
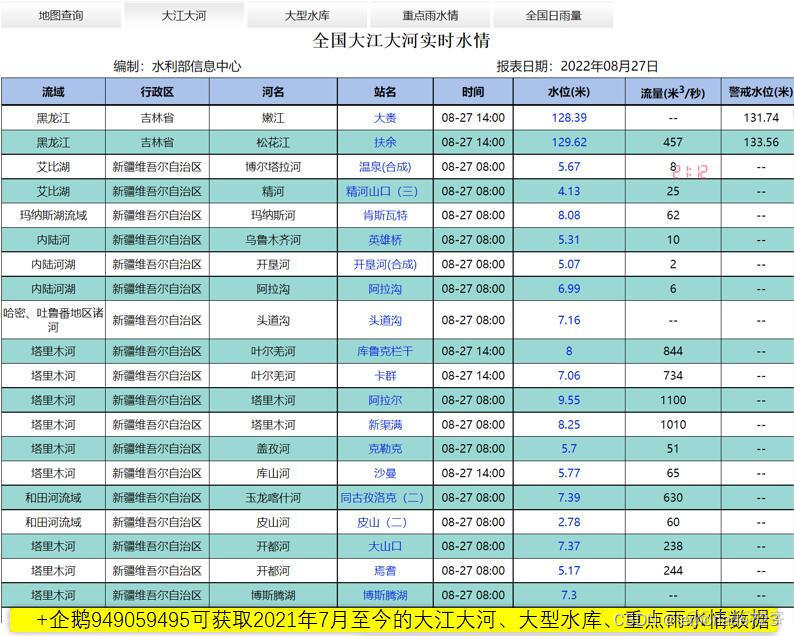
水利部信息中心的全国水雨情网站(全国水雨情信息)提供了部分江河和水库的日水位和和日流量数据,可通过Python进行提取(由于是实时发布,仅能提取当天及之后的数据,获取之前数据可见下图)。
2023年8月29日更新:
可使用windows计划任务进行自动提取(省去打开Pycharm)参考链接:
python 任务队列 python 任务计划_mob6454cc6caa80的技术博客_51CTO博客
2022年8月27日更新:
加入了自动提取和全国重点站实时雨情,三种数据并保存在一个代码中,但若使用自动提取,Pycharm会固定占用30%左右的CPU和1G左右的内存,如果是主力机还是建议取消自动,到晚上手动提取,防止占用过多电脑资源。
import requests
import pandas as pd
import os
import time
#每天定时运行代码爬取
while True:
current_time = time.localtime(time.time())
if ((current_time.tm_hour == 23) and (current_time.tm_min == 30) and (current_time.tm_sec == 0)):
# 存储中英文对应的变量的中文名
word_dict = {"poiAddv": "行政区",
"poiBsnm": "流域",
"ql": "流量(立方米/秒)",
"rvnm": "河名",
"stcd": "站点代码",
"stnm": "站名",
"tm": "时间",
"webStlc": "站址",
"wrz": "警戒水位(米)",
"zl": "水位(米)",
"dateTime": "日期",
"rz":"库水位(米)",
"wl":"蓄水量(百万立方米)",
"inq":"入库(立方米/秒)",
"damel":"坝顶高程(米)",
"dyp":"日雨量(毫米)",
"wth":"天气"}
# 爬取大江大河实时水情
url_greatriver = 'http://xxfb.mwr.cn/hydroSearch/greatRiver'
return_data1 = requests.get(url_greatriver, verify=False)
js1 = return_data1.json()
river_info = dict(js1)["result"]["data"]
river_table = pd.DataFrame(river_info[0], index=[0])
for i in range(1, len(river_info)):
river_table = pd.concat([river_table, pd.DataFrame(river_info[i], index=[0])])
for str_col_name1 in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
river_table[str_col_name1] = river_table[str_col_name1].apply(lambda s: s.strip())
river_table.columns = [word_dict.get(i) for i in river_table.columns]
river_table.index = range(len(river_table.index))
print("读取大江大河数据成功")
"""
功能
保存爬取后得到的数据集river_table为.csv文件
输入
out_path:表格文件的输出路径
"""
out_path_river = os.path.join(os.path.expanduser("~"), r'C:\Users\mhb\Desktop\水文水质数据\全国水雨情信息\大江大河') # 输出路径
date_suffix_river = river_table["时间"].values[0].split(" ")[0]
name = (str(current_time.tm_year)+"-"+str(current_time.tm_mon)+"-"+str(current_time.tm_mday))
out_csv_river = os.path.join(out_path_river, "全国大江大河实时水情_{0}.csv".format(name)) # 输出文件名
river_table.to_csv(out_csv_river, encoding='utf_8_sig')
# 打印待保存的数据
print("爬取大江大河数据成功")
# 爬取大型水库实时水情
url_greatrsvr = 'http://xxfb.mwr.cn/hydroSearch/greatRsvr'
return_data2 = requests.get(url_greatrsvr, verify=False)
js2 = return_data2.json()
rsvr_info = dict(js2)["result"]["data"]
rsvr_table = pd.DataFrame(rsvr_info[0], index=[0])
for i in range(1, len(rsvr_info)):
rsvr_table = pd.concat([rsvr_table, pd.DataFrame(rsvr_info[i], index=[0])])
for str_col_name2 in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
rsvr_table[str_col_name2] = rsvr_table[str_col_name2].apply(lambda s: s.strip())
rsvr_table.columns = [word_dict.get(i) for i in rsvr_table.columns]
rsvr_table.index = range(len(rsvr_table.index))
print("读取大型水库数据成功")
out_path_rsvr = os.path.join(os.path.expanduser("~"), r'C:\Users\mhb\Desktop\水文水质数据\全国水雨情信息\大型水库') # 输出路径
name = (str(current_time.tm_year)+"-"+str(current_time.tm_mon)+"-"+str(current_time.tm_mday))
out_csv_rsvr = os.path.join(out_path_rsvr, "全国大型水库实时水情_{0}.csv".format(name)) # 输出文件名
rsvr_table.to_csv(out_csv_rsvr, encoding='utf_8_sig')
# 打印待保存的数据
print("爬取大型水库数据成功")
# 爬取重点站实时雨情
url_pointHydroInfo = 'http://xxfb.mwr.cn/hydroSearch/pointHydroInfo'
return_data2 = requests.get(url_pointHydroInfo, verify=False)
js2 = return_data2.json()
point_info = dict(js2)["result"]["data"]
point_table = pd.DataFrame(point_info[0], index=[0])
for i in range(1, len(point_info)):
point_table = pd.concat([point_table, pd.DataFrame(point_info[i], index=[0])])
