
HDFS 和 yarn都是主从架构 master==>slave
1.DN NM一般部署在同一个机器上 原因是数据本地化
2.大数据生态圈大部分组件都是主从架构,例如hdfs yarn
有些是集群架构 例如 zookeeper kafka
hbase也是主从架构,master regionserver ,但是hbase比较特殊,这个要注意。
HDFS HA架构
官网架构图

NameNode(nn)
就是Master,它是hdfs的管理者,NameNode存储Metadata信息(Name、replicas等)
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块映射信息
- 处理客户端读写请求
DataNode(dn)
就是slave,nn下达命令,dn执行实际操作
- 存储实际的数据块
- 执行数据块的读/写操作
Client
- 文件切分。文件上传HDFS的时候,Client讲文件切分成一个个Block,然后进行上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS,比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删改查
Secnodary NameNode
SNN并非NameNode的热备。当NN挂掉的时候,它并不能马上替换NameNode并提供服务
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NN
- 在紧急情况下,可辅助恢复NN
个人梳理完整流程
客户端请求会先请求到命名空间,注意命名空间不是进程,只是一个参数化的配置。
命名空间会去找 active状态的name node

HA使用active NN,standby NN两个节点解决单点问题。两个NN节点通过我们JN集群共享状态,通过ZKFC选举谁是active,监控状态自动备援。DN会同时向两个节点发送心跳。
各组件说明
active namenode
接收client的rpc请求并处理,同时自己editlog写一份,也向JN的共享存储上的editlog写一份。
也同时接收DN的block report,block location updates 和 heartbeat
standby namenode
standby nn 会进行重演,这样能够保证和active 状态的name node 的源数据保持一致。
同样会接受到从JN的editlog上读取并执行这些log操作,使自己的NN的元数据和activenn的元数据是同步的,
所以说standby是active nn的一个热备。一旦切换为active状态,就能够立即马上对外提供NN角色的服务。
也同时接收DN的block report,block location updates 和 heartbeat
jn
用于active nn,standby nn的同步数据,本身由一组的JN节点组成的集群,奇数,3台(CDH),是支持Paxos协议。
保证高可用。
ZKFC
监控NN的健康状态
向ZK集群定期发送心跳 ,让自己被选举,当自己被ZK选举为主时,zkfc进程通过rpc调用让nn转换为active状态
Yarn HA
官网yarn架构图
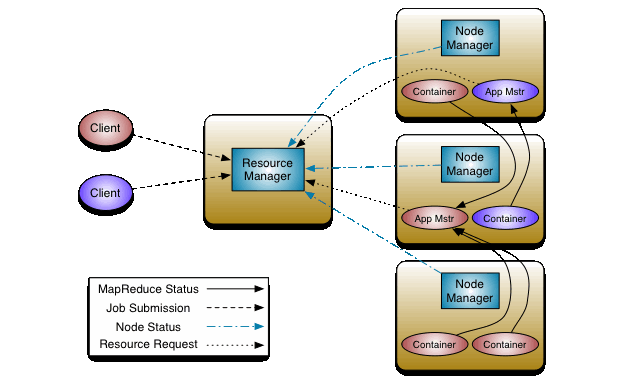
ResourceManager(RM)
- 处理客户端请求
- 监控NodeManager
- 启动或监控ApplicationMaster(管理集群上运行的job)
- 资源的分配与调度
NodeManager(NM)
- 管理单个节点上的资源
- 处理来自于ResourceManager的命令
- 处理来自ApplicationMaster的命令
ApplicationMaster(AM)
- 负责数据的切分
- 为应用程序申请资源并分配给内部任务
- 任务的监控与容错
Container
- Container是YARN中的资源抽象,他封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等
个人整理完整架构图

各组件说明
ResourceManager(RM)
1.启动时会向ZK的/hadoop-ha目录写一个lock文件,写成功则为active,否则为standby。standby RM会一直监控lock文件是否存在,如果不存在就会尝试去创建,争取为active RM。
2.会接收客户端的任务请求,接收和监听NM的资源的汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
NodeManager(NM)
节点上的资源的管理,启动container容器运行task的计算,上报资源,container情况汇报给RM,任务的处理情况汇报给作业的ApplicationMaster(AM)
ApplicationMaster(AM)(driver):NM机器上的container
单个application(job)的task的管理和调度,并向RM进行资源的申请,向NM发出container指令,接收NM的task的处理状态信息。
RMStatestore
1.RM的作业信息存储在ZK的/rmstore下,active RM向这个目录写app信息;
2.当active RM挂了,另外一个standby RM成功转化为active RM后,会从/rmstrore目录读取相应的作业信息,重新构建作业的内存信息。然后启动内部服务,开始接收NM的心跳,构建集群资源的信息,并接收客户端的提交作业的请求等。
active rm挂了的瞬间是不能提供服务,因为新起来的节点会从zk读信息
注意NM心跳信息只向active状态的rm发送心跳
ZKFC
自动故障转移,只作为RM进程的一个线程,而非独立的守护进程来启动。
HDFS 和 yarn 区别
ZKFC的区别
yarn ZKFC 在RM中,它是线程
HDFS ZKFC是进程
存储的区别
HDFS有独立的存储进行,yarn会把数据存在zookeeper里


















