
R-CNN出来以后,首次将卷积神经网络带入目标检测领域。随着SPP-Net等的出现对它的改进,受SPP-Net的启发,Fast R-CNN出现了。

Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
一.Fast R-CNN所解决R-CNN的两个问题
1、测试和训练速度慢
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
Fast R-CNN将整个图像归一化后直接送入CNN网络,卷积层不进行候选区的特征提取,而是在最后一个池化层加入候选区域坐标信息,进行特征提取的计算。
2、训练所需空间大
R-CNN中目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本。
Fast R-CNN将目标分类与候选框回归统一到CNN网络中来,不需要额外存储特征。
二、Fast R-cnn框架介绍

相比R-CNN最大的区别,在于RoI池化层和全连接层中目标分类与检测框回归微调的统一。
1、RoI池化层(RoI pooling layer)
RoI池化层可以说是SPP(spatial pyramid pooling)的简化版。RoI指的是在一张图片上完成Selective Search后得到的“候选框”在特征图上的一个映射,RoI层的作用主要有两点:
①考虑到感兴趣区域(RoI)尺寸不一,但是输入图中后面FC层的大小是一个统一的固定值,因为ROI池化层的作用类似于SPP-net中的SPP层,即将不同尺寸的RoI feature map池化成一个固定大小的feature map。具体操作:假设经过RoI池化后的固定大小为
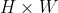
是一个超参数,因为输入的RoI feature map大小不一样,假设为

,需要对这个feature map进行池化来减小尺寸,那么可以计算出池化窗口的尺寸为:

,即用这个计算出的窗口对RoI feature map做max pooling,Pooling对每一个feature map通道都是独立的。
②其次RoI有四个参数
")
除了尺寸参数

、

外,还有两个位置参数

、

表示RoI的左上角在整个图片中的坐标。
2、特征提取方式
Fast R-CNN在特征提取上可以说很大程度借鉴了SPP-Net,首先将图片用选择搜索算法(selective search)得到2000个候选区域(region proposals)的坐标信息。另一方面,直接将图片归一化到CNN需要的格式,整张图片送入CNN(本文选择的网络是VGG),将第五层的普通池化层替换为RoI池化层,图片然后经过5层卷积操作后,得到一张特征图(feature maps),开始得到的坐标信息通过一定的映射关系转换为对应特征图的坐标,截取对应的候选区域,经过RoI层后提取到固定长度的特征向量,送入全连接层。
3、联合候选框回归与目标分类的全连接层

之前RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,Fast R-CNN巧妙地将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型。实际实验也证明,这两个任务能够共享卷积特征,并相互促进。Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal+CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster-RCNN做下了铺垫。
cls_ score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。 bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
网络的代价函数细节如下图所示:

三、训练 / 测试过程
1、训练
首先用ILSVRC 20XX数据集进行预训练,预训练是进行有监督的分类的训练。然后在PASCAL VOC样本上进行特定调优(fine tunning),调优的数据集中25%的正样本(如果和真实框中的IOU值超过了阈值0.5即 IOU>=0.5)、75%的负样本(与真实框IoU在0.1-0.5的候选框)。PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;正样本仅表示前景,负样本仅表示背景;回归操作仅针对正样本进行。
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征,文章中N=2,R=128。微调前,需要对有监督预训练后的模型进行3步转化:
①RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
②两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层;
③上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;
2、测试
用selective search方法提取图片的2000个proposal,并保存到文件;
将图片输入到已经训好的多层全卷积网络,对每一个proposal,获得对应的RoI Conv featrue map;
对每一个RoI Conv featrue map,按照3.1中的方法进行池化,得到固定大小的feture map,并将其输入到后续的FC层,最后一层输出类别相关信息和4个boundinf box的修正偏移量;
对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score。

注:文中给出了大中小三种网络,此处示出最大的一种。三种网络基本结构相似,仅conv+relu层数有差别,或者增删了norm层。


















