
声音信号的数字化
数字信号基础知识:https://wenku.baidu.com/view/be544303d5d8d15abe23482fb4daa58da0111c88.html
声音是一种模拟信号,想要用于计算机,就必须将模拟信号转化为数字信号,声音的信息表示过程是这样的:声音-->采样-->量化-->编码-->数字音频。这样,我们就能在计算机上储存声音了,等待用户需要播放的时候,再将数字信号转化为模拟信号。
声音的数字化需要经历三个阶段:采样,量化,编码
采样
所谓采样,就是在某些特定的时刻对模拟声音信号进行测量,得到离散时间信号。其原理是首先输入模拟信号,然后按照固定的时间间隔截取该信号的振幅值,每个波形周期内截取两次,以取得正、负相的振幅值,该振幅值采用若干位二进制数表示,从而将模拟声音信号变成数字音频信号。
采样是把时间上连续的模拟信号在时间轴上离散化的过程。这里有采样频率和采样周期的概念,采样周期即相邻两个采样点的时间间隔,采样频率是采样周期的倒数,理论上来说采样频率越高,声音的还原度就越高,声音就越真实。为了不失真,采样频率需要大于声音最高频率的两倍。
量化
所谓量化,就是声音信号在幅值方面的数字化。方法是把模拟信号的每次采样值进行“整数化”。
量化的主要工作就是将幅度上连续取值的每一个样本转换为离散值表示。其量化过后的样本是用二进制表示的,此时可以理解为已经完成了模拟信号到二进制的转换。量化中又个概念叫精度,指的是每个样本占的二进制位数,反过来,二进制的位数反映了度量声音波形幅度的精度。精度越大,声音的质量就越好。通常的精度有8bit,16bit,32bit等,当然质量越好,需要的储存空间就越大。
编码
编码是整个声音数字化的最后一步,其实声音模拟信号经过采样,量化之后已经变为了数字形式,但是为了方便计算机的储存和处理,我们需要对它进行编码,以减少数据量。
通过采样频率和精度可以计算声音的数据传输率:
- 数据传输率(bps)= 采样频率 * 精度 * 声道数
单声道一次可以产生一组声音波形数据,双声道一次可以产生两组波形数据。
有了数据传输率我们就可以计算声音信号的数据量:
- 数据量(byte)= 数据传输率 * 持续时间 / 8
例题:
CD唱片上所存储的立体声高保真音乐的采样频率为44.1kHZ,量化精度为16位,双声道,计算一小时的数据量:
根据公式:
44.1kHZ * 16bit * 2 * 3600s /8 =6350400B ≈ 605.6MB
数字信号处理中的声学基础知识
主要对一些声学的概念以及计算公式进行了总结。
① 频率
声源在一秒钟内振动的次数叫频率,记作f,单位为Hz。
② 波长
沿声波传播方向,振动一个周期所传播的距离,或在波形上相位相同的相邻两点间的距离称为波长,用λ表示,单位为m。
③ 声速
一秒时间内声波传播的距离叫声波速度,简称声速,记作c,单位为m/s。
④ 声功率(W)
声功率是指单位时间内,声波通过垂直于传播方向某指定面积的声能量。在噪声监测中,声功率是指声源总声功率,单位为W。
⑤ 声强(I)
声强是指单位时间内,声波通过垂直于声波传播方向单位面积的声能量,单位为W/m²。
⑥ 声压(p)
声压是由于声波的存在而引起的压力增值。声波是空气分子有指向、有节律的运动。声压单位为Pa。
⑦ 分贝
分贝是指两个相同的物理量(如A1和A0)之比取以10为底的对数并乘以10(或20)。
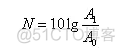
分贝符号为“dB”,它是无量纲的,是噪声测量中很重要的参量。上式中A0是基准量(或参考量),A1是被量度量。被量度量和基准量之比取对数,该对数值称为被量度量的“级”,亦即用对数标度时,所得到的是比值,它代表被量度量比基准量高出多少“级”。
⑧ 声功率级
声功率级常用LW表示,定义为:
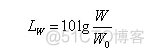
式中:LW——声功率级,dB;
W——声功率,W;
⑨ 声强级
声强级常用LI表示,定义为:
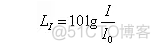
式中:LI——声强级,dB;
I——声强,W/m²;
I0——基准声强。
⑩ 声压级
声压级常用Lp表示,定义为:
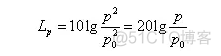
式中:Lp——声压级,dB;
p——声压,Pa;
p0——基准声压。
在空气中规定p0为2×10^-5Pa,该值是正常青年人耳朵刚能听到的1000Hz纯音的声压值。在水中取1×10^-6Pa。
⑪ 倍频程
将频谱分为若干个频段,每个频段为一个频程,以直方图表示。
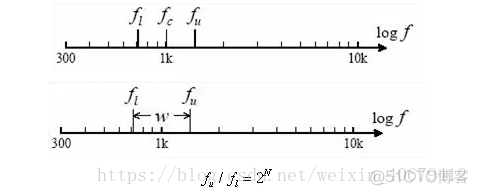
N=1:一倍频程,简称倍频程
N=1/3:三分之一倍频程
N=1/12: 十二分之一倍频程
中心频率:
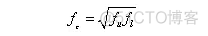
带宽:
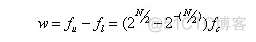
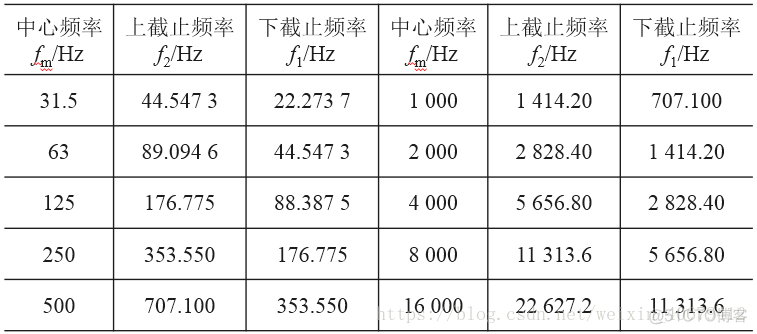
倍频程最常用的中心频率值(fm),以及上、下截止频率。
winsound模块提供对Windows平台的基本声音播放功能的访问


from winsound import Beep
def sound():
Beep(880, 250)
Beep(988, 250)
Beep(523 * 2, 600)
Beep(988, 300)
Beep(523 * 2, 600)
Beep(659 * 2, 600)
Beep(988, 1000)
Beep(659, 250)
Beep(659, 250)
Beep(880, 600)
Beep(784, 300)
Beep(880, 600)
Beep(523 * 2, 600)
Beep(784, 1000)
Beep(659, 600)
Beep(698, 800)
Beep(659, 300)
Beep(698, 600)
Beep(523 * 2, 600)
Beep(659, 980)
Beep(523 * 2, 250)
Beep(523 * 2, 250)
Beep(523 * 2, 250)
Beep(988, 600)
Beep(739, 300)
Beep(739, 600)
Beep(988, 600)
Beep(988, 1000)
Beep(880, 250)
Beep(988, 250)
Beep(523 * 2, 600)
Beep(988, 300)
Beep(523 * 2, 600)
Beep(659 * 2, 600)
Beep(988, 1000)
Beep(659, 250)
Beep(659, 250)
Beep(880, 600)
Beep(784, 300)
Beep(880, 600)
Beep(523 * 2, 600)
Beep(784, 1000)
Beep(659, 600)
Beep(698, 800)
Beep(659, 300)
Beep(698, 600)
Beep(523 * 2, 600)
Beep(659, 980)
Beep(523 * 2, 250)
Beep(523 * 2, 250)
Beep(523 * 2, 250)
Beep(988, 600)
Beep(739, 300)
Beep(739, 600)
Beep(988, 600)
Beep(988, 1000)
# 天空之城
sound()View Code
Python中的音频和数字信号处理(DSP)
创建一个正弦波
在这个项目中,我们将创建一个正弦波,并将其保存为wav文件。
但在此之前,你应该知道一些理论。
频率:频率是正弦波重复一秒的次数。我将使用1KHz的频率。
采样率:大多数现实世界的信号是模拟的,而计算机是数字的。因此,我们需要一个模数转换器将模拟信号转换为数字信号。有关转换器如何工作的详细信息超出了本书的范围。关键是采样率,即转换器每秒采样模拟信号的次数。
现在,采样率对我们来说并不重要,因为我们正在以数字方式完成所有工作,但我们的正弦波公式需要它。我将使用48000的采样率值,这是专业音频设备中使用的值。
正弦波公式:公式如下。
y(t)= A * sin(2 * pi * f *t)y(t) 是对于某个 x 轴 时间 t , y 轴的值
A 是幅值
pi 是我们的老朋友 3.14159.
f 是频率.
t 是样本. 由于我们需要将其转换为数字,我们将按采样率进行划分。
关于幅值:
上述的幅值A。在大多数书中,他们只选择A的随机值,通常为1.但我们这里不能这么取。我们生成的正弦波将处于浮点状态,虽然这对于绘制图形来说已经足够了,但是当我们写入文件时这将无法工作。原因是我们需要处理整数。如果查看wave文件,它们将被写为16位短整数。如果我们写一个浮点数,它将无法正确被表示。
为了解决这个问题,我们必须将浮点数转换为固定值。其中一种方法是将其乘以固定常数。我们如何计算这个常数?带符号的16位数的最大值是32767(2 ^ 15-1)。 (因为最左边的位是为符号保留的,留下15位。我们将2增加到15的幂,然后减去1,因为计算机从0开始计数)。
所以我们想要全音阶音频,我们将它与32767相乘。但我想要的音频信号是满量程的一半,所以我将使用16000的幅度。
代码如下:
import numpy as np
import wave
import struct
import matplotlib.pyplot as plt
# frequency is the number of times a wave repeats a second
frequency = 1000
num_samples = 48000
# The sampling rate of the analog to digital convert
sampling_rate = 48000.0
amplitude = 16000
file = "test.wav"设置我们刚才声明过的波形变量:
sine_wave = [np.sin(2 * np.pi * frequency * x/sampling_rate) for x in range(num_samples)]它表示生成0到num_samples范围内的 x,并且对于每个x值,生成一个值为该值的值。你可以将此值视为y轴值。然后将所有这些值放入列表中。十分简单。
nframes=num_samples
comptype="NONE"
compname="not compressed"
nchannels=1
sampwidth=2好的,现在是时候将正弦波写入文件了。我们将使用Python的内置wave库。在这里我们设置参数。 nframes是帧数或样本数。
comptype和compname都表示同样的事情:数据未压缩。 nchannels是通道数,即1. sampwidth是以字节为单位的样本宽度。正如我前面提到的,波形文件通常是每个样本16位或2个字节。
wav_file=wave.open(file, 'w')
wav_file.setparams((nchannels, sampwidth, int(sampling_rate), nframes, comptype, compname))打开波形文件并且设置参数:
for s in sine_wave:
wav_file.writeframes(struct.pack('h', int(s*amplitude)))这里可能需要解释一下。我们正在按样本写sine_wave文件。writeframes是写正弦波的函数。一切都很简单。可能让你感到困惑的是下面这一行:
struct.pack('h', int(s*amplitude))分解上述句子:
int(s*amplitude)
s
现在,我们拥有的数据只是一个数字列表。如果我们将其写入文件,音频播放器将无法读取。
Struct是一个Python库,它接收我们的数据并将其打包为二进制数据。代码中的h表示16位数。
要了解这个包的作用,让我们看看IPython中的一个例子。
In [1]: import numpy as np
2]: np.sin(0.5)
Out[2]: 0.47942553860420301
5]: 0.479*16000 Out[5]: 7664.0
上面是以0.5为例。
因此我们取0.5的sin,并将其乘以16000将其转换为固定点数。现在如果我们将其写入文件,它只会将7664写为字符串,这是错误的。让我们看一下struct做了什么:
In [6]: struct.pack('h', 7664) Out[6]: 'xf0x1d'
x 表示数字是十六进制。如你所见,struct已将我们的数字7664转换为2个十六进制值:0xf0和0x1d。
为什么是0xf0 0x1d?好吧,如果你将7664转换为十六进制,你将获得0xf01d。
为什么两个值?因为我们使用的是16位值,而且我们的数字不能合二为一。因此,struct将其分为两个数字。
由于数字现在是十六进制,因此其他程序可以读取它们,包括我们的音频播放器。
回到我们的代码:
for s in sine_wave:
'h', int(s*amplitude)))
这将采用我们的正弦波样本并将其写入我们的文件test.wav,打包为16位音频。
在你拥有的任何音频播放器中播放文件 - Windows Media Player,VLC等。你应该能听到非常短的蜂鸣。
现在,我们需要检查音调的频率是否正确。我将使用Audacity,一个具有大量功能的开源音频播放器。其中之一就是我们可以找到音频文件的频率。让我们打开Audacity。

我们得到了一个正弦波。请注意,波形高达0.5,而1.0是最大值。还记得我们乘以16000,这是36767的一半。
现在找频率。转到编辑 - >全选(或按Ctrl A),然后选择分析 - >频谱分析。

可以看到峰值大约为1000 Hz,这就是我们创建波形文件的方式。
计算正弦波的频率
我在我的学位课程中参加了一门信号处理课程,并且不了解任何事情。我们被要求解一百个方程式,没有任何意义或逻辑。我发现这个主题很无聊和迂腐。
当我不得不再为我的硕士学习时,我不高兴。但我很幸运。
这次,老师是一名执业工程师。他经营自己的公司并兼职教学。与大学教师不同,他实际上知道方程式的用途。
但是这位老师(我忘了他的名字,他是一个丹麦人)向我们展示了一个嘈杂的信号,并且使用了DFT。然后他在图形窗口中显示结果。我们清楚地看到了原始的正弦波和噪声频率,我第一次理解了DFT的作用。
使用 DFT 获取频率
要获得正弦波的频率,你需要获得其离散傅立叶变换(DFT)。你不需要了解如何推导变换。你只需要知道如何使用它。
最简单的说,DFT接收信号并计算其中存在哪些频率。在更多技术术语中,DFT将时域信号转换为频域。那是什么意思?让我们来看看我们的正弦波。

波形随着时间而变化。如果这是一个音频文件,你可以想象播放器在文件播放时向右移动。
在频域中,你可以看到信号的频率部分。此图片将从本章后面的内容中获取,以显示频域的外观:

如果添加或删除频率,信号将发生变化,但不会及时更改。例如,如果你采用1000 Hz的音频并采用其频率,无论你看多长时间,频率都将保持不变。但是如果你在时域中看它,你会看到信号在移动。
DFT在计算机上运行得很慢(早在70年代),因此发明了快速傅里叶变换(FFT)。 FFT如今被广泛使用。
它的工作方式是,接收信号并在其上运行FFT,然后你会得到信号的频率。
如果你从未使用过(甚至没有听过)FFT,请不要担心。我将教你如何开始使用它,如果你愿意,你可以在线阅读更多内容。无论如何,大多数教程或书籍都不会教你太多。他们通常会用公式来轰炸你,而不会告诉你如何处理它们。
frame_rate = 48000.0
infile = "test.wav"
num_samples = 48000
wav_file = wave.open(infile, 'r')
data = wav_file.readframes(num_samples)
wav_file.close()View Code
我们正在读取我们在上一个例子中生成的wave文件。这段代码应该足够清楚。wave.readframes()函数从wave文件中读取所有音频帧。
data = struct.unpack('{n}h'.format(n=num_samples), data)还记得我们必须打包数据以使其以二进制格式可读吗?好吧,我们现在正好相反。该函数的第一个参数是格式字符。告诉解包器按照num_samples16位字来解压缩文件(记住h表示16位)。
data = np.array(data)然后我们将数据转换为numpy数组。
data_fft = np.fft.fft(data)我们接受数据的fft。这将创建一个包含信号中所有频率的阵列。
现在,这里就是问题所在。 fft返回一个复数的数组,不告诉我们任何东西。如果我打印出fft的前8个值,会得到:
In [3]: data_fft[:8]
Out[3]:
array([ 13.00000000 +0.j , 8.44107682 -4.55121351j,
6.24696630-11.98027552j, 4.09513760 -2.63009999j,
-0.87934285 +9.52378503j, 2.62608334 +3.58733642j,
4.89671762 -3.36196984j, -1.26176048 +3.0234555j ])Numpy 可以将复数转换为实数值。
# This will give us the frequency we want
frequencies = np.abs(data_fft)numpy abs()函数将获取我们的复数信号并生成它的实数值。
旁注
稍微解释一下FFT如何返回其结果。
FFT返回信号中所有可能的频率。它返回的方式是每个索引包含一个频率元素。假设你将FFT结果存储在名为data_fft的数组中。然后:
data_fft [1]将包含1 Hz的频率部分。
data_fft [2]将包含2 Hz的频率部分。
...
