
在Pandas的实践过程中,我们经常需要将两个DataFrame合并组合在一起再进行处理,比如将不同来源的数据合并在一起,或者将不同日期的DataFrame合并在一起。
DataFrame的合并组合从方向上分,大体上分为两种情况:横向的,纵向的。(这个很容易理解吧)
看下如下的图示(图片来自Pandas官网)

横向

纵向
另外需要注意的是,两个DataFrame在合在一起的时候,如果针对重叠项(比如都有column B)会有两种不同的处理方式,一种是针对重叠项进行合并处理(比如相加,或者直接取代);另一种是忽略重叠项,只是简单的组合在一起。前者我们称为合并,后者我们叫做组合。
另外,在Pandas中有很多不同函数和不同用法,比如有concat, join, merge, append,它们各有不同的使用场景。
纵向连接
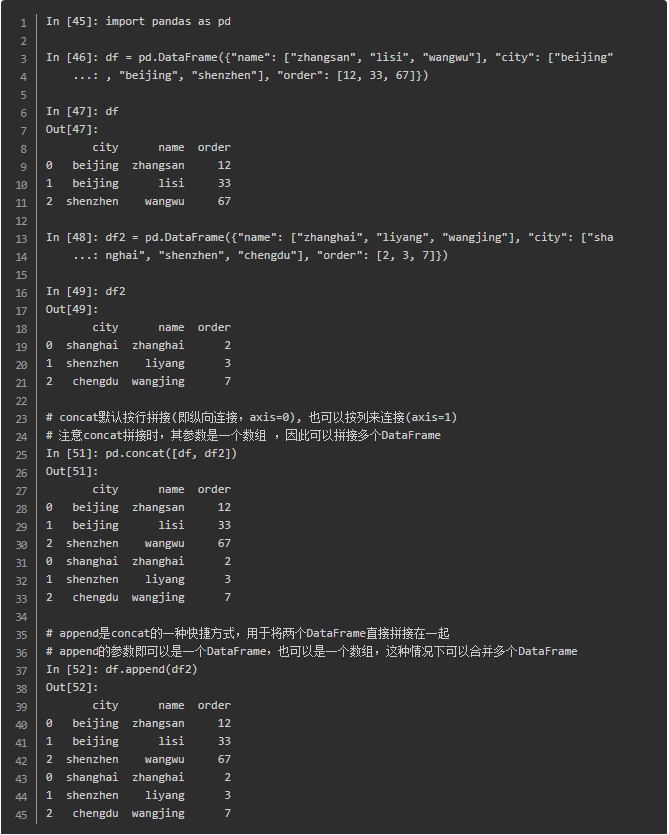
横向连接与合并
前面我们已经知道concat不仅可以纵向连接,也可以横向连接

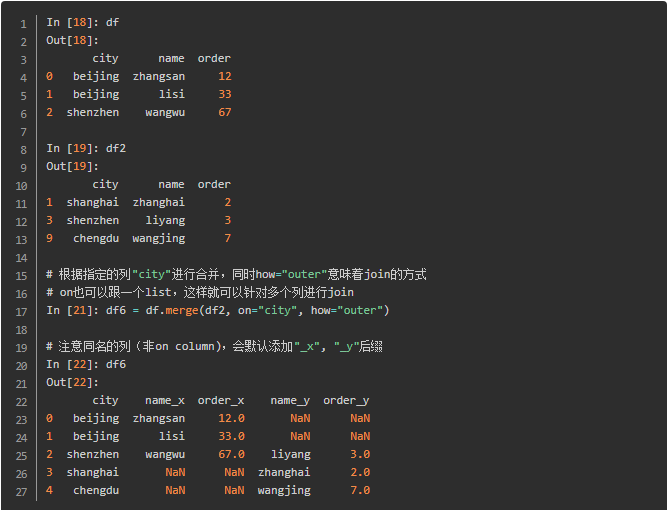
我们看到concat仍然是一种拼接,其根据index进行join,而merge更加灵活,可以根据指定的column来进行合并,如下:
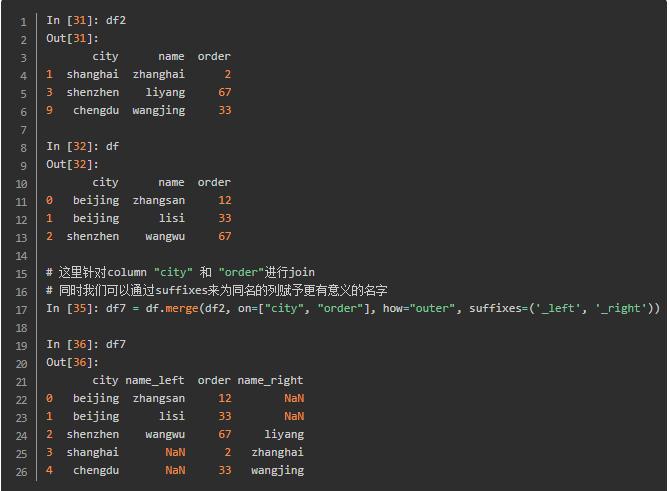
可以针对多个列进行join,并重新命名后缀,如下:
关于merge还有几个常用的参数说明如下:
- left_index & right_index: 当我们需要通过index来进行join的时候(类似concat),则可以使用left_index 或者right_index.
- sort: 默认为False,如果True则将join的key按照字典顺序进行排序,比如我们按照"city"进行join的时候,会按照"city"的字典顺序进行排序。但如果我们不需要排序,则可以将其置为False,以提高性能
- validate: 主要针对duplicate的情况,它有以下几个参数可以设置
“one_to_one” or “1:1”: checks if merge keys are unique in both left and right datasets.
“one_to_many” or “1:m”: checks if merge keys are unique in left dataset.
“many_to_one” or “m:1”: checks if merge keys are unique in right dataset.
“many_to_many” or “m:m”: allowed, but does not result in checks.
更多关于merge的说明参考如下链接:
关于merge的说明
另外,join是merge的一种简便写法,其底层是通过merge来实现的,如下两种表达方式是相同的。

示例:

merging_join_key_columns.png
需要注意的是当要join的两个DataFrame有同名的列时,必须指定suffix,否则会报错,如下:

本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