for str_col_name2 in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
point_table[str_col_name2] = point_table[str_col_name2].apply(lambda s: s.strip())
point_table.columns = [word_dict.get(i) for i in point_table.columns]
point_table.index = range(len(point_table.index))
print("读取重点雨水情数据成功")
out_path_point = os.path.join(os.path.expanduser("~"), r'C:\Users\mhb\Desktop\水文水质数据\全国水雨情信息\重点雨水情') # 输出路径
name = (str(current_time.tm_year)+"-"+str(current_time.tm_mon)+"-"+str(current_time.tm_mday))
out_csv_point = os.path.join(out_path_point, "全国重点站实时雨情_{0}.csv".format(name)) # 输出文件名
point_table.to_csv(out_csv_point, encoding='utf_8_sig')
# 打印待保存的数据
print("爬取重点雨水情数据成功")
print(name)
#time.sleep(86000)++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
import requests
import pandas as pd
import os
# 存储中英文对应的变量的中文名
word_dict = {"poiAddv": "行政区",
"poiBsnm": "流域",
"ql": "流量(立方米/秒)",
"rvnm": "河名",
"stcd": "站点代码",
"stnm": "站名",
"tm": "时间",
"webStlc": "站址",
"wrz": "警戒水位(米)",
"zl": "水位(米)",
"dateTime": "日期"}
# 爬取大江大河实时水情
url = 'http://xxfb.mwr.cn/hydroSearch/greatRiver'
return_data = requests.get(url, verify=False)
js = return_data.json()
river_info = dict(js)["result"]["data"]
river_table = pd.DataFrame(river_info[0], index=[0])
for i in range(1, len(river_info)):
river_table = pd.concat([river_table, pd.DataFrame(river_info[i], index=[0])])
for str_col_name in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
river_table[str_col_name] = river_table[str_col_name].apply(lambda s: s.strip())
river_table.columns = [word_dict.get(i) for i in river_table.columns]
river_table.index = range(len(river_table.index))
"""
功能
保存爬取后得到的数据集river_table为.csv文件
输入
out_path:表格文件的输出路径,默认为桌面
"""
out_path = os.path.join(os.path.expanduser("~"), 'Desktop') # 输出路径,默认为桌面
date_suffix = river_table["时间"].values[0].split(" ")[0]
out_csv = os.path.join(out_path, "全国大江大河_{0}.csv".format(date_suffix)) # 输出文件名
river_table.to_csv(out_csv, encoding='utf_8_sig')
# 打印待保存的数据
print(river_table)
a = input("press any key to quit")大型水库则是在上述文章基础上进行少量更改,如下:
#coding=utf-8
import requests
import pandas as pd
import os
# 存储中英文对应的变量的中文名
word_dict = {"poiAddv": "行政区",
"poiBsnm": "流域",
"wl": "蓄水量(百万立方)",
"stnm": "库名",
"stcd": "站点代码",
"rvnm": "河名",
"tm": "时间",
"webStlc": "站址",
"inq": "入库(立方米/秒)",
"rz": "库水位(米)",
"dateTime": "日期"}
# 爬取水库实时水情
url = 'http://xxfb.mwr.cn/hydroSearch/greatRsvr'
return_data = requests.get(url, verify=False)
js = return_data.json()
reservoir_info = dict(js)["result"]["data"]
reservoir_table = pd.DataFrame(reservoir_info[0], index=[0])
for i in range(1, len(reservoir_info)):
reservoir_table = pd.concat([reservoir_table, pd.DataFrame(reservoir_info[i], index=[0])])
for str_col_name in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
reservoir_table[str_col_name] = reservoir_table[str_col_name].apply(lambda s: s.strip())
reservoir_table.columns = [word_dict.get(i) for i in reservoir_table.columns]
reservoir_table.index = range(len(reservoir_table.index))
"""
功能
保存爬取后得到的数据集reservoir_table为.csv文件
输入
out_path:表格文件的输出路径,默认为桌面
"""
out_path = os.path.join(os.path.expanduser("~"), 'Desktop/水文水质数据/全国水雨情信息/全国大型水库实时水情') # 输出路径
date_suffix = reservoir_table["时间"].values[0].split(" ")[0]
out_csv = os.path.join(out_path, "全国大型水库_{0}.csv".format(date_suffix)) # 输出文件名
reservoir_table.to_csv(out_csv, encoding='utf_8_sig')
# 打印待保存的数据
print(reservoir_table)
a = input("press any key to quit")本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