data_fft [8]将包含8 Hz的频率部分。
...
data_fft [1000]将包含1000 Hz的频率部分。
现在如果你的信号中没有1Hz频率怎么办?你仍然可以在data_fft [1]获得一个值,但它将是微不足道的。举个例子,我们来看看1000 Hz波的实际fft:
data_fft = np.fft.fft(sine_wave)
abs(data_fft[0])
Out[7]: 8.1289678326462086e-13
abs(data_fft[1])
Out[8]: 9.9475299243014428e-12
abs(data_fft[1000])
Out[11]: 24000.0如果你查看data_fft [0]或data_fft [1]的绝对值,你会发现它们很小。最后的e-12意味着它们被提升到-12的幂,所以对于data_fft [0]来说就像0.00000000000812。但是如果你看一下data_fft [1000],那么这个值就是24000.这可以很容易地绘制出来。
如果我们想要找到具有最高值的数组元素,我们可以通过以下方式找到它:
print("The frequency is {} Hz".format(np.argmax(frequencies)))np.argmax将返回信号中的最高频率,然后打印出来。正如我们手动看到的,这是1000Hz(或存储在data_fft [1000]的值)。现在我们也可以绘制数据。
plt.subplot(2,1,1)
plt.plot(data[:300])
plt.title("Original audio wave")
plt.subplot(2,1,2)
plt.plot(frequencies)
plt.title("Frequencies found")
plt.xlim(0,1200)
plt.show()subplot(2,1,1)意味着我们正在绘制一个2×1网格。第三个数字是图号,是唯一一个会改变的号码。

就是这样。我们获取了音频文件并计算了它的频率。接下来,我们将为我们的情景添加噪音,然后尝试清理它。
简单分离噪声
frequency = 1000
noisy_freq = 50
num_samples = 48000
sampling_rate = 48000.0非噪声的频率是1000Hz,我们加入50Hz的噪声。
# Create the sine wave and noise
sine_wave = [np.sin(2*np.pi*frequency*x1/sampling_rate) for x1 in range(num_samples)]
sine_noise = [np.sin(2*np.pi*noisy_freq*x1/sampling_rate) for x1 in range(num_samples)]
# Convert them to numpy arrays
sine_wave = np.array(sine_wave)
sine_noise = np.array(sine_noise)上面的构建代码和之前的类似。我们生成了两个正弦波,其中是一个信号另一个是噪声,并且我们将他们都转化为了一个numpy的数组
# Add them to create a noisy signal
combined_signal = sine_wave+sine_noise我把噪声加到了信号里。正如之前提到的,numpy才有这么方便的累加方式。如果是普通的python列表,则需要写一个for循环。总之numpy很方便啦。
把到目前为止得到的信号图像化:
plt.subplot(3,1,1)
plt.title('Original sine wave')
# Need to add empty space, else everything looks scrunched up!
plt.subplots_adjust(hspace=.5)
plt.plot(sine_wave[:500])
plt.subplot(3,1,2)
plt.title('Noise wave')
plt.plot(sine_noise[:4000])
plt.subplot(3,1,3)
plt.title('Original + Noise')
plt.plot(combined_signal[:3000])
plt.show()
data_fft = np.fft.fft(combined_signal)
freq = (np.abs(data_fft[:len(data_fft)]))
data_fft 包含了噪声+信号波的 fft. freq 包含了其中发现的频率的绝对值。
plt.plot(freq)
plt.title('Before filtering: Will have main signal(1000Hz) + noise frequency(50Hz)')
plt.xlim(0,1200)
现在来过滤信号。我不会详细介绍过滤的每个细节(因为那样可能要讲一整本书)。我将使用 fft 来创建一个简单的过滤器。
下面是完整的代码:
filtered_freq = []
index = 0
for f in freq:
# Filter between lower and upper limits
# Chooing 950, as closest to 1000. In real world, won't get exact numbers like these
if index > 950 and index<1050:
# Has a real value. I'm choosing >1 , as many values are like 0.00000001 etc
if f>1:
filtered_freq.append(f)
else:
filtered_freq.append(0)
else:
filtered_freq.append(0)
index+=1上述代码创建一个空列表 filtered_freq。如果你还记得的话, freq 存储了 fft 的绝对值。
index 是数组 freq 当前的索引。正如我说的,fft 返回了信号中所有的频率。
它们基于索引存储在数组中,因此 freq[1] 的频率为1Hz, freq[2] 的频率为2Hz,依此类推。
因为我知道我的目标信号频率是1000Hz,所以我会在这个值附近搜索它。在现实世界中,我们永远不会得到确切的频率,因为噪声意味着一些数据将会丢失。这里使用950的下限和1050的上限,代码检查我们循环的频率是否在这个范围内。
至于嵌套的 if else,同样在前文中有所提及:虽然所有频率都会有值来表示,但它们的绝对值将是微小的,通常小于1.因此,如果我们找到大于1的值,我们将其保存到filtered_freq数组中。
如果我们的频率不在我们正在寻找的范围内,或者如果该值太低,直接0。这是为了删除我们不想要的所有频率。然后我们移动索引到下一这个值。
接下来画出我们滤波后的图像:
plt.plot(filtered_freq)
plt.title('After filtering: Main signal only(1000Hz)')
plt.xlim(0,1200)
plt.show()
plt.close()
recovered_signal = np.fft.ifft(filtered_freq)现在我们使用 ifft,即 FFT 的逆过程。这将接收我们的信号并将其转换回时域。我们现在可以将它与原始噪声信号进行比较。
plt.subplot(3,1,1)
plt.title("Original sine wave")
# Need to add empty space, else everything looks scrunched up!
plt.subplots_adjust(hspace=.5)
plt.plot(sine_wave[:500])
plt.subplot(3,1,2)
plt.title("Noisy wave")
plt.plot(combined_signal[:4000])
plt.subplot(3,1,3)
plt.title("Sine wave after clean up")
plt.plot((recovered_signal[:500]))
plt.show()
注意我们会看到一个警告:
ComplexWarning: Casting complex values to real discards the imaginary part
return array(a, dtype, copy=False, order=order)这是因为fft返回一个复数数组。幸运的是,就像警告说的那样,虚部将被丢弃。
音频数据预处理
pydub的使用
参考网站:
- https://github.com/jiaaro/pydub
- http://pydub.com/
- https://github.com/jiaaro/pydub/blob/master/API.markdown
依赖要求:
- 需要安装ffmpeg服务或者 libav服务
- ffmpeg下载:http://ffmpeg.org/download.html
pydub的示例代码
# -- encoding:utf-8 --
"""
参考网站:
https://github.com/jiaaro/pydub
http://pydub.com/
https://github.com/jiaaro/pydub/blob/master/API.markdown
Create by ibf on 2018/10/27
"""
from pydub import AudioSegment
import numpy as np
import array
# 1. 读取数据
path = './data/20Hz-stero.wav'
# path = './data/我们的纪念.mp3'
# path = './data/我们的纪念.wav'
path = './data/童年.wav'
# path = './data/04.wav'
"""
file: 给定音频文件所在的磁盘路径
format=None: 给定文件的音频类型,参数可选;如果不给定的话,会使用文件的后缀作为读取的音频格式
"""
song = AudioSegment.from_file(file=path)
# 2. 相关属性
size = len(song)
print("音频文件的长度信息(毫秒):{}".format(size))
channel = song.channels
print("音频的通道数目:{}".format(channel))
frame_rate = song.frame_rate
print("音频的抽样频率:{}".format(frame_rate))
sample_width = song.sample_width
print("音频的样本宽度:{}".format(sample_width))
# 3. 设置相关的特征属性
# 如果降低音乐通道会带来音频的损失,但是增加不会带来损失(频率和样本宽度也一样)
song = song.set_channels(channels=2)
song = song.set_frame_rate(frame_rate=44100)
song = song.set_sample_width(sample_width=2)
print("音频文件的长度信息(毫秒):{}".format(len(song)))
print("音频的通道数目:{}".format(song.channels))
print("音频的抽样频率:{}".format(song.frame_rate))
print("音频的样本宽度:{}".format(song.sample_width))
# 4. 音频文件的保存
song.export('./data/01.wav', format='wav')
# 5. 获取部分数据保存
# 获取前10秒的数据保存
song[:10000].export('./data/02.wav', format='wav')
# 获取最后10秒的数据保存
song[-10000:].export('./data/03.wav', format='wav')
# 获取中间的10秒数据保存
mid = len(song) // 2
song[mid - 5000: mid + 5000].export('./data/04.wav', format='wav')
# 6. 填充保存
# a. 将song对象转换为numpy的array对象
samples = np.array(song.get_array_of_samples()).reshape(-1)
# print(samples.shape)
# print(samples[:10])
# b. 填充操作
append_size = 60 * song.channels * song.frame_rate
# pad_width:给定在什么位置填充,以及填充多少个值;在samples数组的前面添加append_size个值,后面添加0个值
# mode:给定填充方式,constant表示常量填充,要填充的常量需要给定,通过参数constant_values给定
# constant_values: 给定填充的常量
samples = np.pad(samples, pad_width=(append_size, 0), mode='constant', constant_values=(0, 0))
# print(samples.shape)
# print(samples[:10])
# c. 将截取的数组转换为Segment对象
song = song._spawn(array.array(song.array_type, samples))
song.export('./data/05.wav', format='wav')
