
1. 准确率,召回率,F1值
首先介绍三种最常用的无序的评价指标,它们适用于一种相对简单的情况:在搜索结果中仅考虑返回的文档是否与查询相关,而不考虑这些返回文档在结果列表中的相对位置和顺序。
准确率(Precision)是返回的结果中相关文档所占的比例
召回率(Recall)是返回的相关文档占所有相关文档的比例
具体可以根据混淆矩阵来理解
| 相关 | 不相关 |
返回 | 真正例(tp) | 伪正例(fp) |
未返回 | 伪反例(fn) | 真反例(tn) |
已知上述矩阵,那么准确率和召回率可以按如下方法计算:
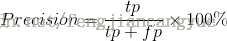
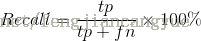
举个例子,假设针对某个查询词,某搜索引擎返回10个结果,其中有5个是相关的,那么准确率就等于5/10 = 50%, 如果索引中与该查询词相关的文档共有8个(也就是说还有3个没有返回),那么召回率就等于5/8 = 67.5%.
通常而言,一个好的搜索引擎需要兼顾准确率(P)和召回率(R),因此有了结合两者的指标—— F值,它是准确率和召回率的调和平均值,定义如下:
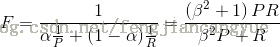
其中,
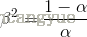
,
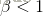
表示强调正确率,而
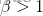
表示强调召回率。当

时,表示准确率和召回率的权重相等,通常记为
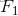
,此时F值的计算公式可以简化为
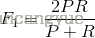
这里为什么使用调和平均而不是算术平均来计算F值呢?考虑极端的情况,如果搜索结果返回所有的文档,那么此时召回率就是100%,这时的F值至少为50%,这显然是不合理的。而调和平均值小于等于算术平均值和几何平均值,如果两个求平均的数之间差距比较大,那么调和平均值更接近其中较小的值。
2. MAP
准确率,召回率和F值都是利用无序的文当集合进行计算,而搜索引擎返回的结果通常是有序的,因此有必要对这些指标进行扩展以考虑位置信息。
MAP(Mean Average Precision)是近年来比较流行的评价指标, MAP在准确率的基础上考虑了位置的因素。
首先对于单个查询,其平均准确率的具体计算方法如下:

其中r是相关文档的总数,Q是查询总数。
查询集合的平均准确率由所有单个查询的MAP值的平均。
总的来说,系统检索出来的相关文档在列表中越靠前,MAP的值就越高。如果系统没有返回相关文档,则MAP=0.
3.NDCG
NDCG(normalized discounted cumulative gain,归一化折损累计增益)是一种近年来逐渐被采用的指标,尤其是在基于机器学习的排序方法中。NDCG是针对连续值的指标,它基于前k个检索结果进行计算。设R(j,d)是评价人员给出的文档d对查询j的相关性得分(通常是一个概率),那么有:
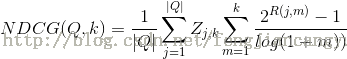
其中,用于保证对于查询j最完美系统的NDCG在k的位置得分是1,m是返回文档的位置。
如果某查询返回的文档数
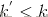
,,那么上述公式只需要计算到k‘为止。




















