
目录
引言
一、glob —— os 库的平替,主打一行代码解决问题
二、time —— 时间处理库
(1)time.time() —— 获取当前时间戳
(2)time.sleep(x) —— 程序休眠函数
(3)time.gmtime(t) —— 获取时间戳 t 对应的 struct_time 对象。
(4)time.ctime() —— 获取当地时间。
(5)使用 mktime(),strftime() 和 strptime() 进行时间格式化
三、copy —— 试错神器(数据处理后悔药)
四、json —— 字典存储库
五、tqdm —— 循环进度条,免除等待焦虑
六、shutil —— 文件复制/粘贴/剪切/重命名
七、pprint —— 层次化输出库
总结
其他内容
Python教学
文本识别类
数据可视化
引言
在上期文章中,我们介绍了 Python 中进行文件/目录操作、路径处理的操作系统库 os,了解了 os 库在数据处理中的实用性。在 Python 中,操作系统库 os 和正则表达式库 re 是标准库中的重难点,除了这两个标准库,在数据处理中,还有不少小众但好用的标准库,这些标准库也能在数据处理中发挥大作用,下面我们为大家一一介绍。
一、glob —— os 库的平替,主打一行代码解决问题
在上一期介绍 Python 标准库 os 的文章中>>>最常用的标准库之一 —— os,我们向大家介绍了使用 os 库一次性获取指定类型文件路径的方法(使用os.walk())。该方法虽然在数据处理中十分常用,但是相应代码的书写难度并不算低,可读性也不高。单纯就批量获取文件路径这件事来说,Python 标准库 glob的易学易用性绝对要领先 os 库。事实上,使用glob模块在多数情况下只需要编写一行代码就可以一次性获取我们需要的文件路径。下面我们来简单介绍glob模块的使用方法。
glob 库中最重要且常用的一个函数是glob(),其作用是返回一个包含所有符合规则的文件路径的列表。例如我们想要获取当前工作目录中名为“已分享的资源”文件夹下所有的 pdf 文件的路径(不含子文件夹下的文件),可以使用下面的代码。
import glob # 这一行不算 :)
glob.glob('./已分享的资源/*.pdf')所得结果如下图所示。

在上面的代码中,我们将路径表达式'./已分享的资源/*.pdf'传入glob.glob()函数就得到了想要的结果。其中各部分的含义如下:
./:Python 当前工作路径,那么./已分享的资源/表示的就是当前工作路径下“已分享的资源”这一文件夹。*.pdf:用于匹配所有任意名称,但文件扩展名为 .pdf 的文件(pdf 文件的扩展名就是 .pdf)的路径。星号*是glob.glob()函数中的一种通配符,可以匹配零到多个任意字符。那么*.pdf则表示任意名称的 pdf 文件。
理解了上面这句代码之后,下面我们就可以探索glob.glob()函数更新奇的玩法了。比如我想获取“已分享的资源”文件夹下文件名中包含“报告”两个字的 pdf 文件,可以使用下面的代码。
glob.glob('./已分享的资源/*报告*.pdf')如果需要匹配所有文件名称中包含“报告”二字的任意类型的文件,可以使用下面的代码。
glob.glob('./已分享的资源/*报告*.*') # 使用通配符 * 匹配文件扩展名以上几种方式虽然能够一次性获取所有指定的文件路径,但都局限于一级文件夹下的文件(不包含子文件夹下的文件)。如果想要获取某个文件夹及其所有子文件夹下符合规则的文件路径,同样可以使用glob.glob()函数,但是需要借助一个参数来实现。例如获取“已分享的资源”文件夹及其所有子文件夹下所有扩展名为 .zip 的文件时,可以使用以下代码。
glob.glob('./已分享的资源/**/*.zip', recursive=True)相较于只获取一级目录下文件路径的代码,上述代码有两点变化:一是使用通配符**匹配零到多级子文件夹的名称;二是通过设置参数recursive为 True,来让glob()函数递归地获取更深层级子文件夹下的文件。
除了*和**之外,glob()函数还支持其他通配符。常用的通配符及其含义如下表所示。