# 7. 对音乐文件的处理
# eg: 音调、音频增大/减小...
(song + 10).export('./data/07.wav', format='wav')
(song - 10).export('./data/08.wav', format='wav')
samples = np.array(song.get_array_of_samples()).reshape(-1)
samples = (samples * 2).astype(np.int)
song = song._spawn(array.array(song.array_type, samples))
song.export('./data/09.wav', format='wav')
# 8. 音乐的循环
(song * 2).export('./data/10.wav', format='wav')View Code
# -- encoding:utf-8 --
"""
Create by ibf on 2018/10/27
"""
import glob
from pydub import AudioSegment
file_paths = glob.glob('./data/*.wav')
for idx, file_path in enumerate(file_paths):
song = AudioSegment.from_file(file_path)
song = song.set_channels(channels=2)
song = song.set_frame_rate(frame_rate=44100)
song = song.set_sample_width(sample_width=2)
song = song[:31000]
song.export('./data/input/{}.wav'.format(idx), format='wav')View Code
音频剪切和播放
# -- encoding:utf-8 --
"""
Create by ibf on 2018/10/27
"""
from pydub import AudioSegment
import os
'''
glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,类似于Windows下的文件搜索,
支持通配符操作,,?,[]这三个通配符,代表0个或多个字符,?代表一个字符,[]匹配指定范围内的字符,如[0-9]匹配数字。
'''
import glob
file_paths = glob.glob(r'D:\AI_pycharm_Code_ backups\Machine_learning_SkLearning\sklearn09\project\music\data\input\WAV删减源文件和8K采样文件\擦肩而过.wav')
print(file_paths)
output_file_path = './data/output'
if not os.path.exists(output_file_path):
os.makedirs(output_file_path)
k = 1
for file_path in file_paths:
song = AudioSegment.from_file(file_path)
song_length = len(song)
print(song_length)
start = 0
kk = 1
while start < song_length:
end = int(min(start+2500, song_length))
song[start:end].export(output_file_path + "/{}_{}.wav".format(k, kk), format='wav')
start = end
kk += 1
k += 1
print("Done!!!")
'''AudioSegment对象的播放'''
from pydub import playback
playback.play(song)
'''array数组的播放'''
import sounddevice
import numpy as np
sounddevice.play(np.array(song.get_array_of_samples()),song.frame_rate,blocking=True)View Code
特征提取
音乐的标签主要体现的是音乐的类型。可以根据音乐的声音特性进行音乐类型的判断,从而可以得到音乐 的标签值。所以说我们只要提取出音乐的声音特性,也就可以利用算法进行标 签值的预测啦!
MFCC(Mel Frequency Cepstral Coefficents)梅尔频率倒谱系数
在声音处理领域中,梅尔频率倒谱(Mel-Frequency Cepstrum)是基于声音频率的非线性梅尔刻度(mel scale)的对数能量频谱的线性变换。
梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCCs)就是组成梅尔频率倒谱的系数。它衍生自音讯片段的倒频谱(cepstrum)。倒谱和梅尔频率倒谱的区别在于,梅尔频率倒谱的频带划分是在梅尔刻度上等距划分的,它比用于正常的对数倒频谱中的线性间隔的频带更能近似人类的听觉系统。 这样的非线性表示,可以在多个领域中使声音信号有更好的表示。例如在音讯压缩中。
梅尔频率倒谱系数(MFCC)广泛被应用于语音识别的功能。他们由Davis和Mermelstein在1980年代提出,并在其后持续是最先进的技术之一。在MFCC之前,线性预测系数(LPCS)和线性预测倒谱系数(LPCCs)是自动语音识别的的主流方法。
在机器学习中,我们可以梅尔频率倒谱系数这一特性作为音频的特征。
使用scipy库中的方法进行wav格式音乐文件的读取, 然后使用python_speech_features(或librosa)中的MFCC相关方法对语音数据进行特征抽取操作。python_speech_features只能处理wav格式文件。
MFCC系数提取步骤:
- 语音信号分帧处理
- 每一帧傅里叶变换---->功率谱
- 将短时功率谱通过mel滤波器
- 滤波器组系数取对数
- 将滤波器组系数的对数进行离散余弦变换(DCT)
- 一般将第2到底13个倒谱系数保留作为短时语音信号的特征
python实现mfcc提取
import wave
import numpy as np
import math
import matplotlib.pyplot as plt
from scipy.fftpack import dct
def read(data_path):
'''读取语音信号
'''
wavepath = data_path
f = wave.open(wavepath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4] #声道数、量化位数、采样频率、采样点数
str_data = f.readframes(nframes) #读取音频,字符串格式
f.close()
wavedata = np.fromstring(str_data,dtype = np.short) #将字符串转化为浮点型数据
wavedata = wavedata * 1.0 / (max(abs(wavedata))) #wave幅值归一化
return wavedata,nframes,framerate
def enframe(data,win,inc):
'''对语音数据进行分帧处理
input:data(一维array):语音信号
wlen(int):滑动窗长
inc(int):窗口每次移动的长度
output:f(二维array)每次滑动窗内的数据组成的二维array
'''
nx = len(data) #语音信号的长度
try:
nwin = len(win)
except Exception as err:
nwin = 1
if nwin == 1:
wlen = win
else:
wlen = nwin
nf = int(np.fix((nx - wlen) / inc) + 1) #窗口移动的次数
f = np.zeros((nf,wlen)) #初始化二维数组
indf = [inc * j for j in range(nf)]
indf = (np.mat(indf)).T
inds = np.mat(range(wlen))
indf_tile = np.tile(indf,wlen)
inds_tile = np.tile(inds,(nf,1))
mix_tile = indf_tile + inds_tile
f = np.zeros((nf,wlen))
for i in range(nf):
for j in range(wlen):
f[i,j] = data[mix_tile[i,j]]
return f
def point_check(wavedata,win,inc):
'''语音信号端点检测
input:wavedata(一维array):原始语音信号
output:StartPoint(int):起始端点
EndPoint(int):终止端点
'''
#1.计算短时过零率
FrameTemp1 = enframe(wavedata[0:-1],win,inc)
FrameTemp2 = enframe(wavedata[1:],win,inc)
signs = np.sign(np.multiply(FrameTemp1,FrameTemp2)) # 计算每一位与其相邻的数据是否异号,异号则过零
signs = list(map(lambda x:[[i,0] [i>0] for i in x],signs))
signs = list(map(lambda x:[[i,1] [i<0] for i in x], signs))
diffs = np.sign(abs(FrameTemp1 - FrameTemp2)-0.01)
diffs = list(map(lambda x:[[i,0] [i<0] for i in x], diffs))
zcr = list((np.multiply(signs, diffs)).sum(axis = 1))
#2.计算短时能量
amp = list((abs(enframe(wavedata,win,inc))).sum(axis = 1))
# # 设置门限
# print('设置门限')
ZcrLow = max([round(np.mean(zcr)*0.1),3])#过零率低门限
ZcrHigh = max([round(max(zcr)*0.1),5])#过零率高门限
AmpLow = min([min(amp)*10,np.mean(amp)*0.2,max(amp)*0.1])#能量低门限
AmpHigh = max([min(amp)*10,np.mean(amp)*0.2,max(amp)*0.1])#能量高门限
# 端点检测
MaxSilence = 8 #最长语音间隙时间
MinAudio = 16 #最短语音时间
Status = 0 #状态0:静音段,1:过渡段,2:语音段,3:结束段
HoldTime = 0 #语音持续时间
SilenceTime = 0 #语音间隙时间
print('开始端点检测')
StartPoint = 0
for n in range(len(zcr)):
if Status ==0 or Status == 1:
if amp[n] > AmpHigh or zcr[n] > ZcrHigh:
StartPoint = n - HoldTime
Status = 2
HoldTime = HoldTime + 1
SilenceTime = 0
elif amp[n] > AmpLow or zcr[n] > ZcrLow:
Status = 1
HoldTime = HoldTime + 1
else:
Status = 0
HoldTime = 0
elif Status == 2:
if amp[n] > AmpLow or zcr[n] > ZcrLow:
HoldTime = HoldTime + 1
else:
SilenceTime = SilenceTime + 1
if SilenceTime < MaxSilence:
HoldTime = HoldTime + 1
elif (HoldTime - SilenceTime) < MinAudio:
Status = 0
HoldTime = 0
SilenceTime = 0
else:
Status = 3
elif Status == 3:
break
if Status == 3:
break
HoldTime = HoldTime - SilenceTime
EndPoint = StartPoint + HoldTime
return FrameTemp1[StartPoint:EndPoint]
def mfcc(FrameK,framerate,win):
'''提取mfcc参数
input:FrameK(二维array):二维分帧语音信号
framerate:语音采样频率
win:分帧窗长(FFT点数)
output:
'''
#mel滤波器
mel_bank,w2 = mel_filter(24,win,framerate,0,0.5)
FrameK = FrameK.T
#计算功率谱
S = abs(np.fft.fft(FrameK,axis = 0)) ** 2
#将功率谱通过滤波器
P = np.dot(mel_bank,S[0:w2,:])
#取对数
logP = np.log(P)
#计算DCT系数
# rDCT = 12
# cDCT = 24
# dctcoef = []
# for i in range(1,rDCT+1):
# tmp = [np.cos((2*j+1)*i*math.pi*1.0/(2.0*cDCT)) for j in range(cDCT)]
# dctcoef.append(tmp)
# #取对数后做余弦变换
# D = np.dot(dctcoef,logP)
num_ceps = 12
D = dct(logP,type = 2,axis = 0,norm = 'ortho')[1:(num_ceps+1),:]
return S,mel_bank,P,logP,D
def mel_filter(M,N,fs,l,h):
'''mel滤波器
input:M(int):滤波器个数
N(int):FFT点数
fs(int):采样频率
l(float):低频系数
h(float):高频系数
output:melbank(二维array):mel滤波器
'''
fl = fs * l #滤波器范围的最低频率
fh = fs * h #滤波器范围的最高频率
bl = 1125 * np.log(1 + fl / 700) #将频率转换为mel频率
bh = 1125 * np.log(1 + fh /700)
B = bh - bl #频带宽度
y = np.linspace(0,B,M+2) #将mel刻度等间距
print('mel间隔',y)
Fb = 700 * (np.exp(y / 1125) - 1) #将mel变为HZ
print(Fb)
w2 = int(N / 2 + 1)
df = fs / N
freq = [] #采样频率值
for n in range(0,w2):
freqs = int(n * df)
freq.append(freqs)
melbank = np.zeros((M,w2))
print(freq)
for k in range(1,M+1):
f1 = Fb[k - 1]
f2 = Fb[k + 1]
f0 = Fb[k]
n1 = np.floor(f1/df)
n2 = np.floor(f2/df)
n0 = np.floor(f0/df)
for i in range(1,w2):
if i >= n1 and i <= n0:
melbank[k-1,i] = (i-n1)/(n0-n1)
if i >= n0 and i <= n2:
melbank[k-1,i] = (n2-i)/(n2-n0)
plt.plot(freq,melbank[k-1,:])
plt.show()
return melbank,w2
if __name__ == '__main__':
data_path = 'audio_data.wav'
win = 256
inc = 80
wavedata,nframes,framerate = read(data_path)
FrameK = point_check(wavedata,win,inc)
S,mel_bank,P,logP,D = mfcc(FrameK,framerate,win)View Code
python_speech_features提取mfcc
# -- encoding:utf-8 --
"""
提取音频文件的MFCC的特征数据
Create by ibf on 2018/10/27
"""
from scipy.io import wavfile
from python_speech_features import mfcc
# 1. 读取wav格式的数据
path = './data/pydub/1.wav'
path = './data/1KHz-stero.wav'
path = "./data/童年.wav"
(rate, data) = wavfile.read(path)
print("音频文件的抽样频率:{}".format(rate))
print("音频文件的数据大小:{}".format(data.shape))
print(data[44100:44110])
print("*" * 100)
# 2. 提取MFCC的值
"""
signal: 给定音频数据的数据,是一个数组的形式
samplerate: 给定的音频数据的抽样频率
numcep:在MFCC进行倒谱操作的时候,给定将一个时间段分割为多少个空间,也可以认为是使用多少个特征信息来进行体现音频数据的
nfft:在傅里叶变换的过程中,参数值
"""
mfcc_feat = mfcc(signal=data, samplerate=rate, numcep=26, nfft=2048)
print(type(mfcc_feat))
print(mfcc_feat.shape)
print(mfcc_feat)
n_sample = mfcc_feat.reshape(-1)
print("最终的特征大小:{}".format(n_sample.shape))librosa提取mfcc
import librosa
# Load a wav file
y, sr = librosa.load('./teat.wav', sr=None)
print(y.shape)
print(sr)
# extract mfcc feature
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40)
# print(mfccs.shape)参考网址:
http://wap.sciencenet.cn/blog-3396477-1162619.html?mobile=1
MFCC提取过程讲解的非常详细,形象(图表多)
2. MFCC原理上讲解的很简洁,有基于MATLAB和HTK的实现代码
3. 另一篇MFCC Blog
4. CMU关于MFCC介绍的经典Slides:http://www.speech.cs.cmu.edu/15-492/slides/03_mfcc.pdf
5. MFCC英文版教程:http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/
隐马尔科夫提取音频特征
# -- encoding:utf-8 --
"""
Create by ibf on 2018/10/27
"""
import warnings
from pydub import AudioSegment
import numpy as np
from hmmlearn import hmm
warnings.filterwarnings('ignore')
paths = ['./data/1KHz-stero.wav',
'./data/10KHz-stero.wav',
'./data/20Hz-stero.wav']
x = None
for path in paths:
song = AudioSegment.from_file(file=path)
song = song[:10000]
samples = np.array(song.get_array_of_samples()).reshape((1, -1))
if x is None:
x = samples
else:
x = np.append(x, samples, axis=0)
print(x.shape)
x = x.reshape(3, -1, 2 * 1000)
print(x.shape)
# 使用HMM来提取特征
sample = x.reshape(-1, 2 * 1000).astype(np.int32)
print("样本大小:{}".format(sample.shape))
lengths = []
for i in range(len(paths)):
lengths.append(x.shape[1])
print("序列:{}".format(lengths))
n = 100
model = hmm.GaussianHMM(n_components=n, random_state=28)
model.fit(sample, lengths=lengths)
# 预测获取结果
print("模型训练得到的参数π:")
print(model.startprob_)
print("模型训练得到的参数A:")
print(model.transmat_)
# 预测
y_hat = model.predict(sample, lengths)
# 做一个新的转换(得到新的特征)
new_x = y_hat.reshape(3, -1)
print(new_x.shape)View Code
GMM-HMM语音识别原理
HMM
隐马尔科夫模型(HMM)是一种统计模型,用来描述含有隐含参数的马尔科夫过程。难点是从隐含状态确定出马尔科夫过程的参数,以此作进一步的分析。下图是一个三个状态的隐马尔可夫模型状态转移图,其中x 表示隐含状态,y 表示可观察的输出,a 表示状态转换概率,b 表示输出概率:
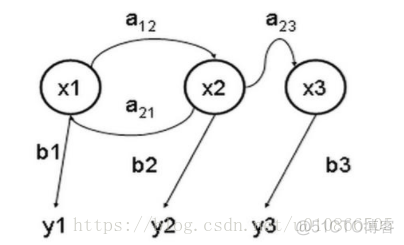
a:转移概率
b:输出概率
y:观测状态
x:隐含状态
一个HMM模型是一个五元组(π,A,B,O,S)
其中π:初始概率向量
A: 转移概率
B: 输出概率
O:观测状态
S:隐含状态
围绕着HMM,有三个和它相关的问题:
1. 已知隐含状态数目,已知转移概率,根据观测状态,估计观测状态对应的隐含状态
2. 已知隐含状态数目,已知转移概率,根据观测状态,估计输出这个观测状态的概率
3. 已知隐含状态数目,根据大量实验结果(很多组观测状态),反推转移概率
对于第一个问题,所对应的就是维特比算法
对于第二个问题,所对应的就是前向算法
对于第三个问题,就是前向后向算法
语音识别的过程其实就是上述的第一个问题。根据HMM模型和观测状态(即语音信号数字信号处理后的内容),得到我们要的状态,而状态的组合就是识别出来的文本。
为啥呢?
