPU加速所提供的并行性。
上面两个插图都经过了简化:假设批大小为1。另外也没有考虑BERT的特殊令牌,比如它需要2个句子等等。
长期记忆
在移动到未来的令牌之前,LSTM被迫将它们学习到的输入序列表示状态向量。虽然LSTMs解决了梯度消失的问题,但他仍然容易发生梯度爆炸。
Transformer有更高的带宽,例如在Encoder-Decoder Transformer[4]模型中,Decoder可以直接处理输入序列中的每个令牌,包括已经解码的令牌。如图3所示:

图3:Transformer中的编码和解码
更好的注意力机制
transformer使用了一种名为Self-Attention的特殊注意力机制:这种机制允许输入中的每个单词引用输入中的每个其他单词。所以可以使用大的注意窗口(例如512,1048)。因此,它们非常有效地捕获了长范围内顺序数据中的上下文信息。
让我们看看Transformer的缺点:
自注意力的计算成本o(n²)
这其实Transformer最大的问题。初始BERT模型的极限为512 令牌。解决此问题的粗爆的方法是直接截断输入句子。为了解决这个问题可以使用surpass的方法,将令牌扩充到到4096。但是关于句子的长度,自注意力的命中成本也是二次的
所以可伸缩性变得非常具有挑战性。这也是为什么后面有许多想法来重组原始的自注意力机制:

图4:不同类型自注意力的成本矩阵
Longformer[6]和Transformer XL[7]等模型针对长格式文本进行了优化,并取得了显著的改进。
但是挑战仍然存在:我们能否在不牺牲效率的前提下进一步降低计算成本?



