通配符 | 含义 |
* | 匹配 0 个或多个任意字符 |
** | 匹配任意名称的目录或子目录 |
? | 匹配 1 个任意字符 |
[] | 匹配指定范围内的字符,如 [0-9] 匹配数字,[a-z] 匹配小写字母 |
最后,标题中所说的 os 库平替的说法其实是十分激进的,因为 os 的作用不仅仅是获取文件路径,而glob库才是只能获取文件路径的标准库。而且glob库是由os库二次开发而来的。
二、time —— 时间处理库
time库是 Python 提供的精确的时间标准库,可以用于分析程序性能,也可以让程序暂停一段时间。time 库采用的是“格林威治时间”,即从 1970 年 01 月 01 日 00 时 00 分 00 秒起到现在的总秒数,time 库的主要功能体现在 3 个方面:时间处理,时间格式和计时。下面将介绍几个 time 库中常用的方法。
(1)time.time() —— 获取当前时间戳
import time # 导入 time 库
time.time() # 获取当前时间戳,即从 1970 年 01 月 01 日 00 时 00 分 00 秒起到现在的总秒数
# 1680775605.486971我们可以在程序开始和结束分别获取时间戳,程序结束后计算两者的差即可知道程序的运行时间。
(2)time.sleep(x) —— 程序休眠函数
time.sleep()函数接受一个数字参数,传入的数字表示程序休眠的秒数。例如程序执行到time.sleep(5)时就会休眠 5 秒钟,期间什么都不做。time.sleep()函数看似鸡肋,实际上这个函数具有重要意义。比如在数据采集中,不停地使用网络可能会让计算机或者服务器崩溃,使用time.sleep()函数就可以控制程序执行频率;又如,当使用多进程向数据库写入数据时,多个进程同时执行建表操作,可能引发数据库报错,所以在第一个进程启动后让程序休眠几秒钟,等待第一个进程建表完成后,再启动其他进程。以上这些例子都表示time.sleep()这个函数具有十分重要的意义。
网络上曾流传一个关于
sleep()函数的笑话/梗,乙方公司某程序员故意在开发的软件中加入了sleep()语句,交付给甲方后,甲方发现软件运行效率非常低,于是花钱请乙方优化软件,提升运行效率。乙方将源代码中sleep()函数的数字调小,在几周后重新交给甲方,并声称花费了巨大精力,甲方测试后发现软件果然变快了,大喜之余仍觉得还不够快,于是又找乙方优化……几番下来乙方已经赚的合不拢嘴!
(3)time.gmtime(t) —— 获取时间戳 t 对应的 struct_time 对象。
time.gmtime()
# 得到:
# time.struct_time(tm_year=2023, tm_mon=4, tm_mday=6,
# tm_hour=10, tm_min=31, tm_sec=35, tm_wday=3, tm_yday=96, tm_isdst=0)struct_time 对象的元素构成如下表所示。
元素 | 含义及范围 |
tm_year | 年份,整数 |
tm_mon | 月份 [1,12] |
tm_mday | 日期 [1,31] |
tm_hour | 时 [0,23] |
tm_min | 分 [0,59] |
tm_sec | 秒 [0,59] |
tm_wday | 星期 [0,6],0 表示周一 |
tm_yday | 该年的第几天 |
tm_isdst | 是否夏令时,0 表示否,1 表示是,-1表示为止 |
(4)time.ctime() —— 获取当地时间。
time.ctime()
# 得到: 'Thu Apr 6 18:36:23 2023'(5)使用 mktime(),strftime() 和 strptime() 进行时间格式化
time 库使用 mktime() 和 strftime() 函数进行时间格式化。使用 mktime(t) 将 struct_time 对象解析为格林威治时间戳。
使用time.mktime()函数将当前时间的 struct_time 对象转为格林威治时间戳的代码如下。
time.mktime(time.gmtime())
