
偶不是计算机专业出身,不过参加过软考,对计算机原理大概也似乎多少有差不多那么个一星半点的了解。唯独看程序编译原理时,如读天书。状态机文法真奇妙,看了睡觉不用安眠药。大学出的书太垃圾了,打击了偶的自信,创伤了偶的幼小心灵。直到多年以后,看到老赵一篇《趣味编程:从字符串中提取信息》,心中的阴影才开始解开。
老赵提出的问题,逻辑算很简单的,用正则表达式,直接用关键字符拆分都行。但是如果字符串处理逻辑复杂一点,比如说,你要写个程序编译器,这时用正则或拆分方式,恐怕要哭了。只有请老赵文中提到的正解—状态机能大展身手了。
在本文,准备解析一个CSS文件。至于编译器,将来也不是不可能啊(菜鸟的白日梦

)。什么是状态机,我就不解释了,免得给大家催眠,何况偶也不懂。那凭什么说你用了状态机?您说是就是,说不是就不是了。先看状态图吧:
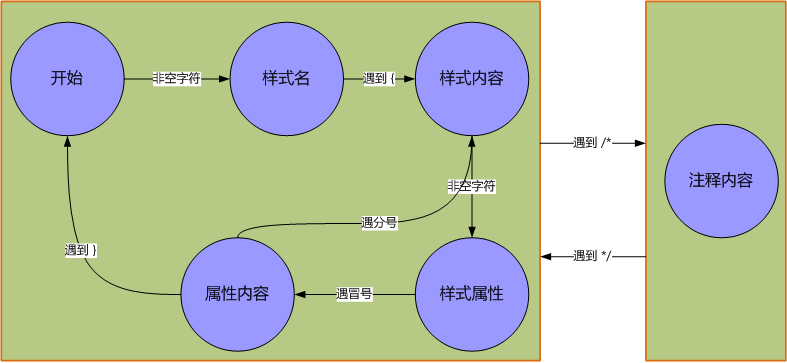
状态机的重要好处,就是清晰,逻辑画在图上一眼就看得清清楚楚。所以我定义了五个老赵说了那种状态机(本来六个,偷鸡一把),就是一种返回自身类型的委托。命名时很纠结,又是个ST打头的类型,我差点就直接用汉字命名了。
public delegate StateReader StateReader(char c);
StateReader rsComment = c=>{ ... }; //Read comment
StateReader rsStyleName = c=>{ ... }; //Read Style's name
StateReader rsStyleText = c=>{ ... }; //Read Style's text
StateReader rsPropertyName = c=>{ ... }; //Read a property's name
StateReader rsPropertyText = c=>{ ... }; //Read a property's text
解析CSS文件,往往只解析部分属性,不需要将其中所有样式都读出来。所以负责样式名的状态机,还要负责筛选,这样其实应该还有一两种状态,作为PropertyName状态的子状态。状态机中的状态,其实是可以分层的,某种状态下有多个子状态,子状态下又可以有子状态。比如上图中的两部分—注释和非注释,就是两大基本状态。状态分层是在写这篇博文时才想到的,在偶的代码中,用了许多状态标志实现分层,就有点啰嗦了,倒是挺锻炼逻辑思维的。
状态机解析文本另一个优势,是性能。用正则或直接拆分,将产生大量的内存对象。没有IO操作情况下,频繁大量的内存分配和回收是程序的性能杀手。用状态机解析,除了解析结果外,只需要存储一些状态,性能要高一个数量级以上,而且绿色环保,符合时代潮流。解析的逻辑越复杂,状态机的优势越明显。到了像程序编译这种程度,状态机是不二的选择。
虽然性能又高,逻辑又清晰,可还是不足以打动你吧,或许你在想编译器关我鸟事?但是另一个领域你或许有兴趣,就是搜索。搜索要用到中文分词,好像除了状态机,还真没有更好处理方式。性能之外,状态机第三个特点就是精确。比如我解析CSS文件时,可以方便地在取得属性时,得到其在多少行,从本行的第几个字符开始。因为状态机是一个个字符解析的,粒度细到不能再细,要是用正则来做就不爽了。
我希望有一天能用上亲手写的编译器,就从偶到山寨状态机开始起步吧。




