1) 在语音处理中,一个word有一个或多个音素构成。怎么说呢?这里补充一下语言学的一些知识。在语言学中,word(字)还可以再分解成音节(syllable),音节可以再分成音素(phoneme),音素之后就不能再分了.因此音素是语音中最小的单元,不管语音识别还是语音合成,都是在最小单元上进行操作的,即phoneme。比如我们的“我”,它的拼音是wo3(这个其实就是word,即字),由于中文的word和syllable是相同的,即中文是单音节语言,即中文有且只有一个音节,但英文就不一样,比如hello这个单词,他就是有两个音节,hello=hae|low,即hello有hae和low这两个音节组成.音节下一层是phoneme(音素),语音识别的过程就是把这些 音素找到,然后音素拼接成音节,音节在拼接成word.如下图所示
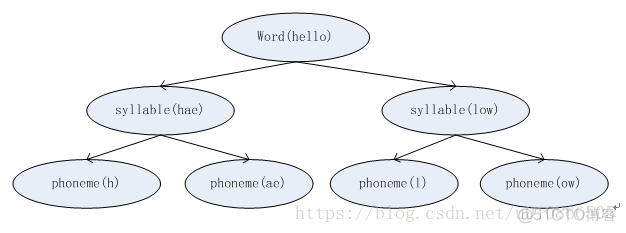
在识别过程中如果识别出来了音素,向上递归,就能得到word。
因此我们的目标是获取音素phoneme.
2) 在训练时,一个HMM对应一个音素,每个HMM包含n个state(状态),有的是3个状态,有的是5个状态,状态数在训练前确定后,一旦训练完成所有HMM的状态个数都是一致的,比如3个。
GMM是当做发射概率的,即在已知观测状态情况下,哪一种音素会产生这种状态的概率,概率最大的就是我们要的音素。因此,GMM是来计算某一个音素的概率。
GMM的全称是gaussmixture model(高斯混合模型),在训练前,一般会定义由几个高斯来决定音素的概率(高斯数目是超参数)。如下图所示为3高斯:
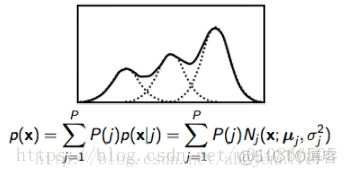
假设现在我们定义一个HMM由3个状态组成,每个状态中有一个GMM,每个GMM中是由3个gauss。
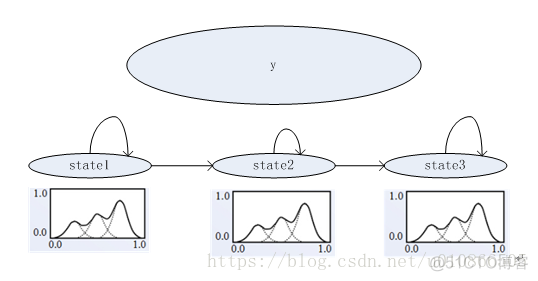
如上图假设y有状态1,2,3组成,每一个状态下面有一个GMM,高斯个数是3.
由此我们训练的参数有HMM的转移概率矩阵+每一个单高斯的方差,均值和权重(当然还有一个初始概率矩阵).如果我们能得到这些参数,我们是不是就能进行语音识别了?
接下来,就看看GMM-HMM到底是如何做到的?
1:将送进来的语音信号进行分帧(一般是20ms一帧,帧移是10ms),然后提取特征
2:用GMM,判断当前的特征序列属于哪个状态(计算概率)
3:根据前面两个步骤,得出状态序列,其实就得到了音素序列,即得到了声韵母序列。
如下面图所示.
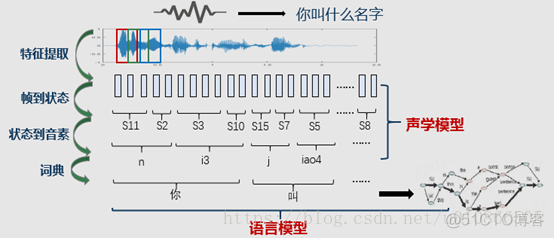
对于GMM-HMM实现语音识别(确切的说是非连续语音识别),到此基本上就结束了,对于连续语音识别而言,还有一个语言模型(主要是通过语料库,n-gram模型)。而前面的GMM-HMM就是声学模型.
代码解析:
下面是关于GMM-HMM声学模型,特征序列提取到训练,并且实现识别的完整代码(操作系统:ubuntu16.04,python2)
该demo总共有三个文件,
1:gParam.py,主要是为了配置一些参数
2:核心文件是my_hmm.py,里面实现的是主要代码。
3:test.py是运行文件.
该demo主要是实现识别阿拉伯数字,1,2,3,4.....你可以自己录制训练数据和测试数据.然后设置好路径,运行下面的程序.
程序是完整的
程序是完整的
程序是完整的
说三遍.
wav数据的格式是:

#! /usr/bin python
# encoding:utf-8
TRAIN_DATA_PATH = './data/train/'
TEST_DATA_PATH = './data/test/'
NSTATE = 4
NPDF = 3
MAX_ITER_CNT = 100
NUM=10gParam.py
#! /usr/bin python
# encoding:utf_8
import numpy as np
from numpy import *
from sklearn.cluster import KMeans
from scipy import sparse
import scipy.io as sio
from scipy import signal
import wave
import math
import gParam
import copy
def pdf(m,v,x):
'''计算多元高斯密度函数
输入:
m---均值向量 SIZE×1
v---方差向量 SIZE×1
x---输入向量 SIZE×1
输出:
p---输出概率'''
test_v = np.prod(v,axis=0)
test_x = np.dot((x-m)/v,x-m)
p = (2*math.pi*np.prod(v,axis=0))**-0.5*np.exp(-0.5*np.dot((x-m)/v,x-m))
return p
# class of every sample infomation
class sampleInfo:
"""docstring for ClassName"""
def __init__(self):
self.smpl_wav = []
self.smpl_data = []
self.seg = []
def set_smpl_wav(self,wav):
self.smpl_wav.append(wav)
def set_smpl_data(self,data):
self.smpl_data.append(data)
def set_segment(self, seg_list):
self.seg = seg_list
#class of mix info from KMeans
class mixInfo:
"""docstring for mixInfo"""
def __init__(self):
self.Cmean = []
self.Cvar = []
self.Cweight = []
self.CM = []
class hmmInfo:
'''hmm model param'''
def __init__(self):
self.init = [] #初始矩阵
self.trans = [] #转移概率矩阵
self.mix = [] #高斯混合模型参数
self.N = 0 #状态数
# class of gmm_hmm model
class gmm_hmm:
def __init__(self):
self.hmm = [] #单个hmm序列,
self.gmm_hmm_model = [] #把所有的训练好的gmm-hmm写入到这个队列
self.samples = [] # 0-9 所有的音频数据
self.smplInfo = [] #这里面主要是单个数字的音频数据和对应mfcc数据
self.stateInfo = [gParam.NPDF,gParam.NPDF,gParam.NPDF,gParam.NPDF]#每一个HMM对应len(stateInfo)个状态,每个状态指定高斯个数(3)
def loadWav(self,pathTop):
for i in range(gParam.NUM):
tmp_data = []
for j in range(gParam.NUM):
wavPath = pathTop + str(i) + str(j) + '.wav'
f = wave.open(wavPath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4]
str_data = f.readframes(nframes)
#print shape(str_data)
f.close()
wave_data = np.fromstring(str_data,dtype=short)/32767.0
#wave_data.shape = -1,2
#wave_data = wave_data.T
#wave_data = wave_data.reshape(1,wave_data.shape[0]*wave_data.shape[1])
#print shape(wave_data),type(wave_data)
tmp_data.append(wave_data)
self.samples.append(tmp_data)
#循环读数据,然后进行训练
def hmm_start_train(self):
Nsmpls = len(self.samples)
for i in range(Nsmpls):
tmpSmplInfo0 = []
n = len(self.samples[i])
for j in range(n):
tmpSmplInfo1 = sampleInfo()
tmpSmplInfo1.set_smpl_wav(self.samples[i][j])
tmpSmplInfo0.append(tmpSmplInfo1)
#self.smplInfo.append(tmpSmplInfo0)
print '现在训练第%d个HMM模型' %i
hmm0 = self.trainhmm(tmpSmplInfo0,self.stateInfo)
print '第%d个模型已经训练完毕' %i
# self.gmm_hmm_model.append(hmm0)
#训练hmm
def trainhmm(self,sample,state):
K = len(sample)
print '首先进行语音参数计算-MFCC'
for k in range(K):
tmp = self.mfcc(sample[k].smpl_wav)
sample[k].set_smpl_data(tmp) # 设置MFCCdata
hmm = self.inithmm(sample,state)
pout = zeros((gParam.MAX_ITER_CNT,1))
for my_iter in range(gParam.MAX_ITER_CNT):
print '第%d遍训练' %my_iter
hmm = self.baum(hmm,sample)
for k in range(K):
pout[my_iter,0] = pout[my_iter,0] + self.viterbi(hmm,sample[k].smpl_data[0])
if my_iter > 0:
if(abs((pout[my_iter,0] - pout[my_iter-1,0])/pout[my_iter,0]) < 5e-6):
print '收敛'
self.gmm_hmm_model.append(hmm)
return hmm
self.gmm_hmm_model.append(hmm)
#获取MFCC参数
def mfcc(self,k):
M = 24 #滤波器的个数
N = 256 #一帧语音的采样点数
arr_mel_bank = self.melbank(M,N,8000,0,0.5,'m')
arr_mel_bank = arr_mel_bank/np.amax(arr_mel_bank)
#计算DCT系数, 12*24
rDCT = 12
cDCT = 24
dctcoef = []
for i in range(1,rDCT+1):
tmp = [np.cos((2*j+1)*i*math.pi*1.0/(2.0*cDCT)) for j in range(cDCT)]
dctcoef.append(tmp)
#归一化倒谱提升窗口
w = [1+6*np.sin(math.pi*i*1.0/rDCT) for i in range(1,rDCT+1)]
w = w/np.amax(w)
#预加重
AggrK = double(k)
AggrK = signal.lfilter([1,-0.9375],1,AggrK)# ndarray
#AggrK = AggrK.tolist()
#分帧
FrameK = self.enframe(AggrK[0],N,80)
n0,m0 = FrameK.shape
for i in range(n0):
#temp = multiply(FrameK[i,:],np.hamming(N))
#print shape(temp)
FrameK[i,:] = multiply(FrameK[i,:],np.hamming(N))
FrameK = FrameK.T
#计算功率谱
S = (abs(np.fft.fft(FrameK,axis=0)))**2
#将功率谱通过滤波器组
P = np.dot(arr_mel_bank,S[0:129,:])
#取对数后做余弦变换
D = np.dot(dctcoef,log(P))
n0,m0 = D.shape
m = []
for i in range(m0):
m.append(np.multiply(D[:,i],w))
n0,m0 = shape(m)
dtm = zeros((n0,m0))
for i in range(2,n0-2):
dtm[i,:] = -2*m[i-2][:] - m[i-1][:] + m[i+1][:] + 2*m[i+2][:]
dtm = dtm/3.0
# cc = [m,dtm]
cc =np.column_stack((m,dtm))
# cc.extend(list(dtm))
cc = cc[2:n0-2][:]
#print shape(cc)
return cc
#melbank
def melbank(self,p,n,fs,f1,fh,w):
f0 = 700.0/(1.0*fs)
fn2 = floor(n/2.0)
lr = math.log((float)(f0+fh)/(float)(f0+f1))/(float)(p+1)
tmpList = [0,1,p,p+1]
bbl = []
for i in range(len(tmpList)):
bbl.append(n*((f0+f1)*math.exp(tmpList[i]*lr) - f0))
#b1 = n*((f0+f1) * math.exp([x*lr for x in tmpList]) - f0)
#print bbl
b2 = ceil(bbl[1])
b3 = floor(bbl[2])
if(w == 'y'):