# 得到:1680748762.0使用time.strftime()函数将 struct_time 转为中文时间对象的代码如下。
t = time.gmtime()
time.strftime('%Y-%m-%d %H:%M:%S', t)
# 得到: '2023-04-06 10:49:19'strftime() 函数常用的的格式化控制符如下表所示。
格式化控制符 | 描述 |
%Y | 四位数年份 |
%y | 两位数年份 |
%m | 月份 |
%W | 一年中的星期数(00 ~ 53),以星期天为一个星期的开始 |
%U | 一年中的星期数(00 ~ 53),以星期一为一个星期的开始 |
%w | 星期数(0 ~ 6),0表示星期天 |
%j | 一年中的第几天 |
%d | 日期 |
%p | 上/下午,AM/PM |
%H | 24 小时制的小时(00 ~ 24) |
%I | 12 小时制的小时(00 ~ 12) |
%M | 分钟 |
%S | 秒 |
%X | 本地相应时间表示 |
%x | 本地相应日期表示 |
%Z | 当前时区名称 |
%% | % 本身 |
三、copy —— 试错神器(数据处理后悔药)
在数据处理过程中,当我们不确定一个操作带来的结果是否符合预期时,可以先对数据进行尝试性的操作。一般来说,合适的做法是复制一个待处理文件的副本,让这个副本文件去“赴汤蹈火”,若程序运行结果没有达到期望或中途报错,那么原始的数据依然完好,不需要再去尝试挽救或者重新生成数据。
这种思维是没有问题的,不过不少初学者由于不了解 Python 的内存机制,在这方面吃了亏。比如某同学在处理数据中花费了一个小时得到半成品,变量名为data,再进行最后一步处理就可以得到结果了,但由于最后一步会直接修改变量 data 的内容。于是这位同学想通过以下语句来复制出一个副本,然后使用副本去试错。
data_test = data如果真的使用了上述方式去复制变量,那么就跳入了内存机制的坑。因为这种“复制”方式基本与复制无关,这仅仅是给变量data起了个别名而已,如果data_test发生变化,data也会跟着改变。
如果需要生成一个完全独立于对象data,但与data一模一样的对象data_test,我们可以使用 Python 标准库copy。介绍它之前,我们需要先了解 Python 中的两种复制方式——浅复制与深复制(也称浅拷贝、深拷贝)。

💡浅复制(Shallow Copy)是指创建一个新的对象,这个新对象与被复制的对象共享内存空间中的一部分数据(主要是不可变类型数据),也就是说这两个对象的部分属性/元素会一致地更新。
深复制(Deep Copy)是指创建一个新的对象,这个新对象中完全不共享内存空间中的数据,也就是说这个新对象与被复制的对象完全独立。
什么意思呢?通俗来说,使用浅复制可以大大节省内存,但是浅复制得到的副本仍与原始数据藕断丝连,同穿一条裤子,修改其中之一,另一个可能也会发生变化。为什么是可能变化,而不是必然呢?这与你修改的对象的类型有关。而深复制则不会出现以上问题,深复制得到的对象完全独立于原始对象,不过使用的内存空间也大了不少(具体大多少视数据情况而定)。所以在上面的场景中,一定要使用深复制来创建数据副本。
使用copy库对变量 data 进行浅复制和深复制的代码如下。
import copy # 导入模块
data_test = copy.copy(data) # 浅复制
data_test = copy.deepcopy(data) # 深复制四、json —— 字典存储库
JSON (JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。是一种文本格式,具有良好的可读性和易于扩展的特点。事实上,JSON 对象与 Python 中的字典非常相似,他们能够存储具有映射关系的数据类型。JSON 对象长什么样子呢?我们通过一个例子来了解一下。在使用高德地图地理编码 API 获取某地址的相关信息时,API 的返回值就是一个 JSON 对象,如下图所示。

