
1. 引言
ClusterONE是由TamásNepusz,Haiyuan Yu和Alberto Paccanaro开发的一个由内聚力(cohesiveness)引导搜索的聚类算法。ClusterONE算法可以主要解决的是蛋白质复合物的类别识别问题,也就是PPI网络中密集子结构的识别问题。ClusterONE算法中,内聚力得分越高则代表了该组蛋白质越有可能是一种蛋白质复合物,但是ClusterONE算法仅仅依赖于内聚力公式,算法过程中可能会出现偏差。可能会出现使内聚力下降的节点,但是实际上该节点的确属于候选蛋白质复合物。所以在内聚力失去效用时,我们可以使用另一套评判机制来判断节点到底属于哪个聚类,我们将这套评判机制称为近邻选择策略。
参考文献:T.Nepusz, H. Yu, and A. Paccanaro, “Detecting overlapping protein complexes inprotein-protein interaction networks,” Nat. Methods, vol. 9, no. 5, pp.471–472, Mar. 2012.
2. ClusterONE算法详解

灰色阴影区域表示已知聚类,与已知聚类内部有联系的节点被称为邻居节点,在聚类内部被联系的节点被称为聚类内部的顶点节点。图中的C,F,G为聚类的邻居节点,A,B,D,E为聚类的顶点节点。深黑色边是internal edges,灰色边是boundary edges,虚线边是external edges。
内聚力被定义为如下:
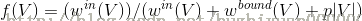
其中,

是指候选蛋白质复合物中所有节点相互作用的边的权重总和,

是指外部节点与候选蛋白质复合物中节点相互作用的边的权重总和,

则是惩罚项,其作用是用来平衡数据本身误差带来的影响。
ClusterONE算法的主要过程是聚类生长过程,该生长过程被称为贪婪凝聚群检测过程(the greedy cohesive group detection process)。贪婪凝聚群检测过程包含两个步骤:
- 增加邻居节点。计算初始聚类的内聚力,将聚类的n个邻居节点分别放入聚类中,按照内聚力公式分别计算出它们的内聚力, ... ,选择其中能够使内聚力增加最大化的邻居节点加入聚类。
- 去除顶点节点。同增加邻居节点的过程类似,也是找到能够使内聚力增加最大化的顶点节点从聚类中去除。在去除顶点节点的步骤中会忽略最开始的种子节点。
我们利用上图来详细说明上述过程。假设惩罚项

,每条边的权重为1。首先,被标记阴影部分的内聚力为10/15,将C加入聚类后得到的内聚力为13/15,将F加入聚类后得到的内聚力为11/17,将G加入聚类后得到的内聚力为11/18。能够使内聚力增加的操作只有加入节点C。之后,再分别将顶点节点A,B,D,E从聚类中去除,得到四个内聚力值7/14,7/14,7/14,6/13,去除顶点节点后的内聚力都没有原来的大,所以不用去除顶点节点。贪婪凝聚选择的最优方案就是增加节点C。
3. ClusterONE算法优化
对于邻居节点,我们使用以下公式判断其是否为近邻,公式如下:

对于某个聚类的邻居节点N,

表示boundary edges权重之和,

表示external edges权重之和。若G(N)>0,邻居节点N为这个聚类的近邻节点,若G(N)>0,邻居节点N不是近邻节点。
部分优化后的代码如下:
public ClusterGrowthAction getSuggestedAction() {
IntArray bestNodes = new IntArray();
final double quality = qualityFunction.calculate(nodeSet);
double bestAffinity;
boolean bestIsAddition = true;
int n = nodeSet.size();
if (n == 0)
return ClusterGrowthAction.terminate();
double den = (n + 1) * n / 2.0;
double internalWeightLimit = this.minDensity * den - nodeSet.getTotalInternalEdgeWeight();
/* internalWeightLimit is a strict limit: if a node's connections to the current cluster
* are weaker than this weight limit, the node couldn't be added as it would decrease the
* density of the cluster under the prescribed limit
*/
if (debugMode) {
System.err.println("Current nodeset: " + nodeSet);
System.err.println("Current quality: " + quality);
}
/* Try the addition of some nodes */
bestAffinity = quality;
for (int node: nodeSet.getExternalBoundaryNodes()) {
double internalWeight = nodeSet.getTotalAdjacentInternalWeight(node);
if (n >= 4 && internalWeight < internalWeightLimit)
continue;
double sub = qualityFunction.getSubWeight(nodeSet,node);
double affinity = qualityFunction.getAdditionAffinity(nodeSet, node);
if (debugMode) {
System.err.println("Considering addition of " + node + ", affinity = " + affinity);
}
if (affinity > bestAffinity) {
bestAffinity = affinity;
bestNodes.clear();
bestNodes.add(node);
} else if(affinity < bestAffinity){
if(sub>0){
bestNodes.add(node);
}
}
else if (affinity == bestAffinity) {
bestNodes.add(node);
}
}
if (this.isContractionAllowed() && this.nodeSet.size() > 1) {
/* Try removing nodes. Can we do better than adding nodes? */
// Set<Integer> cutVertices = null;
for (Integer node: nodeSet) {
// Don't process nodes that were in the initial seed
if (keepInitialSeeds && initialSeeds.contains(node))
continue;
double sub = qualityFunction.getSubWeight(nodeSet,node);
double affinity = qualityFunction.getRemovalAffinity(nodeSet, node);
if (debugMode) {
System.err.println("Considering removal of " + node + ", affinity = " + affinity);
}
// The following condition is necessary to avoid cases when a
// node is repeatedly added and removed from the same set.
// The addition of 1e-12 counteracts rounding errors.
if (affinity < quality + 1e-12)
continue;
if (affinity < bestAffinity)
continue;
// The following condition is necessary to avoid cases when a
// tree-like cluster becomes disconnected due to the removal
// of a non-leaf node
if (nodeSet.isCutVertex(node))
continue;
// Note to self: the above code uses BFS to decide whether the given node is a cut
// vertex or not. Theoretically, it would be better to use a DFS because a single
// DFS could provide us all the cut vertices at once. However, in practice it
// seems to be slower. If you want to try, uncomment the fragment below:
/*
if (cutVertices == null) {
cutVertices = findCutVerticesForNodeSet(nodeSet);
}
if (cutVertices.contains(node))
continue;
*/
if ((affinity > bestAffinity)&&(sub<0)) {
bestAffinity = affinity;
bestNodes.clear();
bestNodes.add(node);
bestIsAddition = false;
} else {
/* affinity == bestAffinity */
if (bestIsAddition) {
bestNodes.clear();
bestIsAddition = false;
}
bestNodes.add(node);
}
}
}
if (bestNodes.size() == 0 || bestAffinity == quality) {
if (debugMode)
System.err.println("Proposing termination");
return ClusterGrowthAction.terminate();
}
if (bestNodes.size() > 1 && onlySingleNode)
bestNodes.setSize(1);
if (bestIsAddition) {
if (debugMode)
System.err.println("Proposing addition of " + Arrays.toString(bestNodes.toArray()));
return ClusterGrowthAction.addition(bestNodes.toArray());
} else {
if (debugMode)
System.err.println("Proposing removal of " + Arrays.toString(bestNodes.toArray()));
return ClusterGrowthAction.removal(bestNodes.toArray());
}
}
4. 结语
这篇文章其实是前几年一个工作的一小部分,ClusterONE的完整代码可以电邮文章作者询问。




