pf = np.log((f0+range(b2,b3)/n)/(f0+f1))/lr #note
fp = floor(pf)
r = [ones((1,b2)),fp,fp+1, p*ones((1,fn2-b3))]
c = [range(0,b3),range(b2,fn2)]
v = 2*[0.5,ones((1,b2-1)),1-pf+fp,pf-fp,ones((1,fn2-b3-1)),0.5]
mn = 1
mx = fn2+1
else:
b1 = floor(bbl[0])+1
b4 = min([fn2,ceil(bbl[3])])-1
pf = []
for i in range(int(b1),int(b4+1),1):
pf.append(math.log((f0+(1.0*i)/n)/(f0+f1))/lr)
fp = floor(pf)
pm = pf - fp
k2 = b2 - b1 + 1
k3 = b3 - b1 + 1
k4 = b4 - b1 + 1
r = fp[int(k2-1):int(k4)]
r1 = 1+fp[0:int(k3)]
r = r.tolist()
r1 = r1.tolist()
r.extend(r1)
#r = [fp[int(k2-1):int(k4)],1+fp[0:int(k3)]]
c = range(int(k2),int(k4+1))
c2 = range(1,int(k3+1))
# c = c.tolist()
# c2 = c2.tolist()
c.extend(c2)
#c = [range(int(k2),int(k4+1)),range(0,int(k3))]
v = 1-pm[int(k2-1):int(k4)]
v = v.tolist()
v1 = pm[0:int(k3)]
v1 = v1.tolist()
v.extend(v1)#[1-pm[int(k2-1):int(k4)],pm[0:int(k3)]]
v = [2*x for x in v]
mn = b1 + 1
mx = b4 + 1
if(w == 'n'):
v = 1 - math.cos(v*math.pi/2)
elif (w == 'm'):
tmpV = []
# for i in range(v):
# tmpV.append(1-0.92/1.08*math.cos(v[i]*math))
v = [1 - 0.92/1.08*math.cos(x*math.pi/2) for x in v]
#print type(c),type(mn)
col_list = [x+int(mn)-2 for x in c]
r = [x-1 for x in r]
x = sparse.coo_matrix((v,(r,col_list)),shape=(p,1+int(fn2)))
matX = x.toarray()
#np.savetxt('./data.csv',matX, delimiter=' ')
return matX#x.toarray()
#分帧函数
def enframe(self,x,win,inc):
nx = len(x)
try:
nwin = len(win)
except Exception as err:
# print err
nwin = 1
if (nwin == 1):
wlen = win
else:
wlen = nwin
#print inc,wlen,nx
nf = fix(1.0*(nx-wlen+inc)/inc) #here has a bug that nf maybe less than 0
f = zeros((int(nf),wlen))
indf = [inc*j for j in range(int(nf))]
indf = (mat(indf)).T
inds = mat(range(wlen))
indf_tile = tile(indf,wlen)
inds_tile = tile(inds,(int(nf),1))
mix_tile = indf_tile + inds_tile
for i in range(nf):
for j in range(wlen):
f[i,j] = x[mix_tile[i,j]]
#print x[mix_tile[i,j]]
if nwin>1: #TODOd
w = win.tolist()
#w_tile = tile(w,(int))
return f
# init hmm
def inithmm(self,sample,M):
K = len(sample)
N0 = len(M)
self.N = N0
#初始概率矩阵
hmm = hmmInfo()
hmm.init = zeros((N0,1))
hmm.init[0] = 1
hmm.trans = zeros((N0,N0))
hmm.N = N0
#初始化转移概率矩阵
for i in range(self.N-1):
hmm.trans[i,i] = 0.5
hmm.trans[i,i+1] = 0.5
hmm.trans[self.N-1,self.N-1] = 1
#概率密度函数的初始聚类
#分段
for k in range(K):
T = len(sample[k].smpl_data[0])
#seg0 = []
seg0 = np.floor(arange(0,T,1.0*T/N0))
#seg0 = int(seg0.tolist())
seg0 = np.concatenate((seg0,[T]))
#seg0.append(T)
sample[k].seg = seg0
#对属于每个状态的向量进行K均值聚类,得到连续混合正态分布
mix = []
for i in range(N0):
vector = []
for k in range(K):
seg1 = int(sample[k].seg[i])
seg2 = int(sample[k].seg[i+1])
tmp = []
tmp = sample[k].smpl_data[0][seg1:seg2][:]
if k == 0:
vector = np.array(tmp)
else:
vector = np.concatenate((vector, np.array(tmp)))
#vector.append(tmp)
# tmp_mix = mixInfo()
# print id(tmp_mix)
tmp_mix = self.get_mix(vector,M[i],mix)
# mix.append(tmp_mix)
hmm.mix = mix
return hmm
# get mix data
def get_mix(self,vector,K,mix0):
kmeans = KMeans(n_clusters = K,random_state=0).fit(np.array(vector))
#计算每个聚类的标准差,对角阵,只保存对角线上的元素
mix = mixInfo()
var0 = []
mean0 = []
#ind = []
for j in range(K):
#ind = [i for i in kmeans.labels_ if i==j]
ind = []
ind1 = 0
for i in kmeans.labels_:
if i == j:
ind.append(ind1)
ind1 = ind1 + 1
tmp = [vector[i][:] for i in ind]
var0.append(np.std(tmp,axis=0))
mean0.append(np.mean(tmp,axis=0))
weight0 = zeros((K,1))
for j in range(K):
tmp = 0
ind1 = 0
for i in kmeans.labels_:
if i == j:
tmp = tmp + ind1
ind1 = ind1 + 1
weight0[j] = tmp
weight0=weight0/weight0.sum()
mix.Cvar = multiply(var0,var0)
mix.Cmean = mean0
mix.CM = K
mix.Cweight = weight0
mix0.append(mix)
return mix0
#baum-welch 算法实现函数体
def baum(self,hmm,sample):
mix = copy.deepcopy(hmm.mix)#高斯混合
N = len(mix) #HMM状态数
K = len(sample) #语音样本数
SIZE = shape(sample[0].smpl_data[0])[1] #参数阶数,MFCC维数
print '计算样本参数.....'
c = []
alpha = []
beta = []
ksai = []
gama = []
for k in range(K):
c0,alpha0,beta0,ksai0,gama0 = self.getparam(hmm, sample[k].smpl_data[0])
c.append(c0)
alpha.append(alpha0)
beta.append(beta0)
ksai.append(ksai0)
gama.append(gama0)
# 重新估算概率转移矩阵
print '----- 重新估算概率转移矩阵 -----'
for i in range(N-1):
denom = 0
for k in range(K):
ksai0 = ksai[k]
tmp = ksai0[:,i,:]#ksai0[:][i][:]
denom = denom + sum(tmp)
for j in range(i,i+2):
norm = 0
for k in range(K):
ksai0 = ksai[k]
tmp = ksai0[:,i,j]#[:][i][j]
norm = norm + sum(tmp)
hmm.trans[i,j] = norm/denom
# 重新估算发射概率矩阵,即GMM的参数
print '----- 重新估算输出概率矩阵,即GMM的参数 -----'
for i in range(N):
for j in range(mix[i].CM):
nommean = zeros((1,SIZE))
nomvar = zeros((1,SIZE))
denom = 0
for k in range(K):
gama0 = gama[k]
T = shape(sample[k].smpl_data[0])[0]
for t in range(T):
x = sample[k].smpl_data[0][t][:]
nommean = nommean + gama0[t,i,j]*x
nomvar = nomvar + gama0[t,i,j] * (x - mix[i].Cmean[j][:])**2
denom = denom + gama0[t,i,j]
hmm.mix[i].Cmean[j][:] = nommean/denom
hmm.mix[i].Cvar[j][:] = nomvar/denom
nom = 0
denom = 0
#计算pdf权值
for k in range(K):
gama0 = gama[k]
tmp = gama0[:,i,j]
nom = nom + sum(tmp)
tmp = gama0[:,i,:]
denom = denom + sum(tmp)
hmm.mix[i].Cweight[j] = nom/denom
return hmm
#前向-后向算法
def getparam(self,hmm,O):
'''给定输出序列O,计算前向概率alpha,后向概率beta
标定系数c,及ksai,gama
输入: O:n*d 观测序列
输出: param: 包含各种参数的结构'''
T = shape(O)[0]
init = hmm.init #初始概率
trans = copy.deepcopy(hmm.trans) #转移概率
mix = copy.deepcopy(hmm.mix) #高斯混合
N = hmm.N #状态数
#给定观测序列,计算前向概率alpha
x = O[0][:]
alpha = zeros((T,N))
#----- 计算前向概率alpha -----#
for i in range(N): #t=0
tmp = hmm.init[i] * self.mixture(mix[i],x)
alpha[0,i] = tmp #hmm.init[i]*self.mixture(mix[i],x)
#标定t=0时刻的前向概率
c = zeros((T,1))
c[0] = 1.0/sum(alpha[0][:])
alpha[0][:] = c[0] * alpha[0][:]
for t in range(1,T,1): # t = 1~T
for i in range(N):
temp = 0.0
for j in range(N):
temp = temp + alpha[t-1,j]*trans[j,i]
alpha[t,i] = temp *self.mixture(mix[i],O[t][:])
c[t] = 1.0/sum(alpha[t][:])
alpha[t][:] = c[t]*alpha[t][:]
#----- 计算后向概率 -----#
beta = zeros((T,N))
for i in range(N): #T时刻
beta[T-1,i] = c[T-1]
for t in range(T-2,-1,-1):
x = O[t+1][:]
for i in range(N):
for j in range(N):
beta[t,i] = beta[t,i] + beta[t+1,j]*self.mixture(mix[j],x) * trans[i,j]
beta[t][:] = c[t] * beta[t][:]
# 过渡概率ksai
ksai = zeros((T-1,N,N))
for t in range(0,T-1):
denom = sum(np.multiply(alpha[t][:],beta[t][:]))
for i in range(N-1):
for j in range(i,i+2,1):