标准库json就是一个处理 JSON 对象的库。那么这个库能给我们带来什么帮助呢?除了能够处理一般的 JSON 文件和 JSON 字符串,我们还可以使用 json 库将 Python 字典写入 JSON 文件,极大程度上方便传输和使用,再次使用时直接读取即可使用,不需要花费精力再去生成。
json 库提供了四个函数,我们使用较多的是json.dump()和json.load()这两个函数,前者用于将 Python 字典对象写入 json 文件;后者用于将 json 文件读取为 Python 字典。例如我们通过处理全国行政区划数据得到了省份名称与下辖县级名称的对照字典,如下图所示。

为了方便下次使用,我们需要将这个字典写入文件中,使用的代码如下。
with open('Province_county.json', 'w', encoding='utf-8') as f:
json.dump(DICT, f) # DICT 就是清理得到的字典写入文件后,我们以文本方式打开它,所得结果如下图所示。

根据上图可知,中文无法在 json 文件中正常显示,一眼望去,全是 Unicode 编码。这是因为json.dump()函数默认会对非ASCII字符进行转义,如果我们希望 json 格式中的中文可以正常显示时,可以设置函数的参数ensure_ascii=False,且在写入文件时指定open()函数的编码参数encoding='utf-8'或encoding='utf-8-sig'来让中文正常显示。同时还可以设置参数indent=4来让 json 文件的层级更加明显。
改进后的写入代码如下。
with open('Province_county.json', 'w', encoding='utf-8') as f:
json.dump(DICT, f, ensure_ascii=False, indent=4) # DICT 就是清理得到的字典
下次再想使用该字典时,可以使用以下代码来将 json 文件读取为 Python 字典。
with open('Province_county.json', 'r', encoding='utf-8') as f:
DICT = json.load(f)五、tqdm —— 循环进度条,免除等待焦虑
在数据处理过程中我们时常面临一个情况,就是我们不清楚编写的循环代码的效率,也无法得到程序当前运行的进度,这使得我们只能盲目地等待程序运行结束,而无法预估其需要运行的时间,这种情况就可以使用tqdm()函数来帮助我们掌握程序的运行情况。Python 标准库中的 tqdm 库也称为进度条库,它可以为 for 循环提供一个进度条以显示数据处理的进度信息,尤其在批量处理数据的场景中,tqdm 库帮助我们更好地了解程序的运行状态。
现在我们想要使用 for 循环遍历并处理一张表格中的所有数据行,该表格的数据量有三十余万条,我们需要通过tqdm()函数查看程序当前的处理进度,同时得到预估的程序运行总时长。示例如下。
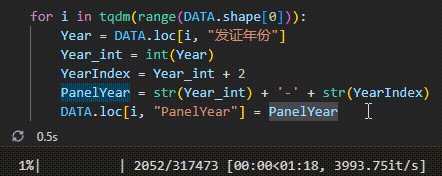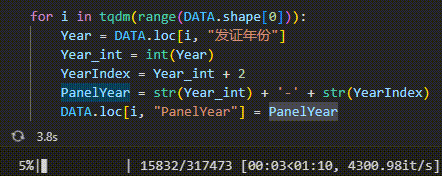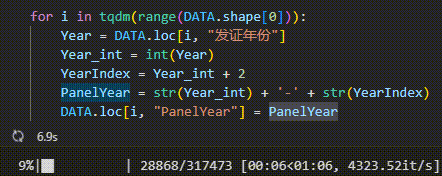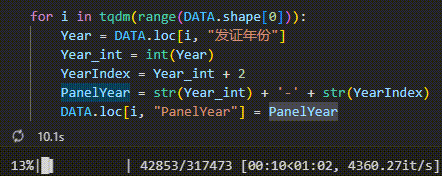
上图呈现了使用tqdm()函数的进度条效果,随着程序的运行,进度条的长度和百分比不断更新以显示当前处理进度,当已知循环体的长度时,进度条右边的文本显示的是已经处理的数据量/需要处理的数据总量,括号中的xxxit/s表示处理速度,左边的时间表示程序已经运行的时间,右边的时间表示预估的剩余用时。由于我们 for 循环每次得到一行数据,所以上图表示的是每秒执行的循环次数。当循环体长度未知时,进度显示的是已循环的次数以及每秒钟执行的循环次数,如下图所示。

六、shutil —— 文件复制/粘贴/剪切/重命名
在数据处理过程中对文件和目录的操作是必不可少的,Python 为了更方便开发者使用程序操作文件或目录,也提供了一些好用的标准库,除了上期文章介绍的 os 库,我们还要介绍一个操作文件/目录的库——shutil,这个库可以作为 os 库的补充,用于对文件或目录进行复制、移动、删除、重命名等操作,我们将shutil库中常用于数据处理的函数按照功能分为两类:复制类、删除/移动类,具体如下表所示。
