
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.

本文是深度学习应用于图像分割的代表作,作为Oral发表于CVPR 2015,在许多教程中都被推荐(例如Li Feifei在Standford的视觉识别CNN)。第二作者Evan Shelhamer也是Caffe的首席开发者。 本文在图像分割问题中应用了当下CNN的几种最新思潮,在PASCAL VOC分割任务上IU(交比并)达到62.2%,速度达到5fps。提供了基于Caffe的模型和测试python代码。
辨:两种分割任务 semantic segmentation - 只标记语义。下图中。 instance segmentation - 标记实例和语义。下图右。 本文研究第一种:语义分割

核心思想
本文包含了当下CNN的三个思潮 - 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。 - 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。 - 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
网络结构
网络结构如下。输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21。

全卷积-提取特征
虚线上半部分为全卷积网络。(蓝:卷积,绿:max pooling)。对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。 这部分由深度学习分类问题中经典网络AlexNet1修改而来。只不过,把最后两个全连接层(fc)改成了卷积层。
论文中,达到最高精度的分类网络是VGG16,但提供的模型基于AlexNet。此处使用AlexNet便于绘图。
逐像素预测
虚线下半部分中,分别从卷积网络的不同阶段,以卷积层(蓝色×3)预测深度为21的分类结果。
例:第一个预测模块 输入16*16*4096,卷积模板尺寸1*1,输出16*16*21。 相当于对每个像素施加一个全连接层,从4096维特征,预测21类结果。
反卷积-升采样
下半部分,反卷积层(橙色×3)可以把输入数据尺寸放大。和卷积层一样,升采样的具体参数经过训练确定。
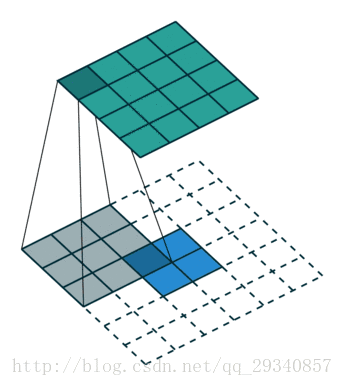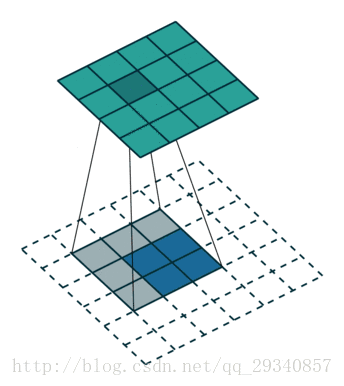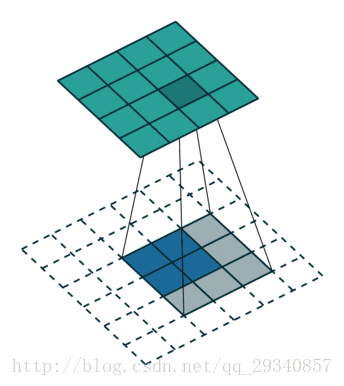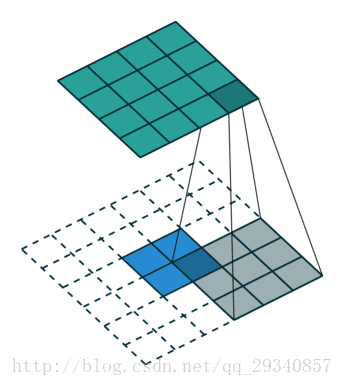
例:反卷积2
输入:每个像素值等于filter的权重
输出:步长为stride,截取的宽度为pad。
输入:2*2
计算过程:2+2*2-3+1
输出:4
VGG16不同层卷积提取出来后经过反卷积与上采样得到的图片。


跳级结构
下半部分,使用逐数据相加(黄色×2),把三个不同深度的预测结果进行融合:较浅的结果更为精细,较深的结果更为鲁棒。 在融合之前,使用裁剪层(灰色×2)统一两者大小。最后裁剪成和输入相同尺寸输出。
训练
训练过程分为四个阶段,也体现了作者的设计思路,值得研究。
第1阶段

以经典的分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
第2阶段

从特征小图(16*16*4096)预测分割小图(16*16*21),之后直接升采样为大图。
反卷积(橙色)的步长为32,这个网络称为FCN-32s。
这一阶段使用单GPU训练约需3天。
第3阶段

升采样分为两次完成(橙色×2)。
在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
第二次反卷积步长为16,这个网络称为FCN-16s。
这一阶段使用单GPU训练约需1天。
第4阶段

升采样分为三次完成(橙色×3)。
进一步融合了第3个pooling层的预测结果。
第三次反卷积步长为8,记为FCN-8s。
这一阶段使用单GPU训练约需1天。较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果。

其他参数
minibatch:20张图片 learning rate:0.001 初始化: 分类网络之外的卷积层参数初始化为0。 反卷积参数初始化为bilinear插值。最后一层反卷积固定位bilinear插值不做学习。
结论
总体来说,本文的逻辑如下: - 想要精确预测每个像素的分割结果 - 必须经历从大到小,再从小到大的两个过程 - 在升采样过程中,分阶段增大比一步到位效果更好 - 在升采样的每个阶段,使用降采样对应层的特征进行辅助
类似思想在后续许多论文中都有应用,例如用于姿态分析的3。


