norm = alpha[t,i]*trans[i,j]*self.mixture(mix[j],O[t+1][:])*beta[t+1,j]
ksai[t,i,j] = c[t]*norm/denom
# 混合输出概率 gama
gama = zeros((T,N,max(self.stateInfo)))
for t in range(T):
pab = zeros((N,1))
for i in range(N):
pab[i] = alpha[t,i]*beta[t,i]
x = O[t][:]
for i in range(N):
prob = zeros((mix[i].CM,1))
for j in range(mix[i].CM):
m = mix[i].Cmean[j][:]
v = mix[i].Cvar[j][:]
prob[j] = mix[i].Cweight[j] * pdf(m,v,x)
if mix[i].Cweight[j] == 0.0:
print pdf(m,v,x)
tmp = pab[i]/pab.sum()
tmp = tmp[0]
temp_sum = prob.sum()
for j in range(mix[i].CM):
gama[t,i,j] = tmp*prob[j]/temp_sum
return c,alpha,beta,ksai,gama
def mixture(self,mix,x):
'''计算输出概率
输入:mix--混合高斯结构
x--输入向量 SIZE*1
输出: prob--输出概率'''
prob = 0.0
for i in range(mix.CM):
m = mix.Cmean[i][:]
v = mix.Cvar[i][:]
w = mix.Cweight[i]
tmp = pdf(m,v,x)
#print tmp
prob = prob + w * tmp #* pdf(m,v,x)
if prob == 0.0:
prob = 2e-100
return prob
#维特比算法
def viterbi(self,hmm,O):
'''%输入:
hmm -- hmm模型
O -- 输入观察序列, N*D, N为帧数,D为向量维数
输出:
prob -- 输出概率
q -- 状态序列
'''
init = copy.deepcopy(hmm.init)
trans = copy.deepcopy(hmm.trans)#hmm.trans
mix = hmm.mix
N = hmm.N
T = shape(O)[0]
#计算Log(init)
n_init = len(init)
for i in range(n_init):
if init[i] <= 0:
init[i] = -inf
else:
init[i]=log(init[i])
#计算log(trans)
m,n = shape(trans)
for i in range(m):
for j in range(n):
if trans[i,j] <=0:
trans[i,j] = -inf
else:
trans[i,j] = log(trans[i,j])
#初始化
delta = zeros((T,N))
fai = zeros((T,N))
q = zeros((T,1))
#t=0
x = O[0][:]
for i in range(N):
delta[0,i] = init[i] + log(self.mixture(mix[i],x))
#t=2:T
for t in range(1,T):
for j in range(N):
tmp = delta[t-1][:]+trans[:][j].T
tmp = tmp.tolist()
delta[t,j] = max(tmp)
fai[t,j] = tmp.index(max(tmp))
x = O[t][:]
delta[t,j] = delta[t,j] + log(self.mixture(mix[j],x))
tmp = delta[T-1][:]
tmp = tmp.tolist()
prob = max(tmp)
q[T-1]=tmp.index(max(tmp))
for t in range(T-2,-1,-1):
q[t] = fai[t+1,int(q[t+1,0])]
return prob
# ----------- 以下是用于测试的程序 ---------- #
#
def vad(self,k,fs):
'''语音信号端点检测程序
k ---语音信号
fs ---采样率
返回语音信号的起始和终止端点'''
k = double(k)
k = multiply(k,1.0/max(abs(k)))
# 计算短时过零率
FrameLen = 240
FrameInc = 80
FrameTemp1 = self.enframe(k[0:-2], FrameLen, FrameInc)
FrameTemp2 = self.enframe(k[1:], FrameLen, FrameInc)
signs = np.sign(multiply(FrameTemp1, FrameTemp2))
signs = map(lambda x:[[i,0] [i>0] for i in x],signs)
signs = map(lambda x:[[i,1] [i<0] for i in x], signs)
diffs = np.sign(abs(FrameTemp1 - FrameTemp2)-0.01)
diffs = map(lambda x:[[i,0] [i<0] for i in x], diffs)
zcr = sum(multiply(signs, diffs),1)
# 计算短时能量
amp = sum(abs(self.enframe(signal.lfilter([1,-0.9375],1,k),FrameLen, FrameInc)),1)
# print '短时能量%f' %amp
# 设置门限
print '设置门限'
ZcrLow = max([round(mean(zcr)*0.1),3])#过零率低门限
ZcrHigh = max([round(max(zcr)*0.1),5])#过零率高门限
AmpLow = min([min(amp)*10,mean(amp)*0.2,max(amp)*0.1])#能量低门限
AmpHigh = max([min(amp)*10,mean(amp)*0.2,max(amp)*0.1])#能量高门限
# 端点检测
MaxSilence = 8 #最长语音间隙时间
MinAudio = 16 #最短语音时间
Status = 0 #状态0:静音段,1:过渡段,2:语音段,3:结束段
HoldTime = 0 #语音持续时间
SilenceTime = 0 #语音间隙时间
print '开始端点检测'
StartPoint = 0
for n in range(len(zcr)):
if Status ==0 or Status == 1:
if amp[n] > AmpHigh or zcr[n] > ZcrHigh:
StartPoint = n - HoldTime
Status = 2
HoldTime = HoldTime + 1
SilenceTime = 0
elif amp[n] > AmpLow or zcr[n] > ZcrLow:
Status = 1
HoldTime = HoldTime + 1
else:
Status = 0
HoldTime = 0
elif Status == 2:
if amp[n] > AmpLow or zcr[n] > ZcrLow:
HoldTime = HoldTime + 1
else:
SilenceTime = SilenceTime + 1
if SilenceTime < MaxSilence:
HoldTime = HoldTime + 1
elif (HoldTime - SilenceTime) < MinAudio:
Status = 0
HoldTime = 0
SilenceTime = 0
else:
Status = 3
elif Status == 3:
break
if Status == 3:
break
HoldTime = HoldTime - SilenceTime
EndPoint = StartPoint + HoldTime
return StartPoint,EndPoint
def recog(self,pathTop):
N = gParam.NUM
for i in range(N):
wavPath = pathTop + str(i) + '.wav'
f = wave.open(wavPath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4]
str_data = f.readframes(nframes)
#print shape(str_data)
f.close()
wave_data = np.fromstring(str_data,dtype=short)/32767.0
x1,x2 = self.vad(wave_data,framerate)
O = self.mfcc([wave_data])
O = O[x1-3:x2-3][:]
print '第%d个词的观察矢量是:%d' %(i,i)
pout = []
for j in range(N):
pout.append(self.viterbi(self.gmm_hmm_model[j],O))
n = pout.index(max(pout))
print '第%d个词,识别是%d' %(i,n)my_hmm.py
import numpy as np
from numpy import *
import gParam
from my_hmm import gmm_hmm
my_gmm_hmm = gmm_hmm()
my_gmm_hmm.loadWav(gParam.TRAIN_DATA_PATH)
#print len(my_gmm_hmm.samples[0])
my_gmm_hmm.hmm_start_train()
my_gmm_hmm.recog(gParam.TEST_DATA_PATH)
#my_gmm_hmm.melbank(24,256,8000,0,0.5,'m')
# my_gmm_hmm.mfcc(range(17280))
#my_gmm_hmm.enframe(range(0,17280),256,80)View Code
提取声音指纹
dejavu的源码地址:https://github.com/worldveil/dejavu
https://www.ctolib.com/dejavu.html
dejavu库是利用python开发的音频指纹提取与识别库,用来实现听歌识曲的功能。Dejavu可以通过听一次来记忆音频,并将其指纹化。然后,通过播放歌曲和录制麦克风输入,Dejavu试图将音频与数据库中保存的指纹进行匹配,返回正在播放的歌曲,
注意:对于语音识别,Dejavu不是合适的工具!Dejavu擅长用合理数量的噪声识别准确的信号。
由于近一段时间正在学习音频分析方面的知识。
古人有云:要想快速掌握知识,就要学会站在巨人的肩膀上。
因此特意研究了一下dejavu的源码。
这篇文章主要是记录学习的过程以及库的核心方法,权当做读书笔记。
关于库的使用方法,本篇不做进一步说明,作者已进行了详细介绍,需要说明的是库的开发者目前已不再维护该库。
前言
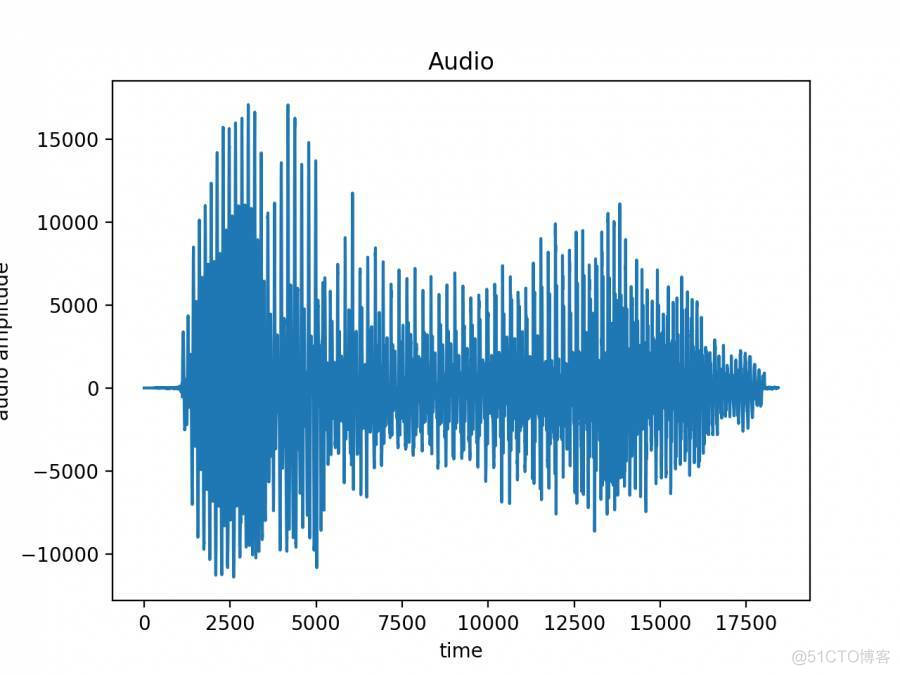
在音频分析中,最简单的是时域分析,音频信号的时域分析是指对声音信号幅值随时间变化曲线进行分析。利用pydub读取“我.mp3”的文件(音频的内容只有一个字为“我”),将其波形画出如下图,横轴为时间,纵轴为音频的幅值。从图中可以看出,在时域内只能分析声音信号的强弱,从波形中很难看出频率的变化,无法对不同的音频信号做出有效的区分。
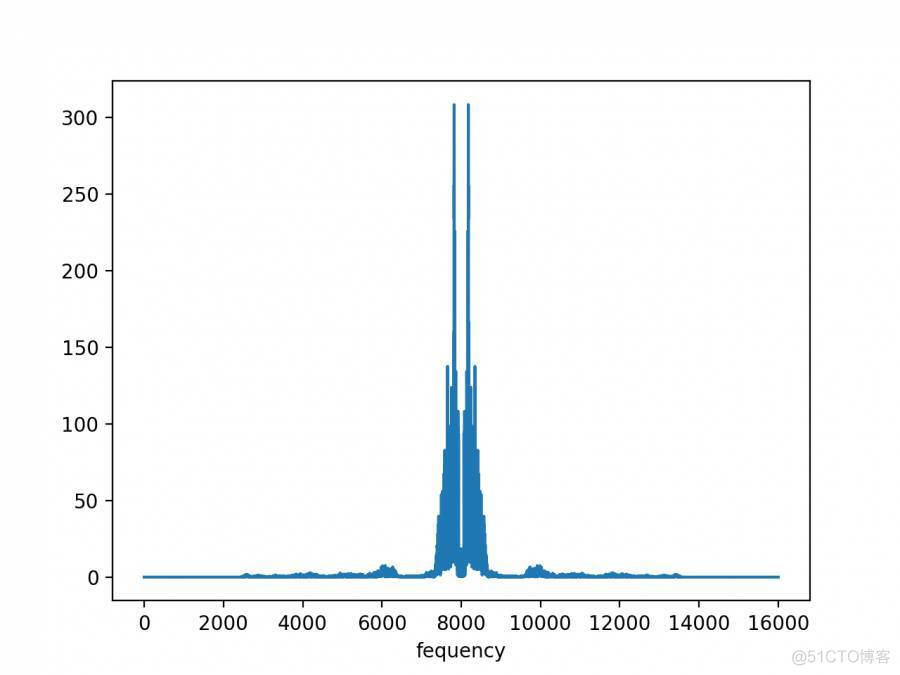
音频信号分析的另外一种方法是频域分析,具体来说就是借助傅里叶变化将原始信号从时域空间转换至频域空间,揭示出构成音频信号的不同频率成分。下图为“我.mp3”文件的频谱图,从中可以看出音频信号的频率分布,这种分析方法可以有效的区分不同的音频文件。但是频谱分析无法反映音频信号的时间信息,只能提供全局的频率信息,不能提供某一时刻的频率信息,只能用于稳态信号的分析,不能用来进行时变信号的分析,单纯的利用频谱分析无法达到听歌识曲的目的。
下面介绍声音的时频分析,获取时频信息最常用的方法是短时傅里叶变换,也是dejavu库所采用的方法。短时傅里叶变换的原理如下,在计算音频文件的频率信息时,不同于频域分析计算整段音频文件的频率信息,短时傅里叶变换方法会对音频文件进行加窗操作,选择一个较短的窗函数对音频信号进行截断,利用快速傅里叶变换计算该窗口内的信号的频率信息,然后移动窗函数,以得到音频文件不同时刻内的频率信息。这样就得到了声音信号不同时刻的频率分布。
dejavu库会读取音频文件,利用时频分析的方法得到不同时刻的频率分布,然后按照一定的算法将音频的指纹信息从音频文件的时频信息中提取出来。通过指纹信息来识别和区分声音文件,每个音频文件都有其单独的指纹库,比对指纹库可以根据声音片段以识别出整个音频文件,以达到听歌识曲的目的。
音频内容的读取
通过fingerprint_file()方法进行音频的读入,该方法返回音频的各个通道的raw_data、frame_rate以及文件的unique_hash(该方法通过获取文件MD5来对文件进行标记,主要是为了后续的文件去重)。在read()方法内引入了两个外部库来进行音频文件的读取,一个是pydub(基于ffmpeg),一个是wavio,这两个库都是用来进行对音频的读取,作者在源码内注释
Reads any file supportedby pydub (ffmpeg) and returns the data contained within.If filereading fails due to input being a 24-bit wav file, wavio is used asa backup.