函数 | 功能描述 |
| 复制文件,参数 src 表示源文件,参数 dst 表示目标文件夹 |
| 复制文件夹,参数 src 表示原文件夹,参数 dst 表示目标文件夹 |
| 移动文件或文件夹,参数 src 表示源文件/文件夹,参数 dst 表示目标文件夹 |
| 删除文件夹,参数 src 表示源文件夹 |
在数据处理工作中常常会遇到一个场景——当我们对一个文件夹中的文件进行处理后,需要将该文件夹中符合我们要求的所有文件移动到指定目录中,比如我们想要找到中国环境统计年鉴(1999-2017)文件夹中,文件名含有关键字“2011”的所有文件,并将这些文件移动到2011年中国环境统计年鉴文件夹中,该文件夹当前不存在。

dir_path = r'./中国环境统计年鉴/中国环境统计年鉴(1999-2017)/'
# 需要存放文件的目录,使用so.mkdir()创建该文件夹
dst_path = r'./中国环境统计年鉴/2011年中国环境统计年鉴'
os.mkdir(dst_path)
# 得到指定文件夹所有文件路径的列表
all_files = os.listdir(dir_path)
# 遍历文件夹中每一个文件
for file in all_files:
# 拼接一个文件的路径,得到该文件的绝对路径
file_path = os.path.join(dir, file)
# 使用os.path.basename()函数获取文件名,判断这个文件的文件名是否含有关键字“2011”
if '2011' in os.path.basename(file_path):
# 将含有关键字“2011”的文件转移到指定目录中
shutil.move(file_path, dst_path)
可以看到,名称中含有关键字“2011”的文件均已移动到指定文件夹中,源文件已不在原始文件夹中。在使用shutil.move(src, dst)函数时需要注意一点,参数 dst 表示的目标目录必须是存在的,我们在上面的程序中使用os.mkdir()函数先创建了该目录。
实际中还有另一种常见情况是需要将文件移动到新文件夹下,并且源文件仍然保留在原始文件夹中用来备份,这就可以使用shutil.copy(src, dst)函数来实现,也就是将上面程序中的shutil.move(file_path, dst_path)改为如下语句。
# 将file_path表示的源文件转移至指定目录dst_path中
shutil.copy(file_path, dst_path)最后介绍一下shutil.rmtree(src)函数,该函数的功能区别于 os 库中的remove()和rmdir()函数,其可以递归地彻底删除参数 src 表示的文件夹,无论其是否非空,所以在使用的时候要谨慎一点!
七、pprint —— 层次化输出库
最后我们介绍一个非常简单又很有用的库——pprint库,从库名就可以看出pprint库一定和print()函数有关系,没错,这个库是用于将数据打印输出到控制台中的,但是该库提供的函数和print()函数的打印方式不同,print()函数尽可能地将打印结果都输出在一行,对于结构较为复杂的数据,这种输出方式不便于阅读,而pprint库中的pprint()函数采用分行打印,在输出过程中会自动添加缩进并且自动断行,使得打印的数据结构更加清晰明了。下面我们用两种方式打印输出一个字典形式的数据,直观感受一下两者的区别。


这就是两种打印方式的不同,对于比较复杂的数据结构,直接使用print库可能会让结果像一堆字母炸弹,这时pprint库就像一个魔法师一样,让打印输出的结果变得简洁美观!
总结
本文向大家介绍了 Python 数据处理中七个实用的标准库,比如当我们在程序中需要处理文件/目录时,glob库和shutil库就是非常好用的工具,再加上上期文章介绍的os库,让 Python 数据处理中关于文件/目录的操作基本不在话下;或者是当不知道循环程序多久才能运行结束,苦苦等待的时候,想到tqdm库。本期文章的目的就是希望这些工具可以帮助大家优化程序。


