pydub在读取24位wav文件时可能会出错,因此使用wavio来进行wav文件处理。另外在读取文件时还提供另外一种方法fingerprint_directory()以支持文件的批量读取。
音频指纹提取
首先介绍一下本库所利用的指纹提取的方法,在读取完音频文件之后,会利用短时傅里叶转化对音频文件的各个通道的raw_data进行转换,以获取时频信息,通过指定的算子进行过滤,获取时频信息内突出的点,时频图如下(获取颜色相较周围重的几个点)(该图片取自github)。通过比较获取同一时间上突出点频率最大的峰值点,然后求出每个峰值点及其后面相邻的15个峰值点的时间差,并将相应的峰值点和时间差哈希化,这样就完成音频文件的指纹提取。
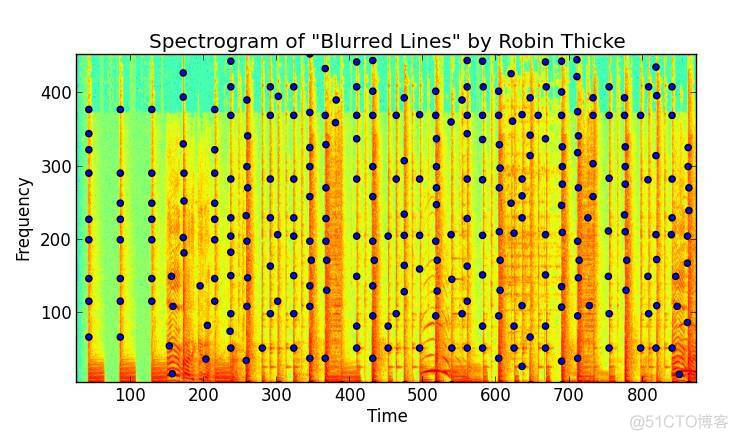
指纹提取的方法在fingerprint内的fingerprint方法内,利用matplotlib内的specgram方法获取频率的信息,之前对于音频分析方面并不太熟悉,通过对这个库的学习算是初识音频分析。下面做一个简要的说明,在第一步内获取了音频的raw_data,这是音频的时间与音频幅度(也就是声音大小)的数值列表,区分声音不同的指标主要是声音的频率,因此为了进行音频指纹的提取,需要获取音频的时间与频率的对应值。使用specgram方法获得的频率是由一个二维列表组成的列表,列表的长度代表着音频的时间长度单位为ms,二维列表内单个列表是各个时间点的频率构成,每个时间点的声音是由多个不同频率的波组合而成。
获取时频信息之后,在fingerprint内的get_2D_peak方法就是对其进行过滤并提取特征值,使用了scipy内的max_filter方法进行频率峰值的筛选,在进行过滤时选择的原始算子如下,中间一行和中间一列全部为true,然后逐次上下递减,呈对称金子塔状。
[0,1, 0]
[1,1, 1]
[0,1, 0]
该库采用的算子长度为41*41,代码如下:
struct= generate_binary_structure( 2, 1)neighborhood= iterate_structure(struct, 20)
获取到所有的突出点之后,通过比较获取同一时间上突出点频率最大的峰值点,下图为“我.mp3”所提取出来的突出点以及峰值点,其中红点为按照上述算子所过滤出来的突出点,蓝点为各个时间点内所提取出来的峰值点,图示如下。
在dejavu库的源码当中,图标显示的方法有一些错误,目前已经pullrequest了,但是项目已经没人维护了,修复见这里(https://github.com/worldveil/dejavu)
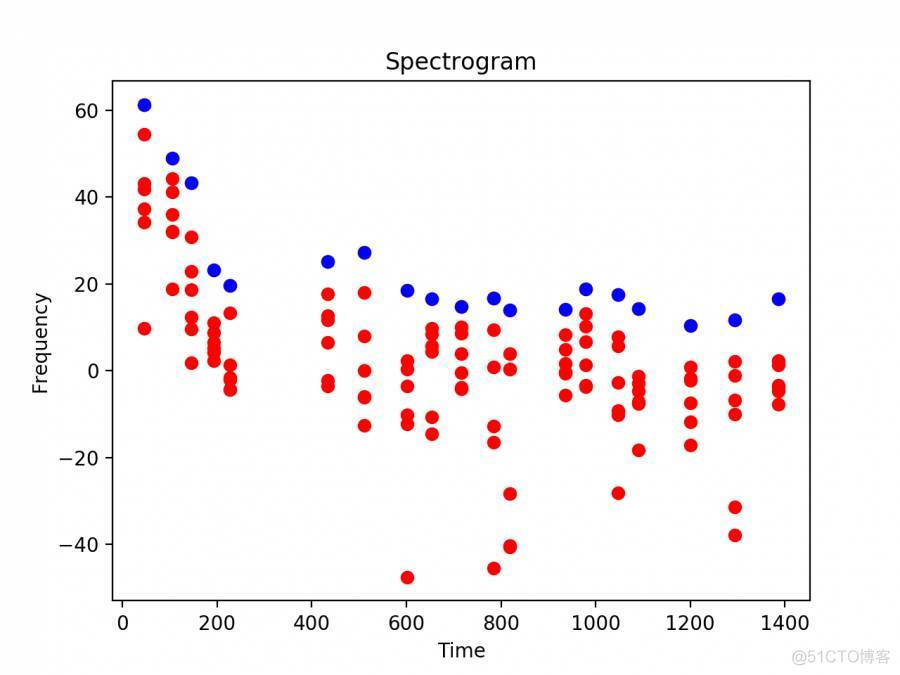
在提取出所有的峰值点后(图中蓝点),计算出和后续相邻的的十五个峰值点的时间差(峰值点的数目可以可以根据自己的需求进行更改),然后利用generate_hashes对相应的峰值点和时间差进行hash化处理。generate_hashes函数如下:
for i in range(len(peaks)): for j in range(1, fan_value): if (i + j) < len(peaks): freq1 = peaks[i][IDX_FREQ_I] freq2 = peaks[i + j][IDX_FREQ_I] t1 = peaks[i][IDX_TIME_J] t2 = peaks[i + j][IDX_TIME_J] t_delta = t2 - t1 if t_delta >= MIN_HASH_TIME_DELTA and t_delta <= MAX_HASH_TIME_DELTA: h = hashlib.sha1( "%s|%s|%s" % (str(freq1), str(freq2), str(t_delta))) yield (h.hexdigest()[0:FINGERPRINT_REDUCTION], t1)
至此,整个音频文件的指纹信息已经提取出来了,在整个提取过程中,最重要的是特征点的提取。在不同的指纹提取方法中,特征点的提取方法也不相同,文章末尾所推荐的parper中有介绍另外的方法,有兴趣的同学可以看看。
存储与比对
指纹提取完毕后,会将提取到的指纹存储至数据库内,默认存储为Mysql,database类为数据库的抽象类,里面定义了必须重写的一些方法,database_sql为具体的实现。这方面不做过多描述。
通过麦克风或者硬盘读取完一段音频文件后,会提取出这段音频文件的所有指纹,然后与数据库内的指纹库进行比对,将匹配成功的音频信息返回。
dejavu的使用
首先,安装dejavu的依赖项。
其次,您需要创建一个MySQL数据库,Dejavu可以在其中存储指纹。例如,在本地设置上:
'''在命令行输入下面两条命令'''
mysql -u root -p #启动并登数据库
Enter password: **********
mysql> CREATE DATABASE IF NOT EXISTS dejavu; #创建dejavu数据库现在你准备开始指纹您的音频收集!
git clone https://github.com/worldveil/dejavu.git ./dejavu
cd dejavu
python example.py首先使用您的配置设置创建一个Dejavu对象(Dejavu使用一个普通的Python字典进行设置)
>>> from dejavu import Dejavu
>>> config = {
... "database": {
... "host": "127.0.0.1",
... "user": "root",
... "passwd": <password above>,
... "db": <name of the database you created above>,
... }
... }
>>> djv = Dejavu(config)接下来,给fingerprint_directory方法三个参数:
- input directory to look for audio files
- audio extensions to look for in the input directory
- number of processes (optional)
>>> djv.fingerprint_directory("va_us_top_40/mp3", [".mp3"], 3)对于大量文件,这将需要一段时间。然而,Dejavu足够强大,您可以在不影响进程的情况下杀死并重新启动它:Dejavu能够记住哪些歌曲是它指纹识别并转换的,哪些歌曲不是,因此不会重复。
一旦它完成一个大文件夹的mp3:,你会有很多指纹。
>>> print djv.db.get_num_fingerprints()
5442376librosa将哼唱旋律转换为音符
import matplotlib.pyplot as plt
import librosa
import librosa.display
import librosa.util
import numpy as np
import pandas as pd
#要转换的输入wav音频文件
input_wav=r"test0.wav"
y,sr=librosa.load(input_wav,sr=None,duration=None)
chroma=librosa.feature.chroma_cqt(y=y, sr=sr)
c=pd.DataFrame(chroma)
c0=(c==1)
c1=c0.astype(int)
labels=np.array(range(1,13))
note_values=labels.dot(c1)
plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=1, hspace=0.2)
plt.subplot(311)
librosa.display.specshow(chroma, y_axis='chroma', x_axis='time')
plt.xlabel('note')
plt.ylabel('beat')
note_values=labels.dot(c1)
plt.subplot(312)
librosa.display.waveplot(y, sr=sr)
plt.xlabel('second')
plt.ylabel('amplitude')
plt.subplot(313)
plt.grid(linewidth=0.5)
plt.xticks(range(0,600,50))
plt.yticks(range(1,13),["C","C#","D","D#","E","F","F#","G","G#","A","A#","B"])
plt.scatter(range(len(note_values)),note_values,marker="s",s=1,color="red")
#plt.show()View Code
import matplotlib.pyplot as plt
import librosa
import librosa.display
import librosa.util
import numpy as np
import pandas as pd
#要转换的输入wav音频文件
input_wav=r"d:\test0.wav"
y,sr=librosa.load(input_wav,sr=None,duration=None)
chroma=librosa.feature.chroma_cqt(y=y, sr=sr)
c=pd.DataFrame(chroma)
c0=(c==1)
c1=c0.astype(int)
labels=np.array(range(1,13))
note_values=labels.dot(c1)
plt.figure(figsize=(20,10))
plt.subplots_adjust(wspace=1, hspace=0.2)
plt.subplot(211)
plt.xlabel('second')
plt.ylabel('amplitude')
librosa.display.waveplot(y, sr=sr,color="#ff9999")
plt.subplot(212)
plt.xlabel('time')
plt.ylabel('notes')
plt.grid(linewidth=0.5,alpha=0.3)
plt.xticks(range(0,600,20))
plt.yticks(range(1,13),["C","C#","D","D#","E","F","F#","G","G#","A","A#","B"])
plt.plot(note_values,color="#008080",linewidth=0.8)
plt.hlines(note_values, range(len(note_values)),np.array(range(len(note_values)))+1 ,color="red", linewidth=10)
plt.show()View Code
案例代码
# -- encoding:utf-8 --
"""
特征处理的相关API
Create by ibf on 2018/8/4
"""
import os
import glob
from pydub import AudioSegment
from python_speech_features import mfcc
import numpy as np
import pandas as pd
from scipy.io import wavfile
music_audio_regex_dir = './data/music/*.mp3'
music_info_csv_file_path = './data/music_info.csv'
music_feature_file_path = './data/music_feature.csv'
music_label_index_file_path = './data/music_index_label.csv'
def extract(file, file_format):
"""
从指定的file文件中提取对应的mfcc特征信息
:param file: 对应的文件夹路径
:param file_format: 文件格式
:return:
"""
result = []
# 1. 如果文件不是wav格式的,那么将其转换为wav格式
is_tmp_file = False
if file_format != 'wav':
try:
# 数据读取
song = AudioSegment.from_file(file, format=file_format)
# 获得输出的文件路径
wav_file_path = file.replace(file_format, 'wav')
# 数据输出
song.export(out_f=wav_file_path, format='wav')
is_tmp_file = True
except Exception as e:
result = []
print("Error:. " + file + " to wav format file throw exception. msg:=", end='')
print(e)
else:
wav_file_path = file
# 2. 进行mfcc数据提取操作
try:
# 读取wav格式数据
(rate, data) = wavfile.read(wav_file_path)
# 提取mfcc特征
mfcc_feat = mfcc(data, rate, numcep=13, nfft=2048)
# 由于file文件对应的音频数据是最原始的音频数据,大小、通道、采样频率等指标都是不一样的,所以说最终mfcc_feat得到的结果大小是不一致的, 一般的格式为: [?, 13]; 也就是说mfcc_feat是一个未知行数,但是列数为13的二维矩阵。
# 这样就导致每个样本(音频数据)的特征信息数目是不一致的,所以需要在这里对这个内容进行处理,让特征维度变的一致
# 解决方案一:使用AudioSegment中的相关API,对音频做一个预处理,让所有音频数据的长度一致、各种特征信息也一致,这样可以保证提取出来的mfcc特征数目一致。
# 解决方案二:在现在的mfcc的指标上,提取出更高层次的特征: 即均值和协方差
# 解决方案二实现代码:
# 1. 矩阵的转置
mm = np.transpose(mfcc_feat)
# 2. 求每行(求13个特征属性中各个特征属性的均值)
mf = np.mean(mm, axis=1)
# 3. 求13个特征属性之间的协方差矩阵,以协方差矩阵作为更高层次的特征
cf = np.cov(mm)
# 4. 将均值和协方差合并
# 最终结果维度: 13 +13 + 12 + 11 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 = 104
result = mf
for i in range(mm.shape[0]):
# 获取协方差矩阵上对角线上的内容,添加到result中
result = np.append(result, np.diag(cf, i))
# 5. 结果返回
return result
except Exception as e:
result = []
print(e)
finally:
# 如果是临时文件,删除临时文件
if is_tmp_file:
os.remove(wav_file_path)
return result
def extract_label():
"""
提取标签数据,返回对的的Dict类型的数据
:return:
"""
# 1. 读取标签数据,得到DataFrame对象
df = pd.read_csv(music_info_csv_file_path)
# 2. 将DataFrame转换为Dict的对象,以name作为key,以tag作为value值
name_label_list = np.array(df).tolist()
name_label_dict = dict(map(lambda t: (t[0].lower(), t[1]), name_label_list))
labels = set(name_label_dict.values())
label_index_dict = dict(zip(labels, np.arange(len(labels))))
# 3. 返回结果
return name_label_dict, label_index_dict
def extract_and_export_all_music_feature_and_label():
"""
提取所有的music的特征属性数据
:return:
"""
# 1. 读取csv文件格式数据得到音乐名称对应的音乐类型所组成的dict类型的数据
name_label_dict, label_index_dict = extract_label()
# 2. 获取所有音频文件对应的路径
music_files = glob.glob(music_audio_regex_dir)
music_files.sort()
# 3. 遍历所有音频文件得到特征数据
flag = True
music_features = np.array([])
for file in music_files:
print("开始处理文件:{}".format(file))
# a. 提取文件名称
music_name_format = file.split("\\")[-1].split("-")[-1].split('.')
music_name = '.'.join(music_name_format[0:-1]).strip().lower()
music_format = music_name_format[-1].strip().lower()
# b. 判断musicname对应的label是否存在,如果存在,那么就获取音频文件对应的mfcc值,如果不存在,那么直接过滤掉
if music_name in name_label_dict:
# c. 获取该文件对应的标签label
label_index = label_index_dict[name_label_dict[music_name]]
# d. 获取音频文件对应的mfcc特征属性,ff是一个一维的数组
ff = extract(file, music_format)
if len(ff) == 0:
continue
# e. 将标签添加到特征属性之后
ff = np.append(ff, label_index)
# b. 将当前音频的信息追加到数组中
if flag:
music_features = ff
flag = False
else:
music_features = np.vstack([music_features, ff])
else:
print("没法处理:" + file + "; 原因:找不到对应的label标签!!!")
# 4. 特征数据存储
label_index_list = []
for label in label_index_dict:
label_index_list.append([label, label_index_dict[label]])
pd.DataFrame(label_index_list).to_csv(music_label_index_file_path, header=None, index=False, encoding='utf-8')
pd.DataFrame(music_features).to_csv(music_feature_file_path, header=None, index=False, encoding='utf-8')
# 5. 直接返回
return music_features
def extract_music_feature(audio_regex_file_path):
"""
提取给定字符串对应的音频数据对应的mfcc格式的特征属性矩阵
:param audio_regex_file_path:
:return:
"""
# 1. 获取文件夹下的所有音乐文件
all_music_files = glob.glob(audio_regex_file_path)
all_music_files.sort()
# 2. 最终返回的mfcc矩阵
flag = True
music_names = np.array([])
music_features = np.array([])
for file in all_music_files:
print("开始处理文件:{}".format(file))
# a. 提取文件名称
music_name_and_format = file.split("\\")[-1].split("-")
music_name_and_format2 = music_name_and_format[-1].split('.')
music_name = '-'.join(music_name_and_format[:-1]) + '-' + '.'.join(music_name_and_format2[:-1])
music_format = music_name_and_format2[-1].strip().lower()
# b. 获取音频文件对应的mfcc特征属性,ff是一个一维的数组
ff = extract(file, music_format)
if len(ff) == 0:
print("提取" + file + "音频文件对应的特征数据出现异常!!!")
continue
# c. 将当前音频的信息追加到数组中
if flag:
music_features = ff
flag = False
else:
music_features = np.vstack([music_features, ff])
# 添加文件名称
music_names = np.append(music_names, music_name)
return music_names, music_features
def fetch_index_2_label_dict(file_path=None):
"""
获取类别id对应类别名称组成的字典对象
:param file_path: 给定文件路径
:return:
"""
# 0. 初始化文件
if file_path is None:
file_path = music_label_index_file_path
# 1. 读取数据
df = pd.read_csv(file_path, encoding='utf-8', header=None)
# 2. 顺序交换形成dict对象
label_index_list = np.array(df)
index_label_dict = dict(map(lambda t: (t[1], t[0]), label_index_list))
# 3. 返回
return index_label_dict
if __name__ == '__main__':
# 1. 提取所有的训练数据
# extract_and_export_all_music_feature_and_label()
# 2. 提取音乐文件对应的mfcc的特征矩阵信息,主要用于模型训练好后的:模型的预测
print("*" * 100)
_, mfcc_features = extract_music_feature('./data/test/*.mp3')
print(mfcc_features)
print(mfcc_features.shape)feature_process.py
# -- encoding:utf-8 --
"""
使用svm算法实现模型构建的相关API
Create by ibf on 2018/8/5
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import pandas as pd
import random
import pymysql
from sqlalchemy import create_engine
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.utils import shuffle
from sklearn.externals import joblib
import feature_process
random.seed(28)
np.random.seed(28)
music_feature_file_path = './data/music_feature.csv'
music_label_index_file_path = './data/music_index_label.csv'
default_model_out_f = './data/music_svm.model'
"""
大概需要些的算法:
1. 模型交叉验证的API,用于模型最优参数的选择
2. 具体的模型训练以及模型保存的API
3. 使用保存好的模型来预测数据,并产生结果的API
"""
def cross_validation(music_feature_csv_file_path=None, data_percentage=0.7):
"""
交叉验证,用于选择模型的最优参数
:param music_feature_csv_file_path: 训练数据的存储文件路径
:param data_percentage: 给定使用多少数据用于模型选择
:return:
"""
# 1. 初始化文件路径
if not music_feature_csv_file_path:
music_feature_csv_file_path = music_feature_file_path
# 2. 读取数据
print("开始读取原始数据:{}".format(music_feature_csv_file_path))
data = pd.read_csv(music_feature_csv_file_path, sep=',', header=None, encoding='utf-8')
# 2. 抽取部分数据用于交叉验证
sample_fact = 0.7
if isinstance(data_percentage, float) and 0 < data_percentage < 1:
sample_fact = data_percentage
data = data.sample(frac=sample_fact, random_state=28)
X = data.T[:-1].T
Y = np.array(data.T[-1:]).reshape(-1)
print(np.shape(X))
print(np.shape(Y))
# 3. 给定交叉验证的参数
parameters = {
'kernel': ['linear', 'rbf', 'poly'],
'C': [0.00001, 0.0001, 0.001, 0.01, 0.1, 1.0, 10.0],
'degree': [2, 3, 4, 5, 6],
'gamma': [0.00001, 0.0001, 0.001, 0.01, 0.1],
'decision_function_shape': ['ovo', 'ovr']
}
# 4. 构建模型并训练
print("开始进行模型参数选择....")
model = GridSearchCV(estimator=SVC(random_state=28), param_grid=parameters, cv=3)
model.fit(X, Y)
# 5. 输出最优的模型参数
print("最优参数:{}".format(model.best_params_))
print("最优的模型Score值:{}".format(model.best_score_))
def fit_dump_model(music_feature_csv_file_path=None, train_percentage=0.7, model_out_f=None, fold=1):
"""
进行fold次模型训练,最终将模型效果最好的那个模型保存到model_out_f文件中
:param music_feature_csv_file_path: 训练数据存在的文件路径
:param train_percentage: 训练数据占比
:param model_out_f: 模型保存文件路径
:param fold: 训练过程中,训练的次数
:return:
NOTE: 因为现在样本数据有点少,所以模型的衡量指标采用训练集和测试集的加权准确率作为衡量指标, eg: source = 0.35 * train_source + 0.65 * test_source
"""
# 1. 变量初始化
if not music_feature_csv_file_path:
music_feature_csv_file_path = music_feature_file_path
if not model_out_f:
model_out_f = default_model_out_f
# 2. 进行数据读取
print("开始读取原始数据:{}".format(music_feature_csv_file_path))
data = pd.read_csv(music_feature_csv_file_path, sep=',', header=None, encoding='utf-8')
# 3. 开始进行循环处理
max_train_source = None
max_test_source = None
max_source = None
best_model = None
flag = True
print(data.shape)
for index in range(1, int(fold) + 1):
# 3.1 开始进行数据的抽取、分割
shuffle_data = shuffle(data).T
X = shuffle_data[:-1].T
Y = np.array(shuffle_data[-1:]).reshape(-1)
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=train_percentage)
# 3.2 模型训练
svm = SVC(kernel='poly', C=1e-5, decision_function_shape='ovo', random_state=28, degree=2)
# svm = SVC(kernel='rbf', C=1.0, gamma=1e-5, decision_function_shape='ovo', random_state=28, degree=2)
# svm = SVC(kernel='poly', C=0.1, decision_function_shape='ovo', random_state=28, degree=3)
svm.fit(x_train, y_train)
# 3.3 获取准确率的值
acc_train = svm.score(x_train, y_train)
acc_test = svm.score(x_test, y_test)
acc = 0.35 * acc_train + 0.65 * acc_test
# 3.4 临时保存最优的模型
if flag:
max_source = acc
max_test_source = acc_test
max_train_source = acc_train
best_model = svm
flag = False
elif max_source < acc:
max_source = acc
max_test_source = acc_test
max_train_source = acc_train
best_model = svm
# 3.5 打印一下日志信息
print("第%d次训练,测试集上准确率为:%.2f, 训练集上准确率为:%.2f,修正的准确率为:%.2f" % (index, acc_test, acc_train, acc))
# 4. 输出最优模型的相关信息
print("最优模型效果:测试集上准确率为:%.2f, 训练集上准确率为:%.2f,修正的准确率为:%.2f" % (max_test_source, max_train_source, max_source))
print("最优模型为:")
print(best_model)
# 5. 模型存储
joblib.dump(best_model, model_out_f)
def fetch_predict_label(X, model_file_path=None, label_index_file_path=None):
"""
获取预测标签名称
:param X: 特征矩阵
:param model_file_path: 模型对象
:param label_index_file_path: 标签id和name的映射文件
:return:
"""
# 1. 初始化相关参数
if not model_file_path:
model_file_path = default_model_out_f
if not label_index_file_path:
label_index_file_path = music_label_index_file_path
# 2. 加载模型
model = joblib.load(model_file_path)
# 3. 加载标签的id和name的映射关系
tag_index_2_name_dict = feature_process.fetch_index_2_label_dict(label_index_file_path)
# 4. 做数据预测
label_index = model.predict(X)
# 5. 获取最终标签值
result = np.array([])
for index in label_index:
result = np.append(result, tag_index_2_name_dict[index])
# 6. 返回标签值
return result
if __name__ == '__main__':
flag = 3
if flag == 1:
"""
模型做一个交叉验证
"""
cross_validation(data_percentage=0.9)
elif flag == 2:
"""
模型训练
"""
fit_dump_model(train_percentage=0.9, fold=100)
elif flag == 3:
"""
直接控制台输出模型预测结果
"""
_, X = feature_process.extract_music_feature('./data/test/*.mp3')
print("X形状:{}".format(X.shape))
label_names = fetch_predict_label(X)
# label_names = fetch_predict_label(X, model_file_path='./data/music_model.pkl',
# label_index_file_path='./data/music_index_label2.csv')
print(label_names)
else:
print("Error")svm_main.py


















